基于節點識別的慢任務調度算法
2014-10-27 11:53:48崔云飛李新明李藝劉東
通信學報 2014年7期
關鍵詞:作業
崔云飛,李新明,李藝,劉東
(1. 北京航天飛行控制中心,北京 100094;2. 裝備學院 復雜電子系統仿真重點實驗室,北京 101416)
1 引言
隨著科學技術的快速發展,科學研究、互聯網服務、電子商務等多個領域均出現數據量激增的趨勢,如何對大數據進行高效處理成為亟需解決的問題。為了應對大數據處理的挑戰,Google 提出了Map-Reduce[1],Apache Hadoop 對 Map-Reduce實現了開源,并成為目前最流行的大數據處理工具。Map-Reduce目前已有2個版本:使用最廣泛的MR1和正在測試的Yarn,它們主要的框架均是設定系統由主控節點(Master)和數據節點(Slave)組成。Master負責接收用戶請求 job和管理整個集群的Slave,首先將job拆分成多個task并根據Slave的負載情況分配task;然后對Slave節點信息和運行task進行狀態監控,并根據設定的容錯調度策略進行動態調度調整;最后匯總Slave完成的task信息,給出job處理結果。
每個程序員在編程時都會問自己2個問題“如何完成這個任務”,以及“如何能讓程序運行的更快”。Map-Reduce計算模型的使用和多次優化也是為了更好地解答這2個問題[2]。其中一個比較重要的是針對慢任務進行優化。在分布式集群環境下,因為程序 bug,負載不均衡或者資源分布不均,造成同一個job的多個task運行速度不一致,有的task運行速度明顯慢于其他task(比如:一個job的某個task進度只有10%,而其他所有task已經運行完畢),則這些task拖慢了作業的整體執行進度,這種進度緩慢從而影響整個job執行速度的task稱為慢任務。
如何確定真正的慢task,并在合適的節點上為慢 task啟動備份 task成為減少作業響應時間的關鍵。集群資源緊缺時,合理控制備份task的數量和啟動節點,對確保在少用資源情況下,減少大作業響應時間有至關重要的作用。由于大數據處理系統的異構性,集群必然存在任務執行效率不同,任務執行時間不同的情況。應該對當前運行的task進行分析,確定對大作業響應時間影響最大的task,即慢task,采取以空間換時間的思路,為慢task啟動備份task,讓備份task與原始task同時運行,哪個先運行完,則使用哪個結果,從而減少大作業的整體響應時間。慢task完成的時間是整個作業運行時間的關鍵,只有減小慢task完成的時間,才能減小大作業完成的總時間。如何判定慢task,如何選擇合適的節點啟動備份任務,如何減少慢任務的產生,是Map-Reduce調度方式在異構環境中能夠高效運行所必須解決的問題[3~6]。
針對慢任務問題,經典的解決方案[7~10]有Google MapReduce、Hadoop Speculative task、Berkerley的LATE(Longest Approximate Time to End)和Hadoop Yarn Speculative Execution。
Google MapReduce采用以空間換時間的方式為慢任務啟動多個備份任務,一定程度上解決了慢任務的影響。但存在以下不足:Google是基于同構環境研究的,不能動態識別異構環境中節點性能,不能夠選擇最優節點啟動任務拷貝;同時啟動多個任務拷貝,對資源造成浪費。
Hadoop Speculative task較Google MapReduce更精準地定位慢任務,但仍然沒有解決異構的問題,沒有考慮節點性能,容易造成調度抖動。
Berkerley的LATE建立了節點隊列和任務隊列來解決慢任務識別和節點識別的問題,選擇性能優異的節點啟動備份任務。
Hadoop Yarn Speculative Execution提出了備份價值[11~13]的概念,選擇執行備份任務帶來最大價值的節點,比原有算法更精準地定位哪個節點來執行備份任務。
上述4種算法共同的思路均是以空間換時間,在執行能力強、負載較輕的節點上對慢任務啟動備份任務,4種算法均在處理已經存在的慢任務時存在一定的缺陷,更重要的是都沒有從根本上解決慢任務生成的問題,不能夠有效地減少慢任務的生成。
本文分析上述幾種慢任務調度算法存在的問題,提出異構環境中基于節點識別的慢任務調度算法。該算法通過實時調整運行任務中的慢任務隊列和集群節點中歸一化的慢節點隊列,精確識別慢任務,在合適的節點上為慢任務啟動合適的備份任務,并對后續任務進行動態調度,從根本上減少慢任務的生成。
2 研究背景
2.1 Hadoop作業調度流程及執行描述
Apache Hadoop的 MapReduce框架是基于Google MapReduce原理實現的開源軟件,目前是最流行的大數據處理工具。
Hadoop的 MapReduce框架執行作業時,單個作業 job被拆分成多個任務 task執行。由JobInProgress監控job的執行進度,TaskInProgress監控單個 task的執行,task的執行采用 task attempt機制。正常情況下,每個task啟動一個task attempt;當檢測到任務執行失敗后,控制中心會為該任務啟動一個相同的 task attempt;當 task attempt被判定為慢任務后,控制中心會選擇一個合適的節點為對應的慢任務再啟動一個 task attempt,稱為備份任務,這2個task attempt同時運行,哪個先執行完,就采用哪個的結果,并kill掉另一個task attempt。
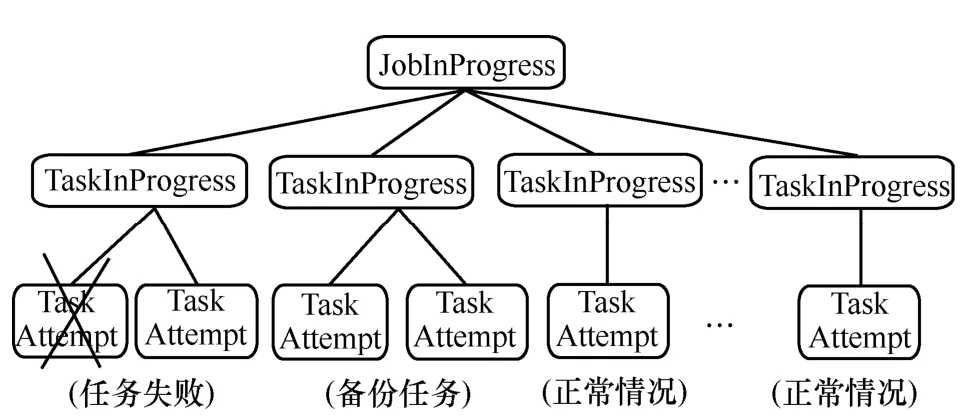
圖1 Hadoop MapReduce作業描述方式
為了降低慢任務對作業整體執行效率的影響,Google、Apache Hadoop以及一些研究機構對此進行了一定研究,目前主要的解決思路是:根據各Slave節點的負載情況,將慢任務調度到執行能力強、負載較輕的節點運行。關鍵的技術點是如何在大量task運行環境中動態判定慢任務,以及如何選擇合適的節點啟動備份任務。
2.2 問題的提出
在目前備份任務的機制下,由于慢節點的原因,某種情況下會出現多節點執行作業反而慢于較少節點執行同樣作業。下面以一個簡單的例子進行說明。
假設集群中有 slave1、slave2、slave3、slave4共4個節點,其中slave4工作效率低。
一共有12個任務需要去做,slave1、slave2和slave3執行一個任務需要1 min,slave4執行一個任務需要3 min。假設每個slave完成自身的任務才去執行備份任務。
如果讓 slave1、slave2和 slave3去做,則需要4 min,并行執行總時間就是單個slave的執行時間4 min;然而4臺同時去做需要5 min,分析如下。
這里slave1、slave2和slave3都完成了自身的3個任務,slave4完成了1個任務,還有2個任務沒開始執行,已經花費了3 min,剩下最后2個任務中的一個考慮到數據的本地性分給了 slave4,另一個分給slave1。1 min后,slave1上的任務執行完畢,slave4上的任務仍在執行,基于目前的備份任務機制,jobtracker會覺得slave4正在執行的任務為慢任務,假設在slave2上執行其備份任務,再經過1 min,slave2上的備份任務執行完畢,slave4上的任務kill掉,最后執行時間是5 min。
上述例子說明使用目前解決慢任務的備份機制,執行相同的作業,使用較多的節點可能會比使用較少的節點所需時間更長。為了避免此類情況的出現,有必要使用節點識別技術,通過資源的動態調度,從根本上減少慢任務的生成,減少作業的響應時間。
3 基于節點識別的慢任務調度
本文提出的基于節點識別的慢任務調度算法,解決2個問題:根據任務執行信息,判斷已經產生的慢任務,并為其選擇合適的節點啟動備份任務;識別集群中的慢節點,動態調整集群的任務調度,降低慢任務生成的概率,從根本上解決慢任務問題。
基于節點識別的慢任務調度算法的基本思想是,首先,根據任務的執行進度,建立任務隊列,并以此來判斷可能的慢任務;其次,根據歸一化的節點執行能力,建立節點隊列,并以此來區分慢節點和快節點;然后,當一個節點空閑時,根據節點隊列信息、任務隊列信息和備份任務執行信息,確定是否為該節點分配任務,是否為該節點分配備份任務。
3.1 任務隊列和節點隊列
為了判斷慢任務,設計了任務隊列排序算法。使用TaskQueue記錄任務快慢信息,根據任務近似結束時間升序排列task;使用NodeQueue記錄集群中各節點的快慢信息,根據節點計算能力進行降序排列slave節點。
算法1 任務隊列和節點隊列建立算法
輸入:slave節點的心跳信息(任務執行進度、執行時間)
輸出:任務隊列和節點隊列
Begin
1)When a heartbeat of slave node arrives:
2)計算該slave node 上正在運行的tasks的運行速率;
3)根據任務運行進度 progress和運行速率推測任務近似結束時間AproximateEndTime;
4)sort TaskQueue by AproximateEndTime in descending order;
5)sort NodeQueue by average speed of tasks running on slave nodes in ascending order;
6)define first 25% of TaskQueue as SlowTaskSet;
7)define first 25% of NodeQueue as SlowNodeSet;
8)define first 10% of NodeQueue(and its speed<averagespeed*0.5)as VerySlowNodeSet;
End
3.2 減少慢任務生成及其處理算法
在算法1確定慢任務隊列、慢節點隊列和非常慢節點隊列的基礎上,提出減少慢任務生成及其處理算法。
算法2 減少慢任務生成及其處理算法
輸入:當前到達的空閑節點n
輸出:是否向節點n下發任務,是否向其下發備份任務
Begin

4)//為非常慢的節點分配一個測試任務,測試該節點的性能,直到該節點不屬于非常慢的節點。

8)//根據系統事先部署的FIFO或Capacity等調度算法下發一個新任務,避免在慢節點上啟動備份任務。
9)return;
10)else if 符合啟動備份任務的條件 then
11)fortaskiin SlowTaskSet do
12)compute speculativeValue of taskiif it runs on slave noden;
13)//計算慢任務隊列中所有任務在noden上備份執行的價值。
14)end for
15)return;
16)選擇speculativeValue最大的taskj;
17)as sin gntaskj(n);
18)//在noden上為taskj啟動備份任務。
19)return;
20)else
21)as sin gnNewtask(n);
22)return;
End
下面重點對算法中測試任務、啟動備份任務的條件和speculativeValue的計算方法說明如下。
測試任務:在算法2中,被認定為特別慢的節點 VerySlowNode,在其空閑時將不再被分配正常的任務,而怎樣對其能力進行實時監測以及何時將其重新納入正常節點的范疇成為必須解決的問題。本文使用測試任務對VerySlowNode進行測試,測試任務是一個隨機的正常任務的副本執行,其執行過程及執行結果均與正常任務無關(規避測試任務對正常任務的影響)。使用測試任務監測VerySlowNode歸一化的處理能力,一旦監測到該節點的處理能力達到集群使用的標準(該節點的實時能力大于VerySlowNode的判定值),將該節點從VerySlowNodeSet中釋放。
VerySlowNodeSet中某個節點只要滿足以下 2個條件中的任意一個,那么就將節點重新納入正常節點范疇,并讓其正常執行任務。
1)該節點歸一化的執行能力大于所有節點隊列NodeQueue中最慢的10%的節點的執行能力。
2)該節點歸一化的執行能力大于所有節點平均執行能力的50%。
說明:第一個條件是確認節點執行性能不屬于最差范疇;第二個條件避免把性能還不錯的節點劃入VerySlowNodeSet節點范疇,避免造成資源使用的浪費。
VerySlowNode節點只運行測試任務原因如下。
1)目前,以Hadoop為代表的大數據處理體系,采取了一種粗放的方式處理海量的數據,機器學習的原理很多時候也是依靠大量的樣本而不是精確的邏輯。想要用好大數據,需要通過技術手段快速高效地分析整理海量的樣本,需要盡量用簡單的方式去處理大量的數據,避免復雜的處理方式帶來不必要的開銷。因此,本文在對慢任務調度進行優化的過程中,盡量避免復雜化大數據處理主流程。VerySlowNode節點變慢的原因可能會有很多種(如磁盤故障、內存溢出、程序bug、負載不均衡等),在處理過程中分析節點變慢的原因并進行修復,會影響大數據處理主流程的效率。本文采用簡單的方式處理非常慢的節點(不再分發任務),最大可能減少慢任務的產生,減少處理方式本身對大數據處理主流程的影響;在VerySlowNode節點上運行測試任務,當檢測到該節點歸一化后的執行能力達到閾值時,將其納入正常節點范疇,并讓其正常執行任務。
2)VerySlowNode節點只運行測試任務會造成資源使用的浪費,但能夠減少慢任務的產生。避免資源的浪費和減少慢任務的產生是一對矛盾體。在2.2節(問題的提出部分)對資源使用個數和作業響應時間之間的可能關系進行了說明。為了避免資源浪費,而在非常慢的節點上正常執行任務,產生慢任務的可能性會很大,反而會降低作業的整體執行效率。因此,本文不向“真正的慢節點”分發正常任務,減少慢任務的產生;同時,使用慢節點判定條件2)減少誤判慢節點的概率,盡量避免資源浪費。
啟動備份任務的條件如下。
1)還沒有為慢任務taskj啟動備份任務。
2)整個作業job的備份任務數目小于其上限,該數目是以下3個數值的最大值:
①MINIMUM_ALLOWED_SPECULATIVE_TASKS(常量10)
②PROPORTION_TOTAL_TASKS_SPECUL ATABLE(常量0.01)×totalTaskNumber
③PROPORTION_RUNNING_TASKS_SPECU LATABLE(常量0.1)×numberRunningTasks
3)在目前的空閑節點上為慢任務 taskj啟動備份任務的價值speculativeValue比其他task啟動備份任務的價值大。
speculativeValue的計算方法:借鑒hadoop- 0.23系列中speculationValue的計算方法。
speculationValue=estimatedEndTime_estimated ReplacementEndTime
其中,estimatedEndTime是通過預測算法推測的該任務的最終完成時刻,計算方法為
estimatedEndTime=estimatedRunTime_task AttemptStartTime
其中,taskAttemptStartTime為該任務的啟動時間,而estimatedRunTime為推測出來的任務運行時間,計算方法如下
estimatedEndTime=(timestamp_start)/Math.max(0.0001,progress)
其中,timestamp為當前時刻,而start為任務開始運行時間,timestamp_start表示已經運行時間,progress為任務運行進度(0~1.0)。
estimatedReplacementEndTime含義為:如果此刻啟動該任務,(可推測出來的)任務最終可能的完成時刻。
4 實驗與結果分析
為了分析文中提出的基于節點識別的慢任務調度算法(TQST)的性能,下面將 TQST算法和Berkeley LATE算法、Hadoop Yarn Speculatve Execution算法進行比較。基于Hadoop開發了Adaptive Capacity Scheduler模塊。通過在異構集群的實驗,分析算法的性能。
4.1 實驗環境
本節主要描述實驗的環境,以及環境的各個參數。使用實驗室的10臺PC機進行實驗集群的搭建,各PC機采用1000 Mbit/s的局域網互聯。這10臺PC機是異構的,如表1所示。
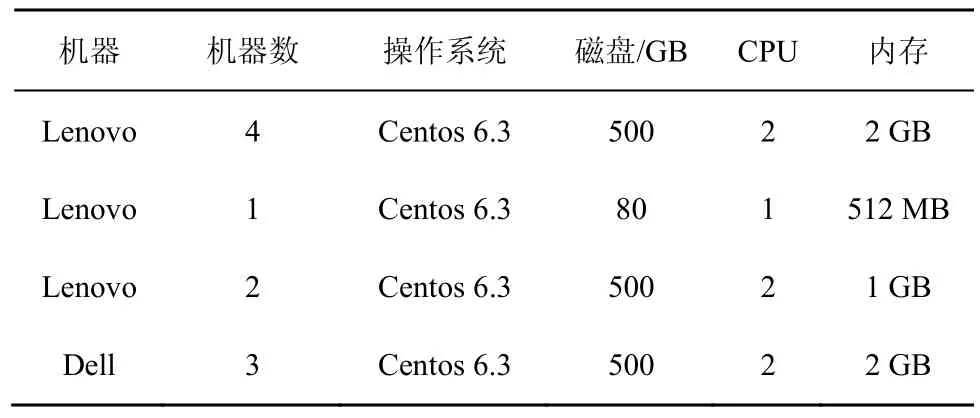
表1 實驗用集群環境配置
原型系統基于 Hadoop-0.23.5開發,Master模塊部署于管理節點,Slave模塊部署于 9個計算節點,1000 Mbit/s以太網作為數據傳輸網絡。輸入文件由Hadoop分布式文件系統管理,文件塊存儲于計算節點的本地硬盤,每個文件塊的大小為100 KB至 64 MB(用于測試處理不同大小數據塊時的效率),并且有2個副本。每一個MapReduce job作為一個作業,而一個作業中的Map Task作為任務。實驗利用Hadoop自帶的Capacity Scheduler模塊實現 Hadoop Yarn Speculatve Execution算法,利用Adaptive Capacity Scheduler模塊實現 Berkeley LATE算法和TQST算法。
4.2 實驗設置
為了比較調度算法對不同規模作業的影響,實驗依照單個task處理的數據量分成5組,分別為100 kB、1 MB、10 MB、32 MB和64 MB。每組測試的任務數均取20個任務、100個任務和500個任務。具體設置如表2所示。
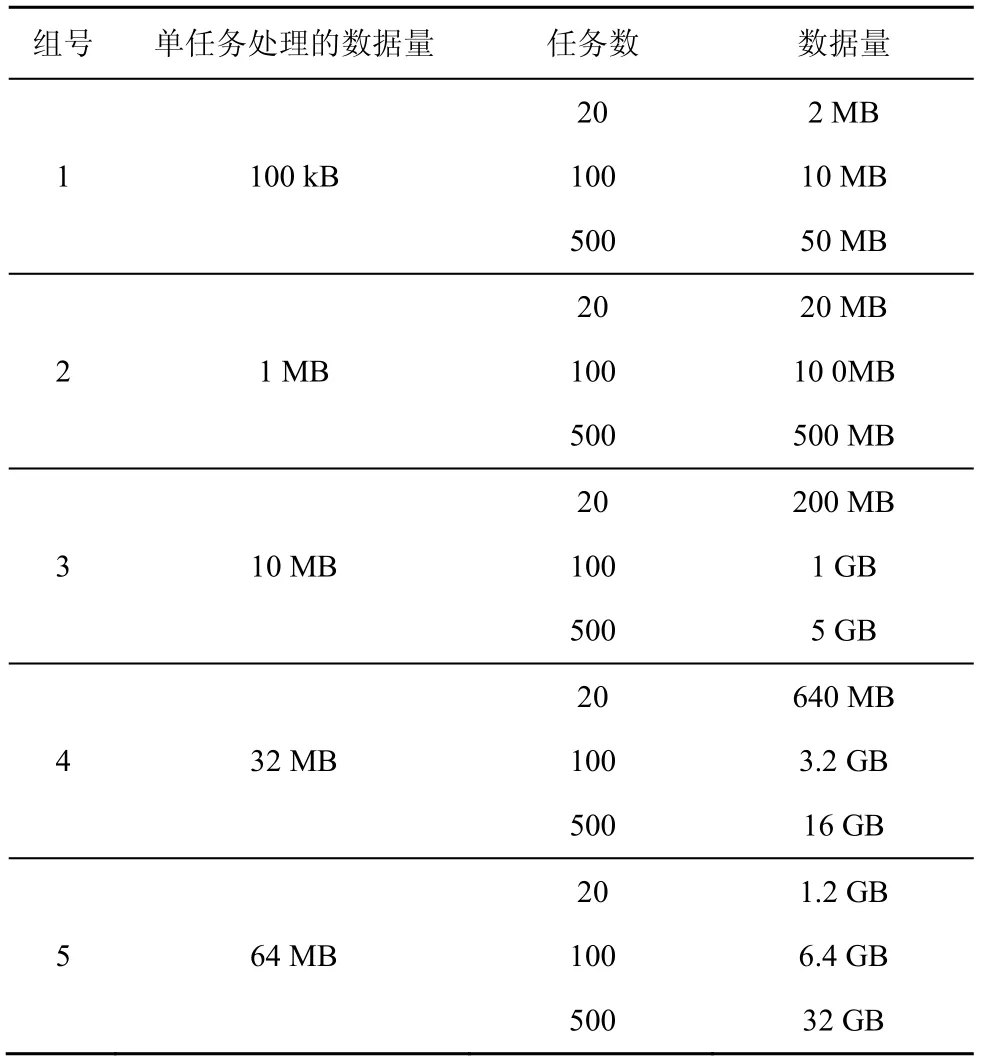
表2 作業參數設置
通過提交不同大小的作業,主要考察2個指標:備份任務執行數量,主要反映慢任務生成個數;算法完成作業的響應時間。
4.3 慢任務生成個數分析
在使用不同算法的實驗中,采用相同的慢任務判斷標準:任務執行效率為最慢的20%的任務,并且小于作業中所有任務平均執行效率的 50%。TQST算法和Berkeley LATE算法、Hadoop Yarn Speculatve Execution算法執行完作業過程中共啟動的備份任務數量對比如圖2~圖4所示。

圖2 備份任務數量對比(20任務)

圖3 備份任務數量對比(100任務)
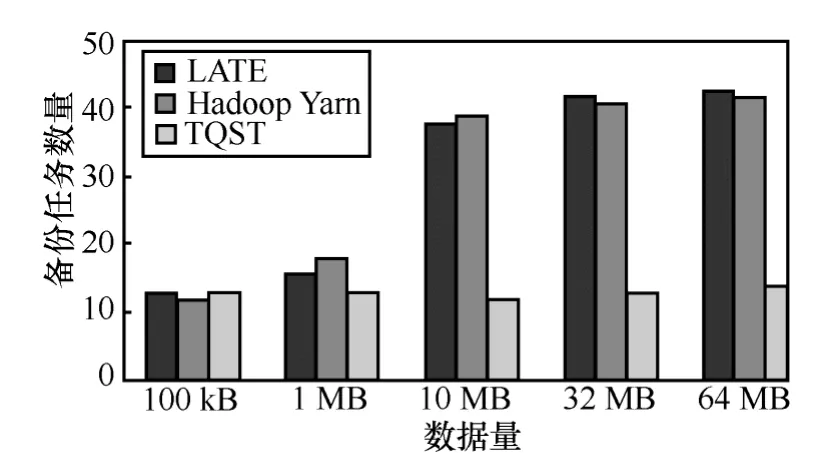
圖4 備份任務數量對比(500任務)
從上述比較中可以直觀看出,原來的慢任務調度算法 Berkeley LATE算法和 Hadoop Yarn Speculatve Execution算法沒有采取異構環境中減少慢任務產生的機制,會產生較多的慢任務,同時會啟動較多的備份任務;而本文提出的TQST算法,采取基于節點識別的調度算法,避免向非常慢的節點調度新任務,從而減少慢任務的產生,大幅度降低了慢任務的產生。同時,從上述幾個圖中可以看出,隨著單個任務處理數據量的增加,備份任務執行的數量變多,原因是單個任務的執行時間增大,更容易達到識別慢任務的時間限制。
4.4 作業響應時間分析
作業響應時間如圖5~圖7所示。

圖5 作業響應時間(20任務)

圖6 作業響應時間(100任務)
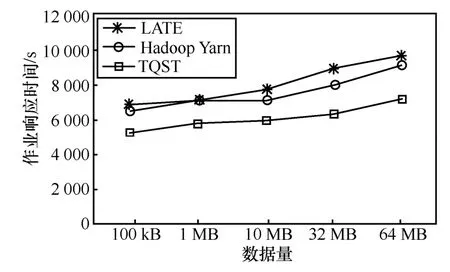
圖7 作業響應時間(500任務)
從上述比較中可以直觀地看出,Hadoop Yarn Speculatve Execution算法由于采用備份價值最大的啟動機制,能夠更準確地為慢任務啟動備份任務,從而比Berkeley LATE算法減少了作業響應時間。本文提出的TQST算法,采用基于節點識別的慢任務調度算法,不為非常慢的節點調度新任務,雖然部分慢節點不能正常參加集群工作,但是減少了慢任務的產生,從而最大可能降低了慢任務對作業響應時間的影響,明顯提高了作業效應效率。
5 結束語
本文提出了一種基于節點識別的慢任務備份執行和減少慢任務產生的調度算法。該算法與已有慢任務處理算法的不同在于非常慢節點不再執行新任務。根據備份任務啟動價值,為慢任務啟動價值最大的備份任務,解決已經產生的慢任務;在確保集群資源利用率的前提下,規避非常慢的節點,從根本上減少慢任務的產生。該算法能顯著降低慢任務的數量,提高作業的響應效率。最后的實驗結果證明了TQST算法的正確性和合理性。
[1]DEAN J,GHEMAWAT S. MapReduce: simplified data processingon large clu8ters [J].Communications of the ACM,2008,51(1): 107-113.
[2]陸嘉恒. Hadoop實戰[M]. 北京:機械工業出版社,2012.LU J H. Hadoop actual combat[M]. Beijing: China Machine Press,2012.
[3]Adaptive scheduler[EB/OL]. https://issues.apache.org/jira/browse/MAPREDUCE-1380,2013.
[4]Improve speculative execution[EB/OL]. https://issues.apache.org/ jira/browse/MAPREDUCE-2039,2013.
[5]Speculative execution is too aggressive under certain conditions[EB/OL].https://issues.apache.org/jira/browse/MAPREDUCE- 2062,2013.
[6]Speculative execution algorithm in 1.0 is too pessimistic in many cases[EB/OL]. https://issues.apache.org/jira/browse/MAPREDUCE-3895,2013.
[7]FLORIN D T. S. Eugene ngunderstanding the effects and implications of compute node related failures in hadoopHPDC’12[A]. The Netherlands ACM[C]. 2012.187-197.
[8]段翰聰,李俊杰,陳宬等. 異構環境下降低任務抖動的調度法——DPST[J]. 計算機應用,2012,32(7): 1910 -1912,1938 DUAN H C,LI J J,CHEN C,et al. DPST: a scheduling algorithm of preventing slow task trashing in heterogenous environment [J]. Journal of Computer Applications,2012,32(7): 1910 -1912,1938.
[9]LEE K H,LEE Y J,CHOI H,et al.Parallel data processing with MapReduce: a survey[J]. SIGMOD Record,2011,40(4):11-20.
[10]MATEI Z,ANDY K,ANTHONY D. Improving MapReduce performance in heterogeneous environments[A]. 8th Usenix Symposium on Operating Systems Design and Implementation[C]. 2008.29-42.
[11]Resource manager rest[EB/OL].www.hadoop.apace.org/docs/r0.23.6,2013
[12]Speculative execution for reads[EB/OL]. https://issues.apache.org/jira/browse/CASSANSRA-4705,2013.
[13]Looking for speculative tasks is very expensive[EB/OL]. https://issues.apache.org/ jira/browse/MAPREDUCE -4499,2013.
猜你喜歡
小主人報(2022年1期)2022-08-10 08:28:44
新作文·小學低年級版(2021年9期)2021-11-27 07:57:46
學生天地(2020年17期)2020-08-25 09:28:54
作文成功之路·小學版(2020年7期)2020-08-24 08:19:30
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
作文成功之路·小學版(2020年7期)2020-01-02 10:10:44
趣味(數學)(2018年12期)2018-12-29 11:24:10
小學生作文(中高年級適用)(2017年10期)2017-11-13 06:01:00
能源(2016年2期)2016-12-01 05:10:46
故事大王(2016年7期)2016-09-22 17:30:08
