動態云模型大規模數據挖掘算法
2014-03-26 07:33:00黃取治
長春工業大學學報 2014年3期
黃取治
(福建師范大學信息技術學院,福建福州 350007)
0 引 言
云計算的發展為互聯網的發展提供了新的機遇,它有效地降低了企業在IT設備上的成本投入,提高了企業的工作效率。數據挖掘是從大量數據中找到需要、有用數據中有的過程。數據挖掘從統計學上可以認為,是通過計算機對大量的復雜數據集的自動分析。數據挖掘是為了確定數據的模式,它需要對觀察到的數據庫進行處理。數據挖掘涉及對數據庫管理、人工智能、模式識別以及數據可視化等內容。
1 云計算和數據挖掘簡介
云計算是一種新的計算模型,它可以將計算任務用分布式技術通過大量互連的計算機協同工作,從而得到需要的計算資源和其它服務信息。云計算為互聯網時代海量數據的處理和分析提供了高效的平臺。云計算可以將海量數據分解為同樣大小的信息并且進行分布存儲,然后利用MapReduce等模型進行編程,這種技術已經在搜索引擎中得到了廣泛的應用并且取得了良好的效果[1]。用云計算的方式來進行數據挖掘,主要是由于數據挖掘所面臨的數據是海量的,在云技術出現以前都希望由高性能機或者是大規模的計算設備來完成,但是計算機服務器的功能總是有限的。同時,在海量數據的挖掘中還有比較特殊的要求,這對數據挖掘的開發環境和應用環境提出了新的要求,而云計算的方式能夠有效滿足數據挖掘的特殊需要。
數據挖掘是從大量的數據中挖掘出有用的信息,來滿足人們的特定需要。有專家預測隨著互聯網時代數據的不斷積累和計算機的普及,數據挖掘將在我國形成一個新的高科技產業。數據挖掘使數據庫技術進入到了一個新的發展階段,它不僅能夠實現對數據的查詢,而且能夠找到數據之間的聯系,從而促進信息的應用和傳遞。數據挖掘能夠實現真正的按需服務,用戶可以根據自己的需求選擇相應的服務模式。基于云計算的數據挖掘計算的一般過程如圖1所示。
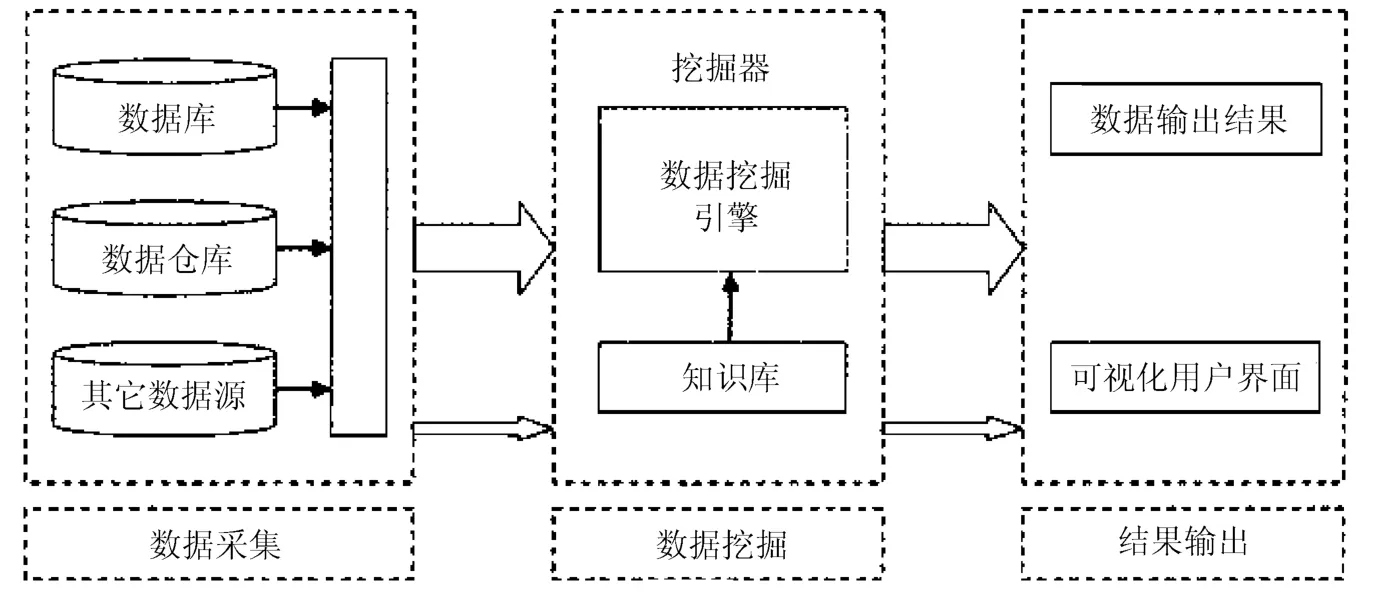
圖1 云計算數據挖掘計算過程
2 云計算和數據挖掘之間的關系分析
云計算是一種基于互聯網的的計算模式,其計算過程、計算能力、交互能力等功能是一個動態、虛擬化的過程[2]。云計算的動態和可伸縮的計算能力為數據挖掘技術的實現帶來了可能性,云計算環境為新的數據挖掘方法的研究提供了新的環境,云計算也使面向大眾的數據挖掘成為了可能。同時,云計算的發展也離不開數據挖掘的支持,在基于云計算的搜索中就包含了網頁存儲、搜索處理等內容。數據挖掘在搜索服務中具有廣泛應用,在網頁存儲中網頁去重、搜索處理中網頁排序等,其中每項服務的實現都需要數據挖掘技術來提供支持[3]。
新型的數據挖掘技術包括了面向異構數據、同構數據和跨域數據等不同的數據挖掘方法,在同構海量數據挖掘方法中,節點所存儲的數據都具有同樣的屬性。云計算平臺采用集成學習的方式來完成預測分析,并且在同構節點的基礎上實現了數據挖掘的增量學習方法,從而滿足了實時性的要求。在異構數據挖掘技術中,云計算平臺能夠根據數據的模態將數據進行分類,并提供數據相關性度量和集成。同時數據挖掘技術還存在特殊性的應用,而云計算平臺能夠為海量數據的遷移挖掘提供方法上的支持,這不僅擴大了云計算環境下數據挖掘應用的范圍,同時也更好地滿足了數據挖掘用戶的需要。
3 數據挖掘算法研究
樹型機構是一種非線性的結構,在數據庫的信息組織中得到了廣泛的應用。1986年,Quinlan提出了數據網挖掘的ID3算法,然后Quinlan在ID3算法的基礎上又提出了C4.5算法。同時為了滿足海量數據處理的需要,又提出了一系列的改進的算法,其中SLIQ和SPRINT是比較有代表性的兩個算法[4]。
ID3算法是一種分類預測算法,其核心是信息熵,信息上是一種數據所包含的信息。一組無序數據的信息熵越高,那么其熵也就越大。分類預測法可以對目標數據進行分級處理,具體表現在構建決策樹的過程中。通過生成決策樹并且按照相應的規則來判斷數據。ID3算法用信息增益作為屬性的選擇標準,ID3算法在工作中需要檢測所有數據的屬性,然后將信息增益最大的屬性來作為決策樹的結點。信息增益作為判斷屬性的標準,通過計算每個屬性的信息增益,然后比較它們的大小,就能夠得到最大信息增益的屬性。可以假設S是包含了s個數據樣本的集合,其中類標號屬性有m個不同值,定義為m個不同類Ci(i=1,2,…,m),其中假設si是類Ci中的樣本數量。假設屬性A具有v個不同的值,其集合為{a1,a2,…,av}。用屬性A將S劃分為v個不同的子集{S1,S2,…,Sv},其中Sj中的樣本表示在屬性A上具有同樣的值aj(j=1,2,…,v),設sij是子集Sj中Ci的樣本數量。C4.5算法延續了ID3算法的優點,并且對ID3算法進行了優化改進。用信息增益率來選擇屬性,避免了利用信息增益過程中屬性不足的現象。在構建樹的過程中進行了剪枝處理,并且對連續屬性的離散化處理。C4.5算法具有獨特的優點,其分類規則更容易被理解,而且準確率也比較高。但是其缺點也比較明顯,需要對數據集進行多次排序,因此在數據挖掘的過程中其算法的效率比較低。C4.5在一些駐留內存的數據集中應用比較廣泛,當數據集在內存無法容納時程序就難以有效地運行[5]。
SLIQ算法對C4.5分類算法進行了有效的改進,在決策樹的構造過程中采用了預排序和廣度優先策略兩種技術來對數據的采集進行優化。在C4.5算法中預排序是在連續屬性內部結點中尋找最優分裂標準時,對訓練集按屬性值的大小進行排序,而排序則需要一定的時間等待。為了提高數據采集的效率,SLIQ算法應用了預排序技術。預排序是通過對每個屬性進行取值,并且把所記錄的數據屬性值按照從小到大的順序進行排序,從而避免在決策樹建立的過程中對每個結點數據集進行排序而花費大量額外的時間。在實際的操作時需要根據訓練數據集的屬性來創建針對性的屬性列表,同時根據類別的屬性創建相應的類別列表。在C4.5算法中樹的構造是根據深度的優先來進行的,在具體的工作時需要對每個屬性列表的結點都進行掃描,需要花費大量的時間。為了提高數據挖掘的效率,SLIQ算法采用了廣度優先的方法來構建決策樹,在決策樹的每一層上只需要對屬性列表掃描一次就可以為決策樹中的每個結點找到最佳的分裂標準[6]。
Bayes法是一種在已知先驗概率與類條件概率的情況下的模式分類方法,待分樣本的分類結果取決于各類域中樣本的全體。設訓練樣本集分為M類,記為C={c1,…,ci,…cM},每類的先驗概率為P(ci),i=1,2,…,M。當樣本集非常大時,可以認為P(ci)=ci類樣本數/總樣本數。對于一個待分樣本X,其歸于cj類的類條件概率是P(X/ci),則根據Bayes定理,可得到cj類的后驗概率P(ci/X):
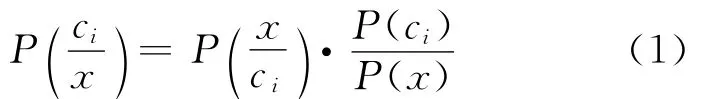
若
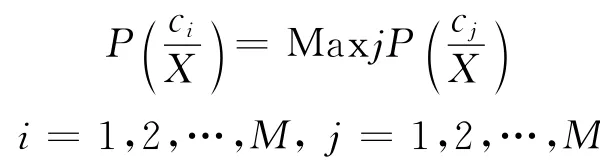
則

式(2)是最大后驗概率判決準則,將式(1)代入式(2),則有,若
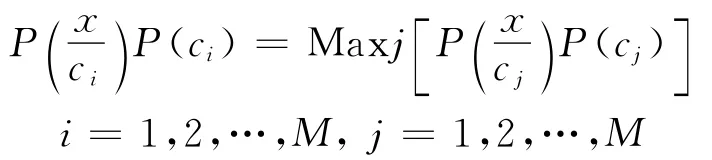
則
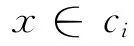
這就是常用到的Bayes分類判決準則。經過長期的研究,Bayes分類方法在理論上論證得比較充分,在應用上也是非常廣泛的。Bayes方法的薄弱環節在于實際情況下,類別總體的概率分布和各類樣本的概率分布函數(或密度函數)常常是不知道的。為了獲得它們,就要求樣本足夠大。另外,Bayes法要求表達文本的主題詞相互獨立,這樣的條件在實際文本中一般很難滿足,因此,該方法往往在效果上難以達到理論上的最大值。
為了減少內存中的數據量,SPRINT算法又對決策樹中的算法數據結構進行了進一步的改進,SPRINT算法改變了SLIQ算法中保存在內存中的類別列表,將類別列表合并到了屬性列表中。這樣在掃描屬性列表尋找結點的最佳分裂標準時,不需要參考其它的信息就可以將結點的分裂劃歸到屬性列表中進行分裂,將每一個屬性列表分成兩個分別存放各個結點的記錄。SPRINT算法使尋找每個結點的最佳分裂標準變得更簡單,但是也存在著對非分裂屬性列表進行分裂時比較困難[7]。為了改變這種缺點,在對分裂屬性進行分裂時,可以用哈希表記錄屬于某個屬性的結點,如果內存能夠容下整個哈希表,那么其它不同的屬性列表的分裂可以只參照哈希表。哈希表的大小和訓練集的大小成正比,當訓練集很大時,哈希表仍然可能完成保存在內存中,這種情況下分裂只能進行分批進行,這說明了SPRINT算法的可伸縮性仍然需要繼續改進。
基于云計算的并行數據挖掘服務模式是將同一個算法分布到不同的多個節點上,這些算法在工作的過程中是并行的、互不干擾的,而且計算資源能夠進行按需分配。分布式計算采用了云計算的模式,而數據挖掘的關鍵就是實現數據挖掘算法的并行化。云計算采用MapReduce等新的計算模型,所以現有的數據挖掘算法和并行化不能直接應用到云計算平臺上,它需要經過一系列的改造才能滿足數據挖掘的要求。因此在云計算的模式下,需要研究數據挖掘算法的并行化策略,從而實現云計算平臺下的并行數據挖掘算法。并行數據挖掘算法包括并行分類算法和并行聚類算法等,能夠進行數據分類或者預測,以及數據總結、聚類、異常和趨勢發現等。通過借助并行處理技術,在基于數據挖掘算法的特點上對云計算模型進行優化,使其能夠更加滿足數據挖掘的需要。分布式計算是解決數據挖掘任務的需要,它能夠有效地提高數據挖掘的效率。分布式數據挖掘技術主要有基于網格的分布式數據挖掘、基于云的分布式數據挖掘等,同時數據挖掘一個核心問題是實現數據挖掘算法的并行化[8]。
在利用云計算進行數據挖掘時需要選擇恰當的算法,不是所有的算法都能夠滿足數據挖掘的策略。通過選擇合適的算法,并且應用相應的并行辦法才能有效地提高數據挖掘的效率。在數據挖掘中存在著很多不確定性,所以在應用數據挖掘算法的過程中,應當注意不確定性所帶來的消極影響。數據挖掘任務存在著比較大的不確定性,數據的預處理和采集也存在非常多的不確定性,數據挖掘方法和結果也存在比較大的不確定性,所以要快速找到需要的數據信息[9]。在利用云計算進行數據挖掘時還需要對評價的結果進行評價,用戶的需求不同評價的目標也不同,所以導致了對挖掘結果評價的不確定性。同時在云計算環境下進行數據挖掘,對于云服務軟件的可信度也比較重要,例如其服務是否正確或者恰當,對隱私數據的保護等,都是數據挖掘所關注的內容。數據挖掘的算法和模型應當保持一致性,這樣才能保證數據挖掘結果的正確性。
4 結 語
通過云計算的海量數據存儲和分布計算,為云計算環境下的數據挖掘提供了新方法和手段,有效解決了海量數據挖掘的分布存儲和高效計算問題。通過開展基于云計算特點的數據挖掘算法的研究,可以為更多、更復雜的數據挖掘提供新的應用平臺。通過云計算滿足了數據挖掘的個性化和多樣性的需要,同時由于數據的多樣性,如高維的、動態的數據,都需要云計算技術來實現。
[1] 郭鑫,顏一鳴,徐洪智,等.動態云平臺下的快速閉樹聚類并行算法[J].計算機工程,2013(9):80-83.
[2] 郭鑫,李云,黃云,等.最小閉樹特征集的聚類與分類方法[J].計算機應用,2010,30(2):423-426,448.
[3] 郭鑫,顏一鳴.一種動態云模型下樹數據挖掘算法[J].小型微型計算機系統,2013,34(12):2749-2752.
[4] 宋晶.基于云模型和粗糙集的分類挖掘方法研究[D]:[碩士學位論文].成都:西南交通大學,2007.
[5] 遲慶云.基于決策樹的分類算法研究和應用[D]:[碩士學位論文].濟南:山東師范大學,2005.
[6] 黃華.基于大云數據快速挖掘過程的研究與仿真[J].計算機仿真,2013,30(4):386-389.
[7] 宛婉,周國祥.基于并行抽樣的海量數據關聯挖掘算法[J].合肥工業大學學報:自然科學版,2013,36(8):933-937.
[8] 程苗.基于云計算的用戶瀏覽偏愛路徑挖掘算法[J].計算機工程與應用,2011,47(29):85-89.
[9] 陳湘濤,張超,韓茜.基于Hadoop的并行共享決策樹挖掘算法研究[J].計算機科學,2013,47(11):258-259.
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾投資指南(2021年35期)2021-02-16 01:06:26
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
兒童繪本(2018年5期)2018-04-12 16:45:32
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
