高校學生缺課模型分析及點名策略
2015-12-08 07:36:38管白楠馬園媛魏成花
昌吉學院學報 2015年2期
李 碩 管白楠 馬園媛 魏成花
(1.昌吉學院數學系 新疆 昌吉 831100;2.昌吉學院機關 新疆 昌吉 831100)
引 言
隨著教育資源的廣泛推廣,我國的高等教育由以前的精英教育模式已經轉化到了大眾化教育模式,而有限的教育資源制約著受教育者的數量.目前就業壓力的競爭加大,熱門專業的學員更熱,人數更為龐大,面對接踵而來的廣大學員,高校一般實行合班大課堂來應對廣大學員公平受教育.然而,大班上課人數多,管理較難,易于發生逃課現象[1].高校學生逃課現象的普遍存在,無不與學生個性的不同、學校教學管理的不足、社會各種環境的差異、學生的自身等多種因素存在關系[2].當前,考證熱、考研熱等是大學生盲目逃課的一大原因.大學管理制度的不完善、教師授課水平的差異成為大學生逃課的第二原因。大學生的家庭條件、學習興趣、上網癮、打牌癮等是其逃課的第三原因[3].
針對學生逃課頻發現象,實施有效的點名策略是教師考察學生出勤的一個關鍵問題.課堂點名方式繁多,最常用的點名方式就是點名喊到,點名過程不僅僅是教師檢查學生上課的出勤情況,還蘊含著許多有意義的教育價值,如果教師采取靈活多變的隨機抽樣點名方式,不但能有效地減少點名所花費的時間,而且還能有效地估算大合班學生出勤情況,這為我們研究高校學生點名策略提供了必要的現實意義.我們應用數理統計知識,從大樣本(大合班學生總數)中抽取小樣本(被點名的學生人數)的方法來研究學生上大班課的點名策略,從而估計學生整體的出勤情況.樣本含量體現研究設計中重復原則,其意義在于估計研究中的誤差,且抽樣誤差大小與樣本量有關,足夠的樣本量也是實驗研究中保證組間均衡性的基礎[4].我們假設的樣本含量是參與上課的大班學生(約100人左右),逐人點名方法意味著教師要付出更多的時間、精力、人力,造成不必要的浪費,逐人點名還會降低課堂授課的時間效率.如果在大班中點名的樣本例數太少,就易于把偶然性或巧合的現象當做必然的規律現象,也不能正確的估計學生的出勤率,導致了結論的可靠性差、用于推斷總體的精度差、檢驗效能低,最終總體中存在的差異未能檢驗出來,出現假陰性結果(隱藏),即對大合班學生實施點名策略既不能片面追求增大樣本的逐一點名方法,也不能忽視保證足夠的樣本含量來估計學生的出勤率.
對于大合班上課學生易逃課頻發現象,我們通過簡單隨機抽樣方法,能夠有效的估算出該大班學生出勤情況,同時構造出了小樣本估算出勤率的95%的置信區間,數值模擬顯示該班出勤率在小樣本估算出勤率的95%的置信區間內.
1 缺課模型分析
對總體率π做估計調查的樣本大小模型[5]為

其中:zα2表示正態分布的α2分位數,δ為容許的誤差(允許樣本率p和總體率π的最大容許誤差)。
下面我們應用上述模型研究高校學生大合班上課隨機抽樣需要被抽點的人數,為估算學生出勤率提供有效方法。
案例:某高校教師對某專業大班上課的出勤率進行調查,在預調查中這個比例是90%,希望所得的樣本率p和總體率 π之差不超過10%的可能性不大于0.05,需要被點多少名學生可以有效的估算出該班的出勤率.
案例分析:應用數理統計知識,采用統計學檢驗時,當研究結果高于和低于效應指標的界限均有意義時,應該選擇雙側檢驗,所需樣本量就大;進行雙側檢驗時,α的zα2界值通過查標準正態分布表得到.α水平由研究者具體決定,通常α取0.05.于是
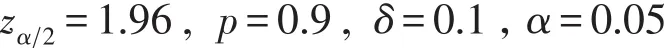
利用公式(1)得

以某高校大合班全體學生作為研究對象(假設100人),除去請假(事假、病假)外,選擇90人作為我們的研究對象,現在研究90人中學生的上課情況,上課情況分為兩類:一類上課;另一類逃課.這90人的上課情況構成了一個樣本空間S={X1,X2,…,X90},其中{Xi=0}表示某學生逃課,{Xi=1}表示某學生上課,i=1,2,…,90.于是我們研究的問題是該選擇多少研究對象才能有效估計該班學生的出勤率.
2 數值模擬及結果分析
假設某大合班需要研究對象90人,逃課人數是8人,則該大合班的出勤率為(90-8)/90=0.9111,利用公式(1)計算出需要被調查的人數n=35人,采用簡單隨機抽樣從樣本空間中抽取35人,用這35人(小樣本)可以估算出大班學生的出勤率.
根據假設,大班有90人,逃課8人,則該樣本空間S就由8個0和82個1組成,利用Matlab軟件進行數值模擬:在S中隨機抽取n=35,然后利用軟件統計出35個數中1的個數(相當于統計抽取的35個學生中上課人數),計算出樣本出勤率,同時構造出樣本出勤率的95%的置信區間.
其中:cql表示全班學生出勤率;cql1表示小樣本出勤率;x表示樣本均值;s表示樣本方差;α=0.05,tα2(n-1)表示自由度為n-1的t分布的α2分位數,n是小樣本個數,于是就有:
小樣本學生的出勤率與全班學生出勤率的誤差δ1=|cql-cql1|,小樣本出勤率的95%的置信區間記為[LC,RC],

模擬結果:
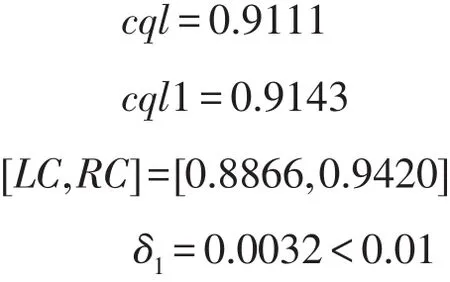
模擬結果顯示:全班學生出勤率(cql)在95%的樣本出勤率的置信區間[LC,RC]內。樣本出勤率與總體出勤率的誤差δ1=0.0032,遠遠不超過0.01,這一結果在原題設容許的最大誤差范圍內,模擬效果顯著.從而說明在大合班進行課堂授課的教師只需隨機抽取其中的35名學生作為點名對象,就可以有效的估算出全班學生的出勤情況,從而為高校教師在學生考勤方面提供了定量化的策略.當然,實際教學中教師們還有一些非定量化策略,詳細情況參見[6-9].
[1]程芳玲,楊百勤.大學生逃課現象的分析及思考[J].中國輕工教育,2004,(4):41-42.
[2]張嬋香.大學生逃課的福利損失分析及對策[J].現代教育科學,2013,(4):42-45.
[3]徐松芝,劉嘉誠,袁朝慶.淺談大學生逃課原因及其對策[J].長春理工大學學報,2012,7(1):107-108.
[4]茆詩松.概率論與數理統計教程(第二版)[M].北京:高等教育出版社,2011.
[5]蔣興國.臨床醫學研究對象樣本量的估計[J].寧夏醫學雜志,2008,30(6):571-573.
[6]趙洋.席位分配及課堂點名模型的研究[M].陜西:西北工業大學,2006.
[7]郭冬生.我國大學本科教育管理制度的反思與重建[J].清華大學教育研究.2004,(6):64-70.
[8]晏成宗.擴招背景下學生缺課現象的經濟學分析[J].高教論壇,2006,(3):42-44.
[9]李小春,蔡湘文.課堂點名的數學模型[J].銅仁學院學報,2013,15(2):125-127.
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
美食(2022年2期)2022-04-19 12:56:24
快樂語文(2021年27期)2021-11-24 01:29:04
少兒美術·書法版(2021年10期)2021-10-20 06:14:10
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
甘肅教育(2020年22期)2020-04-13 08:11:16
甘肅教育(2020年12期)2020-04-13 06:24:48
科技傳播(2019年22期)2020-01-14 03:06:54
福建基礎教育研究(2019年3期)2019-05-28 23:14:43
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
