基于粗粒度可重構陣列結構的多標準離散余弦變換設計
2015-12-13 11:45:46楊海鋼
電子與信息學報 2015年1期
陳 銳 楊海鋼 王 飛 賈 瑞 喻 偉
1 引言
在視頻序列的編解碼流程中,離散余弦變換(Discrete Cosine Transform, DCT) 需要占用大量時間,如何通過硬件加速執行 DCT從而提高編解碼的效率顯得非常有必要。并且,隨著視頻編碼標準的增多,對于單一平臺支持多種標準的需求逐漸突顯出來,DCT硬件的可重構設計逐漸成為學術研究的熱點。然而,在通過硬件設計加速執行 DCT的同時,還需要考慮由此帶來的能效問題,特別是對于一些需要電池支持的手持設備,能效問題更顯得突出,因此,需要一種兼顧能效與性能的平臺,實現對不同視頻壓縮編碼標準的支持。
視頻壓縮標準中采用的DCT可以分為兩類:2維離散余弦正變換(2D Forward DCT, 2D-FDCT)和 2維離散余弦逆變換 (2D Inverse DCT, 2DIDCT)[1]。2D-IDCT/FDCT的整個計算過程一般會被拆成3部分:基于行/列的1D-IDCT/FDCT、矩陣轉置和基于列/行的1D-IDCT/FDCT。根據這3部分的實現方式,2D-IDCT/FDCT的硬件電路結構可以分為:流水線結構和時分復用結構[2]。前者可以實現流水執行,因此速度很快,后者速度較慢,但是所需的硬件資源較前者少。在這兩種硬件電路架構的基礎上,近年來有許多相關文獻通過算法優化或者結構優化來降低1D-FDCT/IDCT硬件實現的難度。按照支持標準的數量,可以將這些優化方法劃分為兩類:(1)只針對一種標準進行的設計化[24]-;(2) 針對多種標準的設計優化[58]-。為了提升 DCT硬件實現的設計效率和能量效率,本文提出一種基于粗粒度可重構結構的 DCT硬件電路結構,與已有結構的不同之處在于:(1)2D-IDCT/FDCT的硬件實現的架構不再采用流水線結構或者時分復用結構,而是基于粗粒度可重構陣列結構(Coarse-Grained Reconfigurable Array, CGRA)[9,10];(2)通過定制 CGRA 的互連網絡,省去了矩陣轉置所需存儲器或者寄存器陣列,而且矩陣轉置無需占用時鐘周期;(3)整個設計形成一種“階段級”的流水線結構,能夠流水處理8×8尺寸大小的像素塊。在SMIC 130 nm標準單元工藝庫下的仿真和綜合結果顯示,本文提出的結構每個時鐘周期能夠并行處理8個像素,而吞吐率最高可達1.157×109像素/s。與已有結構相比,本文提出的結構設計效率最高提升4.33倍,最低提升77.5%,而能量效率最高提升12.3倍,最低提升14.6%,并且能夠以30幀/s的幀率解碼尺寸為 4096×2048,格式為 4:2:0的視頻序列。
論文的章節安排如下:第2節介紹2D-IDCT/FDCT的原理;第3節陳述本文提出的硬件電路結構的基本思路;第4節給出詳細的硬件電路設計;第5節是實驗結果與數據分析;最后是總結。
2 2D-IDCT/FDCT原理
式(1)和式(2)分別給出了 2D-IDCT/FDCT 的原理,從它們的組成上可以看出二者在計算方式上有很大的相似性,二者的硬件設計一般可以實現共用。在式(1)和式(2)中,矩陣 C 是系數矩陣,不同視頻標準的系數值不同,但系數在矩陣中的擺放位置和符號相同。以8×82D-IDCT為例,系數矩陣中系數擺放位置和符號關系如圖1(a)中的C8×8所示,表1列出了不同視頻壓縮標準的系數比較。
從式(1)或式(2)也可以看出,2D-IDCT/FDCT的整個計算過程可以拆成 3部分:基于行/列的1D-IDCT/ FDCT、矩陣轉置和基于列/行的1D-IDCT/FDCT。而1D-FDCT/IDCT可以進一步化簡,以 1D-IDCT為例,如式(3)所示,根據文獻[11]提出的算法,系數矩陣 C8×8可以進行矩陣分解為兩個子矩陣 C4×4和 V4×4與兩個稀疏矩陣 P0和P1,如圖 1(b)~圖 1(e)所示。稀疏矩陣 P1用于調整輸入數據的順序,無需任何計算。稀疏矩陣P0用于將兩個子矩陣與輸入數據的乘積結果通過加減運算合并。
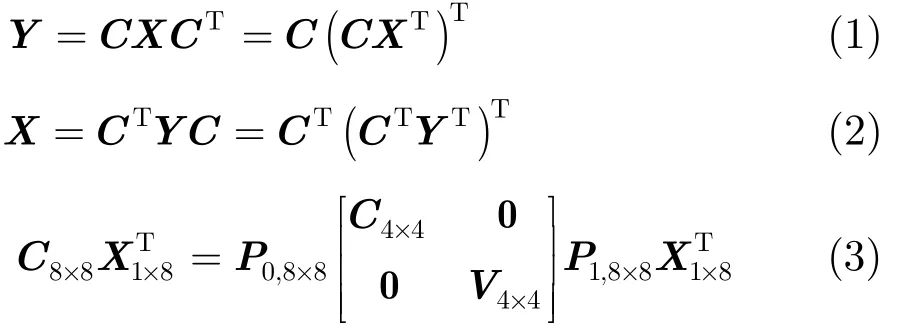
3 基本思路
本文提出的電路結構的基本思路是在以下4個想法的基礎上構建:
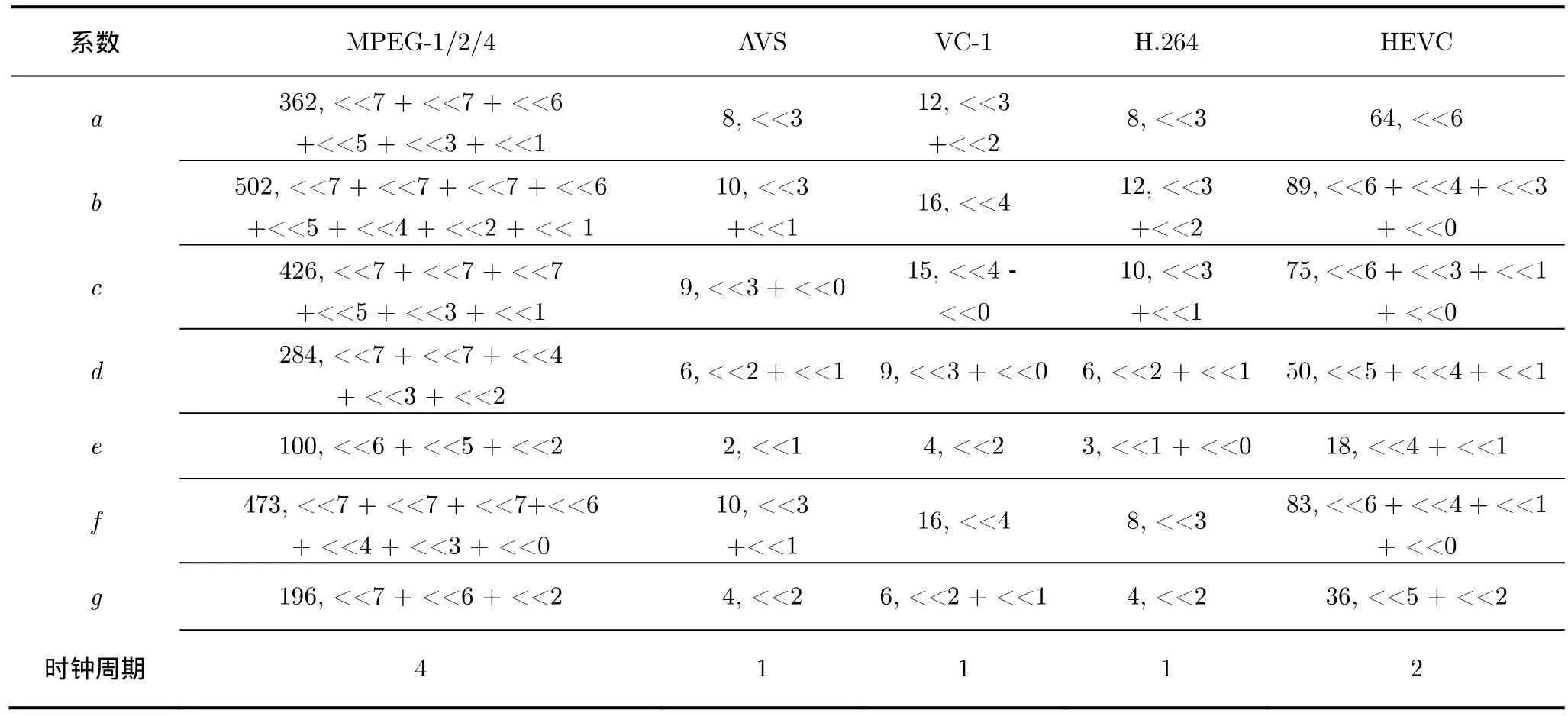
表1 不同視頻編碼標準采用的系數比較以及常系數乘法的實現方式(系數值:采用移位和加/減法實現系數值)

圖1 8×8 IDCT簡化過程中涉及到的矩陣
(1)利用 CGRA 在加速執行計算密集型應用方面的優勢,實現基于CGRA的2D-DCT,提升計算效率。2D-DCT中包含了大量的算術運算,屬于計算密集型應用,而粗粒度可重構陣列結構在加速執行計算密集型應用方面的優勢非常突出。1行像素的1D-DCT可以通過1行的處理單元(Processing Element, PE)來實現,8×8的PE陣列可以同時處理8行,如圖2所示。假設1行像素的1D-DCT所需時鐘周期數為N,那么整個8×8尺寸大小像素塊的 1D-DCT執行時間只需要 N周期即可完成。
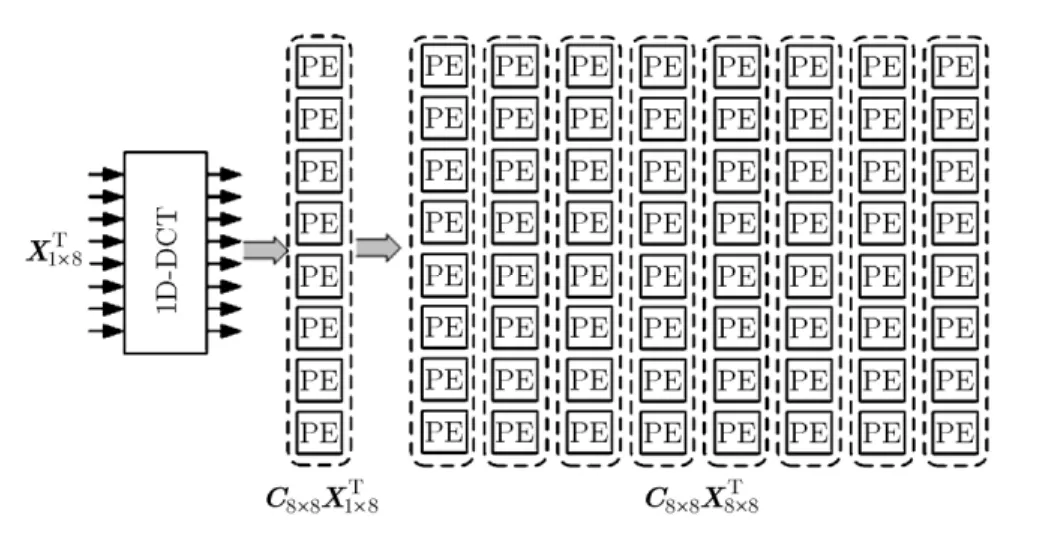
圖2 8×8 尺寸的1D-DCT映射到CGRA示例
(2)通過定制CGRA的互連網絡,可以消除矩陣轉置所需的存儲器或者寄存器陣列。2D-DCT的矩陣轉置一般是通過存儲器或者寄存器陣列實現的,而存儲器或者寄存器陣列會導致較大的面積開銷,并且需要占用多個時鐘周期才能完成矩陣轉置,同時訪問存儲器也會產生較高的功耗。如果在CGRA陣列中引入行總線和列總線,每行PE的計算結果傳到行總線,并且第1行處理單元的行總線和第1列的處理單元的列總線連接,第2行處理單元的行總線和第2列的處理單元的列總線連接,以此類推,而在映射時采用時間映射,即每行負責 1行像素的處理,那么處理完的數據傳到行總線,而在下1個周期讀入列總線的數據,即可實現矩陣轉置。這樣設計的優勢在于:矩陣轉置無需占用額外的時鐘周期;矩陣轉置無需借助于存儲器或者寄存器陣列,因此可以省去這一部分的面積開銷和功耗。
(3)通過定制處理單元的硬件電路結構,節省面積開銷。DCT在計算過程中涉及到大量的乘法運算,如果直接通過乘法器來實現乘法運算,那么整個陣列將需要64個乘法器,這將造成巨大的面積開銷。為了節省面積開銷,可以以移位和加法的方式代替乘法。
(4)引入“階段級”的流水線結構,進一步提升計算效率,并降低對帶寬和 I/O數目的需求。在CGRA上并行執行8行數據的1D-DCT之前,需要同時將 8行的數據準備好并傳輸給每個 PE,因此CGRA本身對帶寬和I/O數目的要求比較高。如圖3所示,如果將2D-DCT的整個計算過程按階段劃分,每個階段所需的時鐘數相等,并且等前一階段的數據完全準備好之后才傳給后一階段,那么可以將整個計算過程理解為一個包含 3級的流水線結構。這樣設計不僅可以降低對輸入輸出數據帶寬和I/O數目需求,而且利用流水線結構在加速執行方面的特性,可以進一步提升整個結構的計算效率。
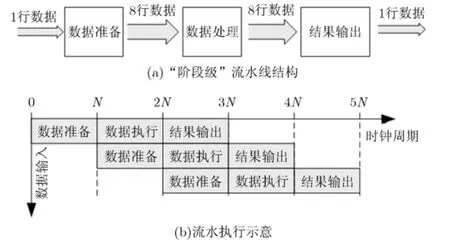
圖3 本文提出的“階段級”流水線結構
4 詳細設計
基于第 3節的分析,本文設計了一款基于CGRA的DCT硬件電路結構。如圖4所示,本文提出的硬件電路結構包括4部分:CGRA、數據準備模塊、數據輸出模塊和時鐘分頻模塊。數據準備模塊為CGRA準備數據,CGRA處理輸入的數據,處理完成之后傳送給數據輸出模塊。整個結構的時鐘信號由時鐘分頻模塊提供。以下幾節先詳細介紹如何針對DCT定制CGRA,之后再簡單介紹其他模塊。
4.1 針對DCT定制CGRA的結構
為了進一步降低硬件實現的復雜度,式(3)可以概括為4個步驟:
步驟 1 載入數據;步驟 2 調整輸入數據的順序,按照奇偶劃分;步驟 3 輸入數據與分別與兩個子系數塊矩陣相乘;
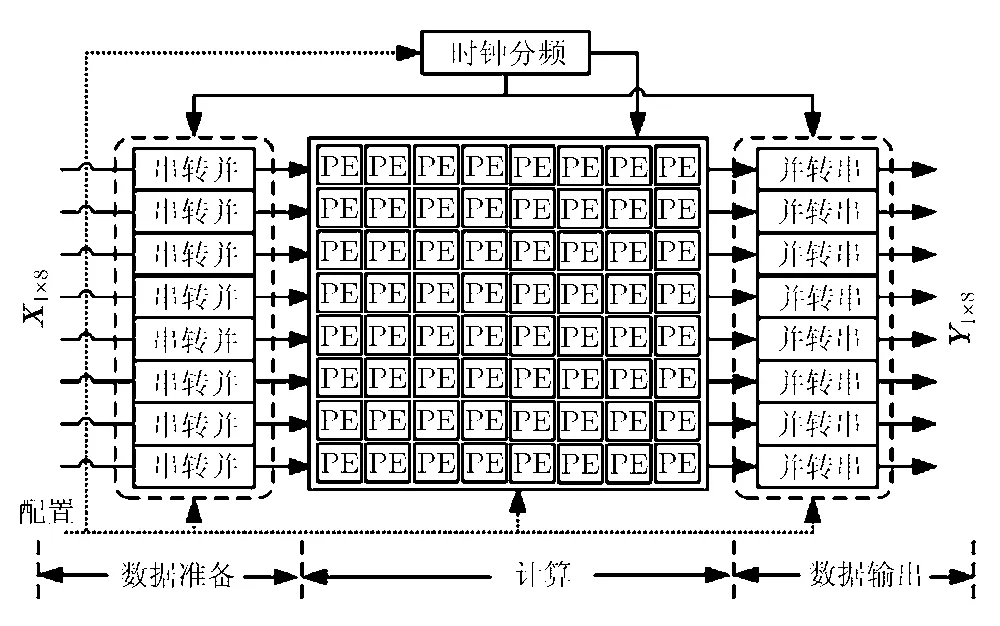
圖4 本文提出的硬件電路結構框圖
步驟 4 對乘法結果進行加減處理。
資料來源 以 “唑來膦酸”和 “急性葡萄膜炎”為中文關鍵詞,檢索中國學術期刊全文數據庫、維普中文科技期刊數據庫和萬方數據庫;以“zoledronic acid”和 “acute uveitis”為英文關鍵詞,檢索PubMed數據庫,收集唑來膦酸相關性急性葡萄膜炎的病例。檢索時間:2000年10月至2018年3月。納入標準:國內外公開發表的相關原始臨床試驗研究或病例報道。剔除標準:綜述性文獻和重復發表文獻。
其中,步驟1載入的數據既可以是數據總線輸入的數據,也可以是矩陣轉置之后的數據,步驟 2和步驟4需要有特定的互連線支持,步驟3和步驟4決定了處理單元的計算功能。以上這些是每行處理單元應該支持的功能。1D-FDCT可以得到類似的結果,唯一不同的是這些步驟的順序。以下幾節主要針對IDCT,而FDCT可以通過調整這些步驟的順序得到。
4.1.1 定制每行處理單元支持的互連線 根據以上的分析,每行處理單元應該支持的互連線可以劃分為3類,如圖5所示。
Ⅰ類:用于支持稀疏矩陣P1調整輸入數據的順序。假設輸入1行8個數據分別為 x0~x7,x0對應于PE0, x1對應于PE1,以此類推,那么1行處理單元之間的互連線應該包括以下 8根互連線,即 P E0→ P E0, PE1→PE4, PE2→PE1, PE3→PE5,PE4→ PE2,PE5→PE6,PE6→PE3,PE7→PE7。通過這8根互連線可以完成1D-IDCT的第2步,也就是按照奇偶順序調整輸入數據。
Ⅱ類:用于支持稀疏矩陣P0進行加減運算。P0需要8根互連線,具體為:P E0→PE7, PE1→PE6,PE2→PE5, PE3→PE4, PE4→PE3, PE5→PE2, P E6→PE1和PE7→PE0,通過這8根互連線即可滿足P0矩陣在加減運算方面的需求。
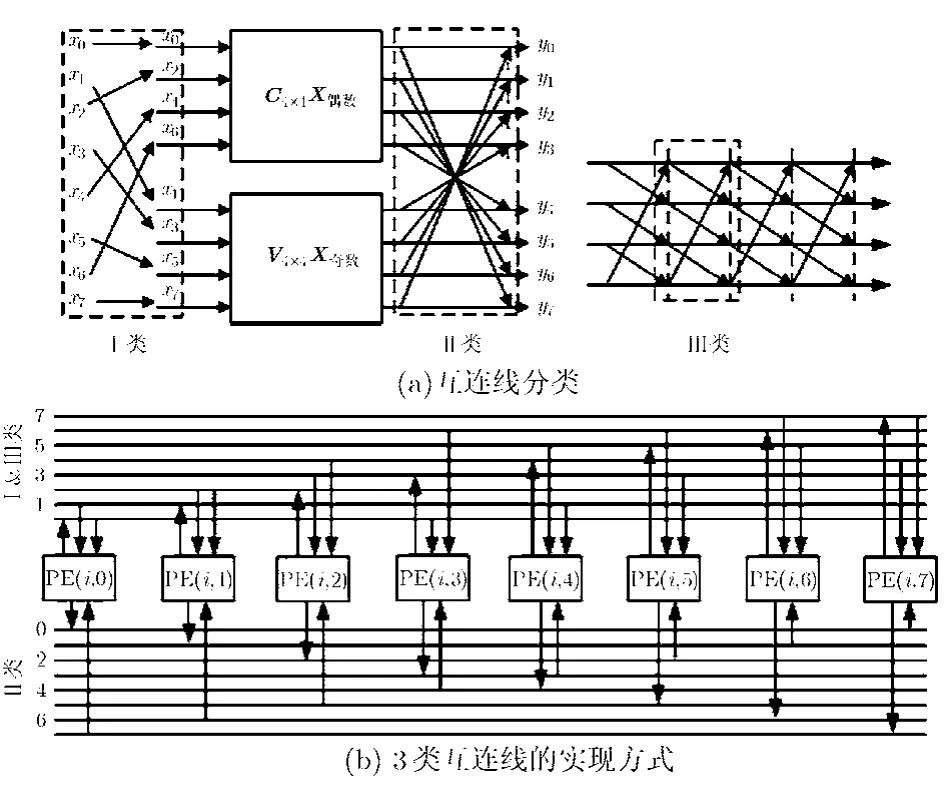
圖5 針對DCT為每行處理單元定制的3類互連線
Ⅲ類:除了P0和P1需要定制互連線之外,系數矩陣的乘法也需要定制互連線。一般來講,系數矩陣的計算采用4×4的蝶形運算來實現,但是這樣的設計需要過多的互連線支持,互連線增多對應著面積開銷增大。在本文提出的設計中,矩陣乘法是通過累加的方式實現的,而數據則是通過循環傳遞的方式,這種方法需要的互連線較少。對于C4×4X偶數,需要循環傳遞 x0,x2,x4,x6,因此需要互連線PE0→PE3, PE1→PE0,PE2→PE1, PE3→PE2。同樣,對于V4×4X奇數,需要互連線PE4→PE7,PE5→PE4, PE6→PE5, PE7→PE6。
4.1.2 消除矩陣轉置存儲器 矩陣轉置就是將矩陣中第i行的數據轉換為第i列的數據。如圖6(a)所示,將第i (i∈[0, 7],從上到下)行處理單元的數據同時輸出到第i根H總線上,同時將第i根H總線連接到第i (i∈[0, 7],從左到右)根V總線上,而V總線作為 1列處理單元的 1個輸入,在基于列的 1DIDCT的第1步時載入V總線輸入的數據。通過H總線和V總線即可實現矩陣轉置,無需占用額外的時鐘周期數,而由此導致的面積開銷與存儲器或者寄存器陣列相比是很小的。
4.1.3 定制處理單元的功能 處理單元的內部結構可以按照功能劃分為3個部分:
(1)輸入數據選擇:如圖6(b)所示,輸入數據的來源有6種:數據輸入總線,V總線,Ⅰ類互連線輸入的數據,Ⅱ類互連線輸入的數據、內部寄存器反饋的數據和Ⅲ類互連線輸入的數據。數據輸入總線和V總線輸入的數據是第4.1節中1D-IDCT計算過程中的第1步載入的數據,Ⅰ類總線傳遞的數據是1D-IDCT的第2步調換順序的數據,Ⅱ類互連線則是傳遞1D-IDCT的第3步累加所需的數據,Ⅲ類互連線輸入的數據則是用于完成 1D-IDCT的第 4步。
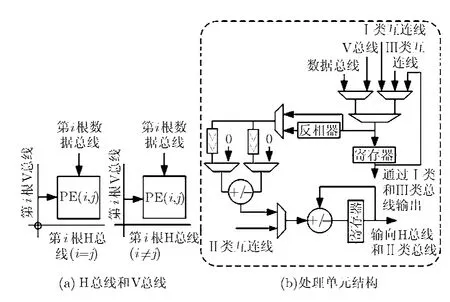
圖6 針對DCT定制的互連網絡以及處理單元結構
(3)累加器和數據輸出: 累加器用于系數矩陣乘累加的計算,對應于1D-IDCT的第3步。累加所需的數據通過Ⅱ類互連線循環傳遞。累加完成之后,需要對44×CX偶數和44×VX奇數的計算結果進行加減運算,即第 4步,以結束1D-IDCT的計算。第 4步所需的數據需要通過Ⅲ類互連線輸入。1D-IDCT完成之后輸出數據。若是基于行的1D-IDCT,那么輸出數據傳遞到 H總線上,如果是基于列的1D-IDCT,輸出數據傳給輸出模塊處理。
4.2 “階段級”流水線結構
本文提出的硬件電路結構構建了一種“階段級”流水線結構。通過這種結構,可以實現流水執行8×8尺寸大小的2D-IDCT/FDCT。整個計算過程可以劃分為3個階段:數據準備、計算和數據輸出階段,而每個階段對應1個流水級,每個階段所需的時鐘周期均一致,這樣可以實現平衡流水。而且,這種設計可以降低對輸入/輸出帶寬和I/O數目的需求,同時也可以以8×8尺寸大小的塊為單位加速完成整個視頻序列的處理。
4.2.1 時鐘分頻 為了構建流水線結構,本文在電路結構中定義了兩個時鐘域:(1)低頻時鐘域,包括數據準備和數據輸出模塊;(2)高頻時鐘域,包括CGRA。不同的視頻壓縮標準對應的高低頻時鐘域的時鐘周期比不同,如表2所示(其中,P代表時鐘周期)。在低頻時鐘域中,完成一個階段需要8個周期,轉換成時間之后等于高頻時鐘域完成一個階段的時間,即每個階段的執行時間是一致的,因此整個結構可以看成“平衡流水線”結構。
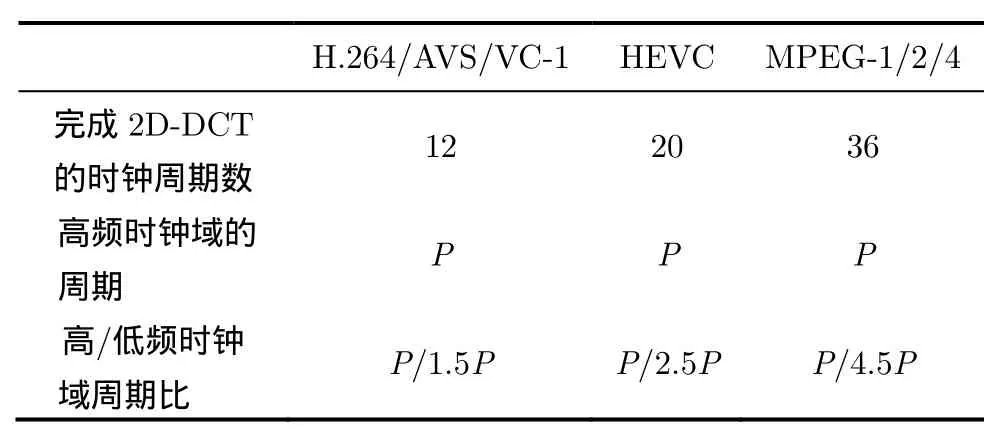
表2 不同標準數據準備階段周期的比較
4.2.2 數據準備和數據輸出模塊 數據準備和數據輸出模塊由低頻時鐘控制,完成一個階段需要8個時鐘周期。數據準備模塊由8個并行的串轉并模塊組成,每個周期載入 1個像素值,8個周期后拼接成 1行的數據,然后發出“Ready”信號。數據輸出模塊由 8個并行的并轉串模塊組成,在接收到CGRA發出的“Done”信號之后,將CGRA輸出的數據載入到數據輸出模塊,然后通過8個并轉串模塊,每個周期輸出8個數據,經過8個周期之后完成輸出。
4.2.3 功能可重構 本文提出的硬件電路具有動態可重構的特性,具體體現在:(1)通過配置,處理單元陣列的功能重構,實現對不同視頻標準的 DCT的支持。不同標準下,矩陣系數不一致,完成一次常系數乘法的周期也不相同。(2)通過配置,處理單元每個周期的功能重構,實現不同時鐘周期下的不同運算。不同標準下,常系數乘法所需的加減運算和移位操作不同,通過配置可選擇運算類型和移位數量。(3)通過配置,處理單元之間的互連網絡實現重構,實現 DCT不同步驟下的數據交換和傳輸。不同步驟下,需要傳遞的數據不相同,通過配置互連網絡實現數據的準確傳遞。為了闡明硬件電路可重構的特性,本文以在CGRA上映射HEVC的DCT為例描述電路重構的過程。
在CGRA上映射DCT時,每行處理單元完成8個像素的1D-DCT,對于HEVC,第1行第1個處理單元 PE(0,0)在 8個周期內完成 a x0+gx6+a x4+ f x2的計算,每兩個周期完成 1個常系數乘法,而常系數乘法是通過移位和加法實現,因此每個周期通過配置處理單元內部的移位器即可實現乘法。如圖7所示,可以看出PE的功能每個周期都會重構1次,這些功能包括:移位,直傳和移位加。而在計算過程中涉及的數據則通過配置3類互連線實現準確傳遞。
在CGRA上映射2D-DCT時,每行處理單元處理1行的像素,8行的處理單元并行處理8行像素,因此,在同1個周期時鐘內,每行的配置是一致的,而整個結構可以理解為 1個單指令多數據(Single Instruction Multiple Data, SIMD)。因此,CGRA每個周期所需的配置信息并不多,僅需1行處理單元的配置信息即可,8行處理單元共用一組配置信息。
4.2.4 整個流程 本文提出的硬件電路結構的工作流程為:(1)數據準備階段:利用8個低頻時鐘周期載入1個8×8尺寸大小的像素塊,載入完成之后發出“Ready”信號;(2)數據處理階段:接收到“Ready”信號,將8×8尺寸大小的像素塊分配到每行的處理單元,然后執行基于行的 1D-DCT,之后通過H總線和V總線進行轉置,轉置之后再進行基于列的1D-DCT,完成之后發出“Done”信號;(3)數據輸出階段:接收到“Done”信號,將CGRA的處理結果載入,然后每個周期輸出8個數據,利用8個周期完成數據輸出。
5 實驗結果與分析
本文提出的硬件電路結構通過Verilog HDL語言描述,并在SMIC 13 nm標準單元工藝庫下,通過 Synopsys EDA[12]工具鏈對整個設計進行了功能仿真、驗證和綜合。為了評估本文提出結構的性能優劣,本文挑選了8種設計作為參照,這些參照中既有支持單一標準的設計,又有支持多個標準的設計,表3給出了本文提出結構與這兩類設計的比較結果。由于本文提出的結構中采用的常系數乘法所需的時鐘周期是根據視頻標準的不同而調整的,因此需要按照視頻標準的不同劃分為3種工作模式,然后分別于參考設計進行比較,這3種工作模式與視頻標準的對應關系為:模式 1針對視頻標準H.264/AVC, VC-1和 AVS;模式 2針對視頻標準HEVC;模式3針對視頻標準MPEG-1/2/4。從表3可以看出,與支持單一標準的參考設計相比,本文提出結構的面積開銷處于劣勢,但是功耗的優勢較為明顯,這主要是因為本文提出的結構無需矩陣
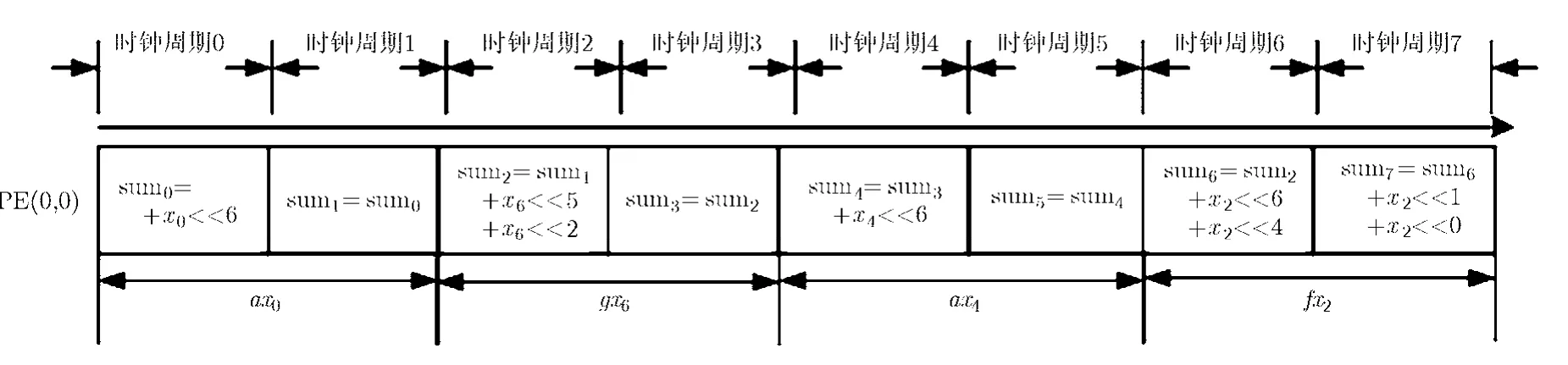
圖7 PE單元的功能可重構示例
轉置存儲器,因此也就省去了這一部分造成的動態功耗;與支持多個標準的參考設計相比,本文提出的結構的功耗方面的優勢顯然要高于面積開銷方面的優勢。為了較公平地比較本文提出結構與參考設計的性能差異,本文借助于設計效率和功耗效率這兩個指標來綜合評價這些設計。
5.1 設計效率
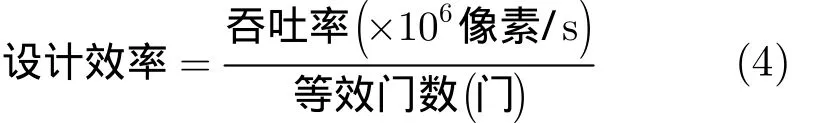
設計效率為吞吐率與等效門數的商,如式(4)所示,其與吞吐率成正比,與面積開銷(等效門數)成反比。如圖8所示,與只支持單一標準的參考設計相比,本文提出的結構的設計效率較低。這是因為只支持單一標準的參考設計功能單一,靈活性差,應用范圍局限于一種標準,而本文提出的結構支持多種標準,靈活性較高,而靈活性的提高必然以面積增加為代價,因此設計效率較低。但是,與支持多種標準的參考設計相比,本文提出的結構的設計效率優勢較明顯。當處于模式1時,吞吐率達到最大值,此時設計效率最高,與其他結構相比,最多提升4.33倍,最低提升1.57倍。模式2和模式3由于吞吐率的限制,設計效率的有所下降,但是依然比文獻[8]至少提升77.57%。
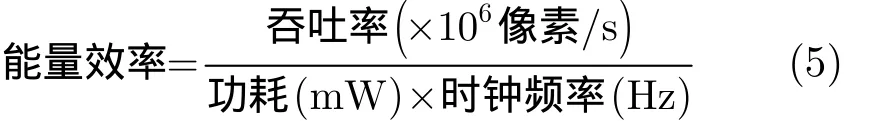
5.2 能量效率
能量效率是指每消耗單位mW的功耗處理的像素數目,計算方式如式(5)所示,其與吞吐率成正比,與功耗成反比。如圖9所示,本文提出結構的能量效率優勢較為明顯,模式1時,與其他結構(包括支持單一標準和支持多個標準的參考設計)相比,本文提出的結構的能量效率最高提升12.3倍,最低提升14.6%,而在模式2和模式3時,由于吞吐率的限制,能量效率略有下降,但是依然比文獻[2-4,7-8]至少提升77.7%。

5.3 視頻序列的解碼能力評估
為了評估本文提出的結構在實時解碼視頻序列方面的能力,給出了硬件電路解碼視頻序列時可以達到的最高幀率。最高幀率是指1秒鐘內,實時解碼某種格式的視頻序列的幀數,如式(6)所示,其與吞吐率成正比,公式中的格式系數根據視頻格式為4:2:0還是4:4:4分別設置為1.5和3.0。表4給出了在不同視頻尺寸下由式(6)計算得來的評估值,可以看出,本文提出的結構能夠在任意模式下以30幀/s的幀率,實時解碼最大尺寸為 4096×2048,格式為4:2:0的視頻序列。
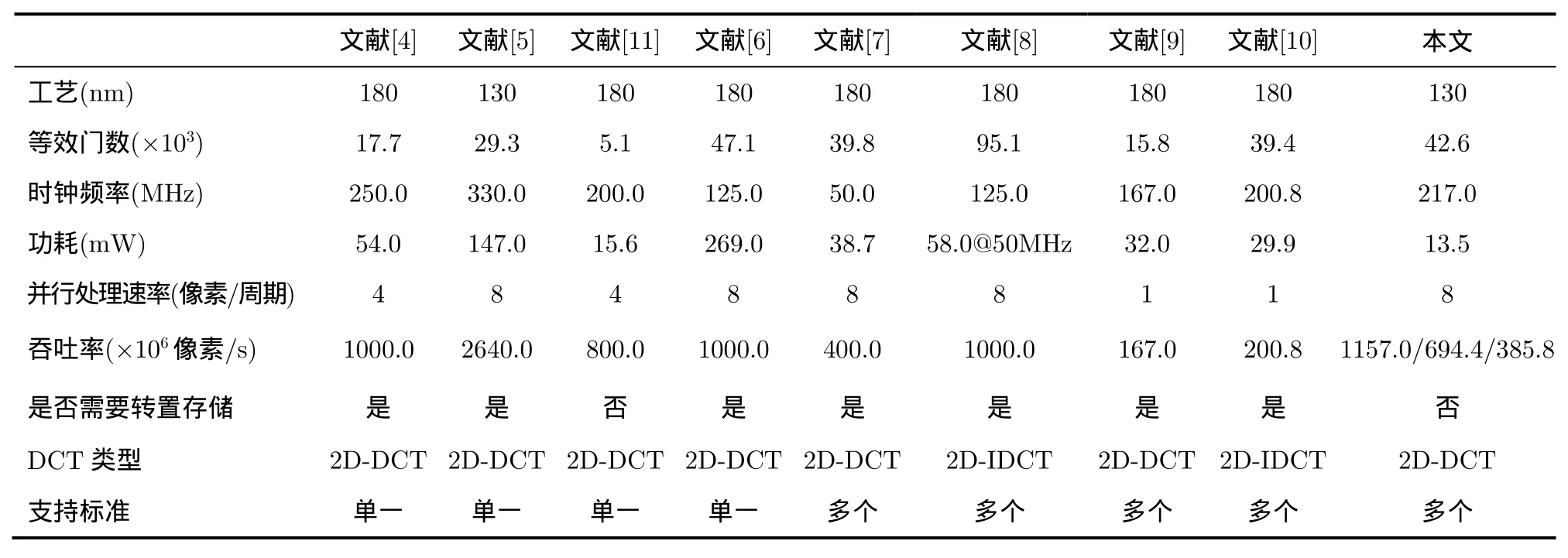
表3 本文提出的結構與參考設計的比較結果
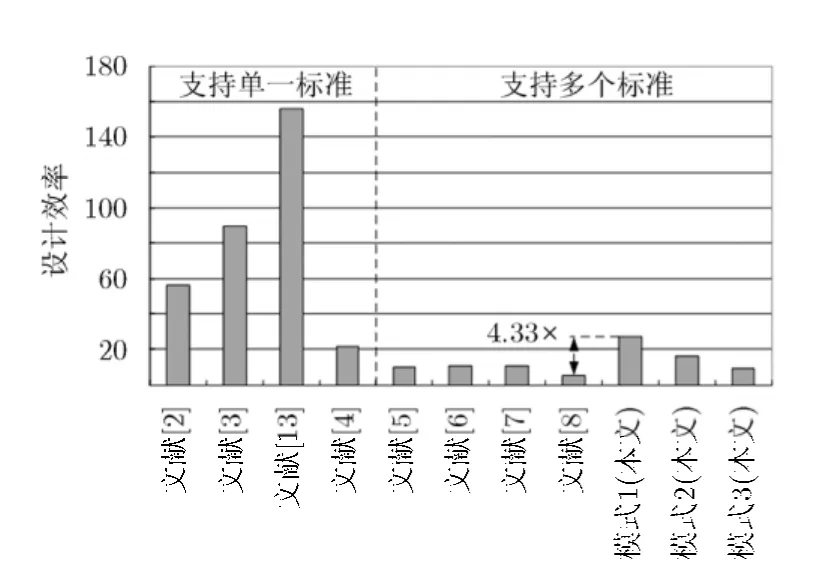
圖8 設計效率的比較結果
6 結束語
本文基于粗粒度可重構陣列結構,設計了一款支持多個視頻壓縮標準的8×8離散余弦變換的硬件電路結構。利用粗粒度可重構陣列結構的可重配置的特性,根據不同的視頻標準,調整工作模式,從而實現支持多個視頻壓縮標準的2D-FDCT/IDCT。通過定制粗粒度可重構陣列結構的互連網絡,本文提出的結構在矩陣轉置時無需占用額外的時鐘周期,也無需借助于存儲器。而且,整個電路結構形成了一種“階段級”流水線結構,能夠實現流水處理8×8尺寸的像素塊。實驗結果顯示,與已有支持多個標準的結構相比,設計效率最高可提升4.33倍,最低提升77.5%,能量效率最高提升12.3倍,最低提升14.6%,而且能夠以最高30幀/s的幀率實時處理尺寸為4k×2k(4096×2048),格式為4:2:0的視頻序列。

表4 本文提出結構的視頻序列解碼能力評估
[1] Richardson I E G. Video Codec Design: Developing Image and Video Compression Systems[M]. New York: John Wiley& Sons Ltd., 2002: 127-161.
[2] Chen Y, Chang T, and Lu C. A low-cost and high-throughput architecture for H.264/AVC integer transform by using four computation streams[C]. Proceeding of the 13th International Symposium on Integrated Circuits (ISIC), Singapore, 2011: 380-383.
[3] Michell J A, Solana J M, and Ruiz G A. A high-throughput ASIC processor for 8×8 transform coding in H.264/AVC[J]. Signal Processing: Image Communication, 2011, 26(2): 93-104.
[4] Sun C C, Donner P, and G?tze J. VLSI implementation of a configurable IP Core for quantized discrete cosine and integer transforms[J]. International Journal of Circuit Theory and Applications, 2012, 40(11): 1107-1126.
[5] Huang C, Chen L, and Lai Y. A high-speed 2-D transform architecture with unique kernel for multi-standard video applications[C]. IEEE International Symposium on Circuits and Systems (ISCAS), Seattle, WA , USA, 2008: 21-24.
[6] Fan C, Fang C, Chang C, et al.. Fast multiple inverse transforms with low-cost hardware sharing design for multistandard video decoding[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2011, 58(8): 517-521.
[7] Chen Y and Chang T. A high performance video transform engine by using space-time scheduling strategy[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems,2012, 20(4): 655-664.
[8] Martuza M and Wahid K A. Implementation of a cost-shared transform architecture for multiple video codecs[J]. Journal of Real-Time Image Processing, 2012, 1-12,doi:10.1007/s11554-012-0266-5.
[9] Choi K. Coarse-grained reconfigurable array: architecture and application mapping[J]. IPSJ Transactions on System LSI Design Methodology, 2011, http: //dx. doi. org/ 10.2197/ipsjtsldm. 4.31.
[10] 魏少軍, 劉雷波, 尹首一. 可重構計算處理器技術[J].中國科學:信息科學, 2012, 42(12): 1559-1576.Wei S J, Liu L B, and Yin S Y. Key techniques of reconfigurable computing processor[J]. SCIENCE CHINA:Information Sciences, 2012, 42(12): 1559-1576.
[11] Chen W H, Smith C, and Fralick S. A fast computational algorithm for the discrete cosine transform[J]. IEEE Transactions on Communications, 1977, 25(9): 1004-1009.
[12] Synopsys Corporation. Accelerate design innovation with design compiler: accelerate design innovation with design compiler[OL].http://www.synopsys.com/Tools/Implementati on/RTLSynthesis/Pages/default.aspx. January 2014.
[13] Qi H, Wei C, and Tong J. A dynamically reconfigurable VLSI architecture for H.264 integer transforms[J]. Chinese Journal of Electronics, 2012, 21(3): 510-514
猜你喜歡
城市道橋與防洪(2022年4期)2022-07-01 06:04:12
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
當代陜西(2019年8期)2019-05-09 02:22:48
動漫星空(興趣百科)(2019年3期)2019-03-07 07:23:10
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
專用汽車(2016年4期)2016-03-01 04:13:43
