口語輸出中詞匯難度及多樣性和自我修正關系的實證探究
2015-10-21 08:37:46楊琪
四川職業技術學院學報 2015年1期
楊琪
(浙江師范大學外國語學院,浙江 金華 321004)
口語輸出中詞匯難度及多樣性和自我修正關系的實證探究
楊琪
(浙江師范大學外國語學院,浙江 金華321004)
本文根據陳立平,濮建忠的自我修正理論框架,應用中國大學生口筆語語料庫,主要采用定量的方法對英語專業二年級學生的口語語料進行了實證研究。研究發現,學生使用的詞匯難度對整體自我修正次數的影響并不顯著,但是卻和錯誤修正這一修正類型發生的頻次呈正相關,即學生使用詞匯越難,則更容易在詞匯的語音、形態、搭配方面出現錯誤并修正。這使得他們難以兼顧整體口語輸出的流暢程度,也是其語言能力薄弱的表現。此外,學生使用的詞匯多樣性越低,則自我修正,特別是相同修正這一修正類型發生頻次也越高,這表明學生大多使用重復這一策略進行隱性修正,這影響了整體口語輸出的質量。
自我修正;詞匯難度;詞匯多樣性
引言
在交際過程中,說話者不斷監控自己的語言,發現問題時進行糾正,這就是自我引發的自我修正[1](Van,2004)。二十多年來,國內外學者對修正現象進行了深入的研究,對修正的種類、功能等進行了分析,國內對第二語言的自我修正研究涵蓋多個方面,如楊柳群(2002:75)對不同英語水平學習者的自我修正類型進行了研究,發現高水平組的學生傾向于恰當修正而低水平組學生錯誤修正頻次更高[2]75。何蓮珍(2004)基于語料庫研究也發現口語水平對自我修正的影響并不顯著[3]34。總體而言,國內外研究對于自我修正的影響因素進行了多方面的研究,但是對于口語產出文本中詞匯的難度以及多樣性對自我修正頻次及類型的影響則寥寥無幾。學習者自我修正量的減少有助于整體口語輸出文本的流暢性,而文本的整體流暢性和詞匯特征之間的關系就是本研究試圖探究的問題。
1 自我修正與詞匯研究
Kormos(1999)從心理語言學的角度給自我修正下了如下定義:自我修正是語言監察機制運作的外在表現[4]。當說話者覺察到表達中有錯誤的或不得體的地方,即中斷講話,并實施修正,便完成了一次自我發起、自我修正的行為。在近二十年中,學界對母語和二語中的自我修正行為產生了興趣,并從不同角度展開研究。Sacks等是首個系統研究會話中自我引發的自我修正的學者(張念[5]14,2005),20世紀70年代以來,許多學者 (如Jefferson[6],1972;Schegloff[7],1977;Cheepen[8],1988)對會話中的修正現象進行了有益的探討。Schegloff等人(1977)認為修正現象中以自我修正為主,并對這種偏愛自我修正的功能進行了研究[7]。其他一些學者則對修正進行了分類,對修正的結構、修正出現的位置以及修正對句法的影響進行了分析,并提出了修正的模式,這些研究反映了自我修正研究的最新成果。
陳立平,濮建忠(2007)根據Levelt(1989)和Van Hest(1996),Kormos(1998)等的研究,對自我修正進行了分類。他們將顯性自我修正分為不同修正,恰當修正,錯誤修正三類[9],本文結合語料的實際情況,將隱性自我修正也作為研究對象,隱性修正是指說話人通過重復語言輸出的方式而贏得思考時間從而對尚未表達出來的信息進行多方面的修正。這種修正方式在口語語料中出現非常頻繁,因此也是研究的重要方面。
本研究以Levelt[10](1989)對第一語言自我修正的分類為主要框架,參照陳立平等(2007)針對第二語言自我修正的分類,將語料庫中收集到的關于自我修正的語料分成以下幾類,表1中的例子均為筆者從語料庫中搜集所得。
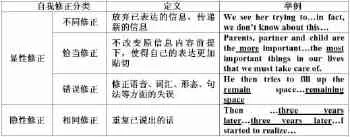
表1 自我修正分類及舉例
為探究學習者口語產出時詞匯的使用和自我修正的數量和類型的關系,本文計算了測量了文本中詞匯的兩大特征,即詞匯難度和多樣性。詞匯難度的測量其核心是詞匯的詞頻分級,如果文本中使用低頻詞的頻次越多,則表明整體的難度系數越低。本文在對詞匯難度測算時使用的是Nation Laufer(1995)的前3000詞頻表[11]。
詞匯多樣性用來測量說話者詞匯運用的廣度,在語言的許多領域,詞匯的多樣性都是衡量語言質量的重要指標,它體現了學習者語言產出的豐富性和成熟性,是學習者語言發展的重要表征之一[12](陸蕓,2012)。詞匯多樣性主要通過類符和形符的比例,即文本中不同詞匯(類符)和文本總詞數(形符)的比率來測量,然而研究表明這種計算方法無法擺脫長度的制約。Yule在1944年提出了K特征常量指數的計算方法,一定程度內減少長度對最終多樣性指標的影響[13],而本研究使用的AdelexAnalyzer這一軟件就是基于Yule的計算方法進行測算的。
2 研究設計
2.1 語料來源
本文采用的語料是中國學生英語口筆語語料中的口語子語料庫,語料來源于2006年全國英語專業四級口試,均為大學二年級英語專業學生,可認定為中級英語學習者。四級考試中學生需要完成復述和演講以及對話三個小任務,由于本文研究的語言現象是自我引發的自我修正,因此第三項對話任務的語料并未采用。
在選取語料時,為保證被試的總體口語水平相當,控制無關變量,本文選取了最終評級均為中等(即二等)的文本,并在所有評級相當的語料中隨機選取了50組轉寫文本材料及音頻,隨后對其中的自我修正部分進行分類和統計。為保證語料文本和音頻匹配,筆者對音頻進行了重聽和核對。在對獲得的語料進行分類的過程中,絕大部分監測到的自我修正都符合以上分類框架,極少數修正失敗情況并未計算在內。
2.2 研究工具
在對語料轉寫文本進行統計的過程中,筆者使用了AdelexAnalyzer這一詞匯分析工具對文本的詞匯多樣性程度進行了測試,本文并未采用類符/形符的統計公式,而采用了Yule的詞匯K特征公式,這是因為前者會明顯會受文本長度的影響,文本長度越長,則比值就越小。由于被試在口試中發言長度以及語速不等,無法保證文本長度不變化,因此本研究采用了第二種詞匯多樣性指標。
在對詞匯難度進行統計時,本文采用了P-LEX這一軟件,它觀察難詞在文本中的分布情況,并由此得出一個難詞在文本中發生的可能性的指標,它的工作原理是將文本切為10個單詞一段,然后計算從1到10個低頻次的段落比例,據此繪制曲線。它能夠根據輸入語料中低頻詞和高頻詞的相對比例,通過各級形符、類符的數據確定詞匯的難易分布,從而計算出文本詞匯的總體難度,其最終報告的limbda數據表明總體的詞匯難度,該指數越高,則表明文本總體難度越大[14](張艷,陳紀梁,2012)。對于P-LEX軟件自帶的詞典無法識別文本中的少量詞匯這個問題,筆者根據NationLaufer(2005)的詞匯頻次表進行人工識別和歸類,對于Nation的頻次表中歸屬于一級詞頻的詞匯歸為低頻詞匯,經過軟件和人工識別,最終得出詞匯難度數據。
2.3 研究問題
本文的研究問題分為以下兩點:一是詞匯的豐富程度和自我修正量及類型的關系如何?二是詞匯的難度特征和自我修正量及類型的關系如何?
3 實證研究分析
3.1 總體自我修正描述統計
在收集的50組數據中,經過標注和統計,共考察到390次修正,其中各個不同類型的修正所占比例如表2所示,在標注過程中不屬于分析框架中的修正并未計算在內。
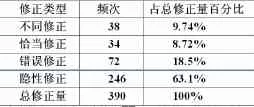
表2 不同修正類型發生頻次及其百分比
從表中可見,在收集的語料中,隱性修正,即重復修正的比例最大,占到63.1%,錯誤修正其次,為18.5%,而恰當修正和不同修正所占比例分別為8.72%和9.74%,這和陳立平,濮建忠所得的結果基本一致。
3.2 總體詞匯特征描述統計
通過P-LEX軟件在對收集的50組文本進行詞匯分析之后,獲得以下關于詞匯難度的數據(見表3)

表3 文本總體詞匯難度的描述性數據
根據P-LEX軟件的計算方法,詞匯難度指數limbda的浮動區間為0.5至4.5,而本研究的語料中文本的總體詞匯難度系數limbda平均值為0.702,難度水平較低。根據軟件的計算方法,這表明學習者口語輸出的詞匯難度總體偏低。這也許和考試的高壓環境相關,在口試環境下,學習者在較短時間的準備之后需要即時輸出,這樣的壓力環境使得他們難以調動頭腦中較高難度的詞匯,因此總體的詞匯難度相對書面輸出要低一些。
通過AdelexAnalyzer對文本進行詞匯的多樣性分析之后,所得描述性數據如表4所示,得出總體的多樣性平均值為152.92。

表4 文本詞匯多樣性的描述性統計
3.3 自我修正和詞匯難度的相關
3.3.1 詞匯難度和總體自我修正量的關系
通過SPSS軟件對詞匯難度與總體修正量進行Pearson相關檢驗,發現二者并無顯著相關關系,具體統計結果如表5所示。
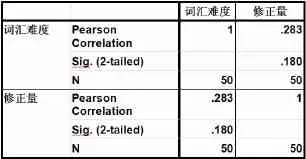
表5 詞匯難度和修正量之間的Pearson相關檢驗
統計結果顯示,詞匯使用難度和修正量之間并沒有顯著相關關系,并不是詞匯使用越簡單,則修正的次數越少,總體輸出文本也就越流暢。總體修正次數和多種因素相關,包括學生心理緊張程度、本身語言水平、任務類型等,本次研究中并未發現和學習者使用的詞匯難易程度有明顯的相關關系。為進一步探究詞匯難度和自我修正之間的關系,下一步筆者將就詞匯難度和不同類型的自我修正之間進行統計檢驗。
3.3.2 詞匯難度和不同類型自我修正的關系
通過SPSS考察錯誤修正和詞匯難度之間的關系,發現在0.01的置信度上,錯誤修正量和詞匯難度呈顯著的正相關。具體統計結果如表7所示:
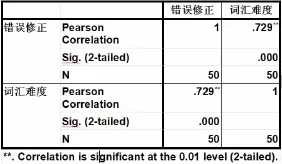
表7 詞匯難度和錯誤修正之間的Pearson相關檢驗
統計顯示,詞匯難度和錯誤修正之間呈負相關,正相關系數為0.729。因選取的樣本最終的口語等級均為二等,可認為文本總體的語言水平相當,學習者使用的詞匯難度越大,則其認知資源或注意力均放在詞匯的語音、搭配、形態上,如語料中有學生使用pronounce這一詞匯時就發生多次修正,修正類型包括語音、詞性、搭配等,這表明在使用難度較大的詞匯時,學習者由于對詞匯深度知識的缺乏,難以確認其正確性而產生了自我修正。而對于詞匯難度較低的文本,學生對該類詞匯的使用可以達到自動化的程度,對語言主動駕馭的能力提高了,錯誤修正則顯著減少,或者說,學習者的認知資源多集中于語用和信息本身的恰當性上而非詞匯本身使用的正確性。
3.4 自我修正和詞匯多樣性的相關
3.4.1 詞匯多樣性和總體自我修正量的關系
通過SPSS統計詞匯多樣性和自我修正量的關系,所得結果如表8:
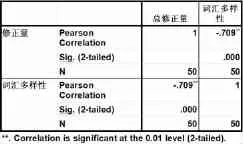
表8 詞匯難度和錯誤修正之間的Pearson相關檢驗
研究表明,詞匯的多樣性越低,則自我修正的量也就越大,二者存在顯著負相關,文本的詞匯多樣性低,意味著學生在不斷使用重復詞匯,從實際的語料中看,學生傾向于使用重復作為一種修正策略,其功能是延遲下一個詞語成分的產出從而為說話者在語言和認知上進行構思的重復以完成自我修正(張念,2005:4)。實際上,重復會導致文本的不流暢,并不是一種有效的自我修正策略,這種重復使得總體的詞匯多樣性大大降低,也降低了語言產出的質量。為進一步考察詞匯多樣性和自我修正之間的關系,筆者對詞匯多樣性以及幾種不同的錯誤修正類型同樣進行了Pearson相關檢驗。
3.4.2 詞匯多樣性和不同類型自我修正量的關系
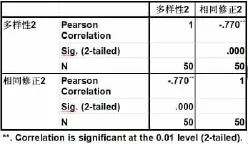
表9 詞匯多樣性和和相同修正之間的Pearson相關檢驗
SPSS統計發現,詞匯多樣性和隱性修正呈顯著的負相關,也就是說,詞匯多樣性越低,則隱性修正發生的頻次越大。在實際的口語輸出中,有時說話者并未發生錯誤,但是為了搜尋更恰當的字眼,避免可能發生的錯誤,就會臨時中斷正在進行的話語從頭開始,這就會造成部分話語重復,說話者的整體詞匯多樣性越低,表明其不斷重復使用相同詞匯,這就影響了語言的連貫性和整體流利性,給人以一種結結巴巴,表述不清的感受,也影響了同時間內信息量的傳遞,這也是學生整體語言能力薄弱的體現。
4 結語
本次研究對于詞匯和自我修正量及類型的關系得出以下結論:
第一,在自我修正各個類型中,以隱性修正,即相同修正的頻率最高,這反映出總體口語產出流利性欠佳的問題。
第二,詞匯難度和自我修正總量并沒有顯著相關關系,可見學生的總體口語流利程度和詞匯的使用難度之間并不相關。
第三,詞匯難度和錯誤修正這一修正類型有顯著的正相關關系,詞匯使用難度越大,學生的駕馭詞匯能力越弱,語音、搭配、形態等錯誤修正發生的概率也越大。但是詞匯難度增大和不同修正、恰當修正并無顯著相關關系,因為這幾種修正和語篇內容、任務類型等關聯較大,和使用的詞匯之間關聯不大。
第四,詞匯的多樣性和自我修正量,尤其是相同修正這一類型呈顯著的負相關,也就是說,詞匯重復率越高,自我修正量也越大,學生多采用重復的方式進行修正,獲得思考時間,這種修正策略實際上反映出學生駕馭語言能力較弱,不懂得利用修正標記語以及填補詞。
[1]Van Hest E.The relationship between self-repair andlanguageproficiency2004.http://www.asha.ucf. edu/vanhest2.html,.
[2]楊柳群.英語水平對英語學生口誤自我修正的影響[J].山東外語教學,2002,(4).
[3]何蓮珍,劉榮君,基于語料庫的大學生交際策略研究[J].外語研究,2004,(1).
[4]Kormos,J.AnewpsycholinguistictaxonomyofselfrepairingL2:Aqualitativeanalysiswithretrospection[J].EvenYearbook,ELTESEASWorkingPapersin Linguistics1999(3):43~68.
[5]張念,中國大學英語課堂中用于自我策略的重復[D]武漢大學碩士學位論文,2005.
[6]Jefferson,G.Sidesequences.InD.Sudnow(ed.),Studiesinsocialinteraction[M].NewYork:FreePress.197: 294-338.
[7]Schegloff,E.A.,Jefferson,G.andSacks,H.Thepreferenceforself-correctionintheorganizationof repairinconversation[J].Language,1977,(53):2.
[8]Cheepen,C.Thepredictabilityofinformalconversation[J].PinterPublishersDeborah.1988
[9]陳力平,濮建忠.基于語料庫的大學生英語口語自我修正研究[J].外語教學,2007,(2).
[10]Levelt,W.J.M.Speaking:FromIntentiontoArticulation[M].Cambridge,MA:MITPress,1989.
[11]Nation,BLaufer1995.ISPVocabularysizeanduse: lexicalrichnessinL2writtenproduction[J].Applie dLinguistics,1995(16):307-322.
[12]陸蕓.詞匯豐富性測量方法及計算機程序開發:回顧與展望[J].南京工業大學學報,2012,(2).
[13]Yule,GU.TheStatisticalStudyofLiteraryVocabulary.Cambridge:CambridgeUniversityPress.1944
[14]張艷,陳紀梁.言語產出中詞匯豐富性的定量測量方法[J].外語測試與教學,2012,(3):104.
責任編輯:周哲良
H319.3
A
1672-2094(2015)01-0072-04
2014-11-06
楊 琪(1989-),女,浙江溫州人,浙江師范大學外國語學院英語語言文學專業碩士研究生在讀。研究方向:二語習得,外語教學研究。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
科技傳播(2019年22期)2020-01-14 03:06:54
制造技術與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
