基于Gammatone濾波器組的說話人識別算法研究
2015-04-14 12:28:04茅正沖王正創
計算機工程與應用 2015年1期
關鍵詞:信號
茅正沖,王正創,王 丹
江南大學 物聯網工程學院,江蘇 無錫 214122
1 引言
說話人識別中最關鍵的問題之一就是提取有效的特征參數,目前常見的特征參數有線性預測系數(LPC)、線譜對參數(LSP)、Mel頻率倒譜系數(MFCC)等[1]。然而,在實際的說話人識別系統中使用時,容易受到噪聲的干擾,導致識別率降低[2]。人耳聽覺系統是一個具有高度復雜性的系統,其研究意義非常重要,尤其是在噪聲的環境下,人耳聽覺系統比任何自動識別系統更具有可靠性、便捷性。因此,將人耳聽覺模型融入到自動識別系統中,可以大幅提升系統的性能[3-5]。
聲音的感受細胞在內耳的耳蝸部分,而基底膜是耳蝸接收聲音最重要的組織。聲波在外耳腔引起空氣振動,從而引起行波沿基底膜的傳播。基底膜能對不同頻率的聲音產生共鳴,反映不同頻率的聲音。不同頻率的聲音產生不同的行波,其峰值出現在基底膜的不同位置上[6-7]。
本文給出了一種基于人耳耳蝸聽覺模型的Gammatone濾波器組,該濾波器組能很好地模擬基底膜的分頻特性,并且基于該濾波器組,提出了一種Gammatone頻率倒譜系數(GFCC)的提取算法,進而用于說話人識別系統中。在有噪聲的背景下,該特征參數的識別率及魯棒性優于傳統的特征參數MFCC。
2 Gammatone濾波器
Gammatone濾波器[8-9]最早應用于描述聽覺系統脈沖響應函數的形狀,后來應用于耳蝸聽覺模型,用來模擬人耳聽覺頻率響應,其時域表達形式如下:
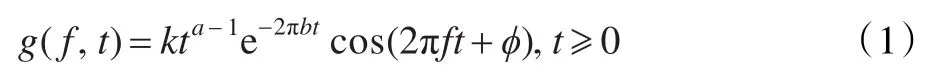
其中,k為濾波器增益,a為濾波器階數,f為中心頻率,?為相位,b是衰減因子,該因子決定相應的濾波器的帶寬,它與中心頻率f的關系為:

由于Gammatone濾波器的時域表達式為沖擊響應函數,所以將其進行傅里葉變換就可以得到其頻率響應特性。不同中心頻率的Gammatone濾波器的幅頻響應曲線,如圖1所示。

圖1 一組不同中心頻率下Gammatone濾波器的幅頻響應曲線
3 GFCC特征參數的提取
根據Gammatone濾波器的特性,準備將該濾波器應用到說話人識別系統中。將輸入的語音信號通過一組Gammatone濾波器,進而語音信號由時域轉換到頻域。這里采用的是一組64個的4階Gammatone濾波器,其中心頻率在50 Hz~8 000 Hz之間。由于濾波器的輸出保留原來的采樣頻率,所以在這沿著時間維度,取響應頻率為100 Hz,通道數為64的Gammatone濾波器。這樣就產生了相應的幀移為10 ms,進而可以應用到短時間的語音特征提取中。當語音信號通過以上的濾波器時,輸出信號的響應Gm(i)的表達式如下:
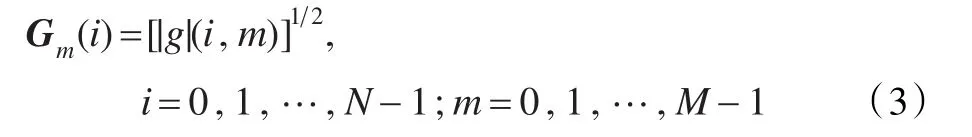
其中,N=64是濾波器的通道數,M是采樣之后的幀數。
這樣Gm(i)構成了一個矩陣,代表著輸入信號在頻域的分布變化,在這采用類耳蝸圖[10]來描述輸入信號在頻域的分布變化。然而,與具有直觀分辨率的語譜圖[11]不同,類耳蝸圖在低頻段的分辨率優于在高頻段的分辨率。圖2是一段純凈語音信號的語譜圖和類耳蝸圖;圖3是一段加噪語音信號的語譜圖和類耳蝸圖。從圖中對比可以看出,類耳蝸圖的分辨效果更加清晰,能更好地反映語音信號的能量分布,尤其是在有噪聲背景下,類耳蝸圖的優勢更突出,更能反映出語音信號的特性。因此,將對類耳蝸圖進行下一步的分析研究。
在這將類耳蝸圖的每一幀稱為Gammatone特征系數(GF),一個GF特征矢量由64個頻率成分組成。但是在實際的說話人識別系統中,GF特征矢量的維度比較大,計算量較大。此外,由于相鄰的濾波器通道有重疊的部分,GF特征矢量相互之間存在相關性。因此,為了減小GF特征矢量的維度及相關性,在這對每一個GF特征矢量進行離散余弦變換(DCT),具體的表達式如下:

圖2 一段純凈語音的語譜圖和類耳蝸圖

圖3 一段加噪語音的語譜圖和類耳蝸圖
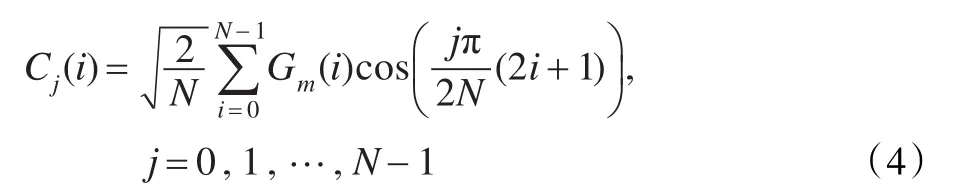
這里將系數Cj(i)稱為GFCCs系數[12],嚴格來說,這個新的特征系數并不是倒譜系數。因為倒譜系數的產生一般要取對數能量,然而在這將GFCCs系數當作倒譜系數,是由于在上面的轉換中和MFCC特征參數的提取轉換有功能上的相似性。和MFCC特征參數類似,在實際的說話人識別系統中,并不是取全部維數的GFCCs系數,經過實驗表明最前若干維以及最后若干維的GFCCs系數對語音的區分性能較大,在這取前26維的GFCCs系數[13]。這樣GFCC特征參數的表達式如下:
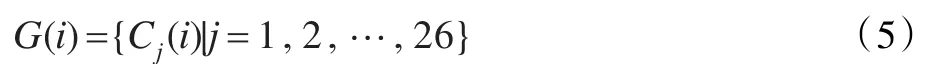
圖4是基于圖2中類耳蝸圖的分析示圖。圖4(a)是GF系數,圖4(b)是基于26維GFCCs合成的GF系數,圖4(c)是基于26維GFCCs合成的類耳蝸圖。

圖4 類耳蝸圖的分析示圖
4 實驗結果與分析
本文所采用的語音庫是在實驗室環境下錄制的,語音采用的是單聲道,8 kHz的采樣頻率,16 bit量化。該語音庫由20人錄制的,每個人錄制10段語音,每段語音時長約5 s,其中每個人的4個語音段作為訓練樣本集,另外6個語音段作為測試樣本集。混入的噪聲選自NOISEX-92標準噪聲庫[14-15],采用的識別方法是高斯混合模型(GMM),GMM的混合數是16。
首先,在大信噪比的背景下,分別提取每個說話人的特征參數MFCC和GFCC。MFCC的提取采用26個Mel頻率濾波器組,經DCT變換計算26維的倒譜系數。GFCC的提取采用64通道的Gammatone濾波器,經DCT變換后取26維的GFCCs系數。經過特征參數提取后,進行說話人識別實驗,實驗結果如表1。
其次,為了測試噪聲環境下特征參數MFCC和GFCC的識別性能,選取噪聲庫中三種典型噪聲作為測試系統的背景噪音。在這里選用的三種典型噪聲是White噪聲、Babble噪聲、Factory噪聲,信噪比為0 dB、5 dB、10 dB、15 dB,實驗結果如表1。

表1 特征參數MFCC和GFCC的識別率(%)
從表1中可以看出,在大信噪比的背景下,GFCC的識別率能達到95%以上。在三種不同的噪聲背景下,特征參數GFCC的識別率明顯高于MFCC。隨著SNR的增大,識別率越來越高,其中在Babble噪聲背景下,由于受到背景中不同說話者之間的相互干擾,以至于系統的平均識別率略低于其他兩種噪聲。此外,在Factory噪聲背景下,SNR為15 dB時,系統采用特征參數GFCC的識別率能達到80%以上,遠高于特征參數MFCC。因此這些可以充分證明,采用Gammatone濾波器組模型對語音進行時域前端濾波是很有效的,這種模型具有很強的抗噪性,也說明了特征參數GFCC對加性噪聲具有一定的抑制性,進一步體現了基于人耳耳蝸聽覺特征的噪聲魯棒性。
5 結束語
本文給出了一種基于人耳耳蝸聽覺模型的Gammatone濾波器組,并且基于該濾波器組,提出了一種GFCC的提取算法。實驗結果表明,在說話人識別系統中采用特征參數GFCC,其識別率及魯棒性都優于傳統的特征參數MFCC,GFCC能降低加性噪聲的影響,抑制加性噪聲的不穩定性。此外,采用特征參數GFCC的計算量大,以及在短時間內進行說話人識別時,識別效果還需進一步改進。因此,如何減少說話人識別系統的計算量,提高系統的識別效率以及實現在短時間內識別將是接下來的研究工作。
[1]屈丹,王波,李弼程.VoIP語音處理與識別[M].北京:國防工業出版社,2010.
[2]蔡蓮紅,黃德智,蔡銳.現代語音技術基礎與應用[M].北京:清華大學出版社,2003.
[3]尹輝,謝湘,匡鏡明.一種基于Gammatone濾波和FrFT的抗噪語音識別方法[C]//第十屆全國人機語音通訊學術會議暨國際語音語言處理研討會論文摘要集.北京:清華大學出版社,2009:5-8.
[4]牛廷偉.噪聲環境下的語音識別關鍵技術研究[D].天津:天津理工大學,2011.
[5]金銀燕,于鳳芹.基于Gammatone濾波和PCNN的說話人識別[J].科學技術與工程,2010,10(30):1671-1674.
[6]何朝霞,潘平.基于聽覺模型的說話人語音特征提取[J].微型機與應用,2012,31(1):37-39.
[7]陳世雄,宮琴,金慧君.用Gammatone濾波器組仿真人耳基底膜的特性[J].清華大學學報:自然科學版,2008,48(6):1044-1048.
[8]王玥,錢志鴻,王雪,等.基于伽馬通濾波器組的聽覺特征提取算法研究[J].電子學報,2010,38(3):525-528.
[9]王玥.說話人識別中語音特征參數提取方法的研究[D].長春:吉林大學,2009.
[10]Shao Yang,Wang Deliang.Robust speaker identification using auditory features and computational auditory scene analysis[C]//Proceedings of IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP2008),March 30-April 4,2008.[S.l.]:IEEE,2008:1589-1592.
[11]張雪英.數字語音處理及MATLAB仿真[M].北京:電子工業出版社,2003.
[12]ZhaoXiaojia,Shao Yang,WangDeliang.CASA-based robustspeakeridentification[J].IEEE Transactions on Audio,Speech and Language Processing,2012,20(5):1608-1616.
[13]He Xu,Lin Lin.A new algorithm for auditory feature extraction[C]//Proceedings of InternationalConference on Communication Systems and Network Technologies.Washington,DC,USA:IEEE Computer Society,2012:229-232.
[14]胡峰松,曹孝玉.基于Gammatone濾波器組的聽覺特征提取[J].計算機工程,2012,38(21):168-171.
[15]Shao Yang,Jin Zhaozhang,Wang Deliang.An auditorybased feature for robust speech recognition[C]//Proceedins of International Conference on Acoustics,Speech and Signal Processing(ICASSP2009),19-24 April,2009.[S.l.]:IEEE,2009:4625-4628.
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
