自適應濾波語音增強算法改進及其DSP實現
2015-04-14 12:28:04王瑜琳田學隆高雪利
計算機工程與應用 2015年1期
王瑜琳 ,田學隆 ,2,高雪利
1.重慶大學 生物工程學院,重慶 400030
2.重慶市醫療電子技術工程研究中心,重慶 400030
1 引言
語音通信中噪聲干擾普遍存在,不可避免地降低了實際應用中語音通信的質量,嚴重時甚至會造成語義理解困難。語音增強的提出就是為了保證在減少語音失真度的同時,盡可能多地提取出有效的語音信號,抑制背景噪聲,達到改善語音通信質量的目的。目前針對語音增強的研究大多致力于算法的改進,但缺乏實時性的處理系統,且依然存在適應性差,收斂速度慢等問題。因此,針對強噪聲環境下的語音增強算法研究和系統研發具有重要意義。
目前應用較為廣泛的語音增強算法主要有譜減法[1]以及自適應濾波法[2]。譜減法簡單且對寬帶噪聲有顯著的處理效果,但往往因對背景噪聲估計不準確而產生較大的殘留噪聲。在這種情況下自適應濾波技術便發揮了其特有的優勢,可在信號統計特性未知或變化的情況下,自動跟蹤輸入的變化,并不斷調整自身參數,來達到最佳的濾波效果。傳統的自適應濾波器大多采用雙通道方式,與譜減技術相比,系統需多提供一路參考信號作為濾波器的輔助輸入,這在一定程度上增加了系統設計的復雜性。針對這一問題,有研究指出取含噪信號的延時量作為濾波器的參考輸入來構造單通道系統,可簡化設計的復雜性[3-4]。而針對自適應濾波中存在的收斂速度慢,收斂精度差等問題,本文使用箕舌線函數[5-6]更新自適應濾波步長并引入解相關運算[7-8]更新權系數迭代方向,在加快自適應濾波收斂速度的同時提高精度。
在硬件實現上,本文選用具有高速幀處理能力的DSP[9-10]芯片與音頻擴展芯片TLV320AIC23(簡稱AIC23)共同搭建系統的處理核心。在簡化系統設計復雜性的同時完成了單通道語音增強系統的硬件設計、軟件仿真及DSP實時實現。實驗結果顯示,經本文系統處理后能有效消除語音信號的背景噪聲,提高語音的清晰度,證明了算法的有效性以及系統的可行性。
2 自適應濾波系統設計
2.1 基于時延結構的自適應濾波原理
語音信號是一種短時平穩信號,在10~30 ms內其頻譜特性和相關特征參數基本不變,具有較強的相關性和準周期特性。而噪聲通常是隨機的,其自相關函數僅在原點處存在峰值[11-12]。因此可利用語音信號的相關性和噪聲的不相關性,構造基于時間延遲方式的濾波系統,減小系統設計的復雜性。系統的結構形式如圖1所示。

圖1 時延結構自適應濾波原理
圖1中期望輸入v(k)為原始含噪語音,參考輸入x(k)為v(k)延時后的信號。由于系統主要利用的是語音的相關性以及噪聲的不相關性,來加強含噪語音的相關部分,同時削弱其不相關的部分,所以系統性能與信號間的相關特性密切相關,相關性越強就越容易從中提取出有用信號。
2.2 LMS算法設計
自適應濾波器的工作原理是依賴某一準則的約束,以實現對參考信號的最佳估計。常用算法有最陡下降法、最小均方誤差算法(LMS)、遞推最小二乘算法(RLS)等。在這一系列的算法中LMS算法以其運算簡單,異于實現及穩健性能好等優點成為自適應濾波技術的首選算法,其基本迭代過程如下[13]。

其中,X(k)=[x(k),x(k-1),…,x(k-M+1)]T為M階濾波器在k時刻的參考輸入,y(k)為濾波器的估計輸出,W(k)=[w(k),w(k-1),…,w(k-M+1)]T對應濾波器權系數矢量,μ為步長因子。然而LMS算法由于μ固定而存在收斂速度與收斂精度之間的矛盾,無法同時提高速度與精度。μ的選取對LMS算法性能的優劣起著決定性的作用:μ小可減小系統的穩定誤差,提高算法收斂的精度,但降低了算法收斂的速度;μ大可加快收斂速度,卻是以大的失調為代價的。為解決這一矛盾,出現了較多的改進型LMS算法,用一個變化的μ來優化LMS算法。
變步長的基本思想是在初始階段用較大的μ來加快算法收斂的速度,收斂階段則用較小的μ來減小系統的穩態誤差。通過動態改變μ的大小,來獲得最優的濾波效果。在這一過程中,μ的大小可依據不同的調控機制來進行調節,如W(k)、e(k)等。式(4)就是基于箕舌線函數而建立的μ與e(k)之間的函數關系式,參數α、β分別為函數形狀及幅度控制因子。

由于 LMS 算法的收斂條件為μ∈(0,1/γmax),γmax為 X(k)的最大特征值,所以式(4)中μmax=β,因此有β< 1/γmax。
另一方面,由式(1)、(2)可得:

若定義Wopt(k)為最優權值向量,ξ(k)為零均值噪聲,則v(k)可表示為:

由此可得:

其中Δ(k)=Wopt(k)-W(k)為權值誤差向量。
將式(7)帶入式(4)得:
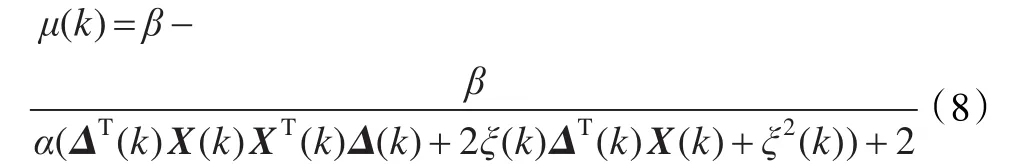
由式(8)可知,除獨立噪聲外,μ(k)還與 X(k)XT(k)密切相關。因此在輸入信號高度相關的情況下,μ(k)除了與跟蹤誤差有關外,還受輸入信號的影響,導致變步長自適應濾波算法的性能下降。若能在濾波前減小輸入信號之間的相關性,便可加快算法收斂的速度。解相關運算的思想就是利用輸入向量之間的正交變換去除輸入信號之間的相關性。根據解相關原理,定義相關系數如下:

Γ(k)即為k及k-1時刻輸入信號之間的關聯性,從X(k)中減去 X(k)與 X(k-1)之間相關的部分便稱為“解相關”運算,由此得出新的更新矢量如下:
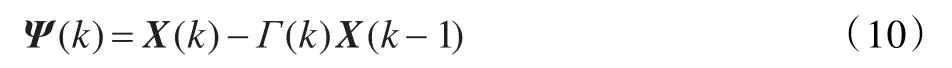
結合式(9)、(10)有 X(k-1)ΨT(k)=0 ,即解相關向量與k-1時刻的輸入信號正交,正是這種正交關系,加快了LMS算法收斂的速率。基于解相關的權值迭代表達式為:
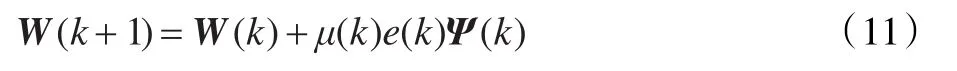
綜上所述,本文自適應濾波算法過程如下:
(1)讀入帶噪語音v(k)并取其延時信號x(k)作為濾波器輔助輸入,初始化W(0)。
(2)分別按式(1)、(4)、(10)計算濾波器輸出y(k)、μ(k)以及權系數更新方向矢量Ψ(k)。
(3)將μ(k)、Ψ(k)代入式(11),更新W(k+1)。
(4)利用更新后的W(k+1)返回步驟(2),進行下一次迭代運算。
3 語音增強系統硬件及軟件設計
3.1 基于DSP的語音增強系統硬件設計
TI生產的TMS320F281x系列DSP提供了多種外設通信接口,如串行通信接口(Serial Communication Interface,SCI)、串行外圍接口(Serial Periperal Interface,SPI)、多通道緩沖串口(McBSP)等。其中McBSP支持全雙工通信機制,并提供雙緩存的發送和三緩存的接收寄存器,允許連續的數據流傳輸。數據長度通過編程設置,可與工業標準的解碼器(CODEC)、模擬接口芯片(AIC)等直接進行串行連接。AIC23是一款Σ-Δ型高性能的音頻編解碼芯片,內部集成了16位A/D、D/A轉換器,可與DSP的McBSP進行無縫連接,采樣速率可通過DSP編程設置,高速實現語音信號的接收、發送。同時DSP以其高速的幀處理能力,靈活的運用方式以及低能耗等優點,逐步成為數字語音處理的首選。因此,本文選用TMS320F2812芯片作為主控芯片與AIC23及相應外圍電路共同完成系統的硬件設計。然而DSP自帶的程序和數據存儲器容量有限,通常難以滿足語音處理的需求,片外擴展了256K×16位SRAM作為外部數據存儲器,512K×16位FLASH作為外部程序存儲器。系統結構框圖如圖2所示。
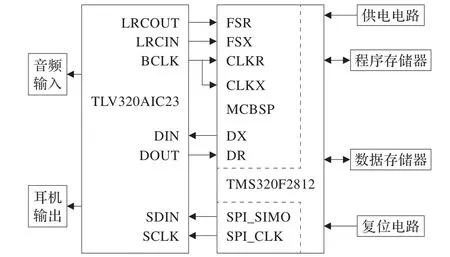
圖2 DSP語音增強系統硬件結構設計
AIC23具有獨立的控制接口和數據接口。控制接口用于配置器件內部的11個寄存器,設置音頻芯片的工作狀態,實現初始化AIC23的目的。控制接口的工作方式有SPI和I2C方式,可通過芯片管腳進行選擇。數據接口則通過DIN、DOUT引腳傳輸AD轉換和待DA轉換的數據,實現與McBSP的無縫連接。數據接口的工作方式可通過數字音頻格式寄存器設置為DSP模式,同時令AIC23工作于主模式下,即由AIC23提供時鐘源,并通過分頻器產生供串口通信的移位時鐘及幀同步信號。其中CLKX、CLKR、BCLK為時鐘同步信號,CLKR與CLKX之間通過一個0 Ω的電阻進行連接;FSX、FSR、LRCIN、LRCOUT為幀同步信號。在實現數據接口與McBSP的正常通信之前,需通過DSP的SPI口連續傳輸11串數據到控制接口,以達到配置AIC23的目的。設置AIC23時鐘為正常模式,采樣率為8K,并設置適當的輸入/輸出信號增益[14]。同時AIC23還具有一個其他音頻處理芯片所不具備的功能,即模擬旁路設置,直接將輸入的模擬信號送出去回放,而不經過AD及DA轉換,這對于系統調試非常重要。
由于經AIC23采樣輸出的數據是串行數據,因此要先對McBSP的相關寄存器進行配置,以協調好與DSP的串行傳輸協議。即通過對McBSP內部的各寄存器(SPCR1、SPCR2、XCR1、XCR2、PCR1、PCR2、RCR 等)寫入適當的控制字,使McBSP工作于SPI從模式下,同步McBSP的接收器和發送器,并使其在AIC23收發時鐘的控制下,進行數據的接收和發送。設置McBSP的串行通信格式為單相位,每個相位一個字,每字傳輸16位,采用無壓縮方式進行數據的傳輸。
基于DSP的McBSP和模擬接口芯片AIC23進行語音信號的數據采集和發送流程,如圖3所示。
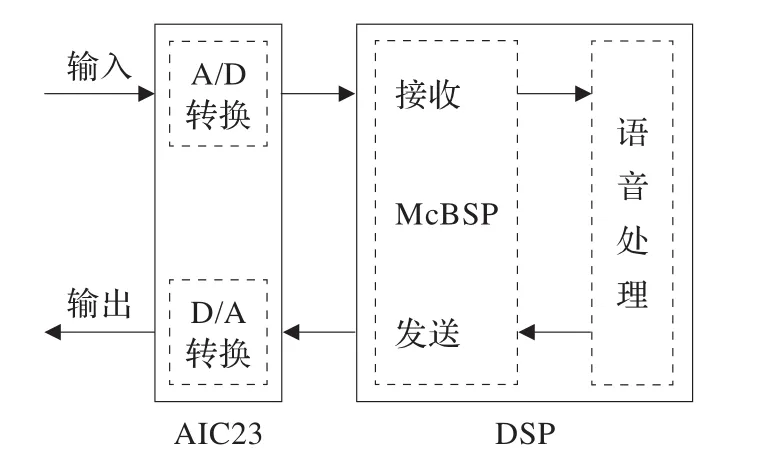
圖3 基于DSP的語音處理流程圖
麥克風采集含噪語音信號,并輸入到AIC23進行抗混疊濾波、A/D轉換,并經McBSP傳至DSP芯片進行降噪處理。同時處理完的數據再經McBSP傳回AIC23進行D/A轉換、重構濾波。通常AIC23內置有耳機驅動電路,因此無需在外部進行驅動處理,而是直接由耳機輸出經過降噪處理后的語音信號。
3.2 基于DSP的語音增強算法軟件設計
首先通過MATLAB編寫基于箕舌線和解相關的語音降噪算法,完成對算法性能的驗證。然后在CCS集成開發環境下用C語言和匯編語言改寫該算法,并下載至DSP進行在線仿真調試。系統軟件實現流程如圖4所示。
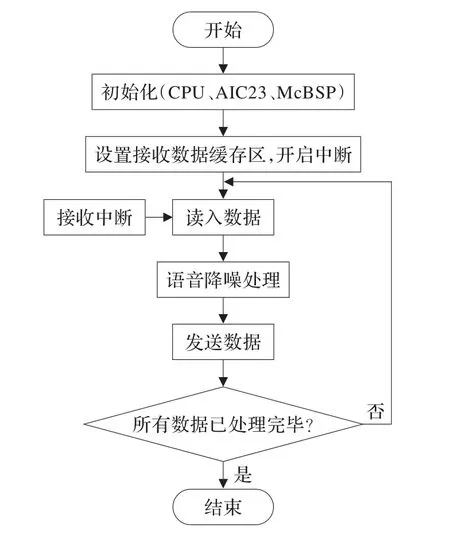
圖4 系統主程序流程圖
(1)合理分配程序和數據內存空間,將程序段和查表數據定義在FLASH中,僅進行讀操作,數據段分配在DARAM中,可同時進行讀寫操作,避免調用和跳轉造成流水延遲。
(2)通過配置片內時鐘方式寄存器CLKMD實現DSP的CPU頻率的初始化。
(3)利用DSP的SPI口,初始化AIC23內部各寄存器設置其工作方式、數據傳輸的位數、采樣速率等。初始化McBSP,完成各串口寄存器的配置,保證其與AIC23的正常通信。
(4)開辟數據緩沖區,由于語音自適應濾波處理速度有時會跟不上數據接收速度。為避免丟幀,開辟多幀數據緩沖區,保存未處理的數據,在CPU空閑時間調用自適應濾波算法,完成緩存數據的降噪處理。
(5)開啟串口接收中斷,并開始接收數據。在每次中斷處理過程中接收一個語音數據,同時發送一個已處理的語音數據,經McBSP傳回AIC23進行后續處理并輸出。
4 算法測試分析
4.1 基于MATLAB的算法性能測試
為了驗證系統算法設計的有效性,本文在MATLAB平臺上,從最小均方誤差特性的角度出發,仿真對比在標準LMS算法、基于箕舌線函數的VS_LMS算法及本文使用的New_LMS算法作用下,系統的穩態誤差及算法的收斂速度。仿真信號采用雙極性隨機序列構造,隨機取值為+1、-1的偽隨機信號通過FIR濾波器,并在輸出端加入高斯白噪聲,由此得到模擬的含噪信號。將該信號用于時延結構的單通道濾波系統,仿真計算采樣點數為2 000,重復次數為1 000時系統的均方誤差。仿真結果如圖5所示。
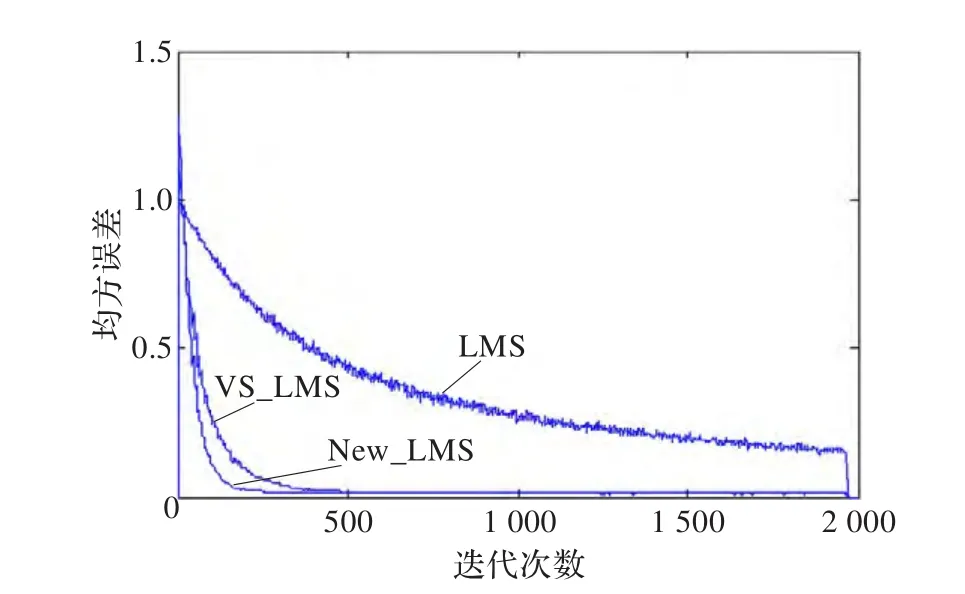
圖5 三種LMS算法收斂性能比較
不同算法的相關參數設置及收斂性能比較,如表1所示。

表1 三種LMS算法參數設置及收斂性能對比
從圖5和表1的穩態誤差和到達穩態的迭代次數可知,對比于標準LMS,算法如果步長選取不合適,可能導致收斂速度很慢,且誤差很大。在變步長算法的作用下,算法的收斂速度、穩態誤差均得到了顯著的改善。兩種變步長算法相對比可看出,引入解相關原理之后,穩態誤差基本不變,但算法收斂的速度得到進一步提高。由此證明了變步長解相關算法的有效性。
完成算法性能分析后,還需進一步驗證算法的去噪效果。這里仿真信號選用標準女聲朗讀音頻,對其添加白噪聲后,取其延時信號與原始含噪語音共同構成噪聲對消系統。使用上述三種方法分別進行降噪處理,處理效果如圖6所示。
顯然,結合圖5、圖6可知,本文算法在獲得快速收斂速度與較小穩態誤差的同時可有效去除加載在語音中的噪聲成分,得到較純凈的語音信號。為進一步驗證本文算法去噪效果,表2列出了語音信號在不同程度噪聲干擾下,降噪處理前后的信噪比。
4.2 基于DSP的算法實時處理效果分析

圖6 語音信號在不同算法作用下的降噪效果

表2 不同強度噪聲干擾下SNR改善量 dB
完成降噪算法的MATLAB測試之后,就需要進一步對本文所設計的DSP處理系統進行硬件和軟件電路的調試,來驗證系統設計的可行性、穩定性及本文采用降噪算法的實時降噪效果等。首先依據MATLAB測試算法完成自適應濾波算法的C語言和匯編語言的移植,再根據音頻芯片與DSP的通信協議實現系統的正常通信。測試中通過音頻線將計算機聲卡輸出連接至AIC23音頻輸入端,并在計算機中播放待測試的噪語音音頻文件。經AIC23完成AD轉換后,輸入到DSP芯片,利用集成開發環境(Code Composer Studio,CCS)對信號進行在線仿真測試,實現含噪信號的去噪處理及輸出。為了清晰對比含噪信號濾波前后的波形效果,可在CCS環境下進入圖形觀察窗口,設置所需顯示圖形的相關數據的起始地址、顯示的長度及數據類型等參數[15]。調試后,CCS圖形顯示窗口顯示的波形如圖7所示。

圖7 基于DSP的語音信號降噪測試
觀察波形易知,本文采用的濾波算法移植到DSP硬件系統上取得了顯著的濾波效果,可顯著去除語音信號中的噪聲成分,接近MATLAB仿真效果,且算法效率高,能夠穩定地實時處理。除了能直觀觀察波形變化外,還可以進行主觀聽覺測試,播放多個含噪音頻文件,并使用耳機從AIC23輸出端感受經DSP系統降噪后語音的聽覺效果。對比未處理的含噪語音便可明顯感覺語音信號變得清晰,可懂度也得到了提高。
5 結束語
本文采用基于時間延遲方式的單通道濾波系統,減小了語音增強系統設計的復雜性。在DSP平臺上利用多通道緩沖串口McBSP和音頻接口芯片TLV320AIC23進行串行通訊,實現了語音信號的高速采集和輸出,運行穩定。在語音降噪處理上,引入了箕舌線變步長算法,同時提高傳統自適應濾波算法收斂速度和收斂精度,有效地解決了跟蹤速度與穩態誤差之間的矛盾。引入解相關原理,使用輸入向量的正交分量來更新權系數迭代方向,進一步加快了強相關信號的收斂速度和精度。實驗表明,本文算法降噪性能好,能有效地消除噪聲環境下語音信號的背景干擾,提高語音通訊的質量,具有一定的參考作用和應用價值。
[1]Paliwal K K,Schwerin B,Wojcicki K K,et al.Singlechannel speech enhancement using spectral subtraction in the short-time modulation domain[J].Speech Communication,2010,52(5):450-475.
[2]陳素芝,李英.一種基于變步長LMS算法的語音增強方法[J].聲學技術,2005,24(1):42-46.
[3]萬新旺,吳鎮揚.基于自適應頻率選擇的魯棒時延估計算法[J].東南大學學報:自然科學版,2010,40(5):890-894.
[4]Zhang Liyan,Yin Fuliang,Zhang Lijun.A new microphone array speech enhancement method based on AR model[C]//Proceedings of International Conference on Life System Modeling and Simulation,and Conference on Intelligent Computing for Sustainable Energy and Environment,2010:139-147.
[5]張安莉,陳丹.一種變步長自適應濾波算法在信號消噪中的應用[J].西安工業大學學報,2010,30(1):71-75.
[6]胡春嬌,楊順.基于箕舌線變步長LMS算法的分析與改進[J].計算機仿真,2010,27(11):359-362.
[7]段正華,王梓展,魯薇.一種改進的解相關LMS自適應算法[J].湖南大學學報:自然科學版,2006,33(3):114-118.
[8]彭勁東,段正華,王梓展.一種變步長解相關LMS算法[J].計算機工程與應用,2004,40(30):136-138.
[9]TMS320x281x Multi-channel Buffered Serial Port(McBSP)Reference Guide(Rev.B)[M].[S.l.]:Texas Instruments,2004.
[10]TMS320x28lx,280x DSP Peripheral Reference Guide(Rev.B)[M].[S.l.]:Texas Instruments,2004.
[11]趙力.語音信號處理[M].北京:機械工業出版社,2003.
[12]夏冬冬.非平穩環境下的語音增強算法研究[D].西安:西安電子科技大學,2006.
[13]汪成曦,劉以安,張強.改進的最小均方自適應濾波算法[J].計算機應用,2012,32(7):2078-2081.
[14]田玉敏.基于DSP的激光偵聽器語音處理研究[D].武漢:華中科技大學,2007.
[15]曹曉琳,吳平,丁鐵夫.基于DSP的語音處理系統設計[J].儀器儀表學報,2005,26(8):583-585.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
鴨綠江(2021年35期)2021-04-19 12:24:18
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
家庭影院技術(2017年9期)2017-09-26 03:41:45
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
