應(yīng)用阿茲海默癥基因表達(dá)數(shù)據(jù)對比2種層次聚類方法
2015-05-04 00:59:09付如意胡本瓊龐朝陽四川師范大學(xué)數(shù)學(xué)與軟件科學(xué)學(xué)院四川成都60066成都理工大學(xué)管理科學(xué)學(xué)院四川成都60059四川師范大學(xué)計算機科學(xué)學(xué)院四川成都60066四川師范大學(xué)可視化計算與虛擬現(xiàn)實省重點實驗室四川成都60066
四川師范大學(xué)學(xué)報(自然科學(xué)版) 2015年6期
付如意, 黃 靜, 胡本瓊, 龐朝陽(. 四川師范大學(xué) 數(shù)學(xué)與軟件科學(xué)學(xué)院, 四川 成都 60066; . 成都理工大學(xué) 管理科學(xué)學(xué)院, 四川 成都 60059;3. 四川師范大學(xué) 計算機科學(xué)學(xué)院, 四川 成都 60066; 4. 四川師范大學(xué) 可視化計算與虛擬現(xiàn)實省重點實驗室, 四川 成都 60066)
?
應(yīng)用阿茲海默癥基因表達(dá)數(shù)據(jù)對比2種層次聚類方法
付如意1, 黃 靜1, 胡本瓊2, 龐朝陽3,4*
(1. 四川師范大學(xué) 數(shù)學(xué)與軟件科學(xué)學(xué)院, 四川 成都 610066; 2. 成都理工大學(xué) 管理科學(xué)學(xué)院, 四川 成都 610059;3. 四川師范大學(xué) 計算機科學(xué)學(xué)院, 四川 成都 610066; 4. 四川師范大學(xué) 可視化計算與虛擬現(xiàn)實省重點實驗室, 四川 成都 610066)
隨著基因芯片技術(shù)的發(fā)展,雙聚類分析方法首先被應(yīng)用到高維基因表達(dá)數(shù)據(jù)的研究中.由于多數(shù)高維數(shù)據(jù)的稀疏性,應(yīng)用主成分分析方法將高維數(shù)據(jù)轉(zhuǎn)化到低維數(shù)據(jù)空間,從而在低維空間中應(yīng)用聚類分析方法.不同的聚類分析方法會得到不同的聚類效果,并且同一種聚類方法處理不同的高維數(shù)據(jù)也會得到不同的聚類效果.因此,首先評估了阿爾茨海默基因表達(dá)數(shù)據(jù)的特征集的聚類趨勢,接下來給出了改進(jìn)地δ閾值層次聚類算法的算法描述.由于已有工作分別給出了不同的δ閾值的計算規(guī)則,于是比較了它們δ閾值下的層次聚類算法,并且給出了相應(yīng)的聚類評價.
層次聚類; 閾值; 基因表達(dá)數(shù)據(jù)
阿茲海默癥是一類神經(jīng)退行性疾病,已成為繼心血管疾病、惡性腫瘤、腦卒中之后老年人的第4大“健康殺手”[1].目前,世界上并沒有治療老年癡呆癥的有效辦法.隨著基因芯片技術(shù)[2]的迅速發(fā)展,2003年起科學(xué)家將聚類分析方法[3-5]應(yīng)用到阿茲海默癥相關(guān)的基因表達(dá)數(shù)據(jù)上.2009年W. Kong等[6]將獨立主成分分析(ICA)方法應(yīng)用于阿茲海默癥的候選基因的識別中.2010年C. Y. Pang等[7]將聚類分析方法應(yīng)用到阿茲海默癥的致病基因的識別中.2012年C. Y. Pang等[8]應(yīng)用層次聚類分析方法挖掘與阿茲海默癥相關(guān)的基因表達(dá)數(shù)據(jù).文獻(xiàn)[9]也給出了一種簡捷地?zé)o監(jiān)督一維聚類方法并且應(yīng)用阿茲海默癥的數(shù)據(jù)對其作了數(shù)據(jù)建模.但是上述文獻(xiàn)均沒有從統(tǒng)計學(xué)上去評估數(shù)據(jù)的聚類趨勢以及比較應(yīng)用不同的聚類方法后的實驗結(jié)果.因此,本文將對其阿茲海默癥的基因表達(dá)數(shù)據(jù)做聚類趨勢的評估.傳統(tǒng)的層次聚類算法需要事先主觀地確定出分類個數(shù),從而接下來本文結(jié)合文獻(xiàn)[8-9]給出了改進(jìn)地δ閾值層次聚類算法的算法描述.由于文獻(xiàn)[8]和[9]分別給出了不同的δ閾值的計算規(guī)則,于是本文通過輪廓系數(shù)指標(biāo)比較分析了它們的實驗結(jié)果.最后,從客觀數(shù)據(jù)的角度對改進(jìn)地δ閾值層次聚類算法做出評價.
1 預(yù)備知識
1.1 主成分分析方法[8]主成分分析(PCA)是一種對數(shù)據(jù)進(jìn)行簡化的技術(shù).這種方法實質(zhì)上是找出數(shù)據(jù)中最“主要”的元素和結(jié)構(gòu),去除噪音和冗余,將原有數(shù)據(jù)降維,揭示隱藏在復(fù)雜數(shù)據(jù)背后的簡單結(jié)構(gòu).接下來將給出主成分分析方法的算法描述:
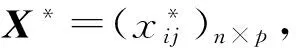
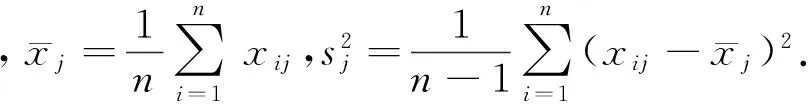
步驟二:計算相關(guān)系數(shù)矩陣R=(rxy)p×p,
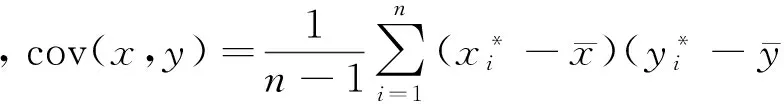
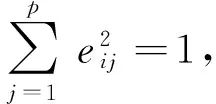
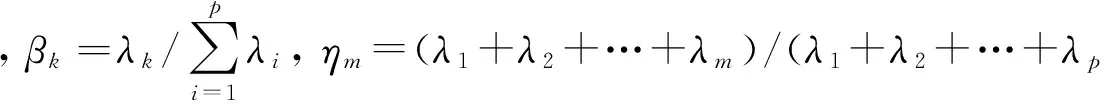
步驟五:計算主成分的載荷矩陣L=(lij)p×p和得分矩陣F.原始數(shù)據(jù)前的加權(quán)系數(shù)決定了新的綜合變量主成分的大小和性質(zhì),通常稱為主成分軸或者載荷向量:
原始變量在新的坐標(biāo)系下投影求得在新坐標(biāo)系下的變量值即為得分:
Fi=e1iX1+e2iX2+…+epiXp,i=1,2,3,…,p.
1.2 霍普金斯統(tǒng)計量[12]霍普金斯統(tǒng)計量是一種空間統(tǒng)計量,檢驗空間分布的變量的空間隨機性,即確定數(shù)據(jù)空間中的數(shù)據(jù)點在多大程度上不同于均勻分布.給定數(shù)據(jù)集D,按以下步驟計算霍普金斯統(tǒng)計量:
1) 均勻地從D的空間中抽取n個點p1,p2,…,pn.找出pi(1≤i≤n)在D中的最近鄰,并令xi為pi與它在D中的最近鄰之間的距離,即
2) 均勻地從D中抽取n個點q1,q2,…,qn.找出qi(1≤i≤n)在D-{qi}中的最近鄰,并令yi為qi與它在D-{qi}中的最近鄰之間的距離,即
3) 計算霍普金斯統(tǒng)計量H,
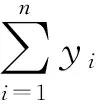
1.3 輪廓系數(shù)[12]對于n個對象的數(shù)據(jù)集D,假設(shè)D被劃分成k個簇C1,C2,…,Ck.對于每個對象o∈D,計算o與o所屬的簇的其他對象之間的平均距離a(o).類似地,b(o)是o到不屬于o的所有簇的最小平均距離.假設(shè)o∈Ci(1≤i≤k),則
并且
對象o的輪廓系數(shù)定義為
輪廓系數(shù)方法結(jié)合了凝聚度和分離度,可以以此來判斷聚類的優(yōu)良性,其值在-1到+1之間取值,值越大表示聚類效果越好.
2 數(shù)據(jù)的來源與特征
本文使用的基因表達(dá)數(shù)據(jù)是從美國國家生物技術(shù)信息中心(NCBI)網(wǎng)站上下載得到的[13-14].該數(shù)據(jù)為31組65~101歲年齡階段的患有不同程度的阿茲海默癥的患者的22 283個基因的表達(dá)水平值.其9組正常人的基因表達(dá)水平值數(shù)據(jù)格式如表1所示.
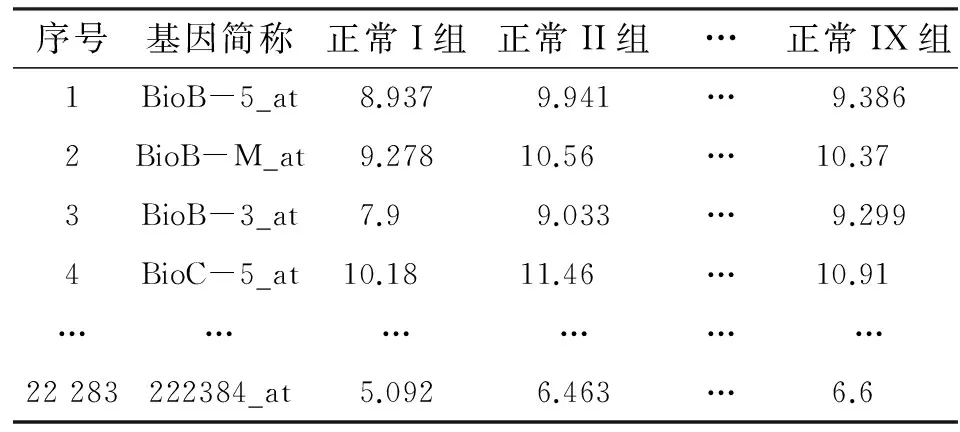
表 1 9組正常人體的22 283個基因表達(dá)水平數(shù)據(jù)表
由于31組患者的個體差異,使得如表1所示的列數(shù)據(jù)之間不可以相互比較.同時,假設(shè)同一程度的阿茲海默癥患者的基因表達(dá)水平數(shù)據(jù)具有相同的特征,即表1所示的各列數(shù)據(jù)間包含了相同或相似的特征集合.文獻(xiàn)[15]中詳細(xì)地闡述了對基因組表達(dá)數(shù)據(jù)運用SVD方法進(jìn)行數(shù)據(jù)建模并且處理得到了其特征集合.從而通過文獻(xiàn)[15]所述的方法可以得到正常、輕度、中度和重度4種不同程度的基因表達(dá)水平數(shù)據(jù)的特征集合.進(jìn)一步地,文獻(xiàn)[11]詳細(xì)地探討了PCA方法的理論和應(yīng)用以及其與SVD之間的關(guān)系.因此,本文通過PCA方法提取基因表達(dá)數(shù)據(jù)的特征集合,即主成分.
根據(jù)2.1節(jié)PCA方法的算法描述,于是分別對4種程度下的數(shù)據(jù)應(yīng)用PCA方法得到了對應(yīng)的特征空間.其特征值分布如圖1所示.
并且,進(jìn)一步可以分別計算出4種程度下的特征集的累計貢獻(xiàn)率CPR,如表2所示.
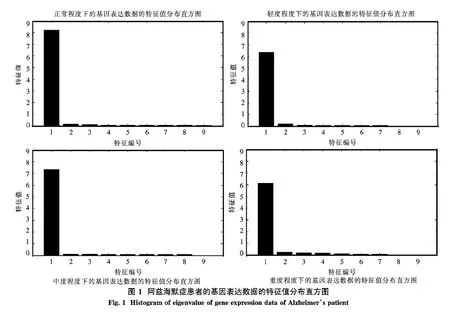
表 2 正常、輕度、中度和重度阿茲海默癥患者的基因表達(dá)數(shù)據(jù)的特征集的累計貢獻(xiàn)率表

特征集1特征集1~2特征集1~3特征集1~4特征集1~5特征集1~6特征集1~7特征集1~8特征集1~9正常0.910.930.950.960.970.980.980.991輕度0.910.940.960.970.980.991.00中度0.920.930.950.960.970.980.991.00重度0.870.910.940.960.970.991.00
從統(tǒng)計學(xué)意義上來說,若特征值集的累計貢獻(xiàn)率達(dá)到了85%~95%,該特征值集為數(shù)據(jù)集的主要特征.從而由表2的數(shù)據(jù)發(fā)現(xiàn),4種程度下的特征1上的累計貢獻(xiàn)率均已達(dá)到了85%.從而由特征1上的數(shù)據(jù)來反映原始數(shù)據(jù)是可行的.
接下來則需要檢驗其特征1的數(shù)據(jù)是否具有聚類趨勢以應(yīng)用其層次聚類方法.本文采用霍普金斯統(tǒng)計量來估計其聚類趨勢,使用0.5作為拒絕備擇假設(shè)閾值,即如果H>0.5,則D不大可能具有統(tǒng)計顯著的簇.根據(jù)2.2節(jié)的霍普金斯統(tǒng)計量的計算描述運用R語言編制出程序分別計算出它們在特征1上的霍普金斯統(tǒng)計量:正常組、輕度組、中度組、重度組的H值分別為0.051 1、0.037 8、0.068 4、0.097 1.可以發(fā)現(xiàn)H均遠(yuǎn)遠(yuǎn)小于0.5,即接受備擇假設(shè),也意味著4種程度下的特征1上的數(shù)據(jù)均具有統(tǒng)計顯著的簇.從而說明特征1上的數(shù)據(jù)具有聚類效果.于是聚類分析方法能夠被應(yīng)用到特征1上去挖掘出不同程度的阿茲海默癥患者的22 283個基因所反映出的聚類模式.
3 δ閾值層次聚類算法
在文獻(xiàn)[8]的基礎(chǔ)上,對層次聚類算法的閾值做出了說明,得到了δ閾值層次聚類算法.接下來,以9組正常人的基因表達(dá)數(shù)據(jù)為例來闡述該算法,由上一節(jié)可以得到9組正常人的基因表達(dá)水平數(shù)據(jù)的特征子空間,記為C.假設(shè)人體內(nèi)所有的基因在特征子空間C內(nèi)數(shù)據(jù)表示為Y=(yij)nm,其中,n=22 283且m為特征子空間C的維數(shù).并且設(shè)δ=(δ1,δ2,…,δm),其中,δi的計算規(guī)則在文獻(xiàn)[9]中也給出了.接下來給出δ閾值層次聚類方法的算法描述:
輸入:樣本點集合Y,閾值δ.

算法:
第1步,初始化K=1,S1=Y,且i=1;
第2步,令Z=Yi=(yji)n,1,并且計算出閾值δi;
第3步,若‖ysi-yti‖>δi,則s,t分別屬于2類,且K=K+1,SK-1=SK-1-{yt}以及SK=SK∪{yt},否則它們屬于同一類別,即SK=SK∪{yt};
第4步,記i=i+1,若i>m,則算法停止,否則轉(zhuǎn)向第2步.
根據(jù)上述的算法描述,可以得到4種不同程度患者的基因表達(dá)數(shù)據(jù)的聚類分析結(jié)果.并且通過對文獻(xiàn)[8]和文獻(xiàn)[9]的聚類結(jié)果比較評估2種層次聚類算法的聚類質(zhì)量.
4 實驗與結(jié)果
首先,將31組阿茲海默癥患者的基因表達(dá)數(shù)據(jù)劃分為正常、輕度、中度和重度4種程度.其次,對于每一種程度的基因表達(dá)數(shù)據(jù)分別應(yīng)用由文獻(xiàn)[8]和文獻(xiàn)[9]給出的δ閾值計算規(guī)則的層次聚類算法得到相應(yīng)的聚類模式.最后,對2組聚類模式衡量它們的聚類質(zhì)量進(jìn)行比較分析,通常是按照無基準(zhǔn)來選定方法:如果有可用的基準(zhǔn),外在方法可以比較聚類結(jié)果和基準(zhǔn),從而測定聚類質(zhì)量;如果沒有基準(zhǔn),則內(nèi)在方法通過考慮簇分離情況即簇的緊湊情況來評估聚類好壞.許多內(nèi)在方法都利用數(shù)據(jù)集的對象之間的相似性度量.這里,計算了衡量聚類質(zhì)量的指標(biāo)——輪廓系數(shù)SC,其相關(guān)的統(tǒng)計數(shù)據(jù)如表3所示.
最后,通過比較表3所示的數(shù)據(jù)發(fā)現(xiàn),文獻(xiàn)[8]對應(yīng)列的數(shù)據(jù)均大于文獻(xiàn)[9]中的數(shù)據(jù).
5 結(jié)語
結(jié)合文獻(xiàn)[8,9],本文給出了改進(jìn)地δ閾值層次聚類算法的算法描述.并且對阿茲海默癥基因數(shù)據(jù)應(yīng)用此層次聚類算法,通過比較聚類質(zhì)量指標(biāo)——輪廓系數(shù),可以發(fā)現(xiàn)文獻(xiàn)[8]通過特征集中的特征值確定的閾值較優(yōu)于文獻(xiàn)[9]通過曲率最大點確定的閾值.從而進(jìn)一步說明由文獻(xiàn)[8]給出的δ閾值的層次聚類算法較客觀,即本文對改進(jìn)地δ閾值層次聚類算法的參數(shù)δ做出了評估.
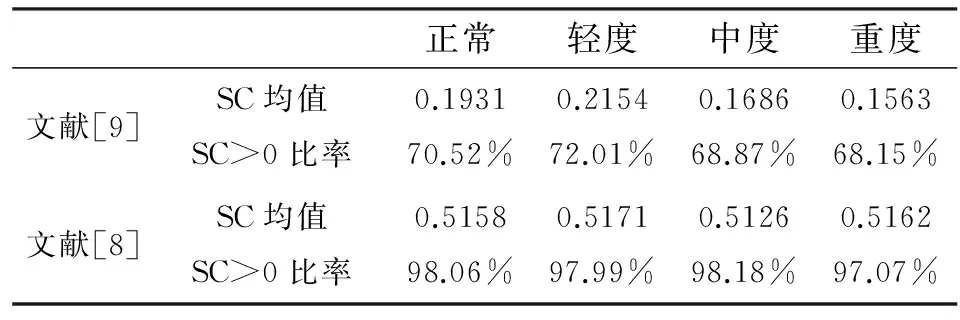
表 3 2類層次聚類算法的聚類質(zhì)量指標(biāo):輪廓系數(shù)的比較
[1] 阿茲海默病. http://zh.wikipedia.org/wiki/阿茲海默病[EB/OL]. 維基百科,2014.
[2] 李瑤. 基因芯片技術(shù):解碼生命[M]. 北京:化學(xué)工業(yè)出版社,2004:77-156.
[3] 胡本瓊,張先迪,龐朝陽. 利用圖論設(shè)計圖像壓縮中的向量量化聚類算法[J]. 四川師范大學(xué)學(xué)報:自然科學(xué)版,2005,28(3):376-378.
[4] 王開軍,李曉. 基于有效性指標(biāo)的聚類算法選擇[J]. 四川師范大學(xué)學(xué)報:自然科學(xué)版,2011,34(6):915-918.
[5] 莊劉,曾艷. 基于模糊C-均值聚類的最優(yōu)量化器設(shè)計[J]. 四川師范大學(xué)學(xué)報:自然科學(xué)版.2010,33(4):559-562.
[6] Kong W, Mou X Y, Yang B. Study DNA microarray gene expression data of Alzheimer’s disease by independent component analysis[J]. Bioinformatics, Systems Biology and Intelligent Computing,2009.
[7] Pang C Y, Hu W, Hu B Q, et al. A special local clustering algorithm for identifying the genes associated with Alzheimer’s disease[J]. IEEE Trans Nanobioscience,2010.
[8] Pang C Y, Liu S Q, Li Y, et al. The nonlinear correlation character of gene expression data on Alzheimer’s disease and hierarchy clustering of co-regulated gene[J]. 2011 IEEE International Conference on Granular Computing,2011.
[9] 黃靜,付如意,彭志紅,等. 基于阿爾茨海默病的基因表達(dá)數(shù)據(jù)改進(jìn)的一維聚類方法[J]. 四川師范大學(xué)學(xué)報:自然科學(xué)版,2015,38(4):584-588.
[10] 茆詩松,王靜龍,濮曉龍. 高等數(shù)理統(tǒng)計[M]. 2版. 北京:高等教育出版社,2006:128-135.
[11] Jonathon S. A tutorial on principal component analysis[D]. Ithaca:Cornell University,2014.
[12] Han J W, Kamber M, Pei J. Data Mining Concepts and Techniques[M]. Beijing:China Machine Press,2012.
[13] GEO DataSet. http://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE1297[EB/OL]. NCBI,2014.
[14] Blalock E M, Geddes J W, Chen K C, et al. Incipient Alzheimer’s disease:microarray correlation analyses reveal major transcriptional and tumor suppressor responses[J]. PNAS,2004,101(7):2173-2178.
[15] O Alter, P O Brown, D Botstein. Singular value decomposition for genome-wide expression data processing and modeling[J]. PNAS,2000,97(18):10101-10106.
2010 MSC:62H30; 62P10; 91C20
(編輯 周 俊)
Comparison of Two Hierarchical Clustering Methods in Gene Expression Data of Alzheimer’s Disease
FU Ruyi1, HUANG Jing1, HU Benqiong2, PANG Chaoyang3,4
(1.CollegeofMathematicsandSoftwareScience,SichuanNormalUniversity,Chengdu610066,Sichuan;2.CollegeofManagementScience,ChengduUniversityofTechnology,Chengdu610059,Sichuan;3.CollegeofComputerScience,SichuanNormalUniversity,Chengdu610066,Sichuan;4.VisualComputingandVirtualRealityKeyLaboratoryofSichuanProvince,SichuanNormalUniversity,Chengdu610066,Sichuan)
With the development of gene microarray technology, biclustering is applied to the research of high dimension of gene expression data. Due to the sparsity of most high-dimensional data, high-dimensional data are transferred into low-dimensional data by dimensionality reduction and so, it could be clustering in the low-dimensional data. Meanwhile, a variety of clustering appear different pattern and different data appears to different pattern for the established clustering. For gene expression data of Alzheimer’s disease, clustering tendency of feature sets is evaluated. Then, algorithm of improved hierarchical clustering with parameterδis described. References before establish computing method of parameterδ, respectively. Thus, two improved hierarchical clusterings with parameterδassigned different value are compared and clustering measure named silhouette coefficient is computed, respectively.
hierarchical clustering; threshold; gene expression data
2014-10-16
中國航空科學(xué)基金(2012ZD11)
O242.1
A
1001-8395(2015)06-0925-05
10.3969/j.issn.1001-8395.2015.06.025
*通信作者簡介:龐朝陽(1973—),男,教授,主要從事基因計算與量子力學(xué)的研究,E-mail:cypang402@126.com
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
