Ward系統聚類法在農村居民收入情況分析中的應用研究
2015-03-23 07:41:16陳江麗
大理大學學報 2015年6期
陳江麗
(臨滄師范高等專科學校信息科學與技術系,云南臨滄 677000)
Ward 系統聚類法是一種聚類分析方法。聚類分析是根據分類樣本數據特征的相似性,按照一定的規則將樣本分成若干類,使同一類中的樣本之間具有高相似度,而不同類的樣本間高度相異〔1〕。聚類分析已經廣泛應用于數據分析、模式識別和圖像處理等許多領域。
聚類分析中主要通過距離來度量樣本間的相似性,可利用系統聚類法對樣本進行聚類。聚類開始時將n 個樣本各自作為一類,并計算樣本間的距離、類與類之間的距離。然后將距離最近的兩類合并為一個新類,計算新類與其它類間的距離。重復將距離最近的兩類進行合并,直至所有的樣本合并為一類。其中類與類間距離的定義可采用7 種不同的方法,分別是最短距離法(single)、最長距離法(complete)、中間距離法(median)、重心法(centroid)、類平均法(average)、可變類平均法(weighted)和離差平方和法(ward)〔2〕。文中主要研究Ward 系統聚類法及其在農村居民收入情況分析中的應用。
1 Ward系統聚類法
Ward 系統聚類法是指利用離差平方和法計算距離的一種聚類方法,類中各元素到類重心(即類均值)的平方歐式距離之和稱為類內離差平方和。假設類GK與GL聚成一個新類GM,則GK、GL和GM的類內離差平方和分別為公式(1)、(2)、(3)〔3〕。
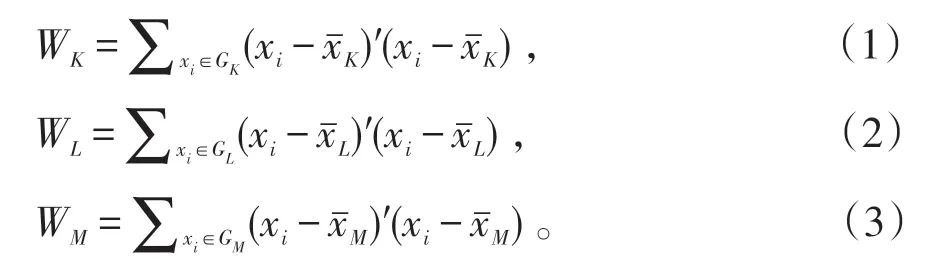
當 GK和 GL合并成新類 GM時,WM> WK+WL,即類內離差平方和增大。若GK和GL距離較近,則離差平方和增加的值應該較小。因此GK和GL的平方距離根據公式(4)計算。

因此,離差平方和法是將方差分析的思想應用于分類中,使同一類中的離差平方和小,表示樣本間的相似度高;而不同類間的離差平方和大,則樣本間的相似度低〔4〕。通過離差平方和的大小來度量樣本間的相似性,符合聚類分析的要求。
2 Ward系統聚類法的Matlab實現
利用Matlab 相關的系統聚類函數進行聚類分析,主要分為以下4個步驟。
2.1 樣本預處理為了保證分析結果的準確性,需要對樣本數據進行一些預處理,如平滑處理、標準化變換和極差歸一化變換等。在實際應用中,可根據數據特征進行選擇處理。一般較常用進行數據的標準化變換,主要針對多元數據中各元間的量綱和數量級不一致的情況。Matlab提供了常用的zsocre函數進行數據的標準化處理。
2.2 計算樣本間距離聚類開始時,需要計算n個樣本間的距離,距離的計算方法包括明氏距離、蘭氏距離、馬哈拉諾比斯距離和斜交空間距離等。其中最常用的是明氏距離中的歐式距離。第i個樣本Xi和第j 個樣本Xj之間的歐式距離計算如公式(5)所示。

Matlab 中使用pdist 函數計算樣本間的歐式距離,調用格式為y=pdis(tX)。其中X 為輸入的樣本矩陣,每一行對應一個樣本,每一列對應樣本的一個分量。輸出y 是一個包含n(n-1) 2 個元素的行向量,分別對應第i 個(其中i=2,3,…,n)和第j 個(其中j=1,2,…,n-1)樣本間的距離。
2.3 利用Ward 系統聚類法創建聚類樹通過Ward 系統聚類法進行聚類是聚類分析中的關鍵環節。通過創建系統聚類樹可以完整地反映聚類的過程。Matlab工具箱中提供了linkage函數創建系統聚類樹,調用格式為Z=linkage(y,‘ward’)。其中輸入參數y是上一步計算的樣本間距離,‘ward’表示使用離差平方和法進行系統聚類。輸出參數Z是創建的系統聚類樹,包含(n-1)×3 個元素的矩陣,它的每一行對應一次聚類,其中前兩個元素為聚類的兩個類編號(初始類編號為1~n,每聚成一個新類,類編號依次增加1),第3個元素為聚類時的距離。
創建好的系統聚類樹可利用Matlab工具箱中的dendrogram 函數生成系統聚類樹形圖,使聚類過程和結果更加清晰直觀。聚類樹形圖由許多連接聚類對象的倒U形線組成,線的高度表示聚類距離。樹形圖中的葉節點對應原始聚類樣本。
2.4 計算系統聚類樹的不一致系數系統聚類樹的不一致系數可用來確定最終的分類個數。在保證最終聚類個數盡量少的前提下,可通過不一致系數的變化確定最終的分類個數。若不一致系數較上次的變化越大,則聚類效果越差。
系統聚類樹的不一致系統可使用Matlab 工具箱中的inconsistent 函數進行計算。調用格式為Y=inconsistent(Z),輸入參數Z是由linkage函數創建的系統聚類樹,輸出參數Y 是一個包含(n-1)×4 個元素的矩陣,其中的第4 列為每一次聚類的不一致系數。
2.5 創建聚類結果根據創建好的系統聚類樹,以及由不一致系數確定的聚類個數,創建聚類,并輸出聚類結果,完成聚類過程。
創建聚類可利用Matlab工具箱中的cluster函數實現,其調用格式為T=cluster(Z,‘maxclust’,n),輸入參數Z是由linkage函數創建的系統聚類樹,創建一個最大聚類數為n 的聚類,輸出參數T 為每一個樣本的所屬的類序號。
3 利用Ward系統聚類法分析農村居民收入情況
中國作為一個農業人口和農民經濟占主體的國家,農民收入水平及其分配狀況直接關系擴大內需政策的落實,關系國民經濟持續快速增長,關系國民經濟發展戰略目標的實現。由于地域差異和經濟基礎等因素的影響,農民人均純收入在地區間形成顯著的差異。根據各地區農村居民人均純收入的構成情況,包括工資性收入、經營性收入、財產性收入、轉移性收入等部分,如表1 中列出2012年全國31個省、市、自治區和直轄市的農村居民人均純收入數據,利用Ward 系統聚類法進行聚類分析,將地區按收入情況劃分為不同的類,根據同一類地區間農村居民收入情況的相似性,不同類地區間收入情況的差異性,為地區經濟分析與研究提供重要依據,對經濟政策和扶持的制定提供科學的指導。
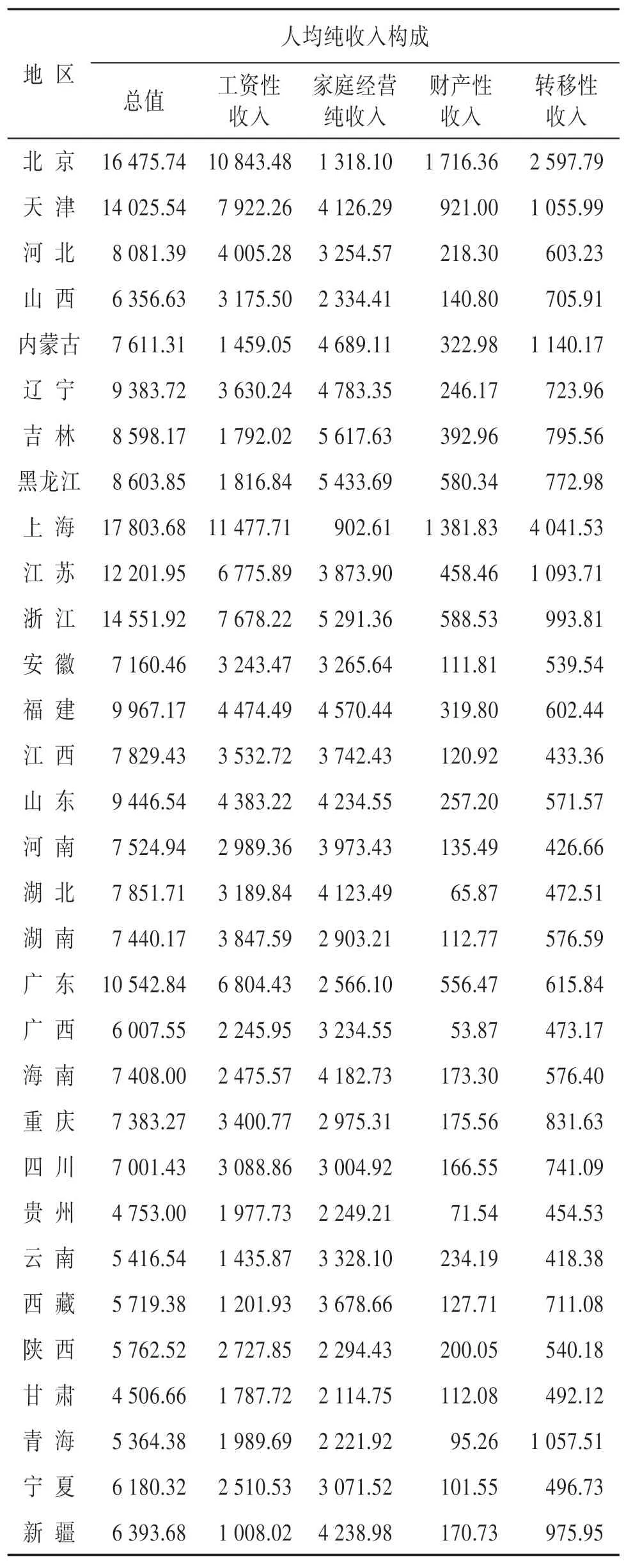
表1 2012年各地區農村居民人均純收入
3.1分析步驟及結果
1)讀取表1 中的工資性收入、家庭經營純收入、財產性收入和轉移性收入4 個主要變量數據放入矩陣 X 中,X 就是一個 31×4 的矩陣。讀取表 1 中的地區數據放入矩陣city 中,city 是一個包含31 個元素的列向量。
2)X=zscore(X);%數據標準化(減去均值,除以標準差)。
3)y=pdist(X); %計算樣品間歐氏距離,y為距離向量。
4)Z = linkage(y,‘ward’); % 利用離差平方和法創建系統聚類樹。
5)H = dendrogram(Z,0,‘orientation’,‘right’,‘labels’,city);%繪制聚類樹形圖,方向從右至左,顯示所有葉節點,用城市名作為葉節點標簽,葉節點標簽在左側,返回線條句柄H。創建的系統聚類樹樹形圖。見圖1。
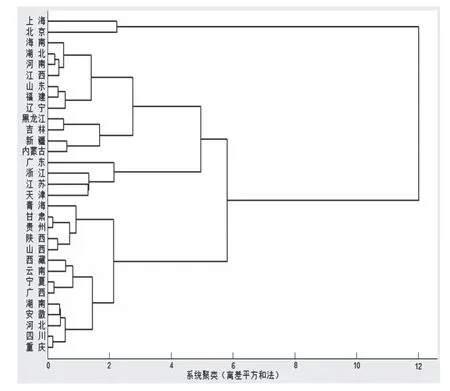
圖1 2012年各地區農村居民人均純收入聚類樹形圖
6)inconsistent 0=inconsistent(Z);%計算不一致系數,計算結果如下所示。
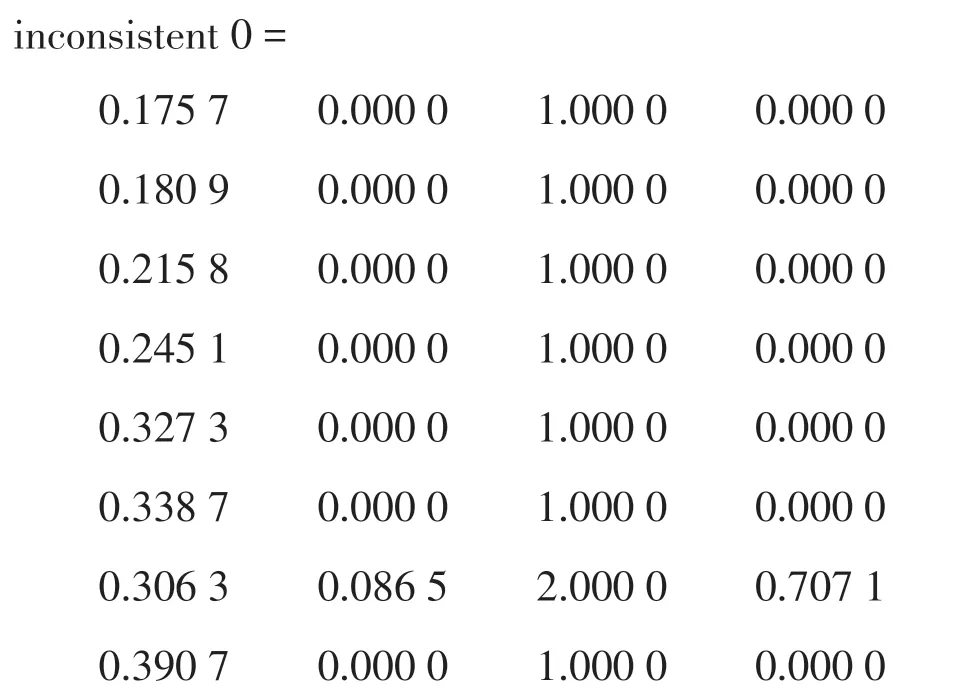
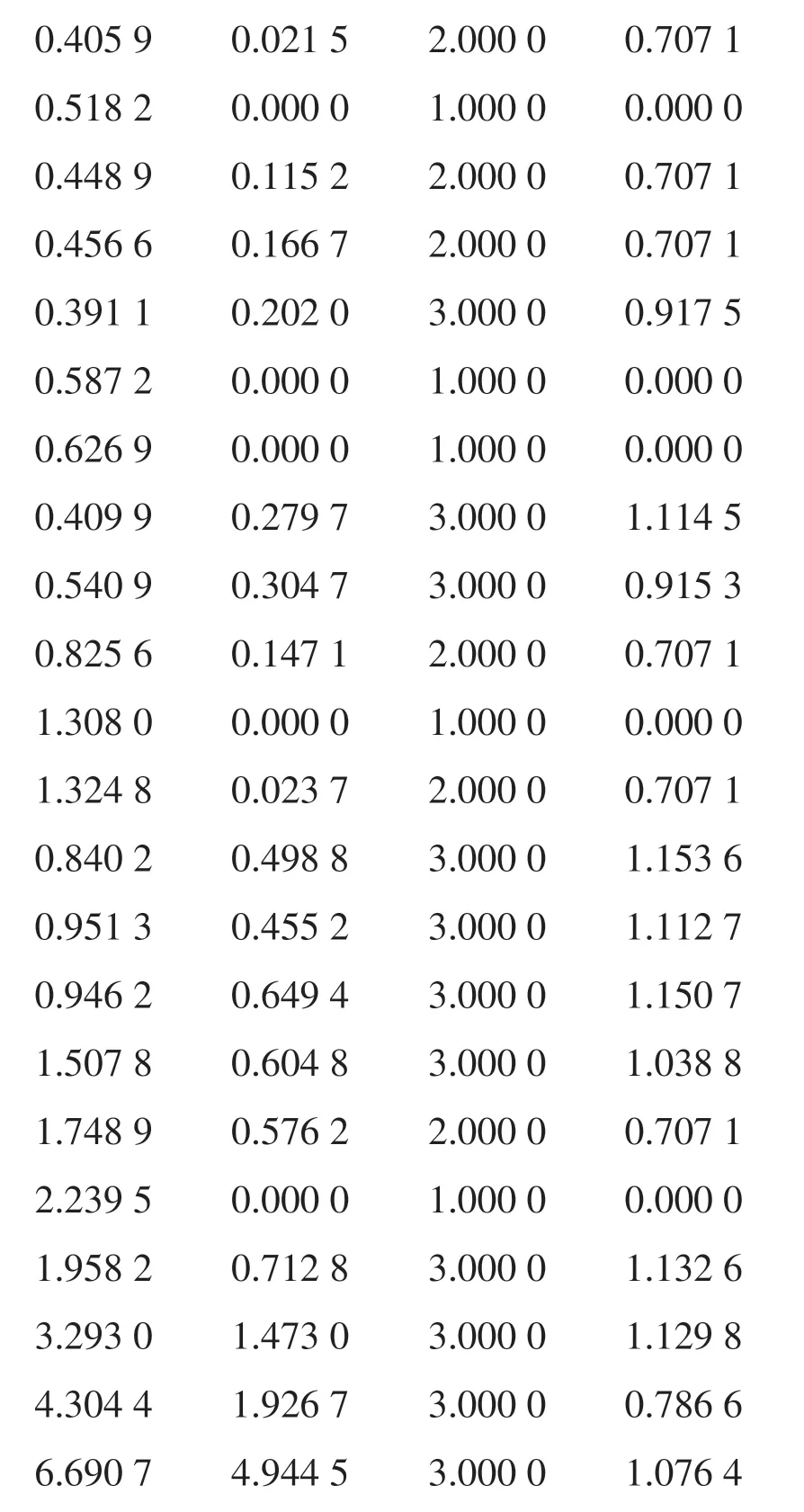
7)inconsistent 0矩陣中的第4列為不一致系數,通過觀察和比較每次聚類過程的不一致系數。考慮倒數第4 和5 次聚類的不一致系數的變化,不一致系數大幅增加1.132 6,說明倒數第5 次的聚類效果是比較好的,對照圖1的系統聚類樹形圖可看出,此時樣本被劃分為4類。即可認為聚為4類是最合適的。
8)T=cluster(Z,‘maxclust’,4);%由系統聚類樹創建聚類,最終聚為4類。
9)obslabel(T==1);%查看第1 類所包含的地區,結果如下。
第1類地區為:天津、江蘇、浙江、廣東。
10)obslabel(T==2);%查看第2 類所包含的地區,結果如下。
第2 類地區為:內蒙古、遼寧、吉林、黑龍江、福建、江西、山東、河南、湖北、海南、新疆。
11)obslabel(T==3);% 查看第 3 類所包含的地區,結果如下。
第3 類地區為:河北、山西、安徽、湖南、廣西、重慶、四川、貴州、云南、西藏、陜西、甘肅、青海、寧夏。
12)obslabel(T==4);% 查看第 4 類所包含的地區,結果如下。
第4類地區為:北京、上海。
3.2 分析結論利用Ward 系統聚類法對2012 年全國31 個地區的農村居民人均純收入情況進行聚類分析,最終劃分為4類地區。從結果可以發現,不同地區的農村居民收入水平與地理位置、資源、人口、經濟發展水平等方面有相應的關系。
第1類中,天津是中國4 個直轄市之一,是首都北京的門戶,中國國家中心城市。江蘇是我國著名經濟大省。浙江是中國經濟比較發達的沿海對外開放省份,以民營經濟的發展帶動經濟的起飛。廣東是中國經濟總量最大和發展最快的省份。4個省的城鎮企業、民營企業較多,政府扶持,發展良好。故這4個省的農村居民家庭人均純收入位居全國前列〔5〕。
第2類中,遼寧、吉林、黑龍江3省土地肥沃,水資源豐富,農業產值和農民收入較高。山東、河南是我國的農業大省,交通發達,使得經濟迅速發展,農村居民生活水平進一步提高。福建、江西、湖北、海南是一個雨量豐沛的地區,氣候溫和,適合農作物生長,農業發展較快,農村居民家庭人均純收入相對較高〔6〕。內蒙古和新疆兩省國家扶持力度大,財政支出持續向民生傾斜,農村居民家庭人均純收入相對較高〔7〕。
第3 類中的14 個地區農村居民家庭人均純收入較低,且多數是西部地區,貴州、云南等屬于丘陵地帶〔8〕。陜西、甘肅的土地資源中旱地占主要部分〔9-10〕。青海、西藏屬高原地帶,由于受地理位置和氣候條件的影響,農業產值較低,農村居民家庭人均純收入較低。
第4 類中,北京是中國的首都,也是中國的政治、文化、科教和國際交往中心,中國經濟、金融的決策和管理中心〔11〕。上海是中國的經濟、交通、科技、工業、金融、貿易、會展和航運中心〔12〕。不僅如此,旅游業等副業的繁榮也是農村農民高收入的原因,因而農村居民家庭人均純收入位于全國最前列。
因此,分析結果可以為進一步研究影響收入水平的因素和提高不同地區農民收入水平的措施提供科學合理的依據。
4 結語
利用Ward 系統聚類法根據數據特征的相似性進行分類的特點,對不同地區按農村居民的人均純收入情況進行聚類,劃分為不同的區類,為深入研究和政策的制定提供決策支持,在現實環境中具有較高的應用價值。
〔1〕Han Jiawei,Kamber Micheeline,Pei Jian.數據挖掘概念與技術〔M〕. 范明,孟小峰,譯. 北京:機械工業出版社,2010:10-100.
〔2〕周濤,陸惠玲.數據挖掘中聚類算法研究進展〔J〕.計算機工程與應用,2012(12):100-111.
〔3〕于秀林,任雪松.多元統計分析〔M〕.北京:中國統計出版社,2008:30-50.
〔4〕鄭紅英. 數據挖掘聚類算法的分析和應用研究〔D〕. 重慶:重慶大學,2002.
〔5〕官琳琳,門可佩.中國農村居民家庭人均純收入的聚類分析〔J〕.安徽農業科學,2009(31):49-51.
〔6〕陶兢強,許能銳.中國農村居民純收入聚類分析〔J〕.江西農業大學學報:社會科學版,2010,9(2):42-48.
〔7〕劉鑫鑫.中國農村居民收入區域差距研究〔D〕.長春:吉林大學,2010.
〔8〕楊小偉.甘肅省不同地區農村居民收入差距研究〔D〕.蘭州:蘭州大學,2012.
〔9〕萬波琴.陜西農村居民收入差距研究〔D〕.西安:西北大學,2010.
〔10〕楊文俊.陜西省農村居民收入差異分析〔D〕.西安:長安大學,2011.
〔11〕劉瑜.我國農村居民收入構成研究〔D〕.哈爾濱:黑龍江大學,2014.
〔12〕楊威.中國農村居民收入區域不平衡研究〔D〕.廣州:暨南大學,2013.
猜你喜歡
今日農業(2022年1期)2022-11-16 21:20:05
工業設計(2022年8期)2022-09-09 07:43:20
今日農業(2021年21期)2022-01-12 06:32:04
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
活力(2019年21期)2019-04-01 12:17:48
中國公路(2017年16期)2017-10-14 01:04:28
家庭影院技術(2017年9期)2017-09-26 03:41:45
