基于上海市消費者的汽車共享選擇分析
2014-11-22 11:44:50周溪召
上海理工大學學報 2014年1期
周 彪, 周溪召, 李 彬
(1.上海海事大學 經濟管理學院,上海 201306;2.上海市交通港航發展研究中心,上海 200025)
20世紀80年代末期,汽車共享在歐洲出現了加速發展的趨勢.到目前為止,歐洲有近200個汽車共享服務組織,遍布瑞士、德國、英國、奧地利、荷蘭、丹麥、瑞典及挪威等國家,會員總數達到12.5萬人.汽車共享研究和實踐在國外取得了一系列成果[1],但由于我國的交通基礎設施條件、居民出行方式及城市基本結構等與歐美國家存在差異,使得它們的研究成果并不能直接應用到我國的汽車共享之中.在我國,張小明[2]研究了汽車共享出現的動因,主要提出了私家車發展帶來的3個問題:環境問題、資源問題和堵車問題.薛躍等[3]在研究中闡明,基于私人擁有為基礎的汽車普及消費既是一種大幅度提高社會福利水平的生活方式,又是一種非可持續性消費模式,它不僅消耗大量自然資源,且造成極大的環境危害.程偉力[4]在關于汽車共享服務的對象研究中指出,汽車共享服務組織的服務對象是那些富有駕駛經驗且遵守交通規則的人.
本文將基于消費者選擇行為理論,通過問卷調查,明確汽車共享的潛在市場.通過建立模型來分析購車與汽車共享之間的效用差異,明確選擇購車或汽車共享影響因素的權重,分析消費者個人長期的汽車擁有行為.
1 模型構建
1.1 問卷目的
通過有效的問卷調查描述各個因素對個人選擇行為的影響.影響汽車擁有和汽車共享的主要因素包括:a.家庭經濟條件,如家庭收入、家庭車輛擁有數、家庭房屋擁有情況、家庭成員及個人駕駛經驗;b.相關費用,如現有汽車的使用費用、計劃購車的費用、汽車共享的使用費用;c.用車需求,如汽車使用頻率、家庭未成年人數、居住地公共交通條件;d.個人特征,如個人通勤及其它出行特征、個人環境意識、個人年齡、個人職業及受教育程度.
通過問卷調查,分析各個影響因素對個人消費者選擇汽車共享的權重,在給定消費者情況時,能夠迅速發現其是否為汽車共享的潛在顧客群.
1.2 問卷設計
問卷主要從上述主要因素的具體表現形式來設計問題,框架如下:第一部分為個人特征部分,主要包括性別、年齡及受教育程度等情況;第二部分是家庭經濟情況,主要是收入情況、家庭車輛擁有情況、家庭成員及個人駕車經驗情況;第三部分主要為用車需求調查,主要搜集的是日常出行方式、現有交通出行情況、出行(用車)頻率等方面信息;第四部分為相關費用部分,主要是了解被訪者車輛的價格、每月開銷等情況;第五部分是收集被訪者對汽車共享的了解情況.
1.3 樣本描述
問卷采取的是網絡調查與紙質問卷調查相結合的方式.網絡調查部分:將設計好的問卷放在問卷星網站上,通過郵件、QQ、MSN、微博及電話等方式邀請同學、同事、朋友、網友以及通過他們轉發來完成.紙質問卷調查部分:在上海市一些住宅小區內發放問卷完成.本次問卷調查總共有250位被調查者,有效問卷213份,被調查對象的個人特征分布如表1所示.
1.4 Logit模型
通過對汽車共享服務和擁有私家車兩者的要素分析,希望能分析出在何種情況下,消費者會選擇汽車共享,在何種情況下消費者會選擇擁有私家車.由于Mcfadden提出的離散選擇模型應用廣泛[5-6],本文采用該模型.
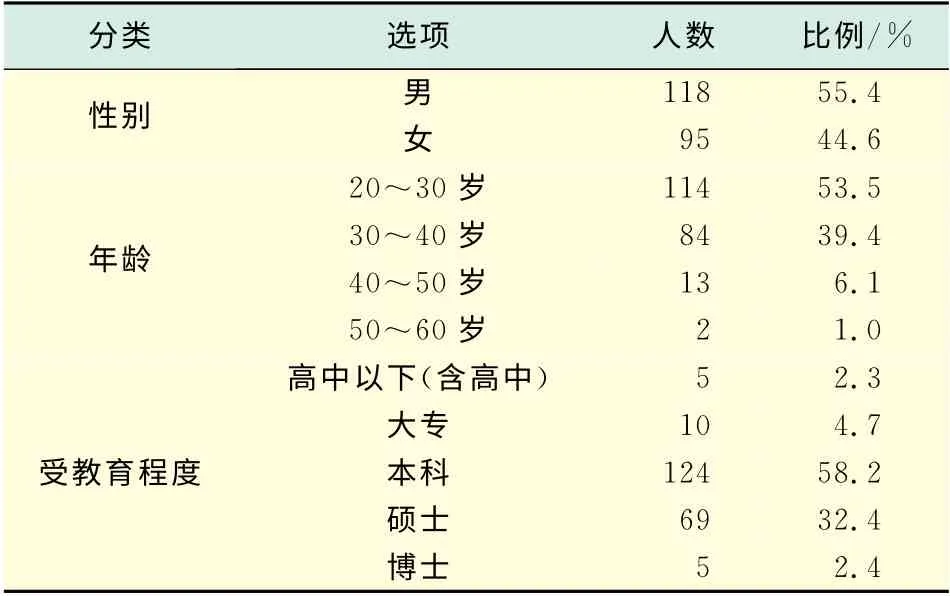
表1個人特征部分調查結果Tab.1 Personal characteristics of the survey results
假設 a.Logit模型的因變量yi是二分變量,它只能取值0,1;
b.Logit模型中的因變量和各自變量之間的關系是非線性的.
通常將事情分為可控部分和不可控部分,因此,二分變量的回歸方程為
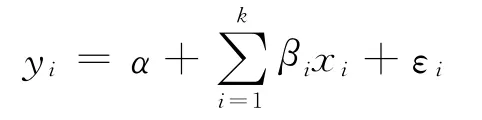
式 中,α,βi為 參 數;xi為 自 變 量;yi為 二 分 變 量;εi為誤差項,假設εi服從Logistic 分布,分布函數其中,μ,σ 分別為Logistic分布的位置參數和尺度參數[7].

這就是著名的Logit模型.
2 SPSS軟件運算分析
問卷調查的目的是得到2個Logit模型:a.放棄私家車而選擇汽車共享出行模式的Logit模型;b.無車一族選擇汽車共享出行模式的Logit模型.因此,分割被調查對象的一個最重要因素就是:有車與否.
2.1 無車一族選擇汽車共享出行模式的Logit模型
在本次問卷調查中,無車一族有125 人,占58.69%.將已獲得數據輸入SPSS18.0,選擇二元Logistic回歸分析,輸出結果如下:
本次SPSS操作共處理了125個案例,在參加問卷調查后愿意嘗試汽車共享這種出行方式的共有77人,占62.4%.在SPSS中,默認將二分類因變量中出現次數較多的賦值為1,本文將“之后不愿意嘗試汽車共享”賦為0,“之后愿意嘗試汽車共享”賦為1.
從表2中的顯著性指標取值可以知道,除了單獨納入Teenager(家庭中未成年人的個數)的模型沒有統計意義之外,其余模型都有顯著的統計學意義.

表2 不在方程中的變量1Tab.2 Variables not in the equation1
表3表示的是將上述變量納入模型后模型的全局檢驗結果,共采用了3種檢驗方法,分別是步與步間的相對似然比檢驗(步驟),塊之間的相對似然比檢驗(塊)和模型間的相對似然比檢驗(模型).本例采取強行一次進入,一次將所有變量納入模型,所以,3種檢驗方法的結果是一致的,模型具有顯著的統計學意義.
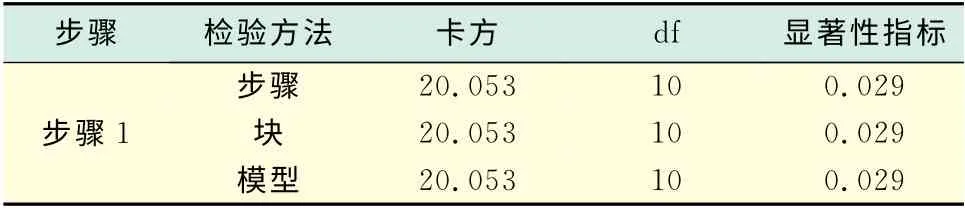
表3 模型系數的綜合檢驗1Tab.3 Comprehensive test of model coefficients 1
表4主要給出-2 對數似然值和兩類決定系數,-2對數似然值越小,兩類決定系數越接近1,說明模型的擬合程度越好.
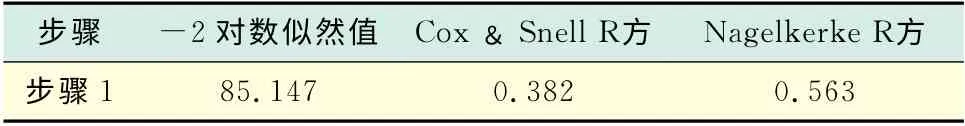
表4 模型匯總Tab.4 Model summary
當自變量數量增加時,尤其是連續自變量納入模型后,皮爾遜卡方不再適用于估計擬合優度,此時引進Hosmer和Lemeshow(HL)研究的對Logistic回歸模型擬合優度的檢驗方法,如表5所示.
HL檢驗根據預測概率值將數據分為大致相同規模的10個組,隨機進行分析,預測值越接近觀測值,說明模型擬合得越好.通過數據可以再次驗證,此次模型擬合得不算好,但是,也具有一定的代表性.
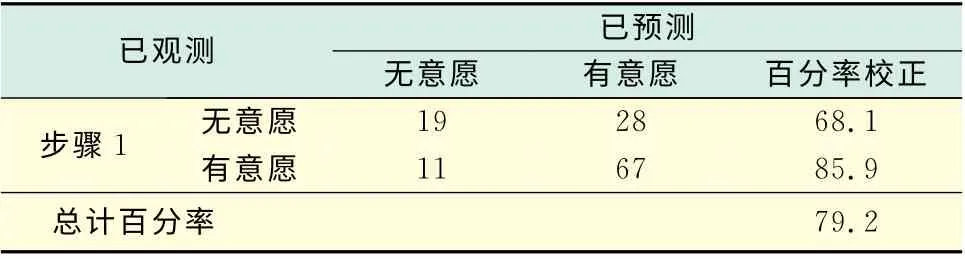
表6是將變量全部納入模型后模型的分類預測值,此時模型預測的準確度只有79.2%.從案例殘差分析來看,只有2個案例(54號和58號)存在異常,剩余的123個案例均在正態分布之內,無異常.
表7(見下頁)是Logistic模型的擬合結果.
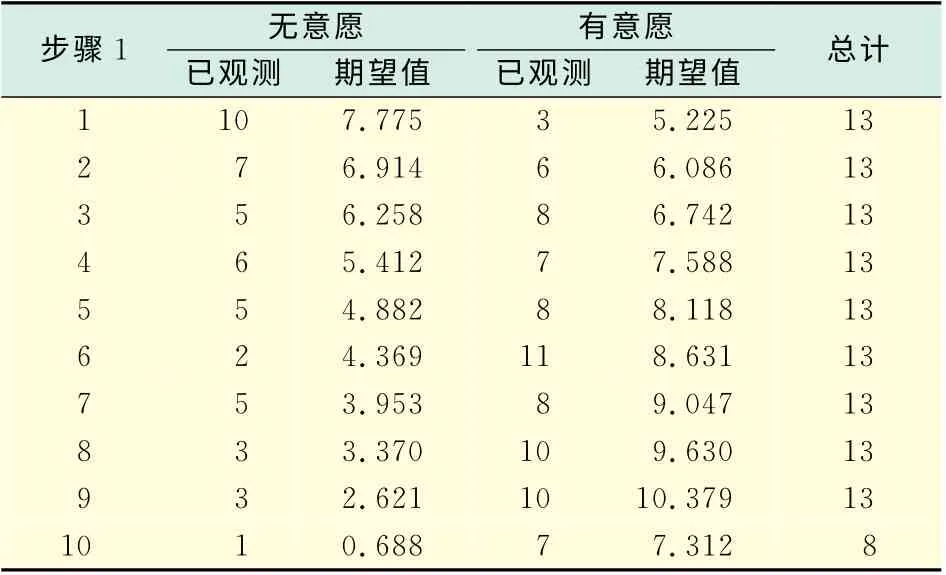
表5 隨機性表Tab.5 Randomness table
?
2.2 放棄私家車而選擇汽車共享出行模式的Logit模型
對于已有私家車的被調查者的信息,用同樣的方式帶入SPSS運算,輸出結果如下:
對于已有私家車的被調查者數據共有88個,占41.3%.在Logistic模型運算中,系統自動賦值1給“之后愿意嘗試汽車共享”的人群,賦值0給“之后不愿意嘗試汽車共享”的人群,在本次調查中,之后愿意嘗試汽車共享出行模式的人占55.7%.
在進行無車一族Logistic回歸分析時,由于各個因素對于最后是否愿意嘗試汽車共享的影響不是很大,如果初始假設參加汽車共享的概率為0.5,通過本次調查所得到的數據來檢驗,預測的準確度為62.4%,因此,Logistic回歸將會失去意義,所以,在無車一族的Logistic回歸分析時,剔除了常數的影響,直接在各個自變量中尋找某種聯系.
在分析已有私家車這類人群,選擇汽車共享這種出行方式時,常數本身對模型的影響不大.如表8所示(見下頁),系統自動賦予常量0.228,顯著性指標的取值為0.287,模型不夠顯著.如表9所示(見下頁).從不在模型中變量的顯著性指標取值可以知道,有些變量對于模型是沒有統計意義的,在此選用向后剔除法,即開始將所有變量納入模型中,每次將最不顯著的一個變量剔除,直到模型中剩余變量都 足夠顯著.

表7 方程中的變量1Tab.7 Variables in the equation 1
在表10中,由于在這里采用的是向后剔除法,先一次性將所有變量納入模型,再逐次剔除最不顯著的變量,所以,3種檢驗方法的結果不大一致,步與步間的相對似然比檢驗顯示模型的統計學意義不夠顯著,但是,塊間的相對似然比檢驗和模型間的相對似然比檢驗結果顯示模型是越來越顯著的.在表11和表12中,HL檢驗顯示,隨著變量的減少,模型的擬合度下降比較小,在步驟4結束時,模型的擬合度還是不錯的.

表8 方程中的變量2Tab.8 Variables in the equation 2
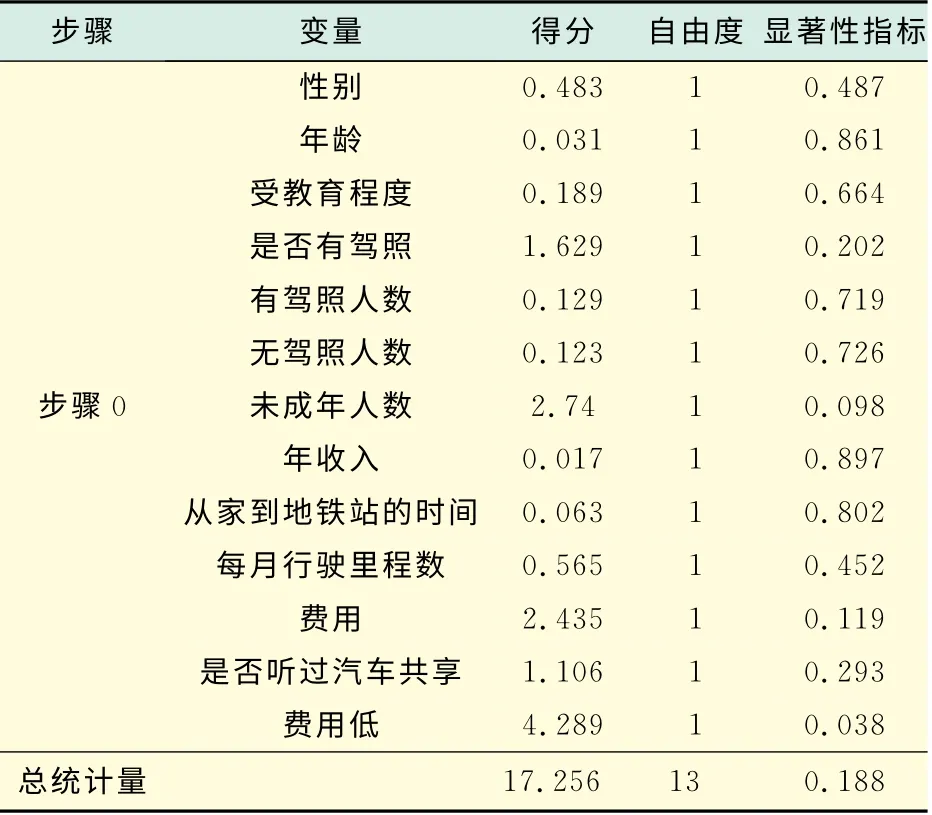
表9 不在方程中的變量2Tab.9 Variables not in the equation 2

表10 模型系數的綜合檢驗2Tab.10 Comprehensive test of model coefficients 2

表11 Hosmer和Lemeshow 檢驗Tab.11 Hosmer and Lemeshow test

表12 Hosmer和Lemeshow 檢驗的隨機性表Tab.12 Randomness table of the Hosmer and Lemeshow tests
如表13和表14所示,在未剔除任何變量時,模型的準確度達到86.4%,但是,當模型進行到步驟4,剔除了3個變量后,模型的準確度降低為83%.雖然模型的準確度有些許降低,但是,其引起的誤差還是在可接受范圍內.進行到步驟4時,模型中被剔除的變量為:受教育程度、家庭中未持有駕照的成年人數和從家步行到最近地鐵站的時間.

表13 分類表2Tab.13 Classification table2
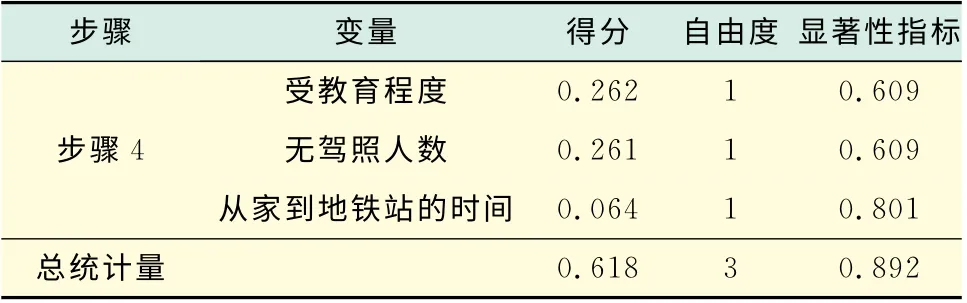
表14 不在方程中的變量3Tab.14 Variables not in the equation 3
在這組數據的運算中,不存在殘差案例,所有的案例均落在正態分布內.從表15可以清楚地看出每個變量的系數以及其對是否選擇汽車共享出行模式的影響程度.從表15中可以看到,已有私家車的潛在顧客群在是否選擇汽車共享出行模式時,首先考慮的是成本問題,其次考慮的是家庭中未成年人數.
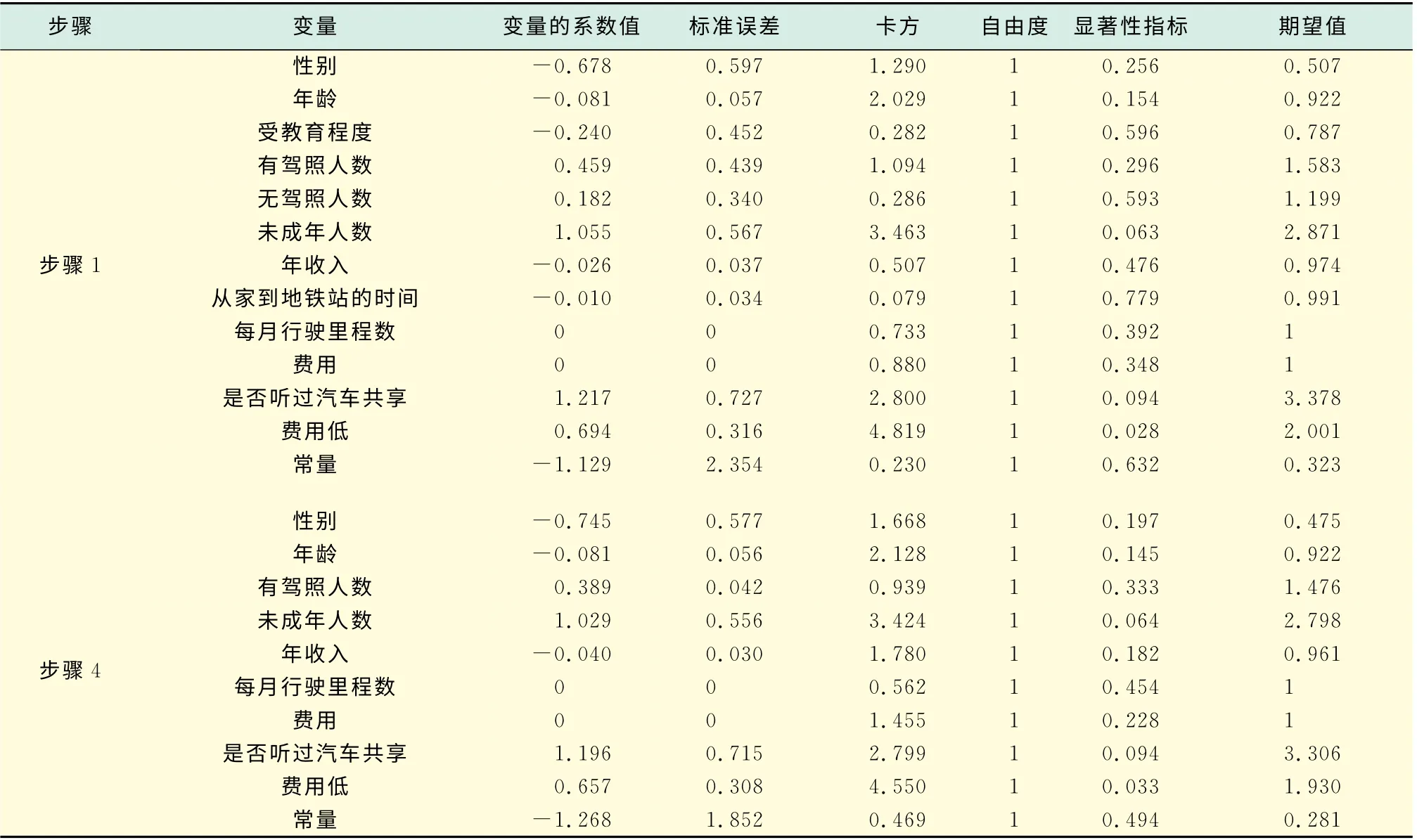
表15 方程中的變量3Tab.15 Variables in the equation 3
3 結果分析
國外的諸多研究都表明,汽車共享的主要客戶是20~40歲之間的青少年,這類人的通勤出行、購物出行需求較高,因此,問卷調查的主要對象集中在20~40歲之間的青少年群體.
通過本次問卷調查可以發現,在汽車共享不夠發達的中國,對于出行方式的選擇,大部分被調查者選擇的是公共交通,占到70.3%,而私家車出行只占到10.9%.通過對私家車擁有的調查,很清楚可以看到,有41.3%的被調查者擁有私家車,由此可見私家車擁有者中有73.6%的人平時的出行仍然不選擇私家車,而是選擇更具經濟性的公共交通.
在調查人們選擇出行方式考慮的主要因素時,有83.6%的被調查者選擇了經濟與快捷.在對私家車的調查中,被調查者普遍認為私家車能夠提供出行更強的便捷性、舒適性、靈活性,但是,在私家車使用過程中,尋找停車位是一件很困難的事情.此外,私家車的使用成本高、帶來嚴重的環境污染,而且,被調查者都不認為擁有私家車是一種社會地位的表現,因此,在消費者不認為私家車是社會地位的表現的前提下,汽車共享如果真正實行,將減少道路車輛,緩解道路擁堵,解決停車難的問題,使出行更加便捷;另一方面,汽車共享對比私家車,有使用費更低的優勢,從這個角度出發,又能滿足消費者對于經濟性的要求.
對上海市場的個人消費者而言,汽車共享更能吸引那些目前還沒有私家車,但有用車需求的人群,特別是已經計劃購買私家車的人群,這一點和國外的研究結果非常接近,因此,這個階段的市場營銷重點應該在于那些有購車計劃的人群.
經過調查,被調查者在考慮選擇汽車共享時,汽車共享的價格是一個最主要的影響因素,取車、還車的手續簡便也是一個重要因素,汽車的新舊程度的影響稍弱.親友是否使用,對于消費者選擇汽車共享的影響很小,基本可以忽略.由此可以看出,要成功推廣汽車共享,價格的制定一定要合理,這一點至關重要.
在對有車和無車兩組被調查對象的數據進行Logistic回歸分析后,發現20~40歲的青少年的收入水平比較穩定,對于是否選擇汽車共享的影響作用不是很大.從Logit函數可以看出,目前青少年的收入水平處于S形曲線的尾部,以其現有的水平可以負擔起汽車共享的費用,所以,收入的變動對于消費者是否選擇汽車共享的影響不是很大.
在無車一族中,通過Logistic回歸,可以清楚地發現最重要的兩個因素是:受教育程度和從家步行至最近地鐵站的時間.受教育程度越高的消費者,更加傾向嘗試汽車共享.這一調查結果與國外許多研究結果一致,汽車共享企業在開拓市場時,對這一部分人群制定專門的營銷計劃是必不可少的.
在有車一族中,最重要的兩個影響因素是:汽車共享的價格和家庭中未成年人數.汽車共享的價格對是否選擇汽車共享,這在經濟學中關于需求有解釋.關于家庭中的未成年人數,在已有未成年人的家庭中,出行的很大一部分原因是送孩子上學,在這種情況下,同一小區各個家庭的孩子可以共車去上學,從而減少各個家庭使用私家車的費用,這樣既便捷又經濟.
此次問卷調查取得的數據基本無殘差案例,都落在正態分布內,能說明一定情況.各個自變量對于是否選擇汽車共享的影響是合理的,但是,由于被調查者數量的限制,各自變量對于消費者是否選擇汽車共享的影響程度可能存在誤差,需要進一步研究.
4 結束語
基于上海市場消費者作問卷調查,進行Logit回歸分析,探討影響消費者選擇汽車共享因素的重要性,但是依然存在很多不足之處.首先是由于時間關系,上海市場消費者調研的樣本數量還很小;其次在調查問卷的設計上也存在一些缺陷,尚有一些對消費者選擇汽車共享有顯著影響的因素未納入模型;第三,對于有車一族與無車一族選擇汽車共享的Logit模型的擬合度有待于提高.
[1]夏凱旋,何明升.國外汽車共享服務的理論與實踐[J].城市問題,2006(4):87-92.
[2]張小明.共享汽車——一種全新的消費模式[J].世界汽車,2001(7):21-22.
[3]薛躍,楊同宇,溫素彬.汽車共享消費的發展模式及社會經濟特性分析[J].技術經濟與管理研究,2005(l):54-58.
[4]程偉力.北美小汽車共用的發展狀況[J].交通與運輸,2007(增刊):34-37.
[5]McFadden D.Conditional Logit analysis of qualitative choice behavior[M]∥Zarembka P.Frontiers in Econometrics.New York:Academic Press,1974.
[6]邁克爾·弗洛里安,吳稼豪,賀曙光.多層Logit結構多模式變量需求網絡平衡模型[J].上海理工大學學報1999,21(3):191-202.
[7]王濟川,郭志剛.Logistic 回歸模型——方法與應用[M].北京:高等教育出版社,2001.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2020年20期)2020-12-15 15:53:19
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童時代·快樂苗苗(2017年7期)2018-01-24 18:28:45
瞭望東方周刊(2017年34期)2017-09-13 17:13:26
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年16期)2016-08-21 13:56:16
發明與創新(2016年21期)2016-05-17 03:57:29
作文大王·低年級(2016年4期)2016-04-18 00:24:37
