2014年新疆棉花產量統計數據建模與決策分析
2015-03-13 09:37:33韓金侯圓圓王鳴泉
中國纖檢 2015年6期
韓金+侯圓圓+王鳴泉

引言
1.棉花產量統計何其難。數學界有一個哥德巴赫猜想,棉花界也有一道難解的數學題,國家的棉花年產量究竟有多少?新疆的棉花產量究竟有多少?這道難題困擾著棉花界的人士。
中國的棉花總產量從500萬噸到800萬噸跨度不斷變化,但確切數字是多少,我們有多種答案,就拿2014棉花年度為例,生產、收購、加工等環節基本結束,我們仍然困擾著這個答案。
2.統計失真問題源于樣本和方法。棉花產量統計失真,主要源于統計口徑與統計方法。棉花產量究竟是多少?對于這個問題權威部門也沒有一個統一的說法,國家統計局、中國棉花協會、發改委、農業部、美國農業部(USDA)、國際棉花咨詢委員會(ICAC)等不同的渠道有不同的版本發布。以2014年新疆棉產量預測,從367萬噸到450萬噸之間有多個版本和渠道發布,跨度較大,不但業外困惑,業內也是眾說紛紜。
統計失真問題,既有樣本影響因素,也有統計口徑因素,還有人為因素,當然統計方法也非常重要。
3.數據建模解決棉花產量精確統計問題。古訓云:工欲善其事,必先利其器。解決中國棉花產量問題,要充分相信科學、充分利用科技手段。為解決棉花產量的精確統計,特別是新疆棉花產量的精確統計與預測問題,作者所在協會的成員單位北京中棉機械成套設備有限公司重點投入搭建了“全國棉花加工檢驗綜合數據平臺”,從2013年度監測新疆阿克蘇,到2014棉花年度在新疆全區推廣應用。該系統精確統計每一包產量,每一包棉花都有自己的條碼編號,每一個加工廠精確統計,每個地區涵蓋所有加工企業。
本文作者韓金在棉花加工領域從事多年研究,中國人民大學侯圓圓是統計方面的專家,王鳴泉是中國聯通大數據分析方面的專家,三人一塊共同對棉花采集數據進行了建模分析。
第一節:數據來源
一、技術基礎
由于數據平臺系統做到了全覆蓋,因此每日加工量匯總數據真實,根據已發生的記載數據,預測未來日期的加工量,從而達到分析預測整個新疆的棉花總產量,有著很重要的研究價值和社會價值,本文就從新疆棉花產量的每日加工量統計,通過建立數據模型,來分析預測新疆2014年度棉花總產量。
目前已經實現了棉花加工、檢驗數據信息化。每包棉花依據加工數據編成條碼,作為棉包身份證進行統計。專業纖檢機構逐包HVI儀器化檢驗,形成公檢電子證書。
新疆所有棉花加工企業的加工、檢驗數據的采集、存儲、管理及業務操作都由北京中棉機械成套設備有限公司的棉包條碼信息管理系統實現。
二、數據平臺和模型作用
1.以棉包條碼信息系統作為數據終端,通過網絡技術實現數據集中存儲形成數據平臺,實現數據價值。準確采集全國收購、加工、檢驗、批次數據,為政府部門、行業協會等提供產量等宏觀數據服務。
2.圍繞新疆棉花產量統計難題,各種數據滯后,調控、經營決策不合理的現狀,建立科學合理的數據模型。形成集加工、檢驗、倉儲、物流、紡織等各環節信息支撐系統,實現棉花全產業鏈信息化。
3.建立棉花現代物流體系需要的信息流,圍繞中央一號文件要求的農產品價格形成機制試點,形成新疆目標價格補貼試點按照產量發放補貼的依據。
4.以平臺為中心圍繞棉花產業鏈開發應用服務,與現有交易平臺形成對接,按照詳細質量指標實現精準購棉,建立適合國產棉使用的計算機輔助配棉系統,實現紡織企業國產棉精細化用棉。
三、數據平臺現狀
數據平臺平穩運行。2014年9月1日建成全疆數據采集系統,覆蓋全疆846家棉花加工廠的1118條生產線,做到了新疆400型加工廠全覆蓋,新疆所有規劃內400型棉花加工全部使用采集終端,采集終端成為棉花加工企業的生產管理系統。由于2014年新疆采取棉花入庫公檢模式,該系統又作為預約終端,實現全部新疆加工企業預約入庫管理系統的一部分,成功采集企業的預約入庫量。加上該系統是儀器化公證檢驗數據下載和傳輸的工具,又采集加工企業加工數據對應的檢驗數據。因此數據平臺涵蓋從生產到入庫所有環節的加工數據、入庫數據、檢驗數據。
本分析僅從采集到的加工數據,通過建模分析,得出預測和分析結論。
四、數據收集
本數據建模采用的數據來源,全部來自2014年9月1日建成的全國加工檢驗綜合數據平臺系統,系統覆蓋了全疆846家400型棉花加工廠的1118條生產線。由于生產線作業采集,企業全覆蓋,因此數據來源真實可靠。
由于樣本不包含200型小廠,因此根據采集樣本得出的總預測產量理論上會小于實際新疆總產量。為保證數據真實,我們抓取了數據平臺的截圖來證明數據來源(見圖1)。
圖1 ? ?產量統計系統登錄窗口
第二節:數據的整理和顯示
一、數據整理
由于數據分收購數據、加工數據、檢驗數據、入庫數據幾類,為便于分析,我們僅以全新疆加工數據為樣本進行分析。
我們截取匯總了從2014年9月18日開始加工的每日新疆加工日增量更新數據見表1,來進行決策和預測分析。
二、數據顯示
1.直方圖
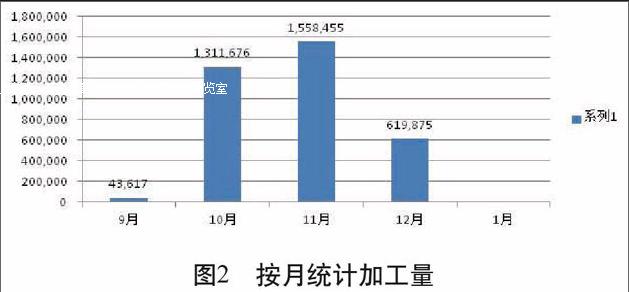
按照月份進行分組,計算組距,如圖2所示。
圖2 ? ?按月統計加工量
從圖2中可以得出一些結論:(1)2014年新疆從9月18日開始加工。(2)加工高峰期主要集中在10月和11月。(3)觀察數為91個,日最大加工量體現在10月30日84180噸,日最小加工量體現在9月20日121噸,平均日加工量38831噸。(4)截至發稿之日12月18日,累計匯總加工量為3533626噸,即新疆產量已經達到353萬噸,占國家統計局統計發布產量的96%。(5)截至發稿之日12月18日,從12月14日日加工量跌破3萬噸后,連續4天檢測平均加工量仍維持2.6萬噸,說明加工進入尾聲,增量下降,總量增加。
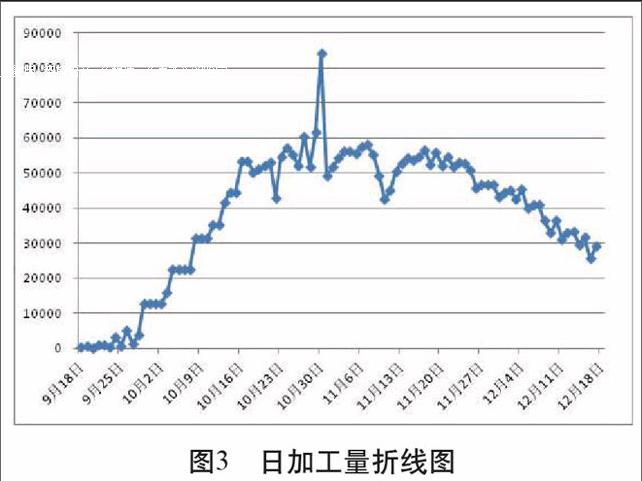
2.折線圖
圖3 ? ?日加工量折線圖
通過圖3的折線圖,可以清晰地揭示出每日加工量的增量在時間序列上的變化規律,通過早期的數據分布規律,我們可以依據時間序列變量及日加工量之間的對應關系,對未來時間的數據進行預測分析,這也是我們課題研究的意義所在。
對異常數據進行適當削峰處理,可以得到圖4 曲線,其中M代表月份。
第三節:數據建模
根據圖3折線圖和圖4平滑圖,我們認為日增量曲線變化規律符合二次曲線,現將時間(excel圖標的水平軸)作為x,例如2014年9月8日就是1,2014年9月9日就是2,以此類推。x2就是x的平方,產量(excel圖標的縱軸)作為y。
函數形式假設為二次型y=a0+b1x+b2x2,看是否通過檢驗。
我們分別采用excel自帶的數據分析工具,先對采集數據進行描述性統計再進行檢驗假設,限于篇幅,假設檢驗步驟省略。從回歸假設檢驗看,回歸模型的R方達到了0.906,ANOVA分析也表現顯著,因此模型的擬合效果良好。再看系數,所有參數系數都非常顯著,因此該二次模型成立。
第四節:數據分析
依據上述模型,根據時間軸與產量作散點圖,棉花產量隨時間遞減,加上上述檢驗假設,模型的擬合曲線與真實增量的散點圖如圖5所示,可以看出模型的擬合效果良好,數據符合二次曲線。
圖5 ? ?二次函數散點曲線圖
根據趨勢線得出曲線方程:y=ax2+bx+c
依據實際加工量進行二次函數運算,得a=-24.07,b=2585.054,c=-12540.375,該模型表達式為y=-24.07x2+2585.054x-12540.375。為此,欲求新疆棉花總產量,首先需要預測出以后各期增量。因此為x賦值92、93、94……并帶入到二次函數中求解產量y,計算的終止條件是y≤0。
用以上方式,算出增量第102天時增量為正,第103天增量為負。
x=102時(即2014年12月28日),解得y值:y=-24.07x2+2585.054x-12540.375
=-24.07×1022+2585.054×102-12540.375=710.853。
略去小數,x=102時,y=711。
數據列表如表2,累計匯總為3660124噸。
在我們截稿之際,恰逢國家統計局2014年12月17日統計發布了新疆棉花產量367.7萬噸。此二次曲線數學模型計算與國家統計局的發布數據基本吻合。
第五節:數據修正
我們依據上述模型對數據進行擬合,發現從9月18日到11月18日期間即前60天預測值與實際值重合度高,從11月18日后,預測值在實際值下方整體偏下,即實際值略高于預測值,而且隨著時間推移,偏離度逐漸加大,進一步抓取11月18日到12月18日之間30天的數據作散點圖(見圖6)分析。
圖6 ? ?30天實際加工量散點圖
該散點圖特質除了具備二次曲線下降的趨勢外,是否更符合線性關系呢?
數據模型的最關鍵點在于找到二次曲線與線性回歸的拐點,依據線性假設和回歸分析,根據趨勢,我們做線假設,假設線性方程:y=ax+b。
利用excel表格中數據分析工具,帶入11月11日到12月18日共38天時間的實際加工量,進行回歸函數運算,得出a= -663,b=92008,該模型表達式為y = -663x + 92008。
為此,欲求新疆棉花總產量,首先需要預測出12月18日以后的每日增量。因此為x賦值93、94……并代入到二次函數中求解產量y,計算的終止條件是y≤0。
當x=139時,y=-149,即第139天增量為負值,也就是說加工到第139天結束,對應加工日期為2015年2月2日,預計整個加工量為4270343噸(見表3)。
表3 ? ?線性回歸函數
第六節:決策結論
427萬噸的數學模型預測產量,我們認為有其合理性。考慮到樣本的覆蓋性,我們增加考慮因素,影響產量變動的主要因素有:
1.未被統計在內的200型小包棉產量。考慮到樣本沒有覆蓋目標價格改革試點實施前,東疆哈密和吐魯番地區棉花成熟早,主要用于絮棉、民用棉的現狀,該區域收購早,加工也早,大部分用的是200型小包銷售,因此樣本不包含小包型產量,預計有2萬~3萬噸左右。
2.未被覆蓋的400型大包未參與公檢部分。因為目標價格補貼政策出臺較晚,部分紡織自用棉加工企業沒有入庫參與公檢,但由于系統包含了紡織自用棉的統計,盡管不參與入庫公檢,但不影響數據采集,數據系統中加工量的統計還是完整的。
3.入庫數量和檢驗數量佐證模型。截止到12月18日,加工分會成員單位北京中棉機械成套有限公司統計新疆全疆皮棉的加工量是353萬噸,從我們掌握的新疆入庫數據看,截至同日新疆棉花入庫336.5萬噸,這和我們模型計算的情況是吻合的。收購情況也符合預測,整體看新疆南北疆采摘基本結束了,無論加工還是入庫,地方上下降明顯,明顯結束早于上年同期,突出表現在兵團企業仍在持續,與目標價格補貼兵地之間籽棉流動減少有關。同期檢驗量是309.5萬噸,符合加工量大于入庫量,入庫量大于檢驗量的規律。
分析結論
綜上,我們根據數學模型計算的新疆棉花產量為427萬噸左右。考慮調整因素,預計新疆產量為430萬噸左右。
數據模型的好處在于,如果能夠累計2~3年以上數據,基本可以得出比較精確的函數關系,那么就可以根據早期的加工量,分析預測全年加工量,例如根據2015年10月的加工規律,預測2015年度的棉花產量,從這層意義上,經濟價值很大。
(作者單位:韓金,中國棉花協會加工分會;侯圓圓,中國人民大學;王鳴泉,中國聯通)
猜你喜歡
國畫家(2022年2期)2022-04-13 09:07:46
礦山安全信息(2022年40期)2022-04-07 02:16:52
今日農業(2021年14期)2021-11-25 23:57:29
四川文學(2021年4期)2021-07-22 07:11:54
石油與天然氣地質(2021年1期)2021-02-22 14:14:44
今日農業(2020年20期)2020-11-26 06:09:10
中國果業信息(2019年10期)2019-11-13 01:21:34
聚氯乙烯(2018年9期)2018-02-18 01:11:34
絲綢之路(2014年9期)2015-01-22 04:24:46
兒童與健康(2011年4期)2011-04-12 00:00:00
