基于谷歌距離的漢英詞表概念映射研究
2015-09-08 01:38:37張李義崔恒
現代情報 2015年3期
張李義 崔恒

[摘要]本文對《漢語主題詞表》(工程技術版)概念與英文超級科技詞表概念的映射進行研究,建立優化的漢對英有序映射模式,并采用基于谷歌距離的語義相似度算法進行實驗,計算英文詞之間的語義距離,導入原有漢英映射信息。通過實驗分析,獲得了按相似度排序的漢英映射模式,實現了多個英文詞匯與漢詞的對應并由高到低排列出來。該方法獲得的排序結果基本滿足要求,部分詞語需要人工修正。
[關鍵詞]語義相似度;漢語主題詞表;谷歌距離;概念映射
DOI:10.3969/j.issn.1008-0821.2015.03.001
[中圖分類號]TP391;G25 [文獻標識碼]A [文章編號]1008-0821(2015)03-0003-05
詞表映射研究是研究和建設跨語言信息檢索(Cross Language Information Retrieval,CAJR)的基礎,本文的目標是通過計算映射詞語的相同程度來解決跨語言搜索結果的有序排列問題,其關鍵在于獲取語義距離和改進現在的映射規則。研究雙語言或多語言的CLIR是一個熱門的話題,《漢語主題詞表》(工程技術版)(以下簡稱《漢表》)與英文超級科技詞表分別用于進行中外文科技文獻的知識組織,而兩者的相互映射正是為了實現對中外文文獻資源的跨語言檢索;考慮到兩個詞表知識體系的差異和語義映射的復雜性,本文不進行知識概念體系、詞間關系和范疇體系等方面的語義映射,主要研究基于概念的映射模型和方法。
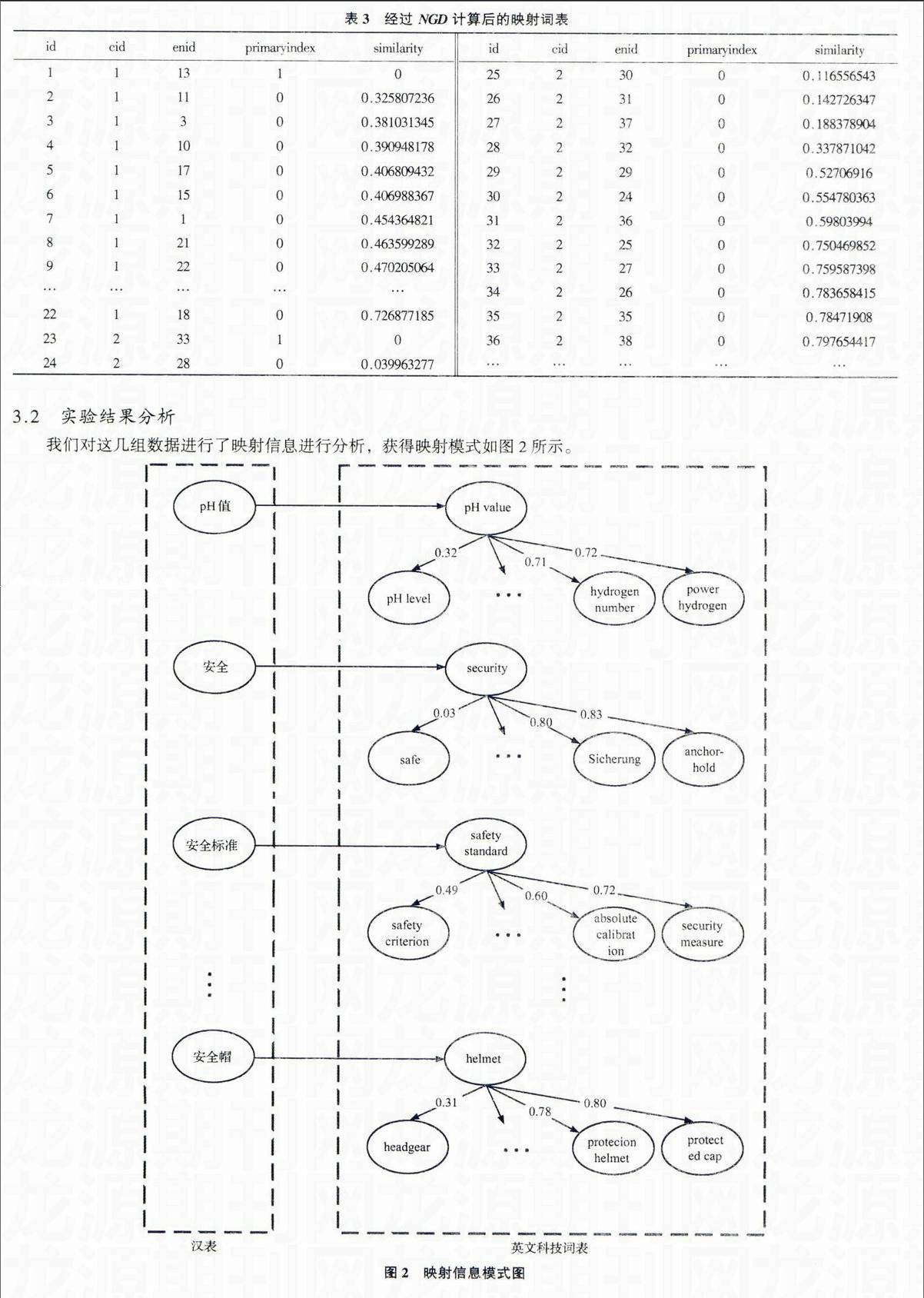
本文以《漢表》的概念作為源(Source)概念,英文超級科技詞表的概念作為目標(Target)概念,參考并修訂W3C的詞表映射規則,建立映射模型。《漢表》概念具有上下位、多層次關系,英文超級科技詞表概念也是網狀關系,在建立概念間映射關系時,只在距離最短、關系最近的概念間建立關系,沒有必要將等同的概念重復給定向上或向下匹配的關系,按照需要,將詞表的原詞間關系導入映射信息即可確定新的映射關系。本文以標準谷歌距離(Normalized Google Distance)作為語義距離的基本計算方法,并設計了映射流程,在已有漢英詞表的基礎上,對映射進行排序,能有效地解決檢索時漢英詞語的匹配問題。在檢索過程中,可以做到按相似度的高低呈現有序的檢索結果,從而給用戶更優的檢索體驗。本文通過程序進行演算獲取實驗結果,根據語義相似度進行排序,建立新的有序映射。endprint
