基于Lucene索引的數據庫全文檢索
2014-09-06 08:33:52岳紹敏李萬龍光順利
吉林大學學報(理學版) 2014年5期
岳紹敏,李萬龍,王 璐,光順利
(長春工業大學 計算機科學與工程學院,長春 130012)
基于Lucene索引的數據庫全文檢索
岳紹敏,李萬龍,王 璐,光順利
(長春工業大學 計算機科學與工程學院,長春 130012)
針對傳統數據庫檢索中檢索速度較慢、 檢索結果不完整、 檢索結果排列無序等問題,基于全文檢索工具Lucene索引的結構,設計一種基于Lucene的數據庫索引結構,并提出記錄倒排索引鏈表的概念,使網站不用再按照傳統順序查找方式進行檢索,而是以索引庫中的關鍵詞進行檢索,提高了檢索效率. 實驗結果表明,基于Lucene的數據庫全文檢索具有查全率高、 檢索結果排列有序等優點.
倒排索引; Lucene索引; 全文檢索; 索引結構
隨著信息化水平的不斷提高及Internet的迅速發展,需要存儲的數據越來越多,各大網站的信息量不斷增長[1],如具有海量數據的電子商務類網站. 目前針對網站的傳統數據庫檢索技術遇到了諸多問題[2],如檢索效率較低、 響應時間過長、 檢索結果與用戶的查詢意圖符合度低、 檢索結果的信息不完整、 檢索結果不能按照用戶的查詢意圖進行排序和無法提高用戶搜索體驗等.
信息檢索指在信息集合中進行查詢,找出符合用戶需求的信息. 在信息檢索技術中,全文檢索具有通用性,且最具實用性[3]. 全文檢索將用戶的查詢請求與文本中的每個詞進行比較,與數據庫檢索的字段匹配相比,全文搜索引擎的優點是查詢全面而充分,可以給用戶最全面、 最廣泛的搜索結果[4]; 且全文檢索是將用戶輸入的關鍵詞與索引庫內相關信息的索引詞進行匹配,與數據庫檢索的順序搜索相比,提高了檢索效率.
本文借鑒全文搜索工具Lucene的索引結構,設計一種針對數據庫信息的倒排索引結構,構建了基于Lucene的數據庫全文檢索系統(database full-text retrieval system based-Lucene,DFRS). 實驗結果表明,DFRS系統顯著提高了數據庫檢索的效率和查全率,可使用戶獲得更好的搜索體驗.
1 Lucene索引
Lucene是一個全文檢索引擎工具包,具有開放的源代碼,并提供了完整的索引引擎和查詢引擎及部分文本分析引擎[5](主要針對英文與德文). Lucene從總體上分為索引功能和檢索功能兩部分[6]. Lucene的索引引擎可將文本內容切詞,并對其建立索引,然后加入索引庫. Lucene的查詢引擎會按照用戶的查詢條件進行搜索,并給用戶返回相關結果[7]. 與傳統全文檢索引擎相比,Lucene具有如下特點:
1) Lucene的索引文件格式是自定義的,與應用平臺無關,它以8位字節為基礎,兼容系統或不同平臺的應用可以使用同一索引文件;
2) 基于傳統檢索引擎的倒排索引,Lucene增加了分塊索引功能,可對新的待索引文件建立小索引[8],并通過與已有的索引合并,可對索引文件進行優化,提升檢索效率;
3) Lucene具有與語言和文件格式無關的文本分析接口,當創建索引文件時,只要用索引器接收Token流即可完成操作;
4) Lucene擁有已經實現了的查詢引擎,用戶可直接利用該引擎實現自己的查詢功能,并可自己定制查詢語法規則,如布爾查詢和分組查詢等[9].
Lucene索引的結構分為4層,分別為Index層、 Segment層、 Document層和Field層[10]. Lucene索引Index由若干段(Segment)組成,每段由若干文檔(Document)組成,每個文檔由若干字段(Field)組成,每個字段由若干詞元(Term)組成.
由于Lucene索引是按照一定結構組織的,所以查詢時不用在原數據源內進行順序搜索,可直接從索引文件中查找[11],搜索的范圍得以降低,因此查詢的速度和效率較快.
Lucene的數據源不是某個具體形式,而是一個文檔的結構,用戶進行索引的源可以有多種形式[12],如html文件、 pdf文件、 字符串或數據庫表中的記錄等.
2 基于Lucene的數據庫全文檢索結構
2.1DFRS的結構
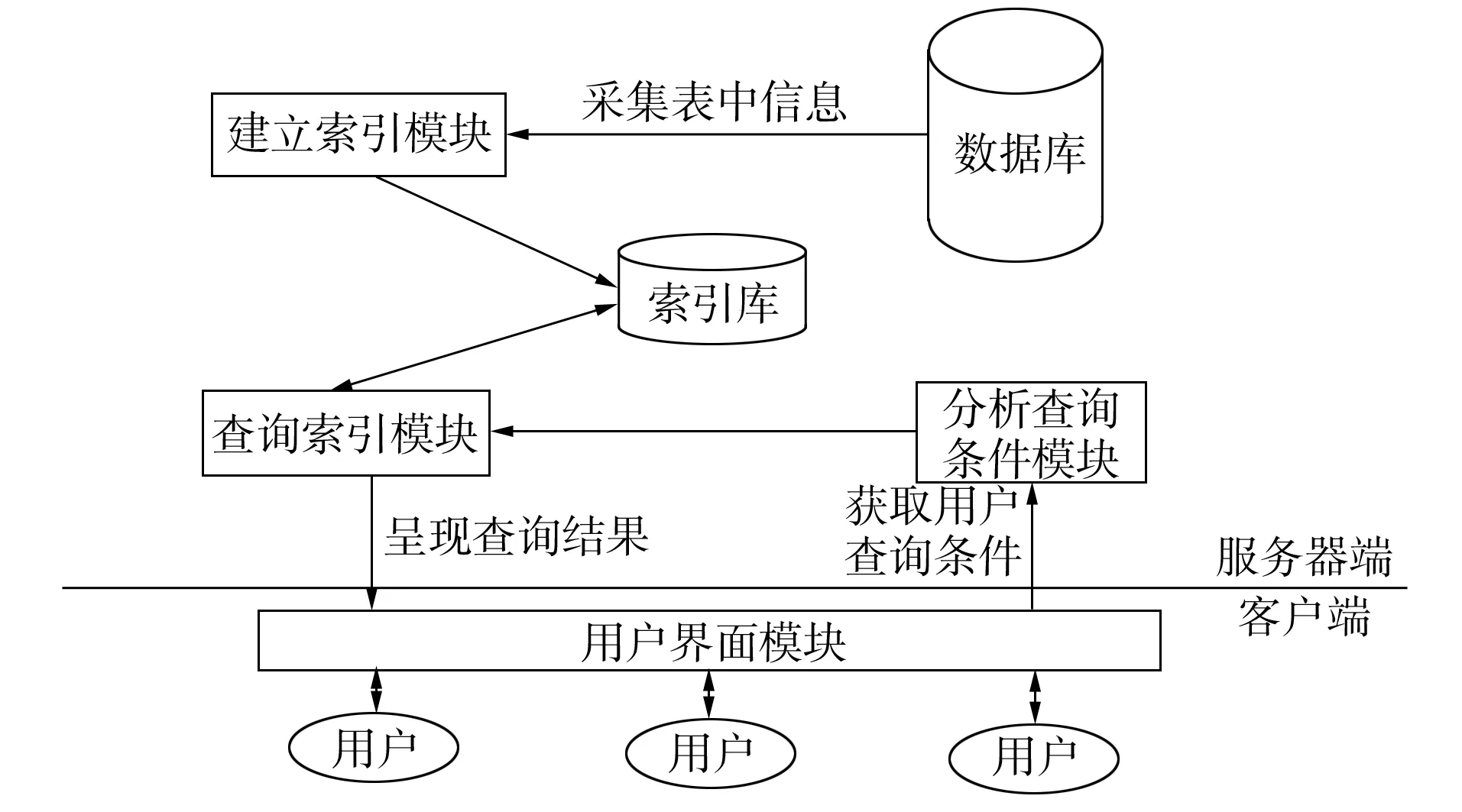
圖1 基于Lucene的數據庫全文檢索系統結構Fig.1 Structure of database full-text retrievalsystem based-Lucene
基于Lucene的數據庫全文檢索系統(DFRS)分為建立索引和查詢索引兩部分. 建立索引模塊周期性地從數據庫收集信息,對采集到的信息進行相應的詞法、 語法分析,對其建立索引,然后把索引添加到索引庫. DFRS可根據用戶輸入的信息,獲取用戶的查詢條件,并對查詢條件進行分析,然后從索引庫中進行搜索,最后把相關的查詢結果呈現給用戶. 基于Lucene的數據庫全文檢索系統結構如圖1所示.
2.2數據庫索引的結構
數據庫索引結構與Lucene索引結構類似,也分為4層,分別為Index層、 Segment層、 Record層、 Field層. 與其不同的是,數據庫索引結構第2層存儲的不是文檔(Document),而是數據庫的記錄(Record)信息. Index由若干段(Segment)組成,每段由若干記錄(Record)組成,每條記錄由若干字段(Field)組成,每個字段由若干詞元(Term)組成,詞元是最小的索引概念單位.
建立索引時,并不是每個Record都馬上添加到同一個索引文件,它們首先被寫入到不同的小文件,再合并成一個大索引文件,每個小文件都是一個Segment. 用戶提供的源是數據庫表中的一條記錄,一條記錄經過索引后,以一個Record的形式存儲在索引文件中. 一個Record可包含多個字段信息,如表中一條記錄可包含“姓名”、 “性別”、 “身高”、 “個人簡介”等字段,這些字段信息以Field的形式保存在Record中. Term是搜索的最小單位,表示字段內容經過分解后得到的一個詞,如字段內容是“張明喜歡唱歌,同時也喜歡跳舞”,分詞后得到的Term有“張明”、 “喜歡”、 “唱歌”、 “跳舞”等.
創建數據庫索引的步驟:
1) 獲取信息源. 按一定周期讀取數據庫表中的記錄,作為創建數據索引的信息源;
2) 信息篩選. 在一條記錄中,要存放哪些字段才能達到信息完整且避免垃圾信息,如學生信息,要存儲的是學生的“姓名”、 “籍貫”、 “個人簡介”等,而“視力”、 “肺活量”等其他信息一般不用存儲;
3) 信息分析. 將篩選好的信息進行分詞,對中文和英文使用的分詞器,一般用標準分詞器(StandardAnalyzer)[13];
4) 建立索引庫. 把記錄寫入到索引庫,并根據分詞器進行分詞、 建立索引,索引庫可建立到硬盤內,也可建立在內存中;
5) 把記錄添加到索引庫.
2.3倒排索引

圖2 倒排索引結構Fig.2 Structure of inverted index
倒排索引是一種索引方法,被用于存儲在全文搜索下某個關鍵詞在一條記錄或一組記錄中存儲位置的映射[14]. 這種索引表中的每項都包含一個屬性值和具有該屬性值的各記錄地址. 由于不是由記錄確定屬性值,而是由屬性值確定記錄的位置,因而稱為倒排索引. 由于倒排索引通過屬性值確定記錄的位置,所以檢索速度比普通的順序查詢快很多. 此外,不同類型的信息都可存儲在倒排鏈表中,使倒排索引具有較大的靈活性. 倒排索引結構如圖2所示. 由圖2可見,記錄頻次(Record Frequency,RF)表示共有多少記錄包含此詞(Term); 詞頻率(Frequency)表示該記錄中包含了幾個該詞(Term). 當進行檢索時可參考該參數,將更符合用戶意圖的搜索結果排在前列,可減輕用戶的檢索負擔,并增加用戶的搜索體驗.
數據庫索引以倒排索引的形式存在. 基于Lucene的數據庫全文檢索系統的索引中,每條記錄由若干字段(Field)組成,每個字段由若干詞元(Term)組成. 在倒排索引中,不同的Term組成一個詞典文件,記錄頻次(RF)是每個Term在所有記錄中出現的次數,指針指向每個Term所對應的位置文件和頻率文件. 通過指針,可找到關鍵詞Term在數據庫記錄中的位置信息和頻率信息.
下面用兩條數據庫記錄為例給出創建記錄倒排鏈表的過程:
1) 學生被準許和他們的朋友走出學校玩耍(Record ID: A0001);
2) 我的朋友去學校看望他的學生(Record ID: A0002).
將原始記錄進行分詞處理,可得到詞元(Term): “學生”、 “準許”、 “他們”、 “朋友”、 “走出”、 “學校”、 “玩耍”、 “朋友”、 “學校”、 “學生”、 “看望”. 利用所得到的Term創建一個字典,對字典按照英文字母排序,合并相同詞Term成為記錄倒排鏈表,如圖3所示.
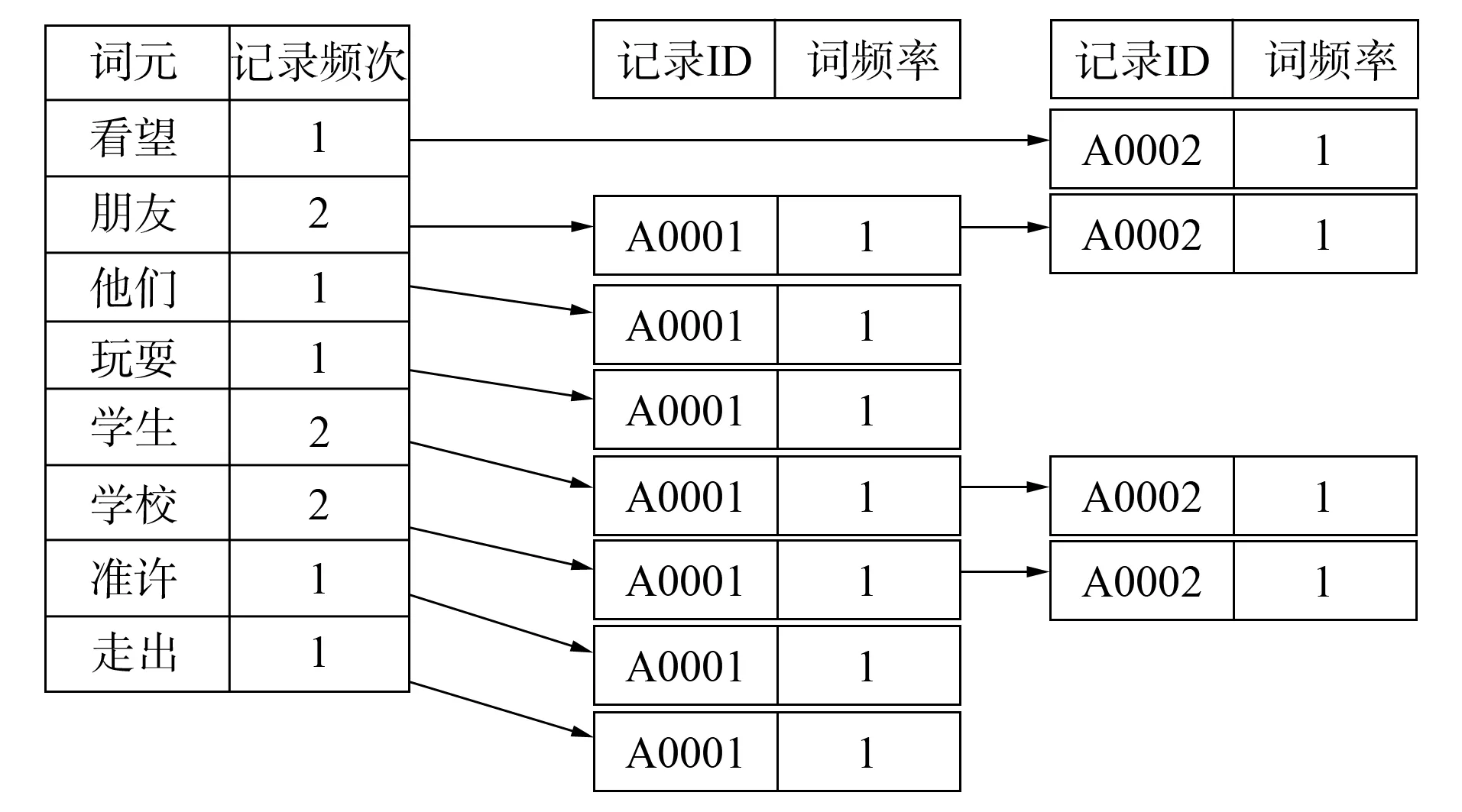
圖3 記錄倒排鏈表示意圖Fig.3 Sketch map of record inverted list
例如,對于詞(Term)“學校”,共有兩條記錄包含該詞(Term),從而詞(Term)后面的記錄鏈表共有兩項,第一項表示包含“學校”的第一條記錄,即1號記錄,該記錄中“學校”出現了1次; 第二項表示包含“學校”的第二條記錄,即2號記錄,此記錄中“學校”出現了1次.
2.4基于索引的查詢過程
首先獲取用戶的查詢語句,然后對查詢語句進行詞法分析,提取出單詞和關鍵字,再根據語法規則形成語法樹,最后利用搜索索引得到符合語法樹的記錄.
以語法樹“word1 AND word2 NOT word3”為例,搜索索引分為以下幾步:
1) 在反向索引表中,分別找出包含word1,word2,word3的記錄鏈表;
2) 對包含word1,word2的鏈表進行合并操作,得到既包含word1又包含word2的記錄鏈表;
3) 將該鏈表與word3的記錄鏈表進行差操作,去除包含word3的記錄,從而得到既包含word1又包含word2且不包含word3的記錄鏈表,該記錄鏈表就是符合檢索條件的記錄.
2.5DFRS檢索和數據庫檢索的比較
DFRS將數據庫表中的記錄通過全文索引建立反向索引(倒排索引); 對于LIKE查詢,傳統的數據庫索引無法使用,需要對數據庫的記錄逐個遍歷,進行GREP式的模糊匹配. 有索引的DFRS檢索和數據庫檢索相比,搜索速度明顯提高.
2.5.1 匹配效果 DFRS通過詞元(Term)進行匹配,可匹配詞序顛倒的記錄; 數據庫對多個關鍵詞的模糊匹配,可以使用諸如“like %吉林%航空%”的查詢語句,但不能匹配詞序顛倒的記錄,如“xxx航空xxx吉林”.
2.5.2 匹配度 DFRS在對檢索結果排序時,參考了關鍵詞的詞頻率,能將匹配度(相似度)較高的結果排在前面,從而減輕用戶的檢索負擔,并提高用戶的搜索體驗; 數據庫沒有匹配度的控制,如分別有記錄中“喜歡”這個詞出現6次和出現1次的,但是檢索結果相同.
2.5.3 結果顯示 DFRS通過特別的算法,將顯示匹配度最高的前100條結果,檢索結果有序排列,且結果集是緩沖式小批量讀取的; 數據庫的檢索結果沒有順序,且會返回所有的結果集,在匹配條目非常多時(如上萬條)需要大量的內存存放這些臨時結果集.
因此,通過全文索引對數據庫中的相應記錄都建立倒排索引,可有效提高網站搜索效率.
3 實驗結果及分析
DFRS檢索和數據庫檢索采用相同的實驗環境: 處理器為Inter Core i3 M 380 @ 2.53 GHz; 內存為4 Gb; 操作系統為Windows 7旗艦版(64位 SP1); Web服務器為Tomcat7.0; 數據庫管理系統為MySql; Lucene API為Lucene 3.6版本.
本文實驗數據來源于學生學籍管理系統的數據庫Student,主要利用DFRS對數據庫中BaseInfo表內的數據建立索引,進而利用該索引進行全文檢索. BaseInfo表共有16個字段,所用字節數總計為337字節,表的結構列于表1.
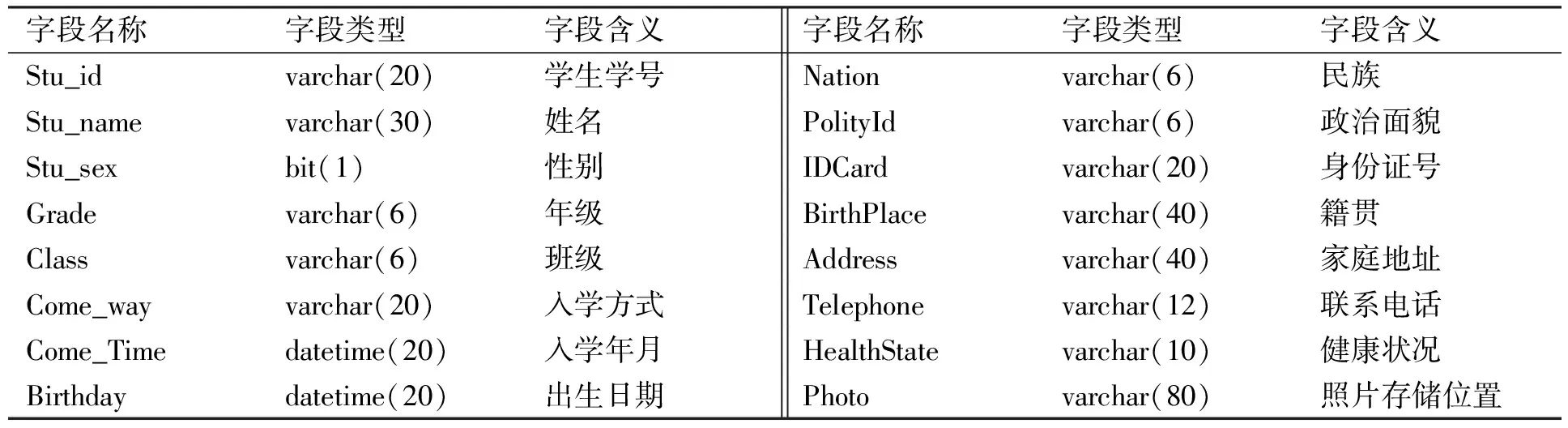
表1 BaseInfo表的結構Table 1 Structure of BaseInfo table
本文數據庫中BaseInfo表的數據內容是由Java程序隨機生成的,為增強實驗結果的可靠性,共生成了114 386條記錄.
實驗分為兩步:
1) 輸入一個關鍵詞,對不同的記錄條數、 數據庫檢索和DFRS檢索分別進行60次檢索操作,并記錄每次檢索結果;
2) 輸入多個關鍵字,分別取關鍵詞的個數為3,6,9,對于不同的關鍵詞個數,數據庫檢索和DFRS檢索分別進行40次檢索操作,并記錄每次檢索的結果.
對實驗結果進行統計,將數據庫檢索和DFRS檢索的結果進行對比,結果列于表2.
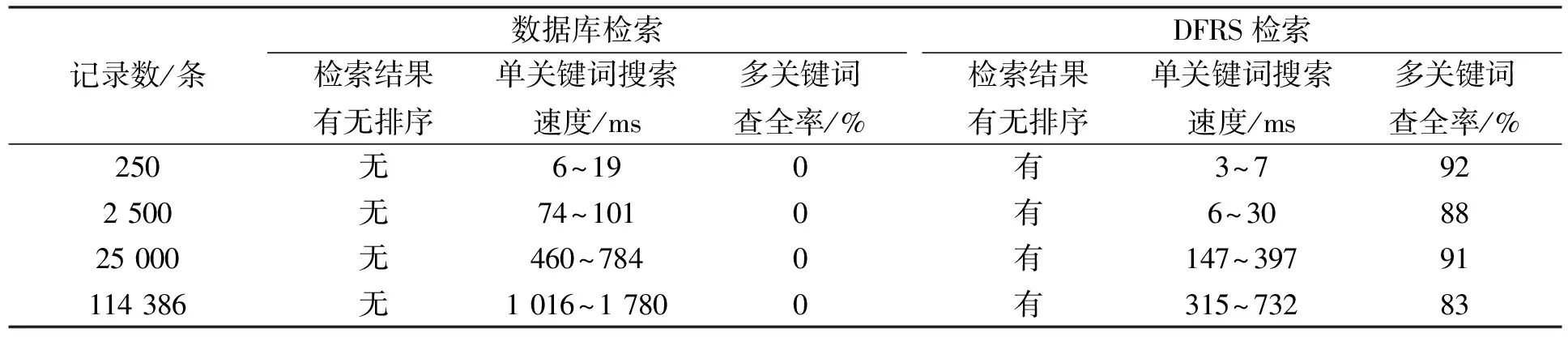
表2 數據庫檢索和DFRS檢索的比較Table 2 Contrast of database retrieval and DFRS retrieval
由表2可見,DFRS檢索與數據庫檢索相比在查詢速度、 查全率及查詢結果排序方面都具有較大的優勢. 尤其是當連續多次檢索同一個關鍵詞時,DFRS可將首次檢索結果的ID放到結果集緩存中,從而當再次檢索相同的關鍵詞時,可充分利用首次的結果緩存,而不必再次對DFRS的索引庫進行檢索,能有效提高檢索效率.
DFRS檢索的查全率較高,當檢索條件包含多個關鍵詞時,DFRS系統可將關鍵詞切分出來,并能通過詞元(Term)進行匹配,可匹配詞序顛倒的記錄,把所有相關的信息都搜索出來,并呈現給用戶. 而數據庫檢索不具備對用戶查詢條件進行切分的功能,它的查全率是0,即無法查出相關信息.
與數據庫檢索不同,由于DFRS通過倒排索引結構中記錄的詞頻實現匹配度計算,DFRS系統的檢索結果可根據用戶的查詢意圖進行排序,以減少用戶篩選無用信息的時間,能很好地提高用戶的搜索體驗,增加用戶的滿意度. 而數據庫檢索的結果一般是按照記錄在表中的順序進行排序的,無法體現用戶的查詢意圖,檢索結果顯得多而雜亂,并會有很多的無用信息,容易使用戶產生煩躁的情緒,不利于提高用戶的搜索體驗.
因此,與數據庫檢索相比,基于Lucene的數據庫全文檢索更適用于網站內數據的搜索和查詢.
綜上所述,傳統的數據庫檢索無法對用戶的查詢條件進行分析,不可以匹配詞序顛倒的記錄,檢索結果的查全率一般較低,且由于沒有相似度計算,使檢索結果沒有順序,加長了用戶的瀏覽時間,增加了用戶的檢索難度; 數據庫檢索順序地查找表中記錄,使得查找時間較長,一般無法快速滿足用戶的查找需求. 與傳統的數據庫檢索相比,基于Lucene的數據庫全文檢索能匹配詞序顛倒的數據庫記錄,有較高的查全率,且具有相似度計算,檢索結果可按照用戶需求排序,能提高用戶檢索的效率,同時,它基于特定格式的索引進行查詢,可提高檢索速度. 基于Lucene的數據庫全文檢索系統應用廣泛,適合于各類網站,檢索速度快、 查全率高,比數據庫檢索有更高的搜索體驗,更能滿足用戶的查詢需求.
[1]張俊,李魯群,周熔. 基于Lucene的搜索引擎的研究與應用 [J]. 計算機技術與發展,2013,23(6): 230-232. (ZHANG Jun,LI Luqun,ZHOU Rong. Research and Application of the Search Engine Based on Lucene [J]. Computer Technology and Development,2013,23(6): 230-232.)
[2]王歡,孫瑞志. 基于領域本體和Lucene的語義檢索系統研究 [J]. 計算機應用,2010,30(6): 1655-1657. (WANG Huan,SUN Ruizhi. Research of Semantic Retrieval System Based on Domain-Ontology and Lucene [J]. Journal of Computer Applications,2010,30(6): 1655-1657.)
[3]徐巖,朱恒民. 數據挖掘與數據庫的集成方法 [J]. 吉林大學學報: 信息科學版,2007,25(2): 228-232. (XU Yan,ZHU Hengmin. Methods of Integrating Data Mining with Database [J]. Journal of Jilin University: Information Science Edition,2007,25(2): 228-232.)
[4]王修力,馬利平. 文本信息檢索的代數模型綜述 [J]. 吉林大學學報: 信息科學版,2007,25(5): 569-576. (WANG Xiuli,MA Liping. Algebraic Models of Text Retrieval Model: Overview [J]. Journal of Jilin University: Information Science Edition,2007,25(5): 569-576.)
[5]張立巖,呂玲,王井陽. 基于最大熵算法的全文檢索研究 [J]. 河北科技大學學報,2009,30(2): 112-115. (ZHANG Liyan,Lü Ling,WANG Jingyang. Research of Chinese Full Text Information Retrieval System Based on Maximum Entropy Principle [J]. Journal of Hebei University of Science and Technology,2009,30(2): 112-115.)
[6]王茹. 提升全文檢索搜索引擎應用問題的研究 [J]. 科技與企業,2012(15): 356. (WANG Ru. Research on Promoting Search Engine Application on Full Text Search [J]. Science Technology and Enterprise,2012(15): 356.)
[7]吳鵬飛,馬鳳娟,李文革,等. 開源全文檢索引擎Lucene本地化實踐研究 [J]. 現代圖書情報技術,2009(4): 19-22. (WU Pengfei,MA Fengjuan,LI Wenge,et al. Localization of the Open Source Full-Text Retrival Engine Based on Lucene [J]. Modern Books Intelligence Technology,2009(4): 19-22.)
[8]李永春,丁華福. Lucene的全文檢索的研究與應用 [J]. 計算機技術與發展,2010,20(2): 12-15. (LI Yongchun,DING Huafu. Research and Application of Full Text Search Based on Lucene [J]. Computer Technology and Development,2010,20(2): 12-15.)
[9]潘以鋒. 基于Lucene的網站全文檢索系統的開發 [J]. 廣西教育學院學報,2006(5): 63-66. (PAN Yifeng. The Development of Full Text Retrieval System Web Site Based on Lucene [J]. Journal of Guangxi Institute of Education,2006(5): 63-66.)
[10]龔磊,武友新. Lucene全文檢索系統的研究與實現 [J]. 計算機與數字工程,2010,38(5): 64-67. (GONG Lei,WU Youxin. Research and Realization of Full-Text Retrieval Searth System by Lucene [J]. Computer and Digital Engineering,2010,38(5): 64-67.)
[11]戚學磊. 基于Lucene的站內搜索引擎技術的研究與應用 [D]. 太原: 太原理工大學,2011. (QI Xuelei. Research and Application of the Site Search Engine Technology Based on Lucene [D]. Taiyuan: Taiyuan University of Technology,2011.)
[12]郭曉磊,趙利,聶鐵錚. 支持全文檢索的XQuery查詢處理及優化的研究 [J]. 計算機與數字工程,2010,38(8): 32-34. (GUO Xiaolei,ZHAO Li,NIE Tiezheng. Study on the Query Processing and Optimization of XQuery with Full-Text Search [J]. Computer and Digital Engineering,2010,38(8): 32-34.)
[13]義天鵬,陳啟安. 基于Lucene的中文分析器分詞性能比較研究 [J]. 計算機工程,2012,38(22): 279-282. (YI Tianpeng,CHEN Qi’an. Comparison Research of Segmentation Performance for Chinese Analyzers Based on Lucene [J]. Compter Engineering,2012,38(22): 279-282.)
[14]鄭榕增,林世平. 基于Lucene的中文倒排索引技術的研究 [J]. 計算機技術與發展,2010,20(3): 80-83. (ZHENG Rongzeng,LIN Shiping. Research of Chinese Full Texts Inverted Index Based on Lucene [J]. Computer Technology and Development,2010,20(3): 80-83.)
(責任編輯: 韓 嘯)
DatabaseFull-TextRetrievalBasedonLuceneIndex
YUE Shaomin,LI Wanlong,WANG Lu,GUANG Shunli
(CollegeofComputerScienceandEngineering,ChangchunUniversityofTechnology,Changchun130012,China)
The traditional database retrieval has a lot of problems,such as the slower retrieval speed,the incomplete results,and disorderly retrieval results and so on. This paper designs a database index structure based on the Lucene index structure,the full text retrieval tool and puts forward the concept of record inverted index list. So Website can be retrieved by the keywords in the index library,not following the traditional sequential search way,which greatly improves the retrieval efficiency. At the same time,experimental results show that the database full-text retrieval based-Lucene has the advantages of high recall and the orderly retrieval results.
inverted index; Lucene index; full-text retrieval; index structure
2013-12-09.
岳紹敏(1988—),男,漢族,碩士研究生,從事搜索引擎和智能系統的研究,E-mail: shaomin_yue@163.com. 通信作者: 李萬龍(1963—),男,漢族,博士,教授,從事軟件工程與智能系統的研究,E-mail: lwl@mail.ccut.edu.cn.
吉林省自然科學基金(批準號: 20130101060JC)和吉林省教育廳“十二五”科學技術研究項目(批準號: 2014132; 2014125).
TP39
A
1671-5489(2014)05-0995-06
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
商用汽車(2016年4期)2016-05-09 01:23:12
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
