基于Lucene全文檢索系統(tǒng)的設(shè)計與實現(xiàn)*
2015-07-10 01:11:38周敬才胡華平
計算機(jī)工程與科學(xué) 2015年2期
周敬才,胡華平,2,岳 虹
(1.61070部隊,福建 福州 350003;2.國防科學(xué)技術(shù)大學(xué)計算機(jī)學(xué)院,湖南 長沙 410073)
1 引言
近年來, 信息技術(shù)的快速發(fā)展加快了企業(yè)信息化的進(jìn)程, 同時也促進(jìn)了企業(yè)的發(fā)展,隨著企業(yè)信息的大量增加, 電子文檔數(shù)目也急劇膨脹, 如何在海量信息中快速、準(zhǔn)確、全面地查找企業(yè)所需的信息資料已成為信息檢索研究領(lǐng)域內(nèi)的一個熱門課題。全文檢索技術(shù)是一種非常高效的信息檢索技術(shù),它使人們可以在各種文本中快速檢索到所需內(nèi)容,極大地提高了海量數(shù)據(jù)檢索的效率。
Lucene[1]是Apache軟件基金會Jakarta項目組的一個子項目,是一個純Java編寫的開放源代碼的全文檢索工具[2],程序員們不僅使用它構(gòu)建具體的全文檢索應(yīng)用,而且將之集成到各種系統(tǒng)軟件中構(gòu)建Web應(yīng)用,甚至某些商業(yè)軟件也采用了Lucene作為其內(nèi)部全文檢索子系統(tǒng)的核心。近幾年,學(xué)者對基于Lucene全文檢索的應(yīng)用研究層出不窮,如行業(yè)應(yīng)用[3,4]、圖像視頻檢索[5]、全文檢索技術(shù)研究[6~13]以及Web應(yīng)用[14~18]等。文獻(xiàn)[6~10]通過改進(jìn)中文倒排序方法,提升了索引檢索效率;文獻(xiàn)[11,12]分別在中文分詞器方面進(jìn)行比較和優(yōu)化,提高了中文分詞的準(zhǔn)確度;文獻(xiàn)[13]研究了Lucene與MySQL在檢索性能方面的差異;文獻(xiàn)[14]基于.Net、文獻(xiàn)[15~18]基于Servlet分別設(shè)計實現(xiàn)了Lucene全文檢索系統(tǒng),但這些系統(tǒng)在文檔解析類型、中文分詞、數(shù)據(jù)顯示等功能上存在一定的不足之處,此外系統(tǒng)在實現(xiàn)上更多是實驗測試,沒有經(jīng)過海量數(shù)據(jù)的實際檢驗,系統(tǒng)實用性方面略顯不夠。
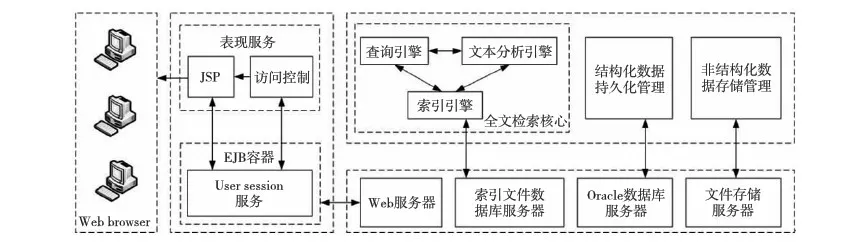
Figure 1 Architecture of system圖1 系統(tǒng)結(jié)構(gòu)
本文在前述Lucene各項應(yīng)用研究的基礎(chǔ)上,結(jié)合輕量級JavaEE應(yīng)用框架SSH(Spring+Struts+Hibernate),提出了一種基于模型-視圖-控制器MVC(Model View Control)分層思想[19]的全文檢索模型,能夠較好地支持各類通用文檔格式的高效解析,有效改進(jìn)了中文分詞算法,提升了中文分詞的準(zhǔn)確度,增加了檢索結(jié)果高亮顯示的人機(jī)交互方式;設(shè)計并實現(xiàn)了一套面向海量文本數(shù)據(jù)的全文檢索系統(tǒng),系統(tǒng)較好地實現(xiàn)了海量文本數(shù)據(jù)的快速索引和檢索,且已經(jīng)投入實際應(yīng)用。此外,本文提出基于MVC模式的Web全文檢索模型,適合于門戶網(wǎng)站以及企業(yè)內(nèi)部海量文本資源的檢索,通過簡單靈活的二次開發(fā),可以快速集成到C/S和B/S模式的信息系統(tǒng)。
2 系統(tǒng)結(jié)構(gòu)
全文檢索是指計算機(jī)索引程序通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現(xiàn)的次數(shù)和位置,當(dāng)用戶查詢時,檢索程序就根據(jù)事先建立的索引進(jìn)行查找,并將查找的結(jié)果反饋給用戶的檢索方式。這個過程類似于通過字典中的檢索字表查字的過程。
本系統(tǒng)具有建立索引、處理查詢返回結(jié)果集、增加索引、優(yōu)化索引結(jié)構(gòu)等全文檢索核心功能,外圍由結(jié)構(gòu)化數(shù)據(jù)管理、文件上傳下載管理等不同應(yīng)用功能組成。本系統(tǒng)結(jié)構(gòu)如圖1所示。索引引擎、查詢引擎、文本分析引擎以及各種外圍應(yīng)用子系統(tǒng)等共同構(gòu)成了本系統(tǒng)。
本系統(tǒng)包括文件上傳模塊、文檔解析模塊、分詞模塊、索引創(chuàng)建模塊、數(shù)據(jù)檢索模塊、數(shù)據(jù)顯示模塊及文件下載等模塊,各模塊工作流程如圖2所示。
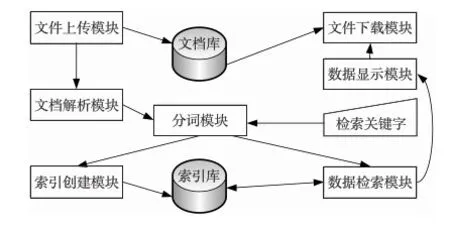
Figure 2 Workflow for each module in system圖2 系統(tǒng)各模塊工作流程
3 關(guān)鍵技術(shù)
3.1 基于MVC模式的Web全文檢索模型
MVC已是一種應(yīng)用廣泛的標(biāo)準(zhǔn)設(shè)計模式,該模式將軟件系統(tǒng)劃為三個主要部分,即模型-視圖-控制器。本文在基于MVC模式分層思想的基礎(chǔ)上,提出了基于MVC模式的Web全文檢索模型。如圖3所示,該模型在表現(xiàn)層完成文檔各類相關(guān)數(shù)據(jù)的顯示、查詢等功能;業(yè)務(wù)層完成文檔增、刪、改、查、上傳、下載、全文檢索等功能的業(yè)務(wù)邏輯管理;應(yīng)用中間層以組件方式提供文件持久化、上傳下載以及全文檢索核心功能;數(shù)據(jù)層則實現(xiàn)了結(jié)構(gòu)化數(shù)據(jù)入庫、各類文檔以及文件索引的本地化存儲。
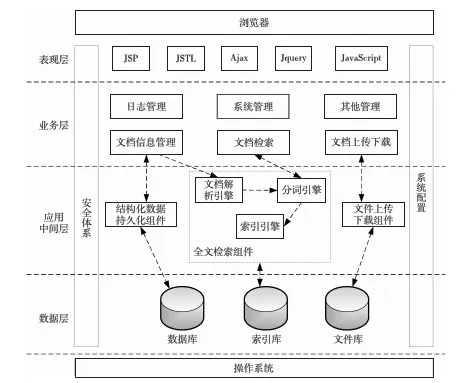
Figure 3 Full-text search model based on MVC圖3 基于MVC模式的Web全文檢索模型
3.2 中文分詞器的改進(jìn)
在Lucene 內(nèi)部提供了幾個分詞工具,如WhitespaceAnalyzer、SimpleAnalyzer、StopAnalyzer及StandardAnalyzer等分析器。但是,這些分析器中除了StandardAnalyzer具備部分中文分詞功能外,其他幾個分詞器基本都是針對西方文字而開發(fā)的。當(dāng)前應(yīng)用于Lucene 的中文分詞器主要有IK_CAnalyzer、PaodingAnalyzer、MMAnalyzer(JE分詞)和CJKAnalyzer。CJKAnalyzer是Apache一個基于Java 語言的開源子項目,是一款針對中日韓語系的分詞工具包,該工具包提供了三種分詞方法:ChineseAnalyzer、CJKAnalyzer和SmartChineseAnalyzer。SmartChineseAnalyzer中文分詞功能支持度相對較強(qiáng)。本文重點比較了SmartChineseAnalyzer、PaodingAnalyzer、MMAnalyzer三種中文分詞器,以“全文檢索技術(shù)設(shè)計與實現(xiàn)”為例,測試結(jié)果如表1所示。
從表1中可以看到,SmartChineseAnalyzer在性能上稍微優(yōu)于PaodingAnalyzer,但分詞結(jié)果后者則更為出色,本系統(tǒng)從分詞效果、性能、擴(kuò)展性以及可維護(hù)性來綜合考慮,采用PaodingAnalyzer,通過擴(kuò)展org.apache.lucene.analysis軟件包,用庖丁分詞器有效改進(jìn)了中文分詞效率與準(zhǔn)確度。

Table 1 Comparison for three chinesewords segmentation analyzer
3.3 基于組件技術(shù)的多文檔解析
Lucene只定義了一個抽象文檔的結(jié)構(gòu)Document,沒有定義具體的數(shù)據(jù)源, 因此在各種應(yīng)用中, 必須采用合適的轉(zhuǎn)換器把數(shù)據(jù)源轉(zhuǎn)換成相應(yīng)的Document結(jié)構(gòu),才能實現(xiàn)文檔解析。針對不同的文檔格式,需要采用不同的組件或者軟件包實現(xiàn)文檔的相應(yīng)解析,比如,利用HTMLParser組件實現(xiàn)對HTML格式的抽取,利用POI組件實現(xiàn)對MS Office文檔的抽取,利用Xpdf組件及其中文補(bǔ)丁包實現(xiàn)PDF格式的文本抽取,而針對TXT文件直接使用Java的字符流來讀取。本系統(tǒng)使用組件技術(shù),通過抽象出文件解析工廠類,屏蔽了不同格式之間的解析差異,采用抽象接口和動態(tài)實例化的方法為用戶屏蔽了各種文檔格式間的差異性, 使其具有統(tǒng)一處理多種格式文檔的能力,實現(xiàn)了對HTML、PDF、MS Office以及TXT等常規(guī)文件格式的文本內(nèi)容透明抽取,文檔解析過程如圖4所示。
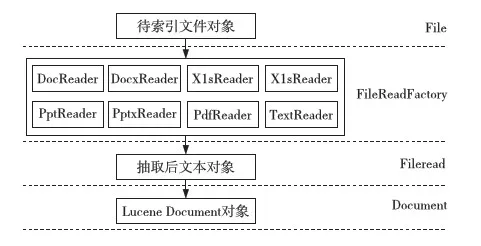
Figure 4 Parsing process for document圖4 文檔解析過程
3.4 數(shù)據(jù)顯示模塊
系統(tǒng)實現(xiàn)了類似Baidu、Google檢索結(jié)果顯示效果,即對關(guān)鍵字相同的詞條進(jìn)行高亮顯示。Lucene的org.apache.lucene.search.highlight包中提供了關(guān)于高亮顯示檢索關(guān)鍵字的工具,通過構(gòu)造的高亮格式對象,生成org.apache.lucene.search.highlight.highlighter實例;然后將檢索結(jié)果中的文本內(nèi)容進(jìn)行切分,找到與檢索關(guān)鍵字相同或相似的詞條,將高亮格式加入到摘要文本中,返回一個新的、帶有格式的摘要文本,在網(wǎng)頁上即可呈現(xiàn)高亮顯示結(jié)果。核心代碼如下。
Document doc=hits.doc(i);
String text=doc.get(fieldName);
SimpleHTMLFormatter simpleHTMLFormatter=new SimpleHTMLFormatter("〈font color='red'〉", "〈/font〉");
Highlighter highlighter=new Highlighter(simpleHTMLFormatter,new QueryScorer(query));
highlighter.setTextFragmenter(new SimpleFragmenter(text.length()));
TokenStream tokenStream=analyzer.tokenStream(fieldName,new StringReader(text));
String highLightText=highlighter.getBestFragment(tokenStream, text);
4 實驗結(jié)果
系統(tǒng)部署環(huán)境如圖5所示,服務(wù)端共部署四臺服務(wù)器,Web服務(wù)器通過Weblogic 9.1提供高性能Web服務(wù),數(shù)據(jù)庫服務(wù)器采用Oracle10g對結(jié)構(gòu)化數(shù)據(jù)進(jìn)行存儲,文件服務(wù)器主要將上傳的文件集中存儲,索引服務(wù)器保存上傳文件生成的各類索引信息。
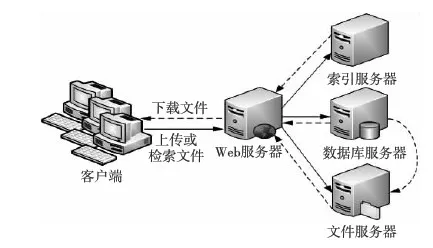
Figure 5 Deployment diagram for the system圖5 系統(tǒng)部署圖
系統(tǒng)當(dāng)前已存儲MS Office、PDF、TXT等各類文本信息達(dá)36 GB,索引服務(wù)器的CPU型號為Xeon E5-2603 1.8 GHz,內(nèi)存為12 GB DDR3。以DOC、PDF、TXT三類文檔為例,分別針對三類文檔測試了100 KB以下、500 KB以下及1 MB以下三個不同大小文檔的文本解析速度、索引建立速度與數(shù)據(jù)檢索速度,測試結(jié)果如表2所示。測試結(jié)果表明,文件類型及大小決定了文本解析與索引建立的速度,但對數(shù)據(jù)檢索速度影響不大,系統(tǒng)在實際應(yīng)用過程中,基本能夠滿足用戶文件存儲及快速檢索的需求,具備良好的穩(wěn)定性與較高的應(yīng)用價值。
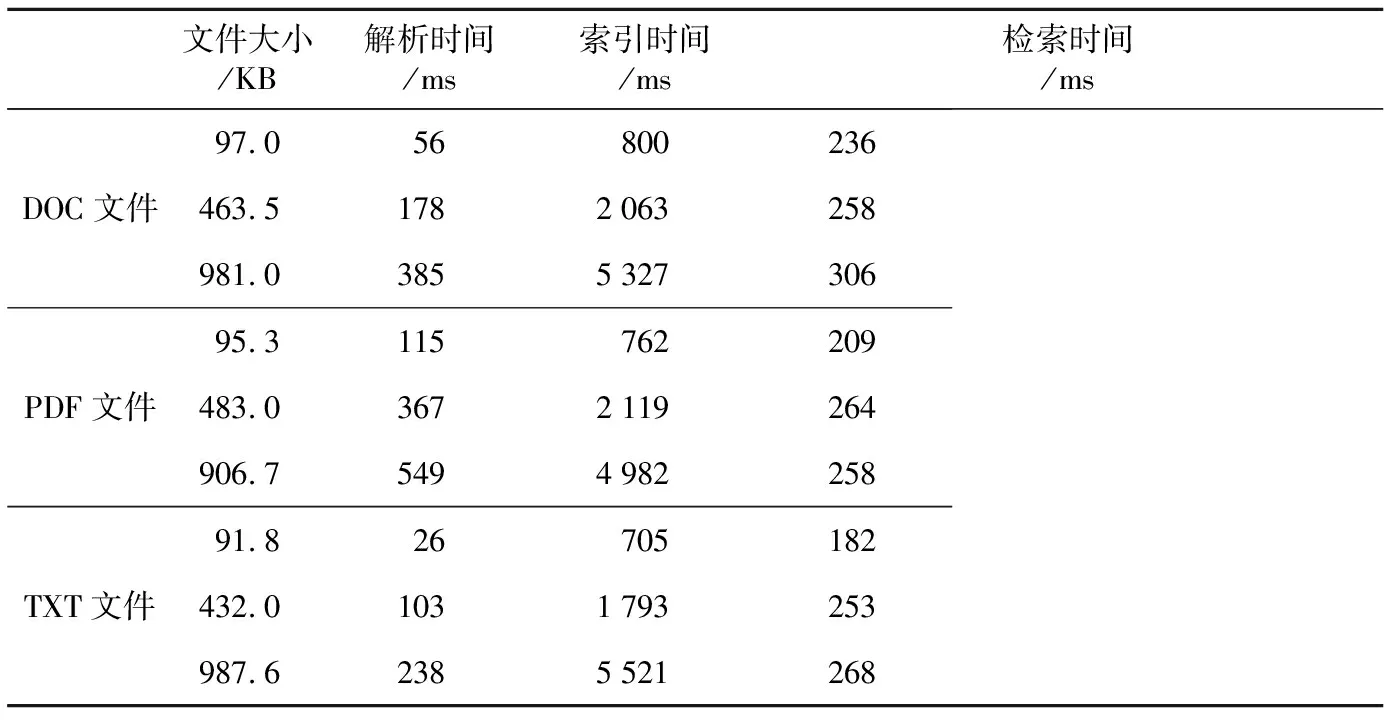
Table 2 Test results
5 結(jié)束語
本文在Lucene全文檢索框架的基礎(chǔ)上,擴(kuò)展了文檔解析功能,對各類常規(guī)文檔格式具備更好的支持,改進(jìn)了中文分詞器,提高了中文分詞效率,設(shè)計并實現(xiàn)了一個高效快速的全文檢索系統(tǒng)。系統(tǒng)主要需要在兩個方面進(jìn)一步改進(jìn),一是進(jìn)一步改進(jìn)中文分詞器,本系統(tǒng)僅將現(xiàn)有對中文支持較好的庖丁分詞器集成到系統(tǒng)中,并未進(jìn)行二次優(yōu)化;二是系統(tǒng)在查全率上與其他同類系統(tǒng)沒有明顯優(yōu)勢,需要進(jìn)一步改善。目前,該系統(tǒng)已應(yīng)用到實際業(yè)務(wù)工作中較好地滿足了常規(guī)業(yè)務(wù)需求。
[1] Xu Ye-qiang, Zhu Yan-hui, Li Chun-liang. The design and implementation of massive database full-text retrieval based on Lucene[J]. Journal of Hunan University of Technology, 2011,25(2):81-82.(in Chinese)
[2] Huang Jiang-ping, Huang Li-can, Xu Ling. Implementation of PDF full-text retrieval based on Lucene[J]. Industrial Control Computer,2012,25(5):103. (in Chinese)
[3] Xia Tian, Huang Wen, Ma Jun-tao, et al. Research and application fo Lucene in the academic information service platform construction[J]. Library and Information Service,2011,27(12):88-89. (in Chinese)
[4] Huang Kui, Zhu Xing-dong. The realization of the retrival model based Lucene in IETM[J]. Micro-Computer Information, 2011,55(21):106-109. (in Chinese)
[5] Jiang Xin, Yu Ping. Research and implementation of Lucene-based retrieval system of audio and vedio resources[J]. Computer Applications and Software, 2011,28(11):245-248. (in Chinese)
[6] Zheng Rong-zeng,Lin Shi-ping.Research of Chinese full texts inverted index based on Lucene[J]. Computer Technology and Development, 2010, 20(3):80. (in Chinese)
[7] Tsai Chih-Hao.MMSEG:A word identification system for mandarin Chinese text based on two variants of the maximum matching algorithm[EB/OL].[2000-03-12]. http://technology. chtsai.org/mmseg.
[8] Moffat A, Webber W, Zobel J.Load balancing for term-distributed parallel retrieval[C]∥Proc of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 2006:348-355.
[9] Butlerm H, Rutherford J. Distributed Lucene:A distributed free text index for Hadoop[EB/OL].[2012-03-25].http://www.hpl.hp.com/techreports/2008/HPL-2008-64.pdf.
[10] Sajja K. Performance study of Lucene in parallel and distributed environments[D].Boise:Boise State University,2011.
[11] Peng Huan-feng.Design and implementation of Chinese words segmentation machine based on Lucene[J]. Micro-Computer & its Applications, 2011, 30(18):62-64. (in Chinese)
[12] Yi Tian-peng, Chen Qi-an. Comparison research of segmentation performance for Chinese analyzers based on Lucene[J]. Computer Engineering, 2012, 38(22):279-282. (in Chinese)
[13] Wu Dai-wen, Yang Fang-qi. The performance study of database full-text retrieval based on Lucene[J]. Micro-Computer Applications, 2011, 32(6):53-58. (in Chinese)
[14] Tang Tie-bing, Chen Lin, Zhu Wei-hua. Research and implementation of full text retrieval component based on Lucene[J]. Computer Applications and Software, 2010, 27(2):197-199. (in Chinese)
[15] Ding Zhao-gui,Jin Min.Research and implementation of personal search engine based on Lucene[J]. Computer Technology and Development, 2011, 21(2):105-108. (in Chinese)
[16] Zou Yan-fei, Yu Cheng-zun, Zhao Liang. Design and implementation of text search engine based on Lucene[J]. Computer and Modernization, 2011, 193(9):40-42. (in Chinese)
[17] Li Xue-li, Huang Li-can, Fan Chen-xi. Design and implementation of documents management system based on Lucene[J]. Industrial Control Computer, 2012, 25(10):87-88. (in Chinese)
[18] Li Yong-chun, Ding Hua-fu. Research and application of full text search based on Lucene[J]. Computer Technology and Development, 2010, 20(2):12-15. (in Chinese)
[19] Li Hai-feng. Study on application of MVC model architecture[J]. Automation & Instrumentation, 2013,165(1):4. (in Chinese)
[20] The apache software foundation.Apache Lucene-Query Parser Syntax[EB/OL]. [2010-06-18].http://lucene.apache.org/java/2_9_3/queryparsersyntax.html.
附中文參考文獻(xiàn):
[1] 徐葉強(qiáng),朱艷輝,栗春亮. 基于Lucene的海量數(shù)據(jù)庫全文檢索的設(shè)計與實現(xiàn)[J].湖南工業(yè)大學(xué)學(xué)報,2011,25(2):81-82.
[2] 黃江平,黃理燦,徐玲. 基于Lucene的PDF文檔的全文檢索的實現(xiàn)[J].工業(yè)控制計算機(jī),2012,25(5):103.
[3] 夏天,黃文,馬駿濤,等. Lucene全文檢索軟件及其在學(xué)科信息服務(wù)平臺中的應(yīng)用[J]. 圖書館情報工作,2011,55(21):106-109.
[4] 黃葵,朱興動. 基于Lucene的IETM系統(tǒng)檢索器的設(shè)計實現(xiàn)[J]. 微計算機(jī)信息,2011, 27(12):88-89.
[5] 姜鑫,余平. 基于Lucene的音視頻資源檢索系統(tǒng)的研究與實現(xiàn)[J].計算機(jī)應(yīng)用與軟件,2011, 28(11):245-248.
[6] 鄭榕增,林世平. 基于Lucene的中文倒排索引技術(shù)的研究[J].計算機(jī)技術(shù)與發(fā)展,2010, 20(3):80.
[11] 彭煥峰. 基于Lucene的中文分詞器的設(shè)計與實現(xiàn)[J]. 微型機(jī)與應(yīng)用,2011, 30(18):62-64.
[12] 義天鵬,陳啟安. 基于Lucene的中文分析器分詞性能比較研究[J]. 計算機(jī)工程,2012, 38(22):279-282.
[13] 吳代文,楊方琦.Lucene在數(shù)據(jù)庫全文檢索中的性能研究[J]. 微計算機(jī)應(yīng)用,2011, 32(6):53-58.
[14] 唐鐵兵,陳林,祝偉華. 基于Lucene的全文檢索構(gòu)件的研究與實現(xiàn)[J]. 計算機(jī)應(yīng)用與軟件,2010, 27(2):197-199.
[15] 丁兆貴,金敏. 基于Lucene的個性化搜索引擎研究與實現(xiàn)[J]. 計算機(jī)技術(shù)與發(fā)展,2011, 21(2):105-108.
[16] 鄒燕飛,于成尊,趙亮. 基于Lucene的文本搜索引擎的設(shè)計和實現(xiàn)[J]. 計算機(jī)與現(xiàn)代化,2011, 193(9):40-42.
[17] 李雪利,黃理燦,范晨熙. 基于Lucene的文檔管理系統(tǒng)的設(shè)計與實現(xiàn)[J]. 工業(yè)控制計算機(jī),2012, 25(10):87-88.
[18] 李永春,丁華福.Lucene 的全文檢索的研究與應(yīng)用[J]. 計算機(jī)技術(shù)與發(fā)展,2010, 20(2):12-15.
[19] 李海峰.MVC模式架構(gòu)的應(yīng)用研究[J].自動化與儀器儀表,2013,165(1):4.
猜你喜歡
工業(yè)設(shè)計(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
甘肅教育(2020年8期)2020-06-11 06:10:02
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
電子制作(2018年18期)2018-11-14 01:48:06
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
