一種基于氣泡流控的改進(jìn)多播路由算法*
2015-07-10 01:23:50肖燦文董德尊龐征斌李存祿
計(jì)算機(jī)工程與科學(xué) 2015年2期
婁 輝,肖燦文,董德尊, 龐征斌,李存祿
(國防科學(xué)技術(shù)大學(xué)計(jì)算機(jī)學(xué)院,湖南 長沙 410073)
1 引言
隨著人們對(duì)芯片計(jì)算性能需求的不斷提升,單純依靠提高芯片時(shí)鐘頻率來提高整體計(jì)算性能的方法已經(jīng)很難滿足性能的需要,因此當(dāng)前片上系統(tǒng)大多通過增加芯片上集成的處理器核的數(shù)目來進(jìn)一步提升性能。片上網(wǎng)絡(luò)通過通信鏈路連接多個(gè)處理器核,這種方式與基于總線的互連相比,能夠?qū)崿F(xiàn)更低的通信延遲、更高的吞吐量和更低的能耗。片上網(wǎng)絡(luò)作為不同處理器核之間的通信部件,其性能對(duì)片上系統(tǒng)的整體性能會(huì)產(chǎn)生很大影響。當(dāng)前片上多處理器系統(tǒng)研究大多致力于提升單播通信的性能,然而許多并行應(yīng)用和程序模型都需要支持多播。例如,在基于目錄的 Cache 一致性[1]協(xié)議中,大量依賴多播和廣播通信特性去維持請(qǐng)求間的順序,并通過廣播作廢不同Cache節(jié)點(diǎn)上的共享數(shù)據(jù)塊;而在基于令牌的 Cache 一致性協(xié)議[2]中也需要使用多播收集令牌。在不同的Cache 一致性協(xié)議通信模型中,多播通信占網(wǎng)絡(luò)總通信量的3.1%~12.4%[3]。因此,設(shè)計(jì)一種針對(duì)多播通信的高效的路由算法將會(huì)有效提升片上網(wǎng)絡(luò)的通信性能。表1列出了不同協(xié)議下多播通信占系統(tǒng)總通信量的比例。從表1可以看出,多播通信在網(wǎng)絡(luò)中所占的比例很大,這些聚合通信對(duì)多核系統(tǒng)的性能會(huì)產(chǎn)生顯著的影響,即使網(wǎng)絡(luò)中注入很少的多播包,網(wǎng)絡(luò)吞吐量也會(huì)明顯下降。為了避免這些重要的聚合通信成為整個(gè)片上系統(tǒng)性能提升的瓶頸,片上網(wǎng)絡(luò)必須支持多播通信這種重要的通信模式。路由算法決定了網(wǎng)絡(luò)中報(bào)文的通信形式,同時(shí)不同的路由算法對(duì)網(wǎng)絡(luò)中帶寬的利用、平均報(bào)文時(shí)延、飽和吞吐率以及能耗等都有很大的影響。對(duì)于多播也是一樣,不同的多播路由算法也會(huì)顯著影響網(wǎng)絡(luò)資源的利用效率。因此,一個(gè)高效的多播路由算法對(duì)多處理器系統(tǒng)來說至關(guān)重要。
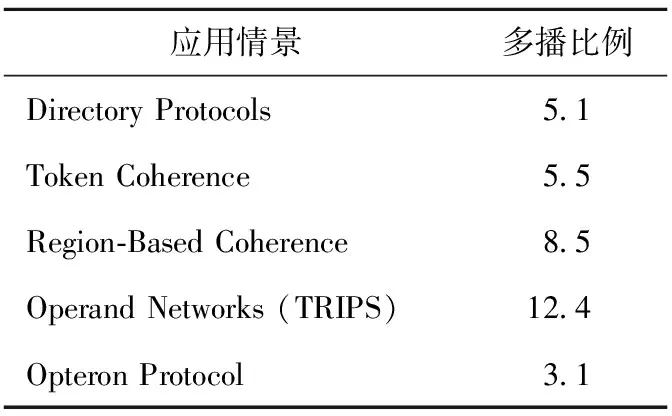
Table 1 Proportion of multicast in the network
多播和廣播是一個(gè)源節(jié)點(diǎn)向一個(gè)目的節(jié)點(diǎn)集合發(fā)送同樣的數(shù)據(jù)信息的通信模型。多播報(bào)文通信的主要目標(biāo)是為多播報(bào)文選擇一條最優(yōu)路徑,使得報(bào)文在該路徑上傳播所占用的通道帶寬盡可能少,并使該報(bào)文的傳播延遲盡可能短。報(bào)文死鎖會(huì)明顯降低多播通信的性能,因此在多播路由設(shè)計(jì)中應(yīng)保證報(bào)文傳播不會(huì)產(chǎn)生死鎖。多播通信對(duì)網(wǎng)絡(luò)的整體性能產(chǎn)生很大影響,因此當(dāng)前的許多工作對(duì)如何設(shè)計(jì)高效的多播路由算法以提高片上網(wǎng)絡(luò)整體性能進(jìn)行了研究。
當(dāng)前已有很多針對(duì)多播通信的路由算法,例如,基于樹的多播路由算法[4]保證多播報(bào)文盡可能地沿著共同路徑傳輸,當(dāng)需要發(fā)往不同方向的目標(biāo)節(jié)點(diǎn)時(shí)進(jìn)行報(bào)文復(fù)制,從而使多播報(bào)文以樹的形式發(fā)送到所有目標(biāo)節(jié)點(diǎn)。該方法的一個(gè)明顯缺陷是容易產(chǎn)生擁塞,當(dāng)傳播樹中有一個(gè)分支擁塞時(shí),其它的分支也會(huì)被阻塞,擁塞的產(chǎn)生使得該方法的網(wǎng)絡(luò)吞吐率很低。基于路徑的多播路由算法限制多播報(bào)文沿著同一路徑依次通過各個(gè)目標(biāo)節(jié)點(diǎn),報(bào)文首先到達(dá)離源節(jié)點(diǎn)最近的目的節(jié)點(diǎn),然后到達(dá)較遠(yuǎn)的節(jié)點(diǎn),并在報(bào)文到達(dá)目的節(jié)點(diǎn)時(shí)進(jìn)行復(fù)制。這種方法往往使得報(bào)文傳播的路徑很長,從而增加了報(bào)文的傳輸延遲。由于片上網(wǎng)絡(luò)在面積、能耗和性能等方面都有嚴(yán)格的限制,因此這些方法不適合在片上網(wǎng)絡(luò)使用。虛電路樹多播路由VCTM(Virtual Circuit Tree Multicasting)[3]是片上網(wǎng)絡(luò)中一種重要的多播路由算法。該算法只需要添加較少的存儲(chǔ)空間就能夠有效地支持多播與廣播。但是,該算法有三個(gè)缺點(diǎn):(1)為維持多播信息需要額外的存儲(chǔ)空間,從而增加了芯片的面積;(2)傳播過程中需要多播包的建立信號(hào),從而增加了網(wǎng)絡(luò)中的延時(shí);(3)即使是同樣的目的節(jié)點(diǎn)集,如果多播源節(jié)點(diǎn)改變,VCTM也必須重新建立多播樹進(jìn)行多播通信。這些缺陷使得VCTM不能很好地運(yùn)用到大規(guī)模網(wǎng)絡(luò)中。支持廣播的邏輯劃分路由BLBDR(Broadcast Logic-Based Distributed Routing)[5]通過劃分工作區(qū)域來有效隔離有缺陷的區(qū)域,同時(shí)關(guān)閉不需要的網(wǎng)絡(luò)區(qū)域,從而有效降低能耗。該方法確定了NOC中層虛擬化的概念,對(duì)網(wǎng)絡(luò)的不同區(qū)域進(jìn)行隔離通信。但是,如果目的節(jié)點(diǎn)集合散落到不同的網(wǎng)絡(luò)部分,則該算法的性能會(huì)明顯降低,這是因?yàn)樵摲椒ê茈y確定一個(gè)能夠覆蓋所有的目的節(jié)點(diǎn)的區(qū)域,因此該調(diào)度算法在片上網(wǎng)絡(luò)多播通信中并不適用。遞歸劃分多播路由算法RPM (Recursive Partitioning Multicast)[6]由于存在緩存資源利用的不均衡,其性能也受到了相應(yīng)影響,本文后續(xù)部分將進(jìn)行詳細(xì)分析。均衡自適應(yīng)多播路由算法BAM (Balanced Adaptive Multicast)[7]采用的死鎖避免方法,影響了網(wǎng)絡(luò)通道資源的利用率,本文就是針對(duì)RPM和BAM算法的不足提出了新的基于氣泡流控的多播路由算法。
本文的主要貢獻(xiàn)總結(jié)如下:
(1)改進(jìn)了多播路由算法(RPM和BAM)的死鎖避免方法。通過加入氣泡(即空閑虛通道)的方法來避免死鎖,該方法釋放了為了防止死鎖而預(yù)留的網(wǎng)絡(luò)緩存資源,從而更有效地利用了網(wǎng)絡(luò)的緩沖資源,提升了網(wǎng)絡(luò)的性能。
(2)對(duì)該方法的無死鎖性進(jìn)行了論述。
(3)評(píng)估了不同流量模型下改進(jìn)的RPM和BAM的性能,同時(shí)評(píng)估了改進(jìn)的BAM在不同網(wǎng)絡(luò)資源下的敏感性及可擴(kuò)展性。
本文其余部分組織如下:第2節(jié)介紹了我們的多播路由算法的實(shí)現(xiàn)過程;第3節(jié)介紹路由器流水線和微體系結(jié)構(gòu);第4節(jié)評(píng)估了不同路由算法的性能,并與我們提出的方法進(jìn)行了比較,同時(shí)總結(jié)了模擬結(jié)果;最后是本文的結(jié)論。
2 多播路由算法
本文針對(duì)RPM和BAM兩種多播路由算法存在的不足,提出一種新的多播路由算法。RPM能夠根據(jù)包當(dāng)前所在的地址,將網(wǎng)絡(luò)劃分成八個(gè)區(qū)域。根據(jù)報(bào)文目的節(jié)點(diǎn)在這八個(gè)區(qū)域的位置,采用一系列的優(yōu)先級(jí)規(guī)則計(jì)算出報(bào)文去每個(gè)區(qū)域的優(yōu)先的輸出端口。RPM盡可能多地使報(bào)文沿著同一條路徑傳輸來減小網(wǎng)絡(luò)帶寬的使用,之后進(jìn)行復(fù)制操作,將復(fù)制的包傳輸?shù)礁鱾€(gè)目的節(jié)點(diǎn)。但是,為了防止多播路由的死鎖,RPM采用了兩個(gè)虛擬網(wǎng)絡(luò)VN0和VN1,VN0只傳輸向上的報(bào)文,VN1只傳輸向下的報(bào)文。這種死鎖避免的方法使水平方向的緩存成為了性能的瓶頸,它被VN0和VN1同時(shí)使用而垂直方向的只有一個(gè)方向使用。這種方法由于不同維度的緩存資源的使用不均衡影響了它的性能。BAM也是根據(jù)包當(dāng)前所在的地址,將網(wǎng)絡(luò)劃分成八個(gè)區(qū)域,但它根據(jù)各輸出端口的擁塞程度選擇到達(dá)目的區(qū)域具有較低擁塞程度的輸出端口,從而高效地使用鏈路帶寬。BAM為了防止死鎖,將Duato 的單播死鎖避免理論[8]運(yùn)用到多播路由算法上,將網(wǎng)絡(luò)中的虛通道劃分為適應(yīng)性虛通道和逃逸虛通道。一旦多播包進(jìn)入逃逸虛通道,后續(xù)路由算法就按維序路由進(jìn)行報(bào)文復(fù)制。這種死鎖避免的方法,當(dāng)網(wǎng)絡(luò)要發(fā)生死鎖的時(shí)候才用逃逸虛通道,所以網(wǎng)絡(luò)中的逃逸虛通道在網(wǎng)絡(luò)使用的概率比較小。它使網(wǎng)絡(luò)的虛通道的資源沒有充分利用,造成資源浪費(fèi),導(dǎo)致網(wǎng)絡(luò)性能不能充分發(fā)揮。當(dāng)多播報(bào)文進(jìn)入逃逸虛通道時(shí)報(bào)文只能夠進(jìn)行維序路由。這種路由方法是為了保證無死鎖而犧牲了網(wǎng)絡(luò)中的帶寬,從而使帶寬不能充分利用,網(wǎng)絡(luò)延時(shí)增大。由于在逃逸虛網(wǎng)絡(luò)中向北和向南傳輸?shù)膱?bào)文不能夠轉(zhuǎn)變方向,造成了網(wǎng)絡(luò)不同維度間的資源的不均衡。
基于對(duì)RPM和BAM的觀察與分析,本文提出了一種新的多播死鎖避免方法。這種死鎖避免方法是在網(wǎng)絡(luò)的垂直方向注入氣泡(Bubble),取消RPM和BAM的兩個(gè)網(wǎng)絡(luò)。以BAM為例簡述新死鎖避免方法,改進(jìn)BAM簡稱BAM-B。
BAM-B是在BAM基礎(chǔ)上提出來的,首先敘述BAM的均衡自適應(yīng)多播路由算法。BAM首先根據(jù)報(bào)文的位置將網(wǎng)絡(luò)劃分成八個(gè)區(qū)域,分別為 0、1、2、3、4、5、6、7,如圖1所示。位于 1、3、5 和 7 中的目標(biāo)節(jié)點(diǎn)只有一個(gè)輸出端口到達(dá), 因此多播報(bào)文目標(biāo)節(jié)點(diǎn)中有處于 1、3、5 或 7的,則對(duì)應(yīng)的北、西、南或東輸出端口一定會(huì)被選擇使用,這些端口被稱作必須輸出端口。而處于區(qū)域0、2、4、6的多播報(bào)文目標(biāo)節(jié)點(diǎn),源節(jié)點(diǎn)有兩個(gè)方向輸出端口可以到達(dá)它們。網(wǎng)絡(luò)中報(bào)文傳輸遵守如下規(guī)則:(1)如果目標(biāo)節(jié)點(diǎn)只有一個(gè)必須端口,則沿著必須端口傳輸數(shù)據(jù)。(2)如果沒有必須輸出端口或有兩個(gè)必須輸出端口,則報(bào)文沿最低擁塞的輸出端口方向傳輸。以上是BAM與BAM-B相同的地方,下面是本文提出的改進(jìn)算法不同的地方。
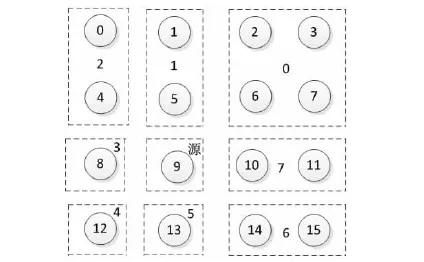
Figure 1 Network regional division schematic diagram圖1 網(wǎng)絡(luò)區(qū)域劃分示意圖
不同的主要地方在于對(duì)死鎖的處理方式。不失一般性,考慮多播源節(jié)點(diǎn)位于如圖1所示的位置,考慮多播包向北輸出端口傳輸,且目標(biāo)節(jié)點(diǎn)集都在北向這一維的不轉(zhuǎn)維的情況,即目的節(jié)點(diǎn)集中不帶有0和2區(qū)域的節(jié)點(diǎn),則不需要加入氣泡(即空虛通道),虛通道全部分配給包進(jìn)行虛通道VC(Virtual Channel)分配。當(dāng)去目標(biāo)節(jié)點(diǎn)存在一次路由轉(zhuǎn)維時(shí),此例子中即目的節(jié)點(diǎn)集中存在0或2區(qū)域的目的節(jié)點(diǎn),則將VC中加入氣泡,即留一個(gè)切片緩存區(qū),其它的全部分配給包進(jìn)行VC分配。
死鎖發(fā)生的情況如圖2所示,A包占據(jù)通道U請(qǐng)求通道V,B包占據(jù)通道V請(qǐng)求通道W,C包占據(jù)通道W請(qǐng)求通道X,D包占據(jù)通道X請(qǐng)求通道U。
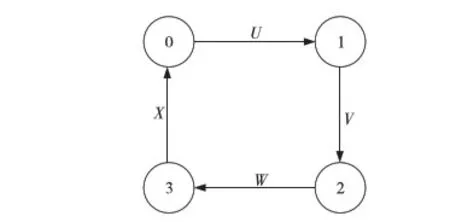
Figure 2 Packet deadlock situation圖2 報(bào)文發(fā)生死鎖情況
文獻(xiàn)[9]證明了在Mesh網(wǎng)絡(luò)中通過注入氣泡來提高單播完全自適應(yīng)路由網(wǎng)絡(luò)性能的方法是無死鎖的。但是,它沒有涉及網(wǎng)絡(luò)中存在多播的情況。由于Cache 一致性協(xié)議的多播包大量用于傳輸網(wǎng)絡(luò)中的控制信息,同時(shí)片上有大量的連線資源,所以可以將這些信息用單切片的多播包傳輸。在網(wǎng)絡(luò)中傳輸?shù)膯吻衅亩嗖グ鱾€(gè)復(fù)制的切片相互獨(dú)立,類似于單播包。
所以新的多播路由算法與網(wǎng)絡(luò)中注入氣泡的單播完全自適應(yīng)路由算法有類似的性質(zhì)且都是無死鎖的。下面將描述新的多播路由算法是無死鎖的:
(1)如果X中的虛通道中所有的報(bào)文都請(qǐng)求U,由改進(jìn)新的路由算法知X通道中必然存在一個(gè)空閑VC。W中請(qǐng)求X虛通道的報(bào)文必有一個(gè)能夠請(qǐng)求成功,則W中的報(bào)文可以繼續(xù)向X通道傳輸。因此,W中將有空閑VC,V可以請(qǐng)求W,則這種情況下存在一個(gè)報(bào)文可以移動(dòng)。
(2)如果X中的所有VC都被占用,由改進(jìn)的新路由算法知X通道中必然存在一個(gè)報(bào)文到達(dá)目的節(jié)點(diǎn)(可以排出)或脫離該環(huán)(不請(qǐng)求U,向上傳輸),則將產(chǎn)生新的空閑VC。W中請(qǐng)求X虛通道的報(bào)文必有一個(gè)能夠請(qǐng)求成功,W中的報(bào)文可以繼續(xù)向X通道傳輸,則在這種情況下存在一個(gè)報(bào)文可以移動(dòng)。
綜上所述,這種新的多播路由算法是無死鎖的。與RPM的死鎖避免方法不同,新的多播死鎖避免方法解決了RPM 為了防止死鎖而采用兩個(gè)虛擬網(wǎng)絡(luò)造成的網(wǎng)絡(luò)緩存資源使用不均衡的問題;與BAM的死鎖避免方法也不同,解決了BAM為防止網(wǎng)絡(luò)死鎖采用逃逸虛通道而造成的虛通道的資源沒有充分利用,和逃逸虛通道中帶寬的不充分利用等問題。
3 路由器流水線和微體系結(jié)構(gòu)
本文選擇的基準(zhǔn)路由器是交叉開關(guān)分配虛通道路由器[10,11]。路由器使用預(yù)先選擇策略來提前選擇擁塞比較小的輸出端口,其原理是前一個(gè)時(shí)鐘預(yù)先選擇每個(gè)象限下一時(shí)鐘的優(yōu)先輸出端口。多播報(bào)文和單播報(bào)文采用經(jīng)典的五步流水線,單播報(bào)文流水線如圖3a所示和多播報(bào)文流水線如圖3b所示。
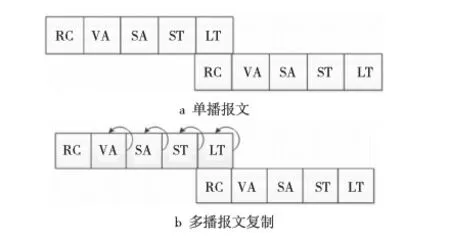
Figure 3 Packet pipeline圖3 報(bào)文的流水線
在多播通信模式下,在中間路由器,一個(gè)包需要去復(fù)制幾個(gè)拷貝的包。為了支持多播包的復(fù)制,路由器需要增加復(fù)制部件,修改在單播包情況下的虛通道分配器VA(Virtual Channel Allocator)和交叉開關(guān)分配器SA(Switch Allocator) 。由于Cache 一致性協(xié)議的多播報(bào)文一般傳輸?shù)氖强刂菩盘?hào),故網(wǎng)絡(luò)上傳輸?shù)亩嗖?bào)文都是單切片報(bào)文。路由器增加的復(fù)制部件僅僅是一些控制邏輯,多播包只有SA和VA分配成功才復(fù)制切片向下傳輸。這種情況下不需要等待所有的地址都分配成功才發(fā)送切片。滿足一個(gè)輸出端口則發(fā)送一個(gè)復(fù)制切片,只有當(dāng)所有的請(qǐng)求輸出端口都得到滿足時(shí) ,多播報(bào)文才能夠從輸入虛通道中移除。
圖4描述了路由器微體系結(jié)構(gòu)。Pre-selection 模塊為每個(gè)象限預(yù)先選擇了優(yōu)先的輸出端口,由于預(yù)先選擇模塊在報(bào)文進(jìn)行路由計(jì)算之前已經(jīng)預(yù)先選擇了優(yōu)先的輸出端口,故不會(huì)影響路由器關(guān)鍵路徑的延時(shí),單播報(bào)文和多播報(bào)文路由計(jì)算都會(huì)使用該模塊的預(yù)先選擇輸出信號(hào)來提前確定每個(gè)象限的優(yōu)先方向。
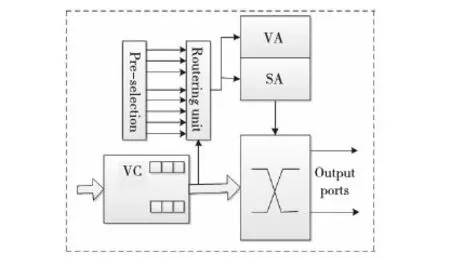
Figure 4 Router microarchitecture圖4 路由器微體系結(jié)構(gòu)
4 實(shí)驗(yàn)評(píng)估
本節(jié)評(píng)估所提出的死鎖避免方法與RPM和BAM結(jié)合使用時(shí)網(wǎng)絡(luò)性能的改進(jìn)。實(shí)驗(yàn)中主要使用合成流量模式[11],使用時(shí)鐘精確模擬器Booksim[11],對(duì)改進(jìn)的多播路由器微體系結(jié)構(gòu)進(jìn)行了細(xì)粒度建模。合成流量模式下評(píng)估RPM、BAM和本文提出的基于氣泡流控的RPM和BAM(分別記做RPM-B、BAM-B)。RPM需要將網(wǎng)絡(luò)劃分成兩個(gè)虛擬網(wǎng)絡(luò)(分別用于傳輸向上和向下的報(bào)文),故不需要配置逃逸虛通道,不會(huì)發(fā)生死鎖;BAM 的多播虛擬網(wǎng)絡(luò)也需要?jiǎng)澐謨蓚€(gè)虛擬網(wǎng)絡(luò)(自適應(yīng)網(wǎng)絡(luò)和逃逸虛網(wǎng)絡(luò)),逃逸虛網(wǎng)絡(luò)是為了防止死鎖。而RPM-B和BAM-B只有一個(gè)網(wǎng)絡(luò),它通過向網(wǎng)絡(luò)注入氣泡來防止死鎖。本實(shí)驗(yàn)在二維Mesh網(wǎng)絡(luò)中進(jìn)行評(píng)估。
多播報(bào)文與單播報(bào)文都包含一個(gè)切片,實(shí)驗(yàn)中使用多種合成流量模型[11],包括uniform random、transpose、bit rotation 和random permutation。網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)使用4×4、8×8的Mesh網(wǎng)絡(luò),多播報(bào)文目的節(jié)點(diǎn)數(shù)目與位置在網(wǎng)絡(luò)中均勻分布。表2給出了基準(zhǔn)實(shí)驗(yàn)配置參數(shù)和用于算法敏感性分析和它的擴(kuò)展性分析的參數(shù)。

Table 2 Configuration parameters in these experiments
4.1 性能
實(shí)驗(yàn)測試了RPM、RPM-B、BAM和BAM-B網(wǎng)絡(luò)的整體性能。RPM:兩個(gè)虛擬網(wǎng)絡(luò)分別用于傳輸向上和向下的報(bào)文;RPM-B: RPM路由算法的改進(jìn),只有一個(gè)虛擬網(wǎng)絡(luò),在其網(wǎng)絡(luò)加入氣泡,即空VC避免死鎖;BAM:兩個(gè)虛擬網(wǎng)絡(luò)分別是自適應(yīng)網(wǎng)絡(luò);逃逸虛網(wǎng)絡(luò)和BAM-B:BAM路由算法的改進(jìn),只有一個(gè)虛擬網(wǎng)絡(luò),在其網(wǎng)絡(luò)加入氣泡,即空VC。
4.1.1 網(wǎng)絡(luò)的整體性能
圖5給出了網(wǎng)絡(luò)的路由算法在uniform random、transpose、bit rotation 和random permutation四種不同的合成流量模型下網(wǎng)絡(luò)的整體性能。
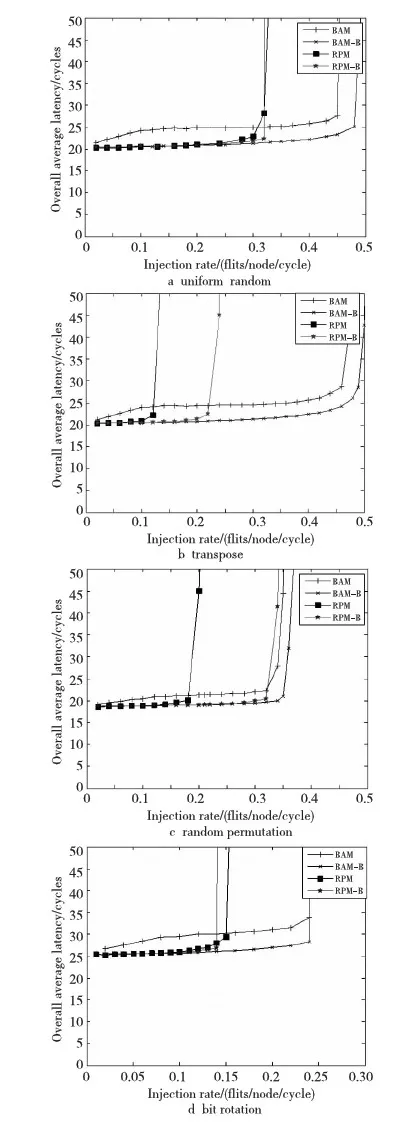
Figure 5 Performance of different synthetic loads圖5 不同合成負(fù)載下的性能
將RPM-B和BAM-B與RPM和BAM 進(jìn)行比較,從圖5中看到取得了性能的提升,報(bào)文的平均延時(shí)都得到了降低,而網(wǎng)絡(luò)的飽和吞吐量除了bit rotation合成流量負(fù)載下RPM-B的性能比RPM性能稍差外,其他的飽和吞吐率得到了提升。uniform random 合成流量模型下BAM-B飽和吞吐率提升了6.3%,網(wǎng)絡(luò)平均延時(shí)下降了8.6%。而RPM-B相對(duì)于RPM來說,網(wǎng)絡(luò)的平均延時(shí)在注入率比較高時(shí)得到了下降,而網(wǎng)絡(luò)吞吐率沒有明顯提升。因?yàn)镽PM分為兩個(gè)網(wǎng)絡(luò),在流量比較低的時(shí)候資源和RPM-B基本上一樣,對(duì)性能沒有多大的影響,當(dāng)網(wǎng)絡(luò)流量比較高時(shí),RPM不同維度間緩存資源的不均衡性顯現(xiàn),導(dǎo)致報(bào)文的延時(shí)增大。transpose和random permutation合成流量模型下BAM-B相對(duì)于BAM飽和吞吐率分別提升了4.1%、5.5%,平均網(wǎng)絡(luò)延時(shí)降低了15.4%、15.0%;而RPM-B相對(duì)于RPM飽和吞吐率分別提升了71.4%、75%,網(wǎng)絡(luò)平均延時(shí)降低了24.9%、12.7%。由于transpose和random permutation兩種合成流量負(fù)載模型對(duì)于RPM將網(wǎng)絡(luò)分成兩個(gè)虛擬網(wǎng)絡(luò)的算法,更容易造成網(wǎng)絡(luò)中不同維度間緩存資源的不均衡,所以網(wǎng)絡(luò)中的平均吞吐率提升和網(wǎng)絡(luò)平均延時(shí)的下降都比較明顯。BAM在不同維度緩存資源相對(duì)均衡,只有逃逸虛通道網(wǎng)絡(luò)存在緩存資源不均衡問題,所以網(wǎng)絡(luò)平均吞吐率相對(duì)增加較少,網(wǎng)絡(luò)平均延時(shí)下降沒有RPM-B的明顯。而在bit rotation模型下,BAM-B相對(duì)于BAM飽和吞吐率沒有得到提升,網(wǎng)絡(luò)平均延時(shí)降低了12.2%;RPM-B相對(duì)于RPM飽和吞吐率和網(wǎng)絡(luò)平均延時(shí)都沒有得到很好的提升。
4.1.2 多播的性能
圖6給出了網(wǎng)絡(luò)中只有多播報(bào)文時(shí)網(wǎng)絡(luò)的整體性能,BAM-B相對(duì)于BAM飽和吞吐率提升了16.7%,網(wǎng)絡(luò)平均延時(shí)降低17.30%,網(wǎng)絡(luò)中全都是多播報(bào)文相比網(wǎng)絡(luò)中存在單播報(bào)文的流量模型,使網(wǎng)絡(luò)中的報(bào)文更容易進(jìn)入逃逸網(wǎng)絡(luò),更容易成為網(wǎng)絡(luò)的瓶頸,從而改進(jìn)后使網(wǎng)絡(luò)飽和吞吐率提升最大,網(wǎng)絡(luò)平均延時(shí)降低最大。RPM-B相對(duì)于RPM平均網(wǎng)絡(luò)延時(shí)僅僅在網(wǎng)絡(luò)注入率比較高的時(shí)候才有少許的性能提高,而網(wǎng)絡(luò)飽和吞吐率提升了6.7%,由于網(wǎng)絡(luò)中都是多播包,當(dāng)網(wǎng)絡(luò)注入率比較低時(shí)RPM和RPM-B都能夠有效地使用網(wǎng)絡(luò)的資源,性能基本相當(dāng),而當(dāng)網(wǎng)絡(luò)注入率比較高時(shí)由于RPM把網(wǎng)絡(luò)分成向上和向下的網(wǎng)絡(luò),造成網(wǎng)絡(luò)不同維度的通道使用率不同,導(dǎo)致相對(duì)于RPM-B更容易發(fā)生飽和。
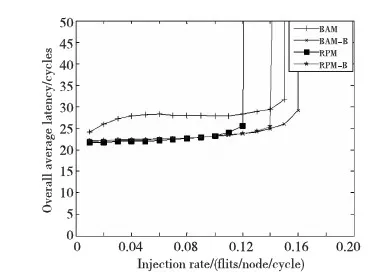
Figure 6 Performance under 100% the proportion of multicast packets圖6 100%多播報(bào)文比例下的性能
4.2 敏感性分析
為了分析本文方法對(duì)網(wǎng)絡(luò)整體性能影響和可擴(kuò)展性方面的影響,進(jìn)一步開展敏感性分析實(shí)驗(yàn)。由于RPM與BAM有類似的性質(zhì),不再討論RPM與它的改進(jìn)算法對(duì)于各種資源的敏感性分析。我們主要以BAM與BAM-B為分析對(duì)象,圖7對(duì)多播改進(jìn)性能在虛通道數(shù)目、多播報(bào)文比例、多播報(bào)文的平均目標(biāo)節(jié)點(diǎn)數(shù)、網(wǎng)絡(luò)規(guī)模四個(gè)方面對(duì)網(wǎng)絡(luò)性能與可擴(kuò)展性進(jìn)行分析。
4.2.1 虛通道數(shù)目
圖7a給出了虛通道配置分別是8個(gè)VC、6個(gè)VC、4個(gè)VC時(shí)網(wǎng)絡(luò)的性能。從圖7a中可以看到,當(dāng)虛通道數(shù)為8個(gè)VC、6個(gè)VC、4個(gè)VC時(shí),網(wǎng)絡(luò)吞吐量分別提升6.3%、8.8%、14.2%,延時(shí)分別下降8.6%、8.1%、14.2%。當(dāng)配置較小的虛通道時(shí),由加氣泡的方法來避免死鎖帶來了性能的很大提升。
主要有兩個(gè)方面因素影響了性能:(1)虛通道比較少時(shí),緩存資源稀缺性增強(qiáng),增加氣泡的方法可以使逃逸虛通道的緩存資源釋放,釋放稀缺的緩存資源。隨著虛通道數(shù)的增加,緩存資源的稀缺性逐漸降低,當(dāng)8個(gè)VC時(shí),網(wǎng)絡(luò)飽和吞吐率只有6.3%的提升,而4個(gè)VC時(shí),網(wǎng)絡(luò)飽和吞吐率提升14.2%。
(2)由于BAM由自適應(yīng)網(wǎng)絡(luò)和逃逸虛網(wǎng)絡(luò)組成,逃逸虛網(wǎng)絡(luò)中采取維序路由的算法,使多播通道重用的概率降低,增加了網(wǎng)絡(luò)延時(shí);同時(shí),由于逃逸虛通道只有符合維序路由的包才能夠注入,使得垂直方向和水平方向的網(wǎng)絡(luò)使用情況不均衡,這種不均衡性隨著網(wǎng)絡(luò)中虛通道的減小更加明顯,所以虛通道少時(shí),改進(jìn)算法的延遲下降更明顯。
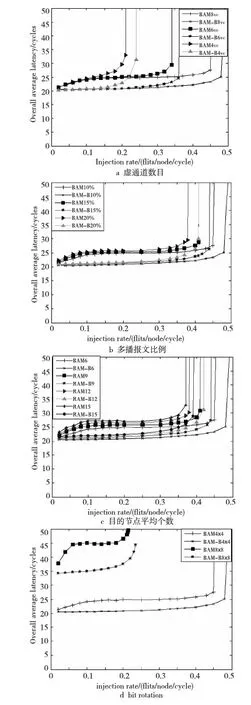
Figure 7 Performance under different network parameters圖7 不同網(wǎng)絡(luò)參數(shù)下的性能
4.2.2 多播報(bào)文比例
圖7b給出了多播比例配置不同時(shí)網(wǎng)絡(luò)的性能及可擴(kuò)展性分析。從圖7b中可以看,到多播比例分別是10%、15%、20%時(shí),網(wǎng)絡(luò)的平均延時(shí)降低分別為13.80%、14.40%、14.80%,網(wǎng)絡(luò)的吞吐率提升分別為8.6%、7.3%、7.9%。改進(jìn)的多播路由算法隨著網(wǎng)絡(luò)多播包比例的提高,平均延時(shí)降低越明顯,因?yàn)殡S著網(wǎng)絡(luò)中多播報(bào)文的增加,網(wǎng)絡(luò)中總的報(bào)文數(shù)量也在大量增加。在BAM中進(jìn)入逃逸虛通道的報(bào)文數(shù)量也增加,從而增加網(wǎng)絡(luò)中報(bào)文的網(wǎng)絡(luò)延時(shí),降低了網(wǎng)絡(luò)的吞吐率。多播比例增加時(shí),加入氣泡避免死鎖的方法能夠提供更多的網(wǎng)絡(luò)資源,延時(shí)下降更為明顯,使得延時(shí)下降比例從13.80% 提升到14.80%。
4.2.3 多播報(bào)文的平均目標(biāo)節(jié)點(diǎn)數(shù)
圖7c給出了多播目的節(jié)點(diǎn)數(shù)量配置不同時(shí)網(wǎng)絡(luò)的性能及可擴(kuò)展性分析。從圖7c中可以看到,多播目的節(jié)點(diǎn)數(shù)量分別為6、9、12、15時(shí),網(wǎng)絡(luò)的平均延時(shí)分別降低13.80%、14.70%、15.30%、16.60%,網(wǎng)絡(luò)的吞吐率分別提升8.6%、7.3%。10.50%、8.1%。可見,多播平均節(jié)點(diǎn)數(shù)目對(duì)網(wǎng)絡(luò)延時(shí)與吞吐率的影響,與多播報(bào)文比例對(duì)網(wǎng)絡(luò)性能的影響類似。
4.2.4 網(wǎng)絡(luò)規(guī)模
圖7d給出了4×4 Mesh、8×8 Mesh網(wǎng)絡(luò)性能,本文方法的網(wǎng)絡(luò)平均延時(shí)分別下降13.80%、18.1%,網(wǎng)絡(luò)飽和吞吐率提升分別為8.6%、9.8%。由于8×8 Mesh網(wǎng)絡(luò)中節(jié)點(diǎn)數(shù)目比4×4 Mesh網(wǎng)絡(luò)中的節(jié)點(diǎn)數(shù)目多,報(bào)文需要走過更多的路徑才能到達(dá)目的節(jié)點(diǎn)。所以,從圖7d中可以看到,對(duì)于網(wǎng)絡(luò)的延時(shí),8×8網(wǎng)絡(luò)比4×4網(wǎng)絡(luò)延時(shí)明顯增大,同時(shí)改進(jìn)后的網(wǎng)絡(luò)平均延時(shí)降低比率也從13.8%增加到18.1%,網(wǎng)絡(luò)的飽和吞吐率提升比例從8.6%提升到9.8%。由于網(wǎng)絡(luò)規(guī)模的增大對(duì)于BAM來說,包進(jìn)入逃逸虛通道避免死鎖的機(jī)會(huì)更大,更容易使逃逸虛通道成為網(wǎng)絡(luò)性能提升的瓶頸,而BAM-B能夠更好地利用網(wǎng)絡(luò)的資源,去掉了逃逸虛通道,解除了網(wǎng)絡(luò)性能提升的瓶頸,使網(wǎng)絡(luò)平均延時(shí)明顯降低,吞吐率明顯增加。
5 結(jié)束語
在當(dāng)前的眾核系統(tǒng)中,支持多播的片上網(wǎng)絡(luò)變得非常重要。它不僅可以提高網(wǎng)絡(luò)的飽和吞吐率,也可以降低網(wǎng)絡(luò)的平均延時(shí),提高網(wǎng)絡(luò)帶寬的利用率。不同多播路由算法對(duì)網(wǎng)絡(luò)資源的利用和網(wǎng)絡(luò)中報(bào)文的分布至關(guān)重要,從而對(duì)網(wǎng)絡(luò)的飽和吞吐率和平均網(wǎng)絡(luò)延時(shí)有極大的影響。
本文提出的通過網(wǎng)絡(luò)中加入氣泡,即空閑虛通道的方式來避免網(wǎng)絡(luò)中的死鎖,充分釋放了網(wǎng)絡(luò)中的緩沖資源,提高了網(wǎng)絡(luò)性能。我們提出的新多播路由算法,相對(duì)于最先進(jìn)的多播路由算法,減少了網(wǎng)絡(luò)的平均延時(shí)和提升了網(wǎng)絡(luò)的飽和吞吐率。網(wǎng)絡(luò)平均延時(shí)相對(duì)于最先進(jìn)的多播路由算法降低了18.1%,飽和吞吐率相對(duì)于最先進(jìn)的多播路由算法提升了16.7%。相對(duì)于RPM路由算法改進(jìn)后的飽和吞吐率最大提升75%,平均延時(shí)最大下降24.9%。
[1] Chaiken D,Field C,Kurihara K,et al.Directory-based cache coherence in large scale multiprocessors[J]. Computer,1990, 23 (6):49-58.
[2] Martin M M K, Hill M D, Wood D A. Token coherence:Decoupling performance and correctness[C]∥Proc of the 30th International Symposium on Computer Architecture, 2003:182-193.
[3] Jerger N E, Peh L-S, Lipasti M, et al. Virtual circuit tree multicasting:A case for on-chip hardware multicast support[C]∥Proc of ISCA, 2008:229-240.
[4] Malumbres M P, Duato J, Torrellas J. An efficient implementation of tree-based multicast routing for distributed shared-memory multiprocessors[C]∥Proc of IPDPS,1996:186-189.
[5] Rodrigo S, Flich J, Duato J, et al. Efficient unicast and multicast support for CMPs[C]∥Proc of MICRO’08, 2008:364-375.
[6] Wang L, Jin Yu-hu, Kim H, et al. Recursive partitioning multicast:A bandwidth-efficient routing for networks-on-chip[C]∥Proc of NOCS’09, 2009:64-73.
[7] Ma S, Jerger N E, Wang Z Y. Supporting efficient collective communication in NoCs[C]∥Proc of HPCA’12, 2012:165-176.
[8] Duato J. A new theory of deadlock-free adaptive routing in wormhole networks [J].IEEE Transactions on Parallel and Distributed Systems, 1993,4(12):1320-1331.
[9] Xiao Can-wen, Zhang Min-xuan, Dou Yong, et al. Dimensional bubble flow control and fully adaptive routing in the 2-D mesh network on chip[C]∥Proc of EUC’08,2008:353-358.
[10] Jerger N E, Peh L. On-chip networks [M]. 1st ed. California:Morgan & Claypool Publishers, 2009.
[11] Dally W, Towles B. Principles and practices of interconnection networks [M]. San Francisco:Morgan Kaufmann Publishers Inc, 2003.
