英漢雙向哲學社科術語詞典系統設計與實現
2014-04-03 05:18:30劉伍穎梁曉波
中國科技術語 2014年2期
王 琳 劉伍穎 梁曉波
(1.國防科學技術大學,湖南長沙 410073;2.解放軍外國語學院,河南洛陽 471003)
公元1799年在埃及發現的羅塞塔石碑(Rosetta Stone)制作于公元前196年。石碑上用三種不同文字(古埃及象形文Hieroglyphic、古埃及草書文 Demotic、古希臘文)平行刻著古埃及法老Ptolemy V的詔書。到近代古希臘文還是可閱讀的,通過比對分析,人類破譯了兩種失傳已久的古埃及文字的意義。
公元1909年在中國內蒙古額濟納旗發現的木刻雕版印刷紙本《番漢合時掌中珠》刊行于西夏乾祐21年(公元1190年),是一本西夏文和漢文雙向雙解注音詞典,編者是西夏人骨勒茂才。書前有西夏文和漢文平行序言,“……不學番言,則豈和番人之眾;不會漢語,則豈入漢人之數……”表明該書目的在于方便西夏人和漢人互相學習對方語言。目前該書成為研究和破譯西夏文的關鍵工具書。
羅塞塔石碑的多語平行文本設計、《番漢合時掌中珠》的雙向雙解設計在當時都是十分先進和實用的,對后世也產生了深遠影響。當前大數據背景下,如何利用雙語平行文本[1]和雙向信息檢索技術對術語大數據進行處理成為極具挑戰的研究課題。
一 相關研究現狀與研究意義
文章開始處的例子說明多語種平行文本和雙語詞典歷來就是人類溝通不同語種的重要方法。隨著計算機和網絡的普及,這些古老的方法借助現代手段煥發出新的生命力。如金山詞霸、有道詞典、靈格斯(Lingoes)、Babylon、句酷等已經成為主流的電子詞典和翻譯軟件。又如維基百科(Wikipedia)、微軟(Microsoft)、谷歌(Google)等在多語種處理方面也是成果豐富。
金山詞霸是金山公司推出的電子詞典,收錄了140多本版權詞典。有道詞典是網易有道推出的電子詞典,它利用大數據挖掘技術對有道搜索引擎爬取的網頁大數據進行處理,得到海量漢語與外語的平行文本,以此支撐詞語和例句的查詢。靈格斯是由凱文(Kevin)個人開發的翻譯與詞典軟件,支持80多個國家語言的詞語查詢和全文翻譯。Babylon是一款提供翻譯和詞典服務的桌面軟件,它的多語種詞典是由Babylon所屬的語言專家開發出來的。句酷是北京郵電大學開發的雙語例句搜索引擎,已積累了上千萬的雙語例句。
維基百科是一種借助維基技術開發的多語種百科知識庫,它公布了截至2011年底因特網上最主要的35種網頁內容語種。微軟的Windows Phone 8手機操作系統能為用戶提供50種不同國家和地區語種支持,微軟的Windows 8操作系統支持多達109種語種。谷歌翻譯目前可提供64種語言之間的即時翻譯,而且還啟動了瀕危語言計劃以挽救3054種瀕危語種。
上述相關研究已經取得了很多產品級的應用成果。在技術上的啟示是把桌面軟件與網絡數據庫銜接起來,既有本地基本數據庫,又有在線大數據庫;借助搜索引擎網絡爬蟲技術和Wiki技術[2]不斷擴充后臺大數據庫;詞典與句典相結合,詞語查詢向機器翻譯邁進。然而已有的產品在使用時還是暴露出一些不足。如大部分電子詞典為了追求詞量,把各種詞典機械合成,造成結果重復、冗長、雜亂、大而不精;專業術語存在較多的翻譯錯誤,或者根本查不到相關的專業術語等。
隨著2010年底美國《規劃數字化未來》報告的出爐,美國政府2012年投入2億美元啟動大數據研究發展倡議,大數據時代已經來臨。微軟研究院出版的《第四范式:數據密集型的科學發現》論文集全面描述了快速興起的數據密集型科學研究,從理論上指導著大數據挖掘的方向。在大數據背景下,哲學和社會科學的飛速發展、計算技術和網絡技術的不斷進步、國際交流的日益深化使得多語種哲學社科術語不斷涌現。本文對英漢雙向哲學社科術語詞典系統的構建方法進行了探索,對限定領域[3]的雙向網絡術語詞典構建進行了嘗試。目的是利用計算機和網絡促進術語使用處理的規范化與標準化[4]、增強哲學社科術語翻譯的準確性、提升使用者的英文文獻閱讀理解和寫作能力。
二 架構設計與系統功能
英漢雙向哲學社科術語詞典系統(哲譯通)是一套基于網絡B/S架構的Web應用系統。哲譯通系統架構如圖1所示,總體上分為兩大部分。
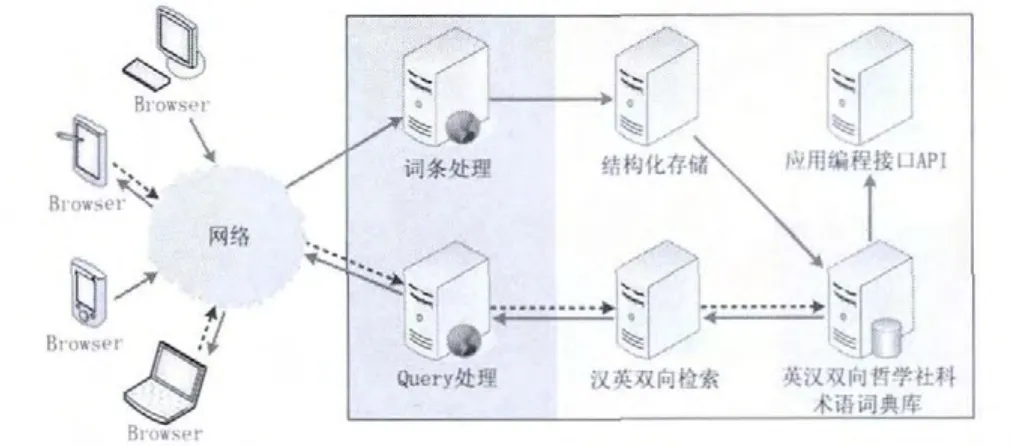
圖1 哲譯通系統架構
一部分是通過網絡接入的各種用戶終端,它們可以是安裝了瀏覽器(browser)的任意接入設備,只需通過網絡訪問服務器就可以使用哲譯通系統,簡化了客戶端的安裝,便于跨硬件、軟件、網絡平臺使用系統。另一部分是采用高速內網連接起來的各類服務器,包括用于存儲英漢雙向哲學社科術語詞典庫的數據服務器,提供結構化存儲、漢英雙向檢索、應用編程接口的應用服務器,接收Web請求并進行相應處理的Web服務器。
服務器端的詞條處理服務器并發接收單條詞條的Web提交,也接收批處理詞條提交,并把詞條數據提交到結構化存儲服務器。Query處理服務器接收漢文Query或英文Query的Web提交,支持高級搜索的邏輯表達式處理,并提交Query到漢英雙向檢索服務器,接收檢索服務器的返回結果,通過網絡反饋給瀏覽器端。結構化存儲服務器支持詞條數據的格式化、詞條相關性挖掘、索引編排、數據庫操作等功能。漢英雙向檢索服務器接收Query請求,查詢英漢雙向哲學社科術語詞典庫的索引,返回檢索結果。應用編程接口服務器擴展通用的編程接口,提供印刷紙本詞典的自動排版清樣、機器翻譯等數據增值服務。
我們設計的用于存儲術語的數據庫term表結構如圖2所示,每條詞條包含10個屬性域(術語ID、漢文詞條、英文詞條、漢文注釋、英文注釋、插圖文件名、學科類別、譯文出處、提供者、聯系方式),其中漢文注釋和英文注釋是雙語平行文本,而插圖采用文件系統進行存儲,所以插圖文件名是文件系統存儲和訪問路徑。

圖2 哲譯通數據庫term表結構
從系統功能角度分析,哲譯通是一個以術語詞典庫為核心的綜合系統,既包含詞典數據高效收集、存儲、維護、管理、分析、共享等基本功能,又包含漢英全文檢索、組合邏輯檢索、學科分類檢索、相關推薦檢索等便捷的搜索功能,還包含漢英雙解展示、開放詞條在線提交、紙本詞典自動出版、機器翻譯等數據增值服務功能。
三 系統實現
根據上文提出的系統架構,首先我們構造了英漢雙向哲學社科術語詞典庫。《番漢合時掌中珠》將詞條分為天體、天相、天變、地體、地相、地用、人體、人相、人事九大類。同理根據哲學和社會科學分類體系把英漢雙向哲學社科術語分為哲學、歷史、經濟、法學、文學、教育、管理、軍事、科技史九大類。如表1所示九大類總共收集了44 136條詞條。
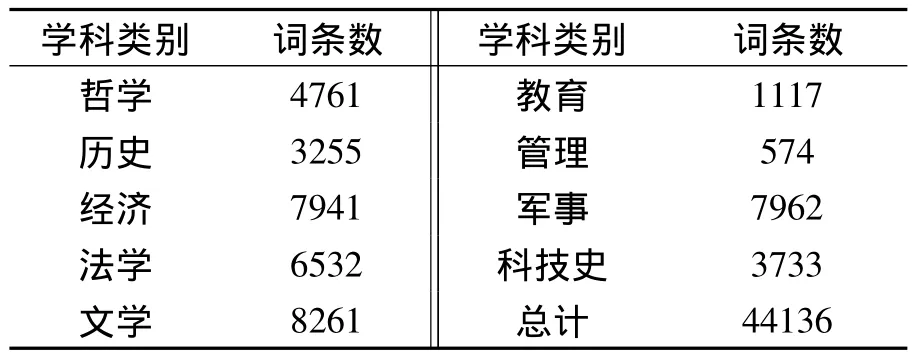
表1 哲譯通學科類別和詞條數
接著我們實現了結構化存儲服務器和詞條處理服務器,按照上文的term表結構對詞條進行格式化,對用于挖掘的域(漢文注釋、英文注釋)文本進行分詞處理,建立全文倒排索引,并存儲到數據服務器。然后我們實現了漢英雙向檢索服務器和Query處理服務器,支持以下四種搜索方式。
1.基本搜索
基本搜索類似于谷歌主頁的搜索,實現漢英全文檢索功能。在哲譯通主頁面的輸入框中輸入搜索請求(Query),點擊搜索按鈕就可以得到詳細的雙語雙解詞條信息。哲譯通基本搜索可以很好地支持對漢文英文的全文搜索,對Query中的人名、地名、機構名等專名進行了識別,提高了搜索的語義準確性。
2.學科搜索
學科搜索實現按照學科分類進行檢索的功能。由于在構造英漢雙向哲學社科術語詞典庫時,對每條詞條進行了學科分類,因此在輸入框上方有相應的學科分類鏈接,通過點擊鏈接選擇學科,能夠更加精準地限定搜索范圍,提高返回詞條的相關性。
3.高級搜索
高級搜索能夠實現復雜的多條件組合邏輯檢索。通過“+”“-”按鈕增刪搜索條件,搜索條件之間的邏輯關系可以通過邏輯下拉框設定,包括“并且”“或者”和“不含”三種邏輯運算符。除此之外,每個條件的權重可以通過權重輸入框設定,通常權重采用一個整數表示。用戶通過權重設置來準確描述自己搜索的側重點。
4.推薦搜索
推薦搜索是采用數據挖掘技術計算Query與每條詞條內容的相關性,輸出術語詞條中不含Query文本,但術語內容與Query緊密相關的詞條。這是一種暗含的隱式搜索,不需要用戶人工干預,伴隨上述三種搜索方式自動完成的。比如:輸入Query(秦始皇)點擊搜索按鈕后的搜索結果頁面,除了兩條搜索結果(秦始皇、秦始皇陵)之外,還向用戶推薦有可能感興趣的三條相關詞條(秦兵馬俑、先秦思想、郡縣制度),如果用戶感興趣可以進一步點擊相關詞條鏈接打開具體內容頁面。
最后我們還實現了應用編程接口服務器,支持印刷紙本詞典的自動排版清樣生成功能,這是對傳統紙本詞典出版的一次變革,能夠縮短詞典版本更新周期,提高詞典的時效性。此外應用編程接口服務器還為機器翻譯提供術語翻譯接口[5]。
哲譯通系統不僅詞庫容量大、學科類別全,而且詞條注釋詳略得當、譯文出處權威準確,2008年底在軍網上線試運行[6],方便教學和科研人員查詢、提交詞條。查詢時用戶只需要輸入漢文或英文詞條,便可獲得譯文詞條、漢英注釋、插圖、學科類別、譯文出處、提供者等信息。提交新詞時用戶只需要根據哲譯通詞條模板逐項填寫,其中包括提供者的姓名,通過審核后提供者自動成為哲譯通電子詞典的作者之一[7]。試運行以來得到用戶廣泛好評,成為從事哲學與社會科學教學和科研人員的好助手。
四 結語
時代劃分依據多種多樣,若以“紙”為依據,我們可以把紙發明之前的人類文明時期稱為“紙前時代”,從紙的發明到普及使用稱為“紙質時代”,那么今天趨于無紙化的大數據時代則是當之無愧的“后紙時代”。羅塞塔石碑是紙前時代的多語平行語料庫,《番漢合時掌中珠》是紙質時代的雙向雙解詞典,而哲譯通就像是后紙時代對英漢雙向網絡詞典的一種有益嘗試。盡管信息記錄材料發生了翻天覆地的變化,但上述三者的本質并沒有太多不同,哲譯通不過是古今中外跨語言文字信息處理的一種延續。
在下一步的研究工作中,我們將加強用戶與研發者之間的交流互動,根據試運行反饋完善系統功能,擴充系統詞量使得詞典覆蓋面越來越廣。可以預見哲譯通將在哲學與社會科學研究領域發揮更大的作用。此外進一步擴展應用編程接口,將英漢雙向哲學社科術語詞典作為一種重要的知識源,支撐機器翻譯領域進行更深的研究。還可以通過遷移學習技術把我們設計的術語詞典系統構建方法和實現的軟件部件用于醫藥術語庫、氣象術語庫、古籍翻譯術語庫、國防縮略術語庫[8]、軍事術語庫[9]等其他專業術語網絡詞典建設之中。
[1]王克非,黃立波.國外雙語庫研制與應用評析[EB/OL].(2013-04-23)[2013-11-15].http://www.npopsscn.gov.cn/n/2013/0423/c362514 -21242066.html.
[2]王莉,梁冰,郝春云,等.基于Wiki技術的標準術語庫的設計與實現[J].數字圖書館論壇,2011(3):44-51.
[3]向音,李蘇鳴.領域術語特征分析——以軍語為例[J].中國科技術語,2012(5):5-9.
[4]馮志偉.一個新興的術語學科——計算術語學[J].術語標準化與信息技術,2008(4):4-9.
[5]羅季美.機器翻譯中的術語錯譯分析[J].中國科技術語,2013(1):41-45.
[6]況守忠,周雨花.國防科大人文與社會科學學院開發出我國第一部“哲譯通”電子辭典[N].解放軍報,2008-12-26.
[7]王握文.在線電子辭典,網友也能當作者——國防科大研發“哲學與社會科學專有名詞電子辭典”紀實[N].解放軍報,2009-2-17.
[8]易綿竹,劉伍穎,劉萬義,王琳.多語種國防縮略術語庫研究[J].中國科技術語,2013(5):18-21.
[9]張國君,吳曉燕,丁國瑞.建立多語種軍事術語數據庫系統的基本構想[J].中國科技術語,2013(5):9-13.
