內容標簽和關系標簽相結合的漢語篇章標注規范
2015-04-21 08:43:41李素建王宇昕
中文信息學報 2015年3期
王 荀,李素建,王宇昕
(北京大學 計算語言學教育部重點實驗室,北京 100871)
?
內容標簽和關系標簽相結合的漢語篇章標注規范
王 荀,李素建,王宇昕
(北京大學 計算語言學教育部重點實驗室,北京 100871)
篇章標注是自然語言處理中的重要任務,很多其他任務,如自動摘要、機器問答等都可以通過篇章標注得到對文本內容和語義的認識,從而獲得更好的結果。與此同時,篇章理解的理論如篇章修辭結構(RST),向心理論(CT)等與實際問題的結合并不緊密,難以實用。該文中我們參考現有的語言學理論和一些語篇標注庫(如RST-DT,PDTB),并結合自然語言處理任務特點,提出了一套用于篇章標注的漢語標注體系。這個體系能夠比較準確和全面地描述出篇章的內容和邏輯關系,并很好地服務于實際任務的需要。
篇章語義標注;修辭結構理論;關系標簽;內容標簽
1 引言
在自然語言處理中,很多任務,如自動摘要、機器問答等,單純依靠統計的方法只能抽取到文本表面的特征,而且過分依賴于頻次等信息。如果可以對篇章進行語義分析,得到對篇章的內容和邏輯關系的認識,便可以輔助模型的設計或者算法的改進從而獲得更好的結果。但是現有的篇章語義分析的理論如修辭結構理論(Rhetoric Structure Theory,RST)[1]、語篇向心理論(Centering Theory)[2]等與實際問題的結合并不緊密,導致語義關系難以得到充分利用。
本文參考話語分析理論,特別是RST等篇章結構方面的理論,并結合自然語言處理中常見任務的特點,提出一套用于篇章標注的標簽體系。這個體系由內容標簽和關系標簽兩套標簽體系構成,能夠比較準確和全面地描述出篇章的重點內容和語義關系,可以很好地滿足實際任務的需要,同時保持了體系的完備性,兼顧了理論和實際的雙重需求。
2 篇章標注的相關工作
篇章關系是指文本的組成部分之間的語義關聯。一般只考慮相鄰的部分之間的語義關系。研究篇章關系時的語義單位,一般是句子或者小句,也有以短語為基本單位的,彼此組合起來形成更大的單位,自底向上層層聯合,直至形成一篇文檔被完全標注。一般使用樹狀結構來描述語義關系,也有使用圖模型的。
目前篇章標注中代表性的工作,一個是基于RST理論的RST-DT (RST-Discoures Treebank)語料庫[3]。RST-DT語料庫基于RST理論標注了385篇Wall Street Journal文章。RST理論認為篇章內部存在著不同的語義關系,整個文本由這些關系連接起來而成為一個整體。
其中另外一個目前應用較廣泛的是2006年發布的PDTB[4],最新的版本是2008 PDTB-V2[5]。PDTB的標簽設置相對比較簡單,它將連接詞視為謂詞,將具有語義關系的成分視為謂詞的論元。PDTB將語義關系分為三層,最高層主要有四種語義關系,分別是Comparison、Temporal、Contingency和Expansion。每種關系下面可以繼續再分,最多有三層,其中第二層有16種關系。PDTB一共標注了一百萬字規模的華爾街新聞文章。其他還有基于框架語義學的FrameNet語料庫,它是基于框架語義學,以動詞為核心,專注于事件和場景的描述,共有大約1 200個框架。而Graphbank則使用圖來對語義關系進行描述的。
中文的篇章語義分析工作基本上采用RST的框架,主要對修辭關系進行標注,而并不對內容和關系進行區分。在此基礎上的工作有樂明[6]在財經類文章上進行的標注;婁開陽[7]在新聞語料上進行了比較系統的語義關系分析研究,標注了數百篇新聞語料,并進行了統計和分析,對新聞敘事的宏觀和微觀結構的表現形式進行了詳盡說明;李毅等[8]基于奧運語料的語義成分標注規范等。這些研究基本是在RST的框架內進行的,對漢語的篇章分析進行了有意義的研究,取得了一定成果。
總結以上幾種語篇標注的體系和語料庫,我們可以發現,RST-DT和GraphBank是將整個文本作為一個整體進行理解和標注,而PDTB和FrameNet主要用來描述文本片段。前者能夠較好地描述文本內部的語義關系,而后者可以對文本片段進行詳盡的說明。而在自然語言處理的實踐中,對文本語義的把握和對細節的分析理解對自然語言處理都很重要。目前的種種方法,并不能很好地兼顧二者。從這一點出發,我們設計一種新的篇章標注體系,來對文本篇章進行標注。
3 標注體系的設置
在對文本進行篇章分析的時候,我們一方面需要對篇章的語義關系進行標注;另一方面還需要對一些重要內容進行標注,以便在整體上把握篇章結構的同時,在局部也可以得到更詳細的理解。標注過程中,我們提出了所應遵循的標注基本原則。
3.1 標注的基本原則
分層的原則: 篇章的構成是分層的。在不同的層次關系的種類和緊密程度不一樣。我們設計了一個多層體系來描述篇章。 3.2中將對篇章的分層體系結構進行詳細說明。
簡單的原則: 使用盡可能少的標簽,清晰地描述出篇章重要的內容和邏輯關系。我們將關系標簽和內容標簽分開使用。文章的單位彼此之間用關系連接起來,而重要的內容使用內容標簽單獨標識出來。這樣的設計層次比較清晰。保證了標注體系的完備性。另外將內容標簽和關系標簽分開,保證了基本的關系標簽的穩定性。而內容標簽可以根據標注對象進行擴展,保證了體系的靈活性。
異質的原則: 在不同的層面,關心的側重點不同。標簽也有不同的適用范圍,這一點跟RST是有區別的。 在RST-DT中,不同的層面使用相同的關系。
這些原則將在本文提出的標簽體系中得到體現。
3.2 篇章的體系結構
整個體系的層次如下,篇由關系比較單調和松散的章組成;章由一個或者幾個意義段組成;意義段由意義段或者自然段組成。自然段下轄句子。句子內部又可以分為句子基本單位。每一層的單元彼此之間以及上下級層次之間存在著關系,從而構成整個篇章。
篇是自然存在的一篇文章,結構完整,信息完備。章是篇的直接組成成分,一篇可以由若干章組成而且一般包含若干章。章內容比較完整,彼此之間的獨立性較強,章之間的關系也較少,較簡單。同一章內部的段落之間聯系比較緊密。章由一個或者多個意義段組成。章之間也可以彼此組合形成章。意義段由一個或者若干個彼此之間聯系緊密的自然段組成的,意義段往往關注一方面內容。自然段由句子和一個較長的停頓組成。句子內部可以進一步切分為基本單位。章作為文章中比較高的層次,一篇中章的數目比較少,章之間的以及章和篇的關系也比較簡單。所以描述這種關系的標簽,也比較簡單。除去一般的關系標簽外,章和篇之間還可以加入實現、附屬、背景、前言等類似的關系標簽,來描述邏輯和內容上難以描述,形式上比較明顯的章與篇的關系。
段落之間的關系可以從多個層面進行描述。有的是很明顯而不需要標注的: 比如段落之間的先后關系;是否屬于同一個章節等。還有的是隱藏的,需要判斷的: 比如邏輯和內容上的聯系。我們的標簽體系要描述的為后者。段落的跨度比較大,彼此之間關系的性質也不一樣,有的段落之間關系比較疏松,有的則很緊密。關系比較緊密的自然段合在一起稱為意義段。段與段的結合,最后構成章。
句子和段落之間的關系是最重要的。對于段落以上的層面,由于數目所限,通常不能提供足夠的信息,而且如果要直接服務于摘要或者問答等應用系統,粒度太大,并不適合。而句子作為組成篇章的基本單位,可以提供足夠的信息。所以這個層面的描述是非常重要的。句子的內部可以進行進一步的切分,小句之間存在比較緊密的關系。
由上面的分析可知篇章天然具有一種層次結構,對于不同層次我們關心的重點也不同,因而使用的標簽也不同。
3.3 關系標簽和內容標簽的設定
關系標簽: 是兩個相鄰成分之間的關系。所有的關系都必須在相鄰的兩個成分之間。
內容標簽: 是單個篇章成分本身的內容所具有的意義特征。
關系標簽是必須的,內容標簽是可選的,內容標簽可以是對關系標簽的一個補充。例如,因果關系中,可以使用內容標簽補充說明是原因部分還是結果部分。(RST里面因果和果因是兩個不同的標簽,本文中將二者合并為一個,加上內容標簽來說明因果和果因的區別。)
內容標簽獨立于關系標簽,用來說明成分的主要內容,比如功能、用途、原因、結果等。內容標簽的設計比較靈活,而關系標簽的數目和種類則是固定的,不能增減。這樣可以同時滿足標簽體系的靈活性和穩定性。
關系標簽的設定: 我們主要參考RST的標簽體系,根據統計規律,將比較類似的標簽進行合并,同時將使用比較廣泛的標簽進行細分,并結合要處理的文本和實際問題,設計如表1所示的關系標簽體系。
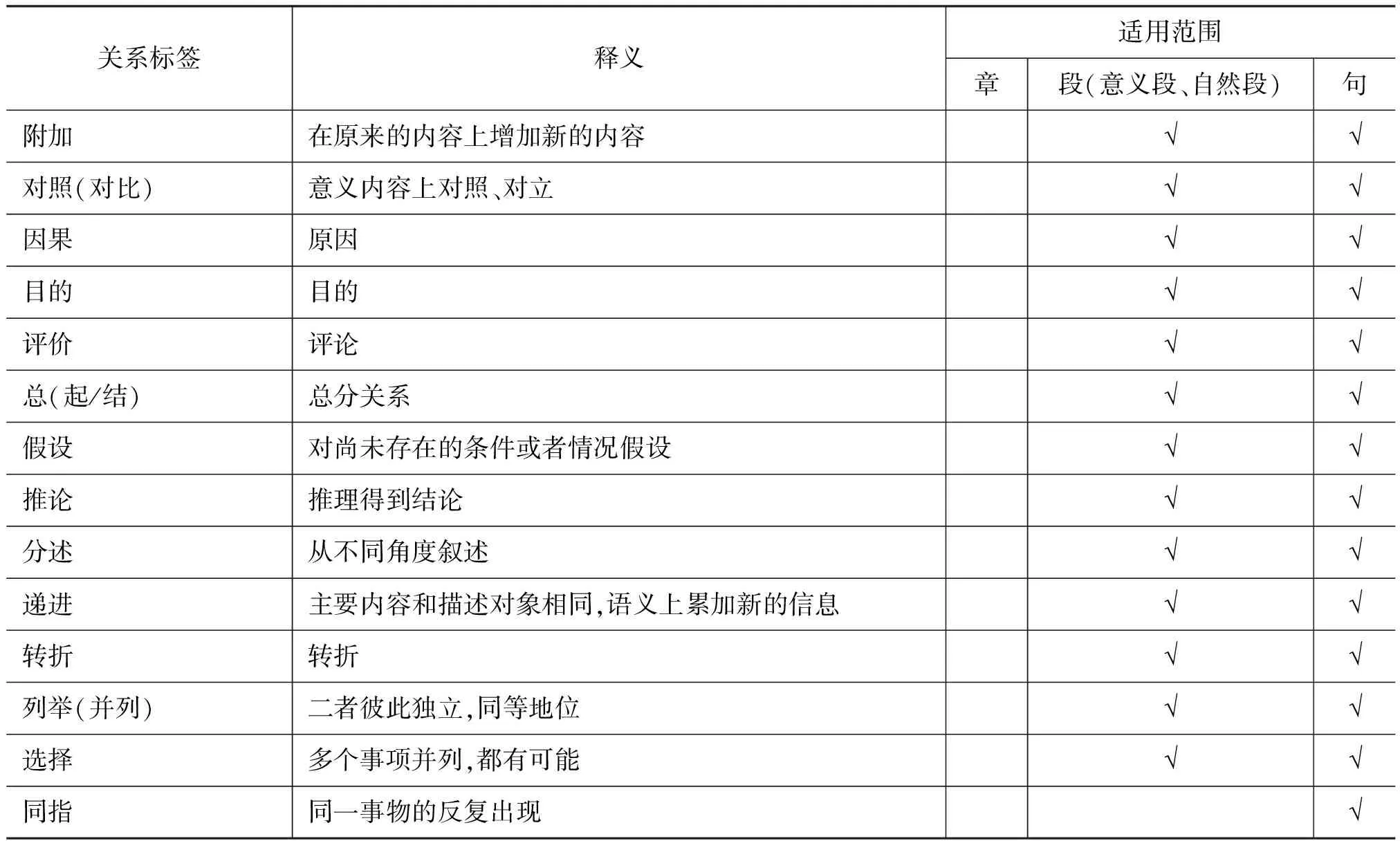
表1 關系標簽
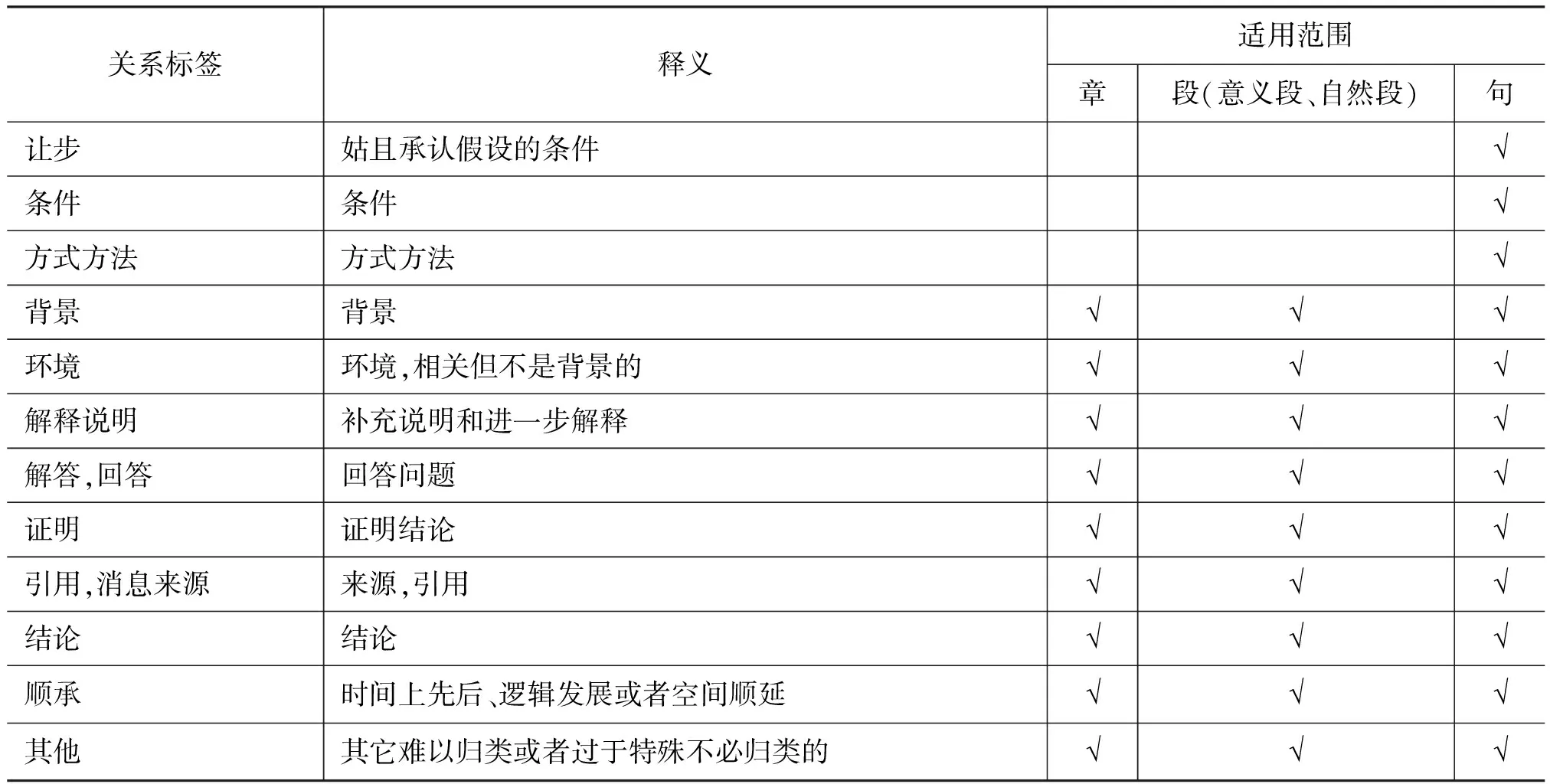
續表
內容標簽和關系標簽是獨立的,用來對部分文本的內容或者功能進行說明。它隨著標注對象的變化而變化。內容標簽的設置和關系標簽的設置是彼此獨立的,但是它們的標注并非截然分開。文本應當首先進行關系標簽的標注,形成層次的結構;然后內容標簽標注在結構中的成分上。即內容標簽標注的對象應當是關系標注中的一個單位。下面我們給出標注的具體樣例和分析。
4 標注樣例
我們分別在醫學文本和新聞語料上進行了標注,下面給出幾個標注的樣例。
文本如圖1 中所示的那樣,來自醫學文獻(內科學部分),根據文字內容,我們采用的內容標簽如表2所示。使用關系標簽和內容標簽同時進行標注的結果如圖2所示。

表2 醫學文本的內容標簽

圖1 醫學文本及基本單位的切分(部分)

圖2 醫學文本標注結果(部分)
內容標簽與文本內容緊密相關,用來對文本的重要內容進行標識和說明。其中“#”后面的部分是該成分的內容標簽,用來說明此成分的內容。由于篇幅所限,我們只截取了標注結果的一個片段。從結果可以看出,我們可以清晰地描述文本的篇章結構,并標識出重要的內容。其中關系標簽描述了整個文本的篇章結構和彼此之間的語義關系;內容標簽對重要的片段進行標記。醫學文本的結構關系相對比較簡單,我們下面使用新聞語料來對文本關系標簽的標注進行詳細說明。以1998年1月4日 《人民日報》第三版-科威特散記為例,我們對整個篇章進行標注。文本及基本單位的切分如圖3所示。

圖3 科威特散記文本及基本單位切分
標注關系標簽時需要注意,呈現出多種關系時,一般來說優選最強的關系。這個最強是指在上下文中表現出的最強、最明顯的關系。
篇章關系標注的結果見圖4。其中為了方便起見,我們將段上和段內的關系分開描述。在實際標注中,我們開發了一套篇章標注軟件,來實現基本單位的切分(稱為“分段分句”)、關系標簽的標注(稱為“關系標注”)和內容標簽的標注(稱為“內容標注”)。圖5所示的是關系標注的界面。
目前為止,我們已經標注了將近十萬字的醫學文本,并對新聞、專利、說明書等進行了試標注。在標注的同時我們也根據語料,對標注體系不斷進行調整。

圖4 散文文本關系標注結果
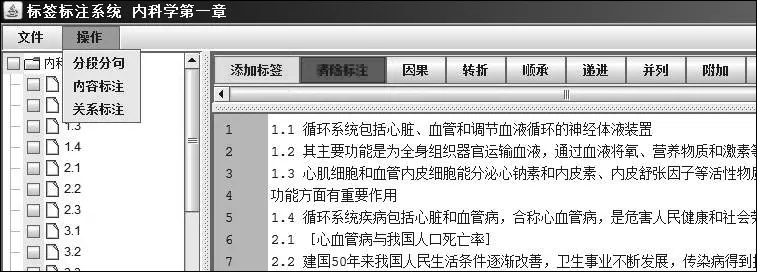
圖5 標注軟件的界面
5 總結和展望
本文提出了一套全新的文本標注體系,我們分別在新聞語料和醫學文本上進行了標注,從試標注的結果來看,這套標簽體系可以描述篇章的語義關系,同時標識出重要內容。對自動摘要、機器翻譯、自動問答等應用都有很大的作用。特別是將內容和語義關系分開,很好地保證了標注體系的理論上完備性,另外又保證了重要信息可以被標識出來。對整體語義結構和對文本片段都有較強的描述能力。之后我們將對更多的文本進行標注,并不斷完善這套體系。
[1] Mann William C, Sandra A Thompson. Rhetorical Structure Theory: Description and Construction of Text Structures[C]//Proceedings of University of Southern California, Information Sciences Institute, 1986.
[2] Walker M A. Centering Theory in Discourse[M]. Oxford:Clarendon Press, 1998.
[3] Carlson Lynn, Daniel Marcu, Mary Ellen Okurowski. Building a discourse-tagged corpus in the framework of rhetorical structure theory[C]//Proceedings of the Second SIGdial Workshop on Discourse and Dialogue-Volume 16. Association for Computational Linguistics, 2001.
[4] The Penn Discourse TreeBank 1.0 Annotation Manual[R]. The PDTB Research Group. March 29, 2006.
[5] Prasad Rashmi, Diresh Nikhll, Lee Alan, et al. The penn discourse treebank 2.0[C]//Proceedings of the 6th International Conference on Language Resources and Evaluation (LREC 2008). 2008.
[6] 樂明. 漢語財經評論的修辭結構標注研究[C].第九屆全國計算語言學學術會議,2007
[7] 婁開陽. 現代漢語新聞語篇的結構研究[M],北京: 世界圖書出版公司,2008.
[8] 李毅,亢世勇,孫茂松,孫道功. 基于奧運語料的語義成分標注規范[C].全國第八屆計算語言學聯合學術會議,南京,2005.
[9] Baker Collin F, Charles J Fillmore, John B. Lowe. The berkeley framenet project[C]//Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics-Volume 1. Association for Computational Linguistics, 1998.
[10] Fillmore Charles J. Frame Semantics and the Nature of Language[J]. Annals of the New York Academy of Sciences, 1976,280(1): 20-32.
Exploration on Chinese Discourse Tagging Scheme
WANG Xun, LI Sujian, WANG Yuxin
(Key Laboratory of Computational Linguistics(Peking University) Ministry of Education Peking University, Beijing 100871, China)
Discourse Tagging is fundamental in natural language processing and helpful to a deep understanding of the texts. Many application tasks, such as automatic summarization, question & answering and so on, would benefit a lot from a thorough understanding of the text. On the basis of the existing discourse theories such as Rhetoric Structure Theory or Centering Theory, this paper designs a new discourse tagging system, which covers both the logical relations and text content or the practical needs of real natural language processing tasks.
discourse tagging; rhetoric structure theory; relation tag; content tag

王荀(1988—),碩士,主要研究領域為自然語言處理,文本分析,統計機器學習。E?mail:wangxun.pku@gmail.com李素建(1975—),通訊作者,博士,副教授,主要研究領域為自然語言處理,自動文摘、篇章分析。E?mail:lisujian@pku.edu.cn王宇昕(1990—),碩士,主要研究領域為自然語言處理。E?mail:arkipku@gmail.com
1003-0077(2015)03-0065-06
2013-04-08 定稿日期: 2013-07-29
國家自然科學基金(61273278);國家社會科學項目(12&ZD227);國家科技支撐計劃子課題項目(2011BAH10B04-03);國家863計劃(2012AA011101)。
TP391
A
猜你喜歡
新世紀智能(數學備考)(2020年11期)2021-01-04 00:38:16
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
新高考·高一物理(2014年1期)2014-09-18 01:26:07
語文知識(2014年1期)2014-02-28 21:59:13
外語學刊(2011年1期)2011-01-22 03:38:33
