不同參數在水稻產量穩產性評價中的差異
2015-10-09 05:26:16嚴明建呂直文胡景濤黃文章雷樹凡黃成志
湖南農業科學 2015年7期
嚴明建,呂直文,胡景濤,黃文章,雷樹凡,黃成志
(重慶三峽農業科學院, 重慶404155)
在不同生態區對水稻品種(組合)進行多點試驗,目的是從中篩選出產量高、穩定性好的組合進入各級區域試驗;而不同區域試驗的目的,也是優選出高產穩產的雜交水稻品種[1]。通常情況下,區域試驗中都是用品種的平均產量(x)較對照增產的百分數來估算產量水平,用標準差(Si)、變異系數(CV)或回歸系數(bi)來估測產量的穩定性,用新復極差法測定參試品種之間產量差異的大小[2]。因此,在對結果進行分析時,必須將上述參數全部計算出來,才能對品種進行全面綜合的分析,而目前還沒有一個綜合指標可以既全面又準確地反映品種的高產穩產性。溫振民等[3]在玉米品種選育過程中采用高穩系數法(High Stability Coeffieient Method)對品種的高產性與穩產性進行綜合分析,取得了較理想的結果;張冬娟等[4]和張保亮[5]也成功地利用高穩系數法分別對高梁和花生品種進行了篩選。但他們在利用高穩系數法分析品種穩定性時,都是以各區試點的平均產量為參照數來統計品種產量的變異系數。但由于不同試點之間存在較大的生態差異性,從而使不同品種的產量差異較大,例如云南的紅河、文山與重慶相比,同一個品種的產量水平增減可達到20%以上,而不同品種的產量差異可達43%以上。這是區域生態特點與品種遺傳特性綜合作用所致,其中區域生態差異對這種增減變化所起的作用更大。因此,如果在品種穩定性分析中,僅以產量的平均值進行分析,會因為數據量級上的偏差而導致最終分析結果的偏差。筆者應用高穩系數法(HSC),并輔以適應性參數法[6-7],以各品種在各試點平均產量以及各品種平均產量與各自試點對照品種產量的比值(無量綱化處理)作為參照數,對不同品種產量的穩定性進行評價,以期為多點試驗品種產量穩定性分析提供依據。
1 材料與方法
1.1 數據來源
試驗以2013年度長江上游中秈遲熟組A 組國家水稻品種試驗匯總報告為數據來源,參試品種共11個,分別為:T 優1655(1)、瀘優257(2)、瑞華218(3)、內 香5A/ 川 恢907 (4)、竹 優1013 (5)、德 香047A/R4923(6)、天龍優1375(7)、鵬兩優187(8)、綠優4923(9)、德潤1A/金恢8023(10)、Ⅱ優838(11),其中,以Ⅱ優838 為對照品種。
1.2 試驗概況
試驗分布在16個不同生態區域,分別是:貴州黔東南、貴州黔西南、貴州陽市、貴州遵義、陜西漢中、四川巴中、四川廣元、四川綿陽、四川內江、四川瀘縣、四川雙流、云南紅河、云南文山、重慶涪陵、重慶巴南、重慶萬州,試驗點海拔跨度為180~1 284 m。各試驗點執行統一試驗方案,田間試驗采用隨機區組設計,3 次重復,測量并計算各試點不同品種平均產量。
1.3 數據分析方法
分析參照數分別為:W 1,以各品種在各試點的平均產量為參照數;W 2,不同品種在不同試點與對照比值(數據的無量綱化處理)的均值作為參照數。
(1)數據的無量綱化處理:Yij=Xij/Xijck×100
式中,Xij為第i個品種在j 試點的觀察值,Xijck為i 品種在j 試點的對照品種觀測值。
(2)標準差Si采用Excel 軟件中的應用函數進行計算:Si=STDEVP(Xi︰Xn)
式中,Si為第i個參試種的標準差,為所有參試種標準差的平均值。
2 結果與分析
2.1 各品種在不同試點產量的變異性比較
各試點不同品種平均產量如表1 所示。采用(1)式對參試水稻品種在各試點的產量進行無量綱化處理,然后根據公式(2)~(4)分別計算各參數,將結果整理成表2。從表2 中可以看出,W1、W2兩個參照數對于各參試品種產量高低的位次是一樣的,但其標準差有較大的變動,為了便于比較,將W1、W2兩個參照數所得標準差分別除以它們的平均數,繪成圖1。
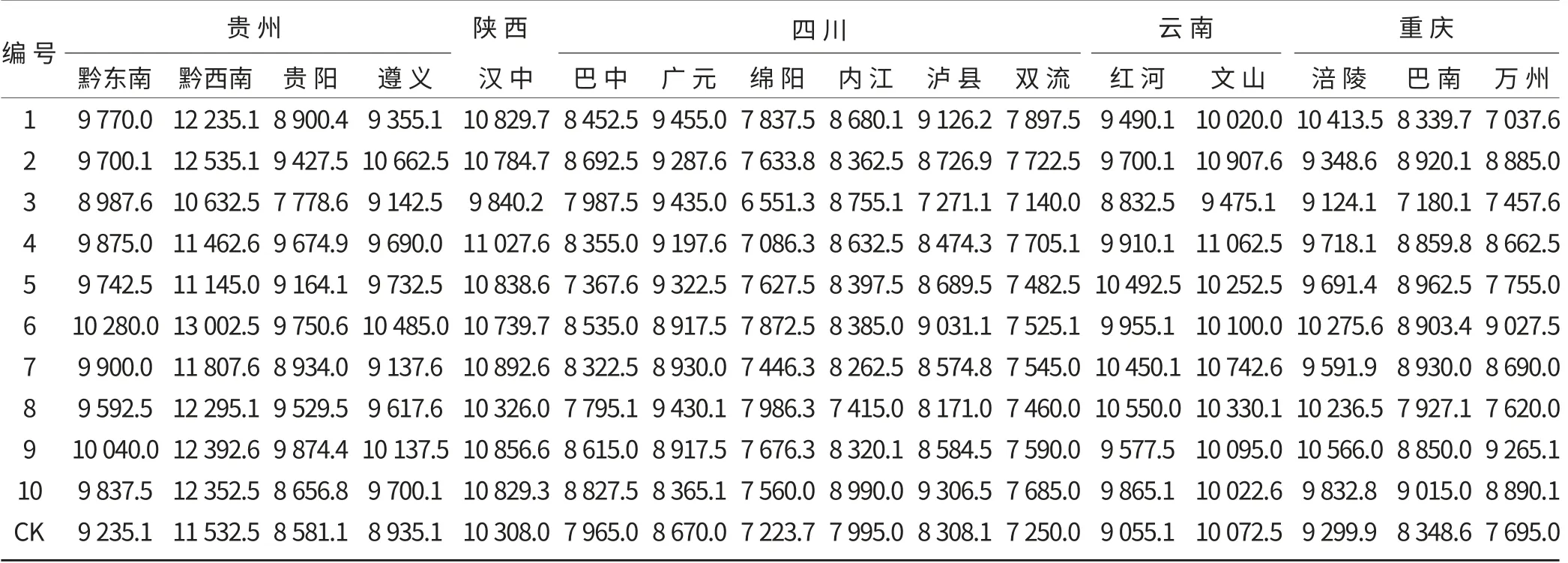
表1 參試水稻品種在各試點的產量 (kg/hm2)
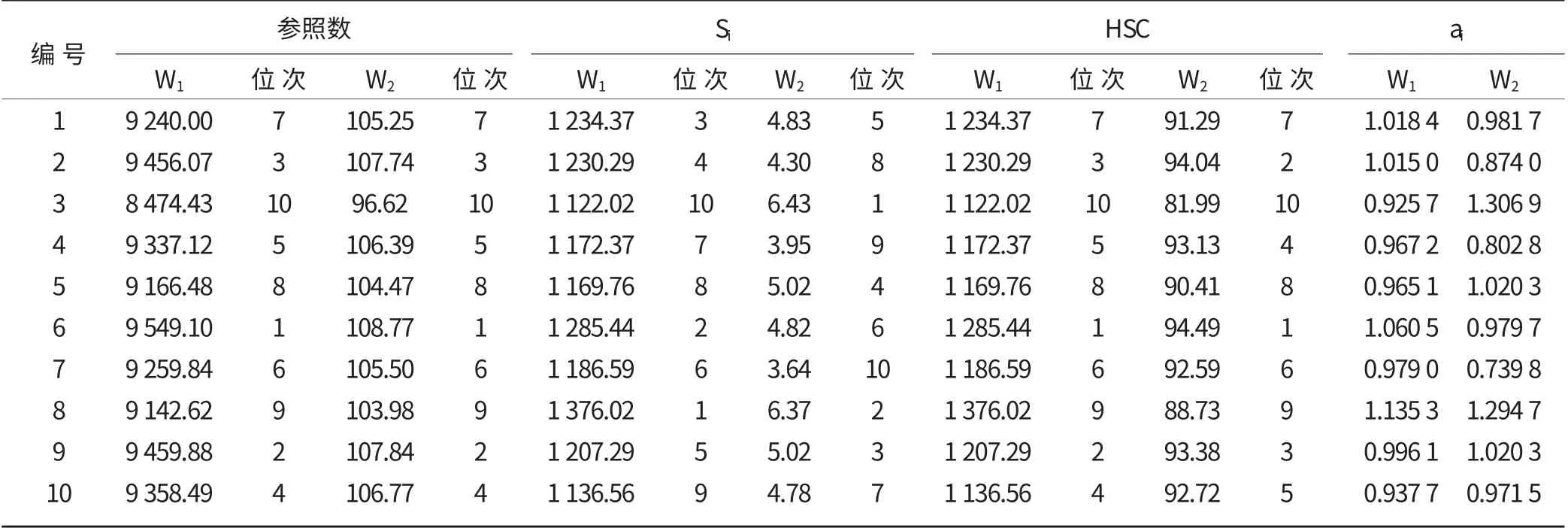
表2 W 1、W 2 參照數分析結果對比
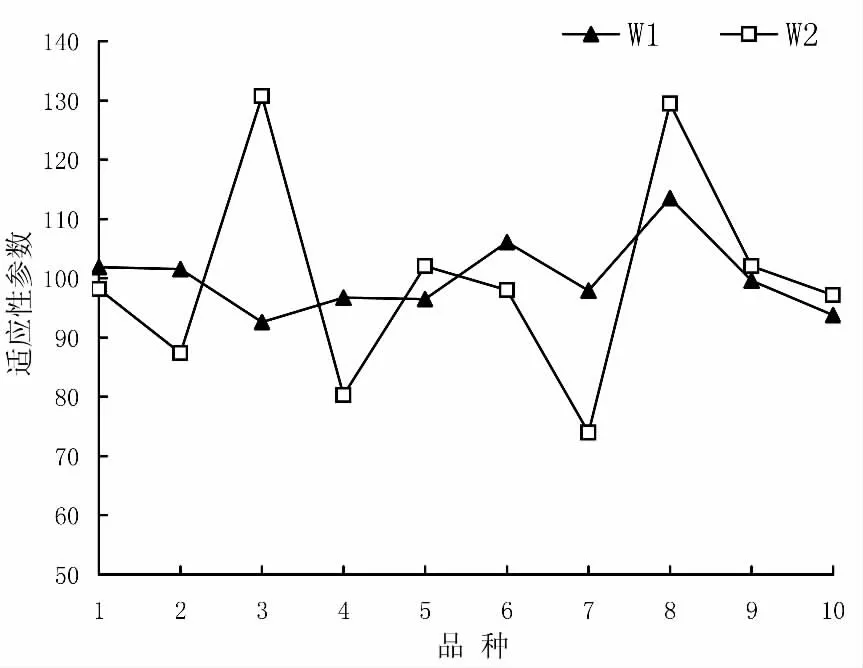
圖1 各品種在不同參照系下適應性參數的比較
由圖1 不難看出,變動最大的是3 號,以W 1 為參照數時,數值最小,排名第10 位,而以W 2 作參照數時,數值最大,排第1 位,表明該組合在無量綱化前其產量在各試點絕對產量變幅最小,但通過無量綱化后,它在各試點其產量的增減幅度是最大的一個。因此,單從各試點絕對產量大小來看,該品種是最穩定的,但以與對照比值結果作為參照數分析來看,該品種卻是一個最不穩定組合。其次是2 號、6 號組合,以W1為參照數時,2 號排第4 位,6 號排第2 位,表現出穩定性較差,但在以W2為參照數時,其排名分別下降到第8 位和第6 位,表現出較好的穩定性;而5 號品種則相反,在以W1為參照數時,排名第8 位,但在以W2為參照數時排名第4 位,其他各品種均有不同程度的變化。總之,采用兩個不同參照數分析得到的標準差差異較大。
2.2 各品種高穩系數結果的比較
分析中高穩系數的運算過程參入了標準差,所得結果也與標準差值的大小具有相關性。從圖2 中可以看出,排名后5 位的品種其高穩系數沒有變化,排名前5 位有小的變動。在以W1為參照數時,排名第2、4位的9、10 號品種,在以W2為參照數分析中下降到3、5 位;而在以W1為參照數分析中排名第3、5 位的2、4 號組合,在以W2為參照數分析中上升到2、4 位。
2.3 各品種穩定性的比較
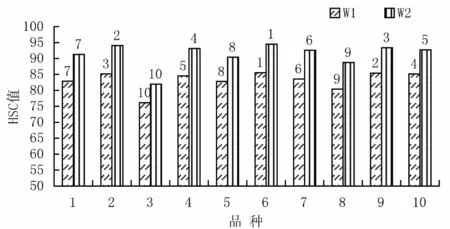
圖2 各品種在不同參照系下HSC 值及排名的比較
為了更直觀比較兩個參照數在穩定性分析中的差異性,以穩定性參數(ai)為橫坐標,參照數W1、W2值為縱坐標(在W1參照數中,以ai=1,Xi=9 244.4 為原點,在W2參照數中,以ai=1,Xi=105.33 為原點),作出品種穩定性如圖3 和圖4。
通過圖3 和圖4 的比較不難看出,6 號及2 號在圖3 中為高不穩定組合,在圖4 中則變為高產穩定組合,而在高穩系數分析中,6 號排第1 位,2 號居第2位,二者具高度穩合;9 號組合則由圖3 的高產穩產組合變為圖4 的高產不穩定組合;3 號、5 號組合在圖3中是低產穩產組合,而在圖4 中則變為低產不穩定組合,而1 號組合則由圖3 的低產不穩定組合變為圖4的低產穩定組合。上述結果表明,兩個不同參照數分析所得穩定性分析具有較大差異。
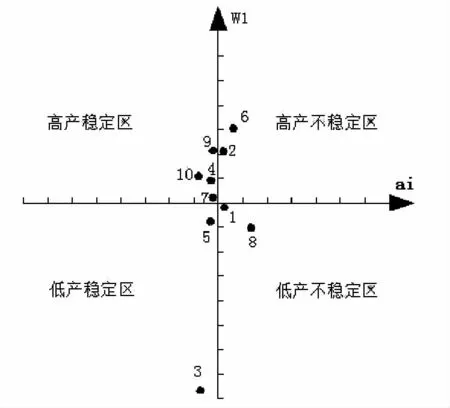
圖3 以平均產量值為參照數的穩定性分析
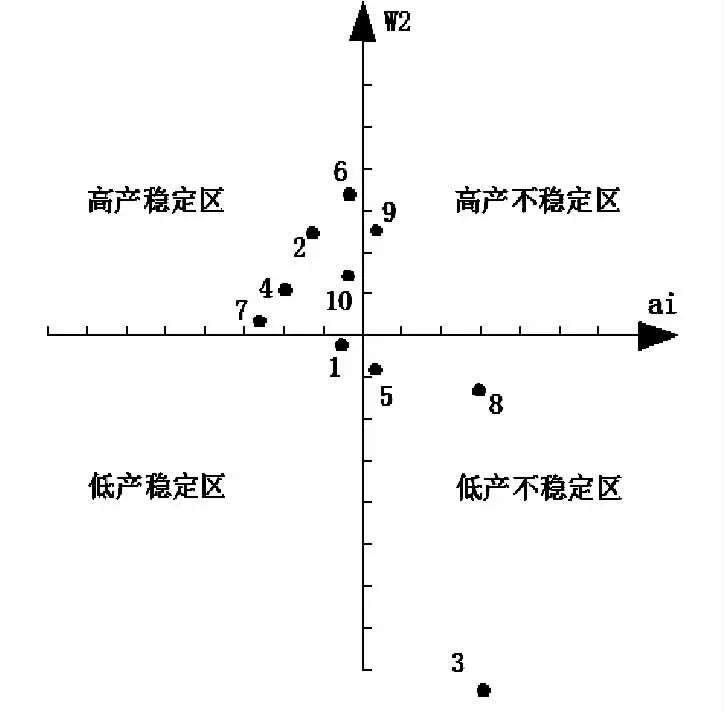
圖4 以與對照值為參數的穩定性分析
3 小結與討論
水稻區域試驗是分布在不同海拔、不同生態區域的多點試驗,由于不同生態區氣候、土壤環境等具有較大的差異,因此對不同水稻品種的產量也將產生一定的影響,而這也是區域試驗所希望的結果。為了使每個品種在不同區域的產量及產量性狀具有可比性,在試驗中一般設有1~2個對照,通過與對照品種的比較來估計并校正試驗田、生態區的氣候及土壤環境的差異,充分利用對照品種在區域試驗中對試驗結果分析的價值,最終得到水稻品種在不同生態區的真實遺傳表現;而以前在分析品種穩定性時往往僅依據品種在各試點的平均產量,其分析結果是該品種表型產量在各試點的穩定性,而不是各品種在各試點與對照增減水平的穩定程度。
通過兩個不同參照數分析,二者在標準差、高穩系數及穩定性參數分析中都具有差異,筆者引入了Yi作為參照數,其分析結果也是各品種在各試點與對照增、減情況的一個穩定性分析,使品種在不同生態區的變異特性及穩定性更為客觀、準確,以此再采用高穩系數法(HSC),并結合俞世蓉提出的適應性參數法,使試驗結果更為完善,對生產的指導性更強。
[1]楊仕華,曾 波.中國水稻新品種試驗-2013年南方稻區國家水稻品種試驗匯總報告[M].北京:中國農業科學技術出版社,2013.91-109.
[2]鄧聚龍.農業灰色系統理論與方法[M].濟南:山東科技出版社,1988.
[3]溫振民,張永科.用高穩系數法估算玉米雜交種高產穩產性的探討[J].作物學報,1994,20(4):508-512.
[4]張冬娟,董建新,張 志.應用高穩系數(HSC)法分析玉米新雜交種高產穩產性[J].國外農學-雜糧作物,1998,(4):21-23.
[5]張保亮,楊青春.應用高穩系數法分析花生新品種高產穩產性[J].中國油料,1997,19(2):8-9.
[6]俞世蓉.作物的品種適應性和產量穩定性[J].作物雜志,1991,(1):36-37.
[7]俞世蓉.品種穩定性及其參數統計[J].種子世界,1986,(7):18-19.
猜你喜歡
青少年科技博覽(中學版)(2022年6期)2022-12-27 19:44:27
礦山安全信息(2022年40期)2022-04-07 02:16:52
當代水產(2021年10期)2021-12-05 16:31:48
軍事文摘(2021年22期)2021-11-26 00:43:51
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
今日農業(2020年20期)2020-11-26 06:09:10
文苑(2020年6期)2020-06-22 08:41:52
文苑(2019年22期)2019-12-07 05:29:00
電子制作(2018年18期)2018-11-14 01:48:24
聚氯乙烯(2018年9期)2018-02-18 01:11:34
