
基于大數據的城軌線路通過能力分析方法
2015-05-30 23:39:23楊文軒王偉
科技創新與應用 2015年36期
關鍵詞:大數據
楊文軒 王偉
摘 要:在城市軌道交通線路的升級改造中,需要通過牽引計算得到線路通過能力,分析改造后的系統能力是否滿足需求,為確定及改進設計方案提供依據。文章設計一種基于大數據分析技術的線路通過能力分析方法,利用海量CBTC歷史運營數據及通信數據計算系統能力。新的分析模型可充分提高面向線路升級改造的線路通過能力分析準確度,從而合理設計冗余,提高經濟效益,實現了對線路數據資源的有效利用。通過具體方案實現驗證該方法的可行性與準確性。
關鍵詞:通過能力;大數據;牽引計算;升級改造
1 概述
城市軌道交通線路通過能力是決定列車運行系統以及線路閉塞方案是否合理的重要依據之一。 為適應線路設備更新升級及網絡化運營的需求,對既有線的升級改造已經成為我國城市軌道交通建設的一項重要內容。能力分析結果用于對改造方案進行評估優化,而現有的分析模型通常來源于車輛和信號系統制造商提供的設計參數,不能完整真實地反映列車和信號設備在外部環境動態影響下的功能表現。因此,有必要從參數模型的角度,利用大數據方法對線路歷史運營數據進行分析挖掘,可以充分提高能力分析模型的準確度和應用價值。
2 能力分析與CBTC系統數據
2.1 線路升級改造中的能力分析
城市軌道交通線路的升級改造類型眾多,與信號系統相關的項目主要有線路結構改造、車輛擴編、能力瓶頸點擴能、信號系統升級擴容等。不同的升級改造項目對能力分析參數的關注有側重,也對能力分析的準確度提出了更高要求。線路的升級改造通常為增量更新,主要改造影響系統提升能力或需要擴容的部分,其他設備僅進行必要配套調整。因此,線路前期運營中產生的歷史數據對于升級改造方案的確定具有重要參考價值。
2.2 線路運營中的海量數據
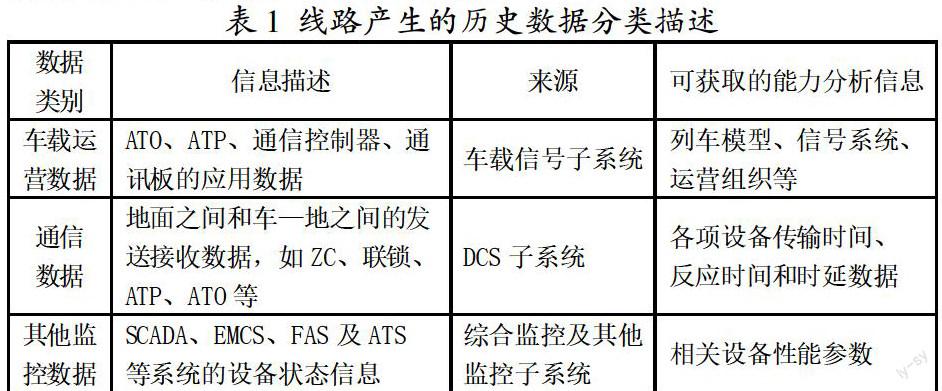
在城市軌道交通運營中,線路各子系統產生的歷史數據可真實反映線路運營,描述列車運行與設備工作狀態,為升級改造方案提供決策支持。數據及特征如表1所示。
2.3 能力分析模型的大數據特征
線路運營產生的系統數據量巨大。在CBTC系統中,車載ATP的設備記錄至少保留7天,文件大小約為幾十GB,一條線路一個月的數據量即可達到TB級;APM單臺主機單日的數據量也在GB級,匯集多種來源的數據后,數據量將更為龐大。此外,綜合監控等系統中包含大量半結構化的文本和圖像、視頻、配置文件等非結構化數據,如果要對這些數據加以利用,傳統的關系型數據庫難以滿足對于這種巨量復雜數據的承載及處理要求。大數據具有數據體量大、數據類型繁多、處理速度快、價值密度低的特點,其核心價值就在于對海量數據的存儲分析。因此,可應用大數據分析挖掘技術對能力分析模型進行優化。
3 基于大數據的能力分析方法設計
應用大數據進行線路通過能力分析的業務流程包括對系統數據的采集存儲、預處理、數據挖掘和牽引計算4個階段。方法核心是針對充分利用線路運營過程中CBTC及其他監控系統產生的海量數據,從參數模型的角度,研究外部環境對于能力分析模型參數取值普遍性、規律性的影響,對線路通過能力的限制條件進行挖掘細分,研究不同運營場景下的線路通過能力,對牽引計算數據模型和仿真模型進行改進。
3.1 線路和車輛模型優化
車輛模型主要指列車的牽引制動特性,線路模型數據包括線路、車站、坡度、曲率、折返區域、軌旁設備、線路限速、軌道分區及其限速、道岔及其限速等。由于列車運行過程中的工況復雜多變,站停時間、運營限速等線路運營參數和車輛模型參數往往隨運營條件動態變化。因此,不同的運營條件下線路條件和車輛性能不能僅用一套模型進行描述。在眾多大數據應用系統中,Hadoop表現出優越的運算效率。因此,分析模型將以Hadoop框架為核心進行整體設計。
3.1.1 原始數據獲取
CBTC車載子系統可記錄保存各系統的數據。將數據寫入HDFS框架作為基本數據存儲,經過預處理剔除格式錯誤及不完整的數據。由于可用數據僅占數據總體的一小部分,如車載ATP中與能力分析直接相關的運營數據僅占不到10%。因此,還需要將這些數據進行屬性選擇,剔除與列車運行曲線無直接關聯的數據,如軟件版本號、通信信息、開關量信息、列車位置標志、應答器信息、ZC切換信息、車門/屏蔽門控制信息等。利用HDFS分布式文件系統和HBase數據庫模型結構實現數據的并行化存儲。
3.1.2 模型動態參數合成
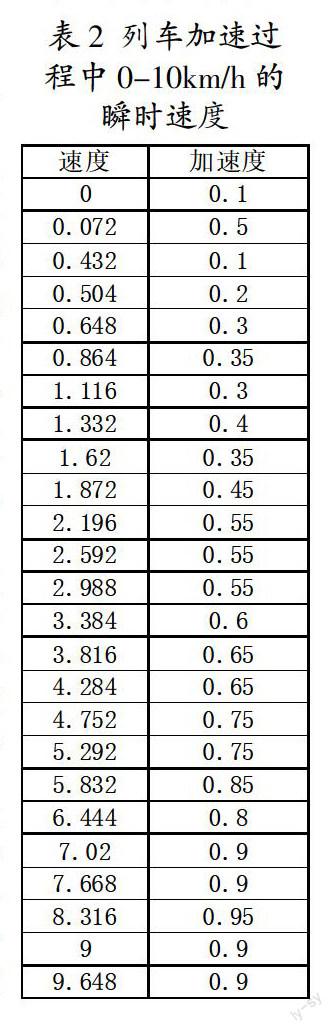
與列車運行相關的動態參數取值是決定模型準確度的重要因素之一。利用并行執行技術和運動學原理,根據瞬時速度的記錄信息,從車載ATP應用數據中計算列車回轉質量系數、分級牽引加速度、常用制動率、緊急制動率等參數,通過聚類分析對列車牽引制動特性進行分級,確定列車在實際運行的分級加速度與制動率,并確定對應級別的速度值。下面以列車分級加速度的合成步驟為例進行說明。
(1)速度屬性選擇。在并行執行條件下,針對加速度數據進行冗余屬性處理,根據瞬時速度的變化趨勢,剔除列車速度曲線中完全呈下降過程的數據,即表示列車減速的信息。(2)牽引加速度離散值的計算。根據運動學加速度公式分別對相鄰的離散瞬時速度值進行牽引加速度的計算,t取車載ATP的計算周期,表2中采集的數據周期為200ms。(3)牽引加速度分級。在列車性能參數中,列車的牽引加速度是根據速度值進行分級確定。在實際運行中列車的加速情況可以通過聚類方式進行確定,包括速度等級的劃分和對應的加速度值。由于K-Means方法計算速度快,且可以得到更緊密的簇,即得到的加速度分級更加嚴格準確,因此采用K均值聚類算法對每個加速過程的牽引加速度離散值進行分級,進行并行化實現。規定數據格式為(v,a),則問題轉換為對二維數據的聚類分析。在map過程中抽取其中一個分塊的部分數據為例說明,表2的數據是某列車從0-10km/h的加速過程,經聚類過程和平方誤差準則函數收斂,以聚類的個數確定加速度等級劃分,得到的牽引加速度分級結果為:(2,0.35);(4,0.58);(6.5,0.79);(10,0.92)四個聚類。要準確計算列車全加速過程的牽引特性,則需要通過大數據的并行計算實現。(4)列車運行過程的分級加速度確定。對各分塊執行的分級加速度進行度量,相鄰時間段內有個別較大偏離的表示列車性能受到外部條件干擾,進行剔除;利用歐幾里得度量判斷數據對象的相異度,如果有群體性的偏離數據產生,說明運營條件存在差異,需要通過劃分運營場景簇的方式進行3.1.3的過程;如果運營條件類似,則不會上述情況,對于剩余相同分級且加速度取值相近的數值進行均值處理即得到最終的分級加速度。
3.1.3 線路運營場景分布式挖掘
當運營環境發生變化時,用同一套模型描述列車運行狀態是不準確的。軌道交通系統作為一個復雜系統,車輛和信號設備的工況受到外部環境的影響,如高峰期列車滿載條件下,列車的牽引制動性能與平峰時段會有明顯差異;雨雪天氣下的列車性能、道岔等固定設備的性能與干燥條件下也不能一概而論。考慮到能力分析是信號系統的固有能力,因此只考慮可預見的因素對系統能力規律性的影響,通過聚類過程把運營條件按照相似性的原則劃分為若干類別。為避免多種因素對數據的共同影響,同時排除故障、突發狀況等不可控因素對聚類結果的影響,對單一影響因素的參數要分別進行聚類過程,并用多因素影響的參數進行驗證。以客流量和天氣為主要因素進行實驗。由于列車的牽引制動性能受到濕度和列車重量的共同影響,因此需要將天氣和客流量兩大因素同時考慮。與天氣和客流相關的車輛設備參數有:
(1)客流量影響參數:站停時間、回轉質量系數、列車質量;(2)天氣影響參數:運營限速、列車沖擊率、列車牽引加速度、列車常用制動減速度、列車緊急制動減速度、道岔動作時間。
為保證聚類質量,需要對數據進行篩選預估,研究單一因素時采用控制變量的方法,剔除掉可能從兩方面同時影響運營的數據,進行單一因素聚類;同時對列車的分級加速度和常用制動率分別進行聚類過程,以排除單一參數計算結果的偏差。聚類過程通過對CURE算法的并行化實現。完成數據標準化后,從所有運營數據中抽取一個隨機樣本S,這個數據樣本至少包含單列車一天的運營信息;再將數據分片處理為K個簇,通過Map過程計算簇之間的距離,由Reduce節點對這些簇進行統計合并。循環進行Map-Reduce過程,直到分區內的最近簇距離大于閾值,則完成聚類。聚類的結果即為不同的運營場景,對應建立不同的分析模型。
3.1.4 運營場景描述
場景描述是對運營數據挖掘的結果。完成運營數據獲取和場景聚類后,完成對于多次聚類過程的結果分析,異常值的處理等過程,獲取各運營場景下的線路參數及列車模型參數,即為最終的線路與列車模型。除線路參數為固定信息外,經數據挖掘得到的參數內容如表3所示。
3.2 信號系統參數模型獲取
為獲取準確的信號系統模型,需要提取CBTC系統的網絡通信數據。DCS管理系統可以實時記錄信號系統地面子系統之間與車-地之間的數據交互,通過查詢記錄文件可以查看網絡中的數據包信息。由于數據體量和集成的需要,同樣采用MapReduce進行分布式計算。對信號系統參數模型的提取包括以下過程。
3.2.1 數據信息獲取
從DCS中提取通信控制器ZC與其它地面子系統、聯鎖與其它地面子系統、地面子系統與車載ATP/ATO之間的數據交互中,與信號系統相關的數據發送時間、源IP、目的IP、數據包內容、數據包協議和數據長度等信息,并儲存在HDFS中。數據中的時間精度應足夠精確。
3.2.2 參數匹配與模型建立
主要任務是根據線路和列車模型中的參數,以及對運營場景的聚類結果,使通信數據與線路控車模型中的時鐘及設備的IP地址相匹配,即可對信號系統的各設備的動作時間及延時進行截取,并根據運營場景進行數據歸類。由于APM與時鐘系統進行時鐘同步,因此可將信號系統數據與運營數據相對應,根據已經完成的聚類過程確定通信數據所屬的應用范圍。對完成歸類的通信數據進行分析處理,得出最終的信號系統模型。建立的信號系統參數模型包括信號系統類型、閉塞制式、閉塞時間、車載設備處理時間、折返信號系統反應時間、道岔動作時間等。閉塞時間加上車載設備處理時間組成了正線系統反應時間。
3.2.3 利用行為數據進行知識發現
信號系統模型中包括一些與司機操作及乘客乘坐行為相關的參數,如啟動列車操作的反應時間、司機換端過程中的處理時間、旅客上下車時間等。目前這些參數通常以實際觀測和統計計算取經驗值,作為信號系統模型的一部分。可以發揮大數據知識發現的優勢,從CBTC車載數據中對這些數據進行提取,用以評價司機駕駛熟練程度、進行高峰期列車停站時間、折返時間的規劃等,為相關研究提供輔助支持。
3.3 牽引計算仿真模型應用
3.3.1 牽引計算通用模型
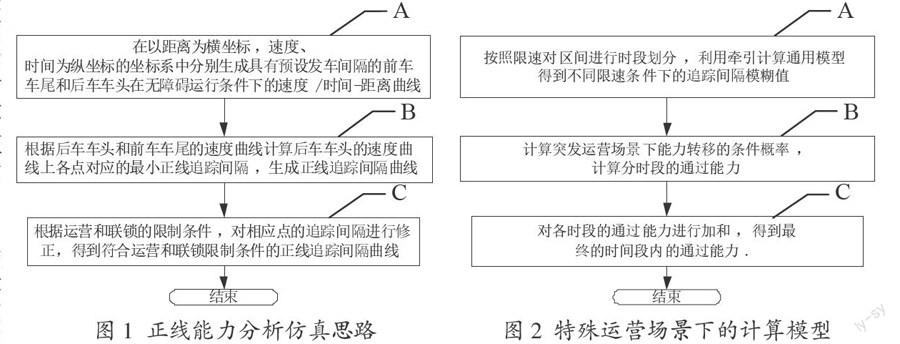
能力分析的牽引計算通用模型采用單車仿真算法實現,利用運動學原理對列車追蹤過程進行仿真,生成能力分析數據曲線。正線能力分析計算仿真的通用方法如圖1所示。
3.3.2 特殊運營場景下的計算模型
由于特殊運營場景下設備狀態和運營組織都會發生變化,影響系統能力,因此需要對突發情況持續時間T內的通過能力進行研究。經過數據建模已經對不同的運營場景進行了劃分,為研究臨時限速、站停時間延長導致晚點等特殊運營場景下的線路通過能力提供了數據準備。突發事件條件下能力計算有一定的不確定性。由于列車的平均旅行速度、停站時間、追蹤間隔等在一定程度上都具有模糊性,因此通過能力本身具有模糊性。利用模糊隨機過程對經牽引計算通用模型計算的結果進行處理,對區間能力的根據速度值進行再次細分,由速度轉移概率得到通過能力轉移概率,將各部分的通過能力求和后得出特殊運營場景下的系統能力,更能容錯各類因素及其不確定性,計算思路如圖2所示。
4 方法實現
根據以上建模方法進行基于大數據的線路通過能力分析平臺設計,并通過線路歷史運營數據進行驗證。系統架構包括數據處理層、算法層、業務處理層、應用層和決策層,整體架構及功能如圖3所示。系統實現包括Hadoop集群配置和牽引計算仿真兩部分。
4.1 Hadoop集群部署配置
主要目標是完成Hadoop環境的安裝配置。通過虛擬機設置實現遠程登錄和對數據節點的管理,通過Host文件修改、從節點用戶名添加、namenode、datanode配置等操作完成Hadoop安裝;配置連接參數,導入Hadoop類庫后進行數據處理的代碼編寫,最終打包成jar文件后部署到Hadoop環境上運行。
4.2 牽引計算仿真
牽引計算利用基于大數據的能力分析平臺實現。平臺由基礎數據庫、列車模型及信號系統數據庫、能力分析及評估和綜合仿真演示系統構成,如圖4所示。
系統根據基礎數據庫輸入和能力分析模型自動計算列車運行數據,生成列車運行V-S、T-S曲線,計算所需的正線間隔與折返、出入段間隔,輸出能力分析結果和安全距離,并通過能力評估給出提高能力的措施。利用北京地鐵7號線車載記錄系統CCOV及DCS的管理子系統APM的線路運營數據、通信數據對模型進行驗證,系統能夠準確對高峰、惡劣天氣、突發客流等條件下的運營場景進行分類,并計算出對應的系統能力,滿足線路升級改造中對于線路通過能力分析的需求。利用大數據合成的列車牽引計算曲線如圖5所示。
5 結束語
將大數據分析挖掘技術應用于城市軌道交通線路通過能力分析過程,提取線路歷史數據作為模型參數的來源,從參數模型的角度對線路通過能力進行研究,是對能力分析概念的深層次理解與應用,提高了能力分析的實用價值。方法可以對不同運營場景下的系統能力進行計算仿真,從應用角度提高了能力分析準確度,有助于線路升級改造方案的優化,從而合理設計冗余,提高經濟效益。這種方法充分利用了線路前期運營信息,實現了對數據資源的有效利用。今后應進一步充分利用CBTC系統數據的隱藏價值,從數據倉庫及牽引計算結果中深入挖掘有用信息,將大數據分析應用拓展到牽引供電、節能優化、人員培訓、設備健康管理等領域,實現資源多價值應用。
參考文獻
[1]趙剛.大數據技術與應用實踐指南[M].北京: 電子工業出版社, 2013.
[2]馬琳, 陳德旺, 吳智利.一種城軌移動閉塞正線通過能力的分析方法[J].鐵路計算機應用,2012, 21 (6): 11-14.
[3]王秀磊, 劉鵬.大數據關鍵技術[J].中興通訊技術, 2013, 19 (4): 17-21.
[4]賈琨.基于數據挖掘技術的交通信息處理與分析系統[D].山東師范大學, 2005.
作者簡介:楊文軒,在讀碩士研究生。
王偉,工程師。
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
