基于主動學習和自學習的噪聲源識別方法
2015-04-14 12:27:58高志華賁可榮
計算機工程與應用 2015年1期
高志華,賁可榮
海軍工程大學 計算機工程系,武漢 430033
1 引言
潛艇聲學故障識別是根據影響潛艇隱身性能的振動異常殼體部位向內定位出倉內設備或區域(即查找內部主要噪聲源),從而提供聲學故障報警和修復建議[1]。因此聲學故障識別研究對于提高潛艇隱身性能十分關鍵,也是目前研究熱點之一。潛艇中的故障會帶來不正常的機械振動,從而引發異常的聲響。由于振動參數比起其他可從潛艇中獲取的狀態參數更能直接、快速、準確地反映機器運行狀態,所以振動噪聲信號一般作為對機組狀態進行監測與診斷的主要依據。實際應用中很難獲取到描述各種故障(工況)狀態的噪聲源樣本,即可以采集到大量的機械噪聲數據,但對這些數據進行標注需要專家參與且要耗費大量時間且代價昂貴。由于存在可用于學習的已標注噪聲源樣本嚴重缺失的問題,因此研究小樣本條件下潛艇的機械噪聲源識別具有重要意義。
在擁有少量有標識樣本的情況下,如何利用大量的未標識樣本來改善學習器性能成為當前機器學習研究中最受關注的問題之一[2]。研究表明,對于訓練樣本的精確標記不但需要該領域中大量的專家參與,并且標記樣本花費的時間是其獲取時間的10倍以上[3]。這種現實使傳統的機器學習算法無法得以有效應用,原因在于監督學習需要大量標記樣本對分類器進行迭代訓練,否則根據 PAC(Probably Approximately Correct)學習理論,算法的泛化性能無法有效提高[4]。
在這種情況下,半監督學習和無監督學習方法應運而生并迅速發展,成為解決上述問題的重要技術。半監督學習中的主動學習技術利用一個好的樣本選擇策略對眾多未標注樣本進行選擇標注,使之能夠加入到訓練集中進行訓練[5]。本文提出一種基于主動學習和自學習的SVDD(Support Vector Data Description)噪聲源識別方法,該方法首先采用不確定性采樣策略從大量無標記樣本中選擇信息量大的樣本交給專家進行標注,然后對未標記樣本加以利用,選出部分有代表性的樣本進行自動標注,進一步將通過主動學習和自學習標記后的樣本加入到訓練集中對分類器SVDD進行循環訓練,以實現在最少標記樣本代價下最大程度地提高分類器的性能。
2 基于主動學習和自學習SVDD分類算法
2.1 支持向量數據描述方法
支持向量機(SVM)方法具有良好的理論性質,如以統計學習理論為基礎的泛化能力,以核方法引入的非線性機制,以及凸優化理論保證的全局最優解性質等[6]。與已有的機器學習方法(如神經網絡)相比,SVM更易于使用,因此在許多領域得到了廣泛應用。支持向量數據描述方法(SVDD)靈感來自于支持向量機,是一種采用直接尋找封閉區域分類的單類(one-class)分類方法[7]。Vapnik認為如果樣本的數據量比較小時,采用直接尋找封閉區域的方式來分類比估計概率密度的方法更為有效[8]。
給定數據集{xi}(xi∈Rn;i=1,2,…,N),通常情況下,即使排除了偏遠的樣本點,數據依然不會呈現球狀分布。為了使算法適用于更廣泛的領域,SVDD采用同SVM方法類似的核函數方法,把樣本變換到更高維的特征空間,假設非線性映射?(x)將數據映射到高維特征空間。奇異的數據點應該位于超球體的外面,為了減少奇異點的影響,引入松弛因子ξi≥0(即允許存在錯誤)。為訓練樣本建立一個最小超球,設超球球心和半徑分別為a和R,則廣義描述模型即為如下凸二次規劃:

約束條件為:

其中C是一個常數,控制對錯分樣本的懲罰程度。將式(2)代入式(1)引入Lagrange系數后優化方程變為:
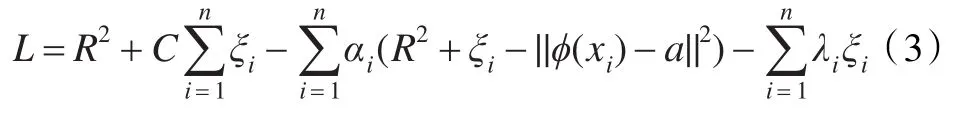

圖1 基于主動學習和自學習的學習系統框圖
對于任一支持向量xs,R由下式給出:

正定核或Mercer核都可以用來作為SVDD的核函數,本文選用高斯核:
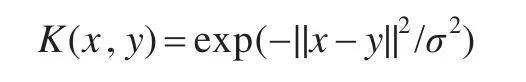
本文將one-class分類方法SVDD擴展至多類分類問題中。初始訓練時為每一個模式類構建一個超球,使得該超球體內包含該模式類別中的所有已標注樣本。當大量未標注樣本載入后,選擇其中最有“價值”的樣本進行標注,并將最終選擇的樣本加入到訓練集中進行學習以更新分類模型。在選擇最有“價值”樣本的過程中,既考慮到樣本的不確定性,又兼顧樣本的代表性,采用主動學習技術和自學習相結合的方法對樣本進行標注。
考慮到構造訓練樣本集的標注負擔,在算法設計時主要從兩個方面出發:(1)對于選出的用于人工標注的樣本必須是對于當前的分類模型而言最具信息量的,以最大化人工標注的效率;(2)對于剩余的大量未標注樣本所包含的信息,在不增加人工標注負擔的情況下,要進一步加以利用。基于以上兩點考慮,本文提出了一種基于不確定性樣本選擇和代表性樣本選擇相結合的SVDD分類算法。其中,最具信息量的樣本采用主動學習技術選取,提供給專家進行手工標注。在剩下的未標注樣本集中選擇有代表性的樣本進行自動標注,進一步對訓練樣本集進行補充更新。本文提出的基于主動學習和自學習的SVDD分類系統,如圖1所示。
該學習系統包括兩個部分:學習引擎使用SVDD作為基準學習算法得到分類器,對訓練集進行訓練,對測試集進行測試。選擇引擎綜合考慮未標注樣本集中樣本的不確定性和代表性兩個因素,選擇最有“價值”的樣本進行標注,并將最終選擇的樣本加入到訓練集中進行學習以更新分類模型。算法在分類器達到指定分類率或指定迭代次數時終止。
2.2 不確定采樣的主動學習
主動學習(active learning)技術可以解決標注困難帶來的有限樣本情況下的分類問題,在主動學習中,學習器主動選擇那些對于當前分類模型最有價值的樣本進行標注,并將這些帶有類別標號的樣本添加到訓練樣本集,對分類模型進行重新訓練。通過迭代的方式,對分類模型進行更新[9]。采樣策略是主動學習技術的核心,可以分為3種:基于不確定性的采樣策略、基于版本空間縮減的采樣策略和基于誤差縮減的采樣策略[10]。
基于不確定性的采樣策略是適用性最廣的一類采樣策略,它可以有效減少人類專家的工作量,提高分類器的分類精確度和泛化能力,是目前研究最為充分的采樣策略[11]。這種采樣思想雖然適用于大多數分類模型,但在與不同分類模型時,算法實現方式各不相同。本文選擇的是SVDD這樣一種采用封閉區域分類的分類模型,采樣策略使用樣本與區域描述邊界之間的距離作為計算形式,選擇與落入單類描述邊界之外或多類描述區域重疊的樣本作為最不確定的樣本。
對于多類分類問題,SVDD對每一個目標類訓練一個相應的超球,假設有m類,每個類分別被標記為ωi(i=1,2,…,m)。將屬于類別ωi的訓練樣本記為子集Di,用Di訓練一個SVDD分類器,并計算出相應的中心ai和半徑Ri。設未標注樣本集為U={x1,x2,…,xn},Y={1,2,…}為可能的類別標號,ai為由已標記樣本集確定的m個模式類的SVDD超球球心。未標注樣本xs(xs∈U)到球心ai的距離為:

當m個最小超球確定之后,它們之間的位置也隨之確定。理想的情況是超球之間彼此獨立,但實際上超球之間完全有可能出現交疊的情況,因此新樣本xs與超球之間的位置關系有3種:(1)xs落入某一個超球中;(2)xs落入兩個或多個超球的交疊區域;(3)xs落在所有超球之外。
情況(1)說明未標注樣本xs同時落在兩個(或更多)已知類別的封閉決策區域之內,即被標記了多個類別標簽。情況(3)說明未標注樣本xs落在所有已知類別的封閉決策區域之外,即被判決為不屬于任何已知類別。這兩種情況都說明了樣本xs不能被已有的學習模型預測所屬類別,樣本所屬類別具有不確定性,需要交給專家進行人工標注。
2.3 代表性樣本的自學習
在大量未標注樣本集中提取不確定性樣本交由專家標注之后,可以進一步從剩下的未標注樣本集中提取部分確定的且具有代表性的樣本進行自動標注,然后加入到訓練樣本集中,用于提高分類模型的泛化性能。自學習是半監督學習中一個常用的技術[12]。在自學習中,添加到訓練樣本集里的樣本的標號不是由用戶進行人工標注,而是由當前的分類器預測得到的。從直觀上說,如果選擇那些在當前分類器下分類結果最明確的樣本進行自學習,引入錯誤標號的概率是最小的。但是從樣本所包含的信息量這個角度來說,這些分類結果最明確的樣本所包含的信息量是非常低的,對于當前分類面的影響極小。因此,將這些樣本加入到訓練樣本集,對分類模型的影響很小,同時反而增加了分類器訓練時的計算負擔。為解決以上矛盾,本文通過設置閾值來提高自學習選出樣本的信息量。
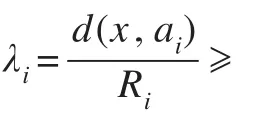
2.4 ALSL-SVDD算法描述
假設ω為已知模式類別,將訓練樣本集和未標注樣本集分別記為L和U,其中L是在初始分類時,由專家人工標注的少量樣本。
步驟1用訓練樣本集L采用SVDD算法訓練出ω個超球狀封閉決策區域。
步驟2導入未標注樣本集U。
步驟3用訓練生成的ω個SVDD分類器對未標注樣本集U進行預測:
(1)采用2.2節中的不確定樣本選擇的主動學習策略從U中選出M個樣本,所構成的集合記為SAL,由專家對SAL中的樣本進行人工標注;
采用2.3節中的代表性樣本的自學習方法從剩余的未標注樣本集合U-SAL中選出N個樣本,所構成的集合記為SSL,并記錄其類別標號,即進行樣本的自動標注。
步驟4更新訓練樣本集:Lnew=L∪(SAL∪SSL)。
步驟5更新分類模型:用訓練樣本集Lnew重新訓練SVDD分類模型。若達到指定分類精度或迭代次數,則算法停止;否則轉至步驟2。
3 實驗及相關分析
3.1 實驗數據
實驗使用1∶1實體艙段模型構建仿真環境,在艙段內安裝了泵、電機、激振器3種設備各一個,3種設備各自有不同的工作模式,泵可以工作在關閉、半開、全開3種狀態,電機可以工作在關閉和開啟兩種狀態,激振器可以產生不同工作電壓下頻率不同的振動。3種設備各自的工作模式與不同模式之間的組合,共形成45種工作模式(工況),用以模擬潛艇的正常或突變時的機械噪聲源。使用布設在相應部位的振動加速度傳感器進行振動噪聲信號采樣,通過功率譜特征提取方法處理采樣信號,經過采樣保持、A/D轉化、低頻濾波、FFT變化、積分壓縮、歸一化,最終提取25維特征向量作為噪聲源樣本進行研究。實驗環境中共布設了19個振動加速度傳感器,本文實驗只針對單傳感器采集數據,數據由布設在耐壓殼左舷位置的傳感器采集獲得。
3.2 實驗設置與結果分析
設計實驗驗證本文提出的ALSL-SVDD算法的性能,實驗環境是PC機2.5 GHz CPU,2 GB內存,Windows XP操作系統,Matlab 7.1實驗平臺。實驗以SVDD為基準分類模型,參數設置:核函數為RBF(Radial Basis Function),懲罰因子ξ和控制因子C通過十折交叉驗證每次均取最佳參數。
實驗采用有標注數據進行學習的算法(簡稱Init)和隨機采樣方法(簡稱Random)作為對比算法。有標注數據進行學習的算法是一般的有監督學習方法,訓練時需要大量已標注樣本。隨機采樣方法可以認為是一種被動學習,被動地接受隨機選定的訓練樣本,忽略了樣本包含的信息量。本文提出的ALSL-SVDD學習算法從未標注樣本集中選擇最有價值的樣本,可以更快改善分類器的性能。實驗分別從各類別識別率、總識別率和樣本標注代價兩個方面對算法的性能進行評價。
實驗選取6種典型工作模式(工況),每種工況16個樣本。將整個數據集各類分別取30%作為已標注樣本集,50%作為未標注樣本集,全數據集用于測試。表1給出了3種算法各類別的識別率和總的識別率。
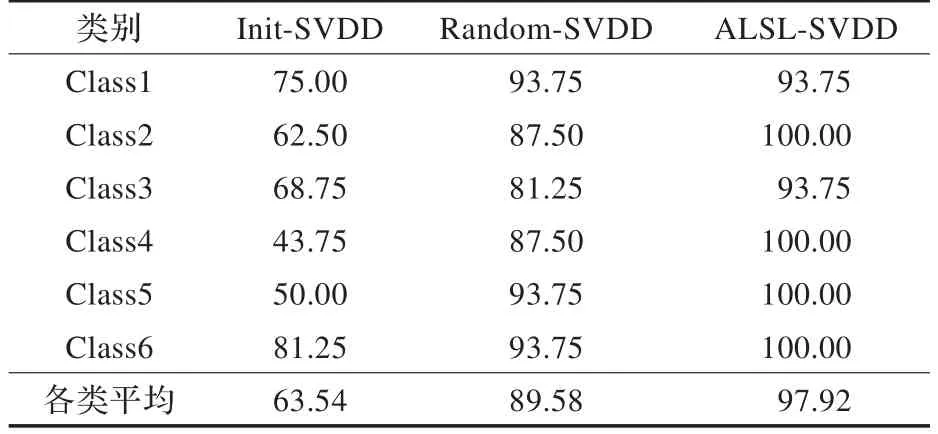
表1 3種算法的識別率比較 (%)
就實驗結果的各類平均識別率來看,Random-SVDD和ALSL-SVDD明顯優于Init-SVDD,原因是Random-SVDD和ALSL-SVDD在初始的30%的已標注樣本集基礎上繼續從50%的未標注樣本集選擇樣本標注,擴充了訓練集。但是Random-SVDD只是隨機的選擇樣本,而ALSL-SVDD是有指導性地選擇有價值的樣本,因此在識別率達到幾乎同等較高水平時,采用ALSL-SVDD所需的標注代價較Random-SVDD相比要低,如圖2所示。

圖2 兩種算法的學習曲線
圖2給出了ALSL-SVDD和Random-SVDD兩種算法的學習曲線。其中,橫軸給出人工標注的樣本數目,縱軸給出各類平均分類正確率。從學習曲線圖上可看出,整體呈上升趨勢,且ALSL-SVDD的上升速度更快,尤其是在樣本標注數目較少時。在達到相同的分類正確率(約90%)時,ALSL-SVDD方法比隨機采樣算法節約了將近1/4的樣本標注工作量。
4 結論
本文針對潛艇故障識別中噪聲源樣本標記代價大的問題,分析了適用于解決小樣本分類問題的支持向量數據描述分類模型和樣本標注技術,提出了一種基于SVDD的主動學習和自學習方法相結合的分類算法。這種算法以SVDD為基準分類模型,初始訓練時僅需少量已標注樣本,對于大量未標注樣本算法每次從中選擇最不確定的樣本交給專家標注,同時選擇最具有代表性的樣本進行自動標注。最后在潛艇機械噪聲源數據集上的實驗結果表明,該方法可以在不降低識別率的同時有效減少標注代價。本文算法中的參數threshold是在訓練前人為指定的,下一步的研究是如何進行無監督參數選擇,對ALSL-SVDD算法作進一步的改進。
[1]章林柯,崔立林.潛艇機械噪聲源分類識別的小樣本研究思想及相關算法評述[J].船舶力學,2011,15(8):940-947.
[2]繆志敏,趙陸文,胡谷雨,等.基于單類分類器的半監督學習[J].模式識別與人工智能,2009,22(6):924-930.
[3]Zhu Xiaojin.Semi-supervised learning literature survey,TR1530[R].University of Wisconsin-Madison,2005.
[4]Hsu D J.Algorithms for active learning[D].Sandiego:University of California,2010.
[5]Settles B.Active learning literature survey,TR1648[R].University of Wisconsin-Madison,2009.
[6]Vapnik V N.The naturn of statistical learning theory[M].New York:Springer-Verlag,1995.
[7]Tax D M J,Duin R P W.Support vector data description[J].Machine Learning,2004,54:45-66.
[8]Vapnik V N.Statistical learning theory[M].Danvers,MA:John Wiley&Sons,2000.
[9]Dasgupta S.Coarse sample complexity bounds for active learning[M]//Advances in Neural Information Processing Systems.Cambridge:MIT Press,2006:235-242.
[10]Muslea I,Minton S,Knoblock C A.Active learning with multiple-views[J].Journal of Artificial Intelligence Research,2006,27:203-233.
[11]吳偉寧,劉揚,郭茂祖,等.基于采樣策略的主動學習算法研究進展[J].計算機研究與發展,2012,49(6):1162-1173.
[12]陳榮,曹永鋒,孫洪.基于主動學習和半監督學習的多類圖像分類[J].自動化學報,2011,37(8):954-962.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
