一種基于MIB信息熵統計的網絡異常檢測方法
2015-12-17 07:14:55蘇慶剛羅宜元
上海電機學院學報 2015年2期
趙 雷, 蘇慶剛, 羅宜元
(上海電機學院 電子信息學院, 上海 200240)
?
一種基于MIB信息熵統計的網絡異常檢測方法
趙雷,蘇慶剛,羅宜元
(上海電機學院 電子信息學院, 上海 200240)
摘要:針對網絡發展中出現的犯罪和攻擊,研究了基于管理信息庫(MIB)信息熵統計的網絡異常發現方法。給出了基于MIB的網絡異常發現的相關概念及實現方法。在此基礎上,討論了固定時間窗口和滑動時間窗口在該方法中的應用。與傳統的網絡異常檢測方法相比,該方法能夠實時、有效地檢測網絡異常的發生。選取大型網絡提供商的MIB數據為應用背景,驗證了方法的準確性和精確性。
關鍵詞:網絡異常檢測; 管理信息庫; 信息熵; 時間窗口

近年來,隨著國際互聯網的迅速發展,計算機網絡在現代社會中發揮著日益重要的作用。隨著網絡規模不斷擴大,網絡設備和網絡應用、服務相應增多,網絡已成為犯罪或敵人攻擊的目標之一。如何快速有效地檢測網絡異常并提高檢測可靠性已成為一大研究熱點。
異常檢測(anomaly detection)是指建立系統正常的模式輪廓,若實時獲得的系統或用戶的輪廓值與正常值的差異超出指定的閾值,就進行入侵報警[1-3]。異常檢測依賴于異常模型的建立,模型不同,檢測方法也不同。常用的異常入侵檢測方法包括基于機器學習的方法[1-2]、基于統計的入侵檢測方法[3-6]、基于小波分析的方法[7]、基于貝葉斯網絡和貝葉斯推理的異常檢測方法[8-9]、基于數據挖掘的異常檢測方法等[10-14]。其中,基于統計的方法由于具有建模容易、檢測精度高、易于與其他方法結合使用等優點而被廣泛使用。
早期用于網絡異常檢測的方法是統計假設檢驗,其中,順序概率比測試(Sequential Probability Ratio Test, SPRT)和似然比(likelihood Ratio, LR)檢驗[3]是較為典型的網絡異常檢測方法。Wald證明了有效天SPRT族中一定存在一個一致最有效的貫序檢驗,但不易檢測突發性異常;LR檢驗對于網絡異常檢測具有顯著的適用性和良好的統計性,但缺點是缺乏容錯能力[3]。近年來,基于統計的方法被廣泛應用。文獻[4]中通過定義一個新的統計量并建立AR模型,可以實時和有效地發現連續網絡數據流中的異常特征。文獻[5]中提出了一種基于統計推演的異常檢測技術。文獻[7]中結合統計方法和機器學習,提出了基于樸素貝葉斯分類的網絡異常檢測模型,具有較高的發現精確度。文獻[8]中將文本分類中的最大信息熵技術應用于網絡異常分類中,對連續流量特征的網絡進行分類。文獻[12]中提出了一種大規模高速網絡環境中網絡熵值估算的方法,將基于熵的網絡流量異常檢測應用于大規模高速網絡環境中。文獻[13]中使用機器學習和統計方法,對網絡數據流的時間序列和特征空間進行綜合檢測,具有較好的實時特性。通過選取路由器中的管理信息庫(Management Information Base, MIB)數據,文獻[14]中提出了針對大規模網絡數據流和網絡管理漏洞進行異常檢測的策略。目前,大部分的異常檢測策略都具有不依賴于攻擊特征,立足于受檢測的目標發現入侵行為的優點。但是,如何建立異常指標、定義正常的模式輪廓、降低誤報率,是異常檢測難以解決的問題[15]。
本文嘗試建立新的網絡異常指標與正常模式輪廓,將MIB數據與信息熵統計方法相結合,研究了基于MIB信息熵統計的網絡異常發現方法,給出了基于MIB的網絡異常發現的相關概念及方法;在此基礎上,討論了固定時間窗口和滑動時間窗口在該方法中的應用;并選取大型網絡提供商的MIB數據為應用背景,結果顯示該方法能夠有效、實時地檢測網絡異常,并具有一定的準確性和精確性。
1基于MIB的異常檢測
異常檢測系統主要分為3個部分: 數據預處理單元、數據處理單元和異常檢測單元。檢測流程如圖1所示。

圖1 基于MIB的網絡異常檢測流程Fig.1 Overview of network anomaly detection using MIB
圖中,數據預處理單元與數據處理單元的主要功能是從MIB中選擇適當的變量進行分析。如MIB中有11類對象數據,包括系統基本信息(如system類)或與協議相關的信息(如IP類和TCP類)等,由于這些數據的非數值型以及與網絡應用的相關性太強,不適合用作普遍性的異常檢測。本文選取MIB中的interfaces類為指標集。該類型標識的內容是網絡接口的信息,如通過接口的數據包數量等,而與具體的協議無關,具有與應用無關的普遍性,適合用作普遍性異常檢測。
在變量的選取方面,也可以通過合并對象的方式進行研究,如MIB中ifInOctets指標集隨時間變化的指標用x(t)表示,而MIB中ifInDiscards指標集隨時間變化的指標用y(t)表示。若綜合考查兩項指標,也可以將它們結合起來,用變量z(t)=x(t)+αy(t)表示,其中,α為變量y(t)的權值。本文采用基于信息熵統計的網絡異常檢測方法。
定義1信息熵。設一個離散隨機變量xi和它的分布概率為p(xi),i=1,2,…,r,則r個隨機變量的不確定性的度量簡稱為熵,記為
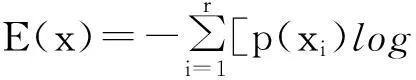
(1)
定義2固定時間窗口。按照時間順序依次選取固定時間段的方法稱為固定窗口,如圖2所示。

圖2 固定時間窗口設置Fig. 2 Fixed time window model
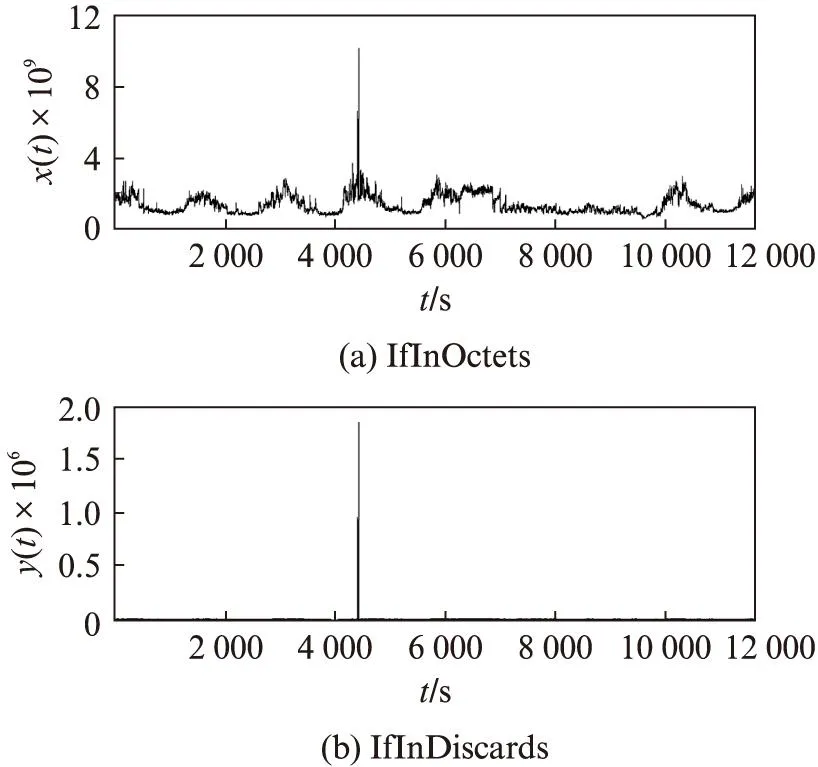
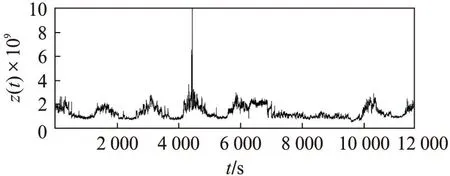
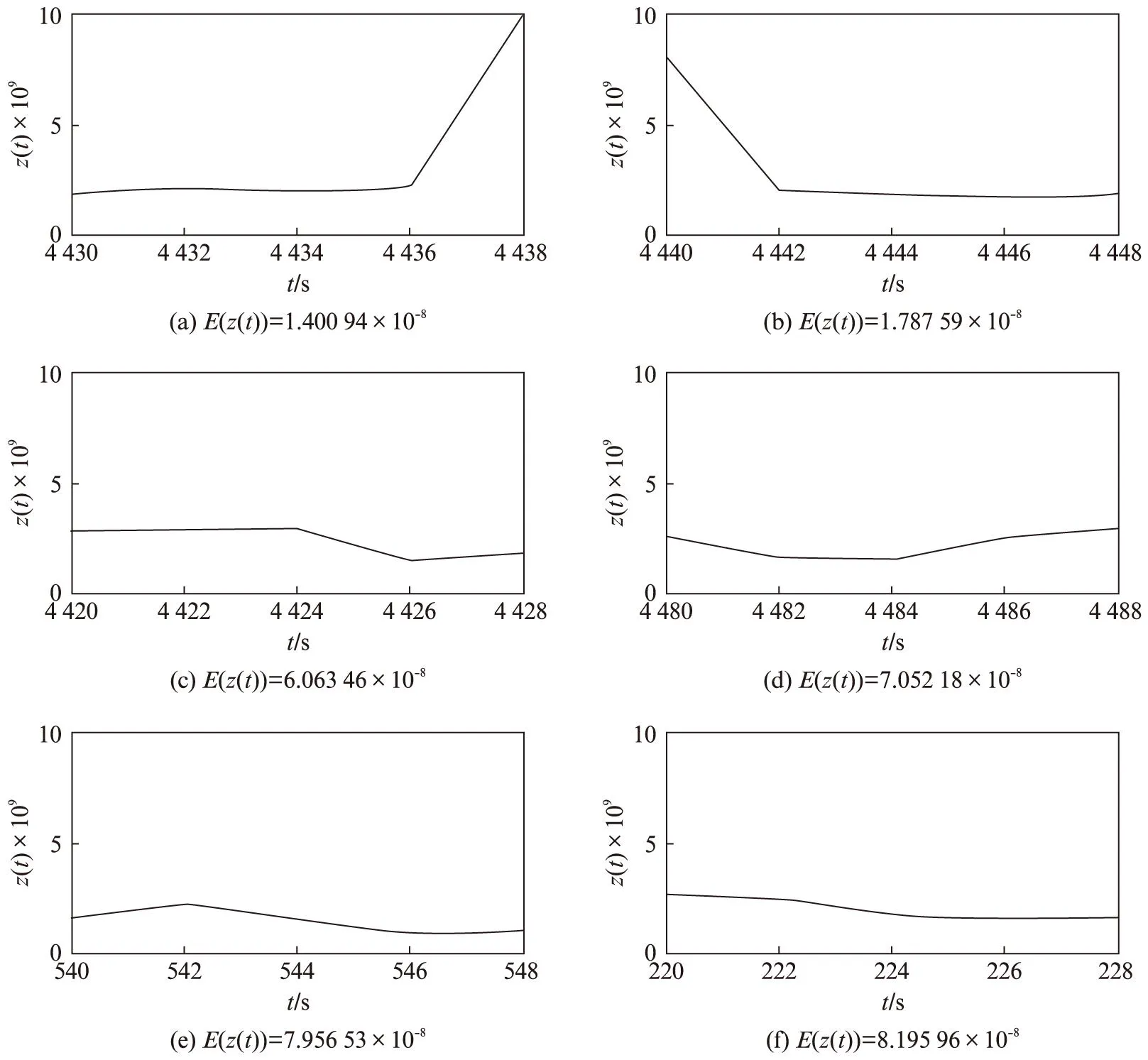
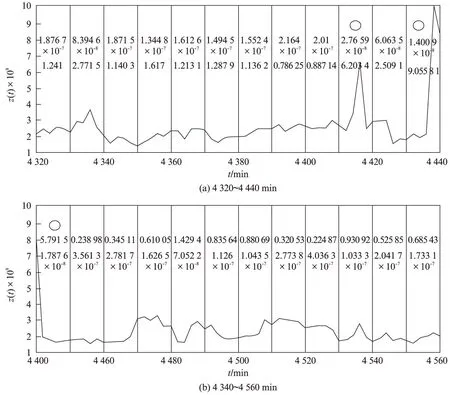
定義3滑動時間窗口。設一個時間窗口內部有m個時間點。滑動窗口是后繼時間窗口作為前時間窗口向前滑動p(p 圖3 滑動時間窗口設置Fig.3 Sliding time window model 定義4熵比。在固定窗口或滑動窗口中,前s(s≥1)個時間窗口指標變量具有的平均信息熵與當前窗口指標變量信息熵的比值,稱為熵比。熵比在一定程度上反映了最近一段時間內信息熵的變化程度。 2基于MIB的信息熵統計的異常檢測 interfaces類指標集主要包括12種數值型變量指標,如表1所示。 表1 MIB中interfaces類主要指標列表Tab.1 Indicators of interface class in MIB 本文數據采自某大型網絡設備供應商提供的實時MIB數據記錄,路由器中每2min都會對MIB進行更新。圖4給出了該MIB中部分interfaces類的指標記錄,依次記錄了表1中12種數值型變量指標值。 圖4 MIB中interface類的指標記錄舉例Fig.4 Example of records for interface class in MIB 由圖4可見,8月4日星期一11:44接口收到的總比特數(ifInOctets指標)為828590480,接口收到并丟棄的包數(ifInDiscards指標)為0,接口傳送出的單播包數(ifOutVcastPkts)為3108960798。 本文以對MIB中ifInOctets指標進行網絡異常檢測為例,設時間窗口TWk為時間點k到k+w的時間段,其中,窗口大小為w;時間點t(t=k,k+1,…,k+w)處的ifInOctets指標值(即時間點t處接口收到的總比特數)為bt,時間點單位為min,則接口在時間點i接收到的比特數為 xt=bt-bt-1 (2) 為衡量時間窗TWk內接收比特xt的不確定性,可以通過其信息熵來體現。歸一化xt,令 (3) 假設zt近似服從某種概率分布,若為正態分布,則zt滿足 (4) 時間窗TWk在變量zt上的信息熵為 (5) 由于p(zi)取值區間為(0,1],故logp(zt)≤0且隨p(zt)單調遞增,則E(TWk)也隨p(zt)單調遞增。因此,若窗口內部接收到的比特數發生異常,則zt滿足正態分布的概率降低,熵值變小;反之亦然。 為了更好地反映近一段時間內網絡接收比特的變化,可以通過計算前一段時間(如前個時間窗口)的平均熵和當前窗口熵的比值來反映當前熵的變化。定義第s個窗口的熵比為 (6) 式中,j為循環變量。 若熵比超出給定閾值,則可判定此時間窗口內發生了網絡異常。在時間窗口的設置時,則可以采取固定和滑動窗口兩種方法。 本文以ifInOctets指標為例,給出基于MIB信息熵統計的異常檢測算法。 步驟1定義窗口大小n和窗口的滑動距離p。 步驟2按照滑動窗口設置依次遞進計算每個窗口的熵值和熵比值。 (1) 計算時間窗口內各時間點的比特數xt和歸一化值zt; (2) 計算各時間點上zt的概率p(zt); (3) 計算窗口在zt上的熵值和熵比值。 步驟3異常判斷。將所得熵值或熵比值與給定閾值進行比較,若超出范圍,即判斷此時間窗口內有數據突變或有不符合之前規律的情況發生,即可能發生異常。 3實驗及分析 在思科研究中心模擬一個小型網絡,其中1臺路由器連接3個子網,路由器采用思科Cisco 7500。3個子網中1個連接HTTP服務器,1個子網上具有一個SQL Server數據庫服務器,最后1個子網用來模擬DDoS攻擊。人為制造4種網絡異常類型,包括:服務器CPU占用、DDoS攻擊、數據庫關閉和HTTP服務器中斷。模擬運行時間為24h,在路由器上收集MIB數據,用Matlab軟件進行模擬軟件編程實現,其中運行軟件的計算機CPU主頻為2.4GHz,內存為2GB。 本文考察IfInOctets和IfInDiscards指標變量在0~12000min內的變化情況,如圖5所示。 圖5 IfInOctets和IfInDiscard指標變量數據分布Fig.5 Distribution of IfInOctets and IfInDiscard indicators 合并考察IfInDiscards(用x(t)表示)和IfInOctets(用y(t)表示),得到新的變量指標z(t),其中,α=3000。其數據分布如圖6所示。 以z(t)為例進行測試,隨機取6個時間窗口內的信息熵值如圖7所示。由圖7可見,曲線越平緩,其熵值越小。由熵的定義可知[6],熵值越小,規則性越明顯,則判定異常發生的可能性越大,反之亦然。另一方面,熵比越大,則當前信息熵與過去一段時間內的平均信息熵相比越小,反映在網絡上則認為發生異常的可能性越大。 圖6 IfInOctets和IfInDiscard合并后的數據分布Fig.6 Combinations of IfInOctets and IfInDiscard indicators 圖7 z(t)變量6個時間窗口的熵的計算Fig.7 Example of entropy computing for 6 different time windows 本文根據圖7,設窗口大小為10,采用固定窗口,利用基于MIB信息熵統計的異常檢測算法1計算4320~4560時間段內各窗口熵值和熵比值,如圖8所示。 圖中,有圓圈標注的窗口z(t)發生了突變。利用實驗計算可以得到圖8中各時間窗口的數據,其中上方為窗口的熵值,下方為各窗口的熵比值(本文采用當前窗口熵與之前12個窗口(即2min)的平均熵的比值)。由圖可見,時間窗口[4410,4420]的熵值和熵比值分別為2.7659×10-8和6.2034;時間窗口[4430,4440]的熵值和熵比值分別為1.4009×10-8和9.0558;時間窗口[4440,4450]的熵值和熵比值分別為1.7876×10-8和5.7915。閾值可以動態設定為當前窗口之前的n個正常窗口熵或熵比的平均值,試驗中設n=5。經計算,這3個窗口的計算值都遠遠超出了對應閾值,因此可診斷網絡有異常發生。 圖8 4320~4560min內各時間窗口熵值和熵比值Fig.8 Entropy values computed in time 4320-4560 minutes 在使用相同數據源的情況下,將本文方法與兩種異常檢測的最常見算法,即廣義似然比(Generalized Lkelihood Ratio, GLR)方法和主成分分析方法 (Principal Component Analysis, PCA)進行比較分析。GLR方法要求預先給出數據的正常模式,并在假設數據符合自回歸(Auto Regressive, AR)模型的情況下計算測試數據的最大似然率[1]。PCA方法則主要用于對給定的數據進行正常和異常部分的分類[7],將MIB數據表示為時間向量序列并通過主成分方法進行正常和異常數據的分類。利用給出的MIB數據 ,考慮兩個相鄰的時間窗口u(t)和w(t)以及這兩個時間窗口的并集uw(t),在GLR方法中,模擬每個窗口為AR模型并計算AR中的殘差,通過與給定的殘差閾值進行比較,判斷是否發生異常。表2給出了3種方法下的CPU時間和內存的耗費。 表2 3種方法下的CPU時間和內存耗費比較Tab.2 Comparision of CPU time consumption and memory needs among three methods 由表2可知,GLR方法和PCA方法需要較高的CPU時間,主要原因如下: GLR方法中,要對每個窗口中的數據進行回歸分析,而PCA方法需要計算矩陣的特征值,故它們都耗費了較高的CPU時間;同時,由于PCA方法處理的是由變量值構成的矩陣向量,故需要占用較大的內存空間。 利用本文的檢測方法對服務器CPU占用、數據庫性能問題、數據庫關閉、服務器中斷4種不同的異常實驗進行準確率和精確率的統計分析。其中,準確率是正確檢測出網絡異常的次數和網絡總異常發生次數的比率,如在統計100次異常情況發生的情況下,系統檢測出了所有異常,則準確率為100%;精確率是誤檢測發生的概率,即網絡正常情況被錯判為異常或網絡異常情況被錯判為正常所發生的概率,如100次檢測中,有1次網絡正常被檢測為異常且有1次網絡異常被檢測為正常,則精確率為98%。表3給出了統計結果。 表3 異常檢測準確率和精確率統計Tab.3 Accuracy and precision ratio of four abnormal types 由表3可見,該方法的準確率及精確率都是相當高的,實驗結果令人滿意。 4結語 本文結合MIB指標與信息熵統計技術,研究了基于MIB的信息熵統計進行網絡異常檢測方法。對各指標之間的相關性進行深入研究,構建時間窗口,通過檢測窗口內熵值和熵比值變化情況判斷異常是否發生。實驗檢測結果表明,該方法能以極高的準確率及精確率對單個和多個異常節點的情況進行檢測;對于建立網絡流量的真實視圖,準確評估網絡蠕蟲、網絡服務器故障等安全事件對網絡所造成的影響具有重要指導意義。 參考文獻: [1]Gavalas D,Greenwood D,Ghanbari M,et al.Advanced network monitoring applications based on mobile/intelligent agent technoloy[J].Computer Communications,2002,23(8): 720-730. [2]Tagliaferri R,Eleuteri A,Meneganti M,et al.Fuzzy min-max neural network: from classification to regression[J].Soft Computing,2001,5(1): 69-76. [3]Basseville M,Nikiforov I V.Detection of abrupt changes: theory and application[M].New York: Prentice Hall,1993: 350-412. [4]Simmross-Wattenberg F,Juan I A.Anomaly detection in network traffic based on statistical inference and alpha-stable modeling[J].IEEE Transactions on Dependable and Secure Computing,2011,8(4): 494-509. [5]魏小濤,黃厚寬,田盛豐.在線自適應網絡異常檢測系統模型與算法[J].計算機研究與發展,2010,47(3): 485-492. [6]曹敏,程東年,張建輝,等.基于自適應閾值的網絡流量異常檢測算法[J].計算機工程,2009,35(19): 164-166. [7]Lakhina A,Crovella M,Diot C.Diagnosing network-wide traffic anomalies[C]∥Proceedings of the ACM SIGCOMM.Portland,Oregon,USA: ACM,2004: 219-230. [8]錢葉魁,陳鳴,葉立新,等.基于多尺度主成分分析的全網絡異常檢測方法[J].軟件學報,2012,23(2): 361-377. [9]卿斯漢,蔣建春,馬恒太,等.入侵檢測技術研究綜述[J].通信學報,2004,25(7): 19-29. [10]鄒柏賢.一種網絡異常實時檢測方法[J].計算機學報,2003,26(8): 940-948. [11]宿嬌娜,李巍,唐發根,等.基于NB分類方法的網絡異常檢測模型[J].計算機應用研究,2008,25(2): 569-571. [12]錢亞冠,關曉惠,王濱.基于最大信息熵模型的異常流量分類方法[J].計算機應用研究,2012,29(3): 1019-1023. [13]Limthong K.Real-time computer network anomaly detection using machine learning techniques[J].Journal of Advances in Computer Networks,2013(1): 1-5. [14]俞承志,王淑靜,宋瀚濤.基于MIB-Ⅱ的網絡安全入侵檢測策略[J].北京理工大學學報,2004,5(8): 696-700. D,Greenwood D,Ghanbari M,et al.Advanced network monitoring applications based on mobile/intelligent agent technoloy[J].Computer Communications,2002,23(8): 720-730. [2]Tagliaferri R,Eleuteri A,Meneganti M,et al.Fuzzy min-max neural network: from classification to regression[J].Soft Computing,2001,5(1): 69-76. [3]Basseville M,Nikiforov I V.Detection of abrupt changes: theory and application[M].New York: Prentice Hall,1993: 350-412. [4]Simmross-Wattenberg F,Juan I A.Anomaly detection in network traffic based on statistical inference and alpha-stable modeling[J].IEEE Transactions on Dependable and Secure Computing,2011,8(4): 494-509. [5]魏小濤,黃厚寬,田盛豐.在線自適應網絡異常檢測系統模型與算法[J].計算機研究與發展,2010,47(3): 485-492. [6]曹敏,程東年,張建輝,等.基于自適應閾值的網絡流量異常檢測算法[J].計算機工程,2009,35(19): 164-166. [7]Lakhina A,Crovella M,Diot C.Diagnosing network-wide traffic anomalies[C]∥Proceedings of the ACM SIGCOMM.Portland,Oregon,USA: ACM,2004: 219-230. [8]錢葉魁,陳鳴,葉立新,等.基于多尺度主成分分析的全網絡異常檢測方法[J].軟件學報,2012,23(2): 361-377. [9]卿斯漢,蔣建春,馬恒太,等.入侵檢測技術研究綜述[J].通信學報,2004,25(7): 19-29. [10]鄒柏賢.一種網絡異常實時檢測方法[J].計算機學報,2003,26(8): 940-948. [11]宿嬌娜,李巍,唐發根,等.基于NB分類方法的網絡異常檢測模型[J].計算機應用研究,2008,25(2): 569-571. [12]錢亞冠,關曉惠,王濱.基于最大信息熵模型的異常流量分類方法[J].計算機應用研究,2012,29(3): 1019-1023. [13]Limthong K.Real-time computer network anomaly detection using machine learning techniques[J].Journal of Advances in Computer Networks,2013(1): 1-5. [14]俞承志,王淑靜,宋瀚濤.基于MIB-Ⅱ的網絡安全入侵檢測策略[J].北京理工大學學報,2004,5(8): 696-700. Entropy Statistics Method for Network Anomaly DetectionBased on Management Information Base ZHAOLei,SUQinggang,LUOYiyuan (School of Electronic Information Engineering, Shanghai Dianji University, Shanghai 200240, China) Abstract:Networks play an increasingly vital role in the modern society, while they are also targets of attacks by criminals and enemies. This paper proposes an entropy-based real-time method that can report entropy contents of data provided by a management information base (MIB). Change of the entropy value indicates a massive network event, meaning that anomaly may happen. Application of fixed time windows and sliding time windows are considered. Experiments are carried out with data from a large network company. The result shows that the method is accurate and precise in a wide variety of computing environments. Key words:network anomaly detection; management information base(MIB); information entropy; time window 文章編號2095-0020(2015)02-0102-08 作者簡介:覃海煥(1978-),女,博士,講師,主要研究方向為工作流、服務計算、云計算和大數據,E-mail: qinhh@sdju.edu.cn 基金項目:上海電機學院重點學科建設項目資助(13XKJ01,A1-1201-14-005) 收稿日期:2015-02-02 中圖分類號:TP 393.08 文獻標志碼:A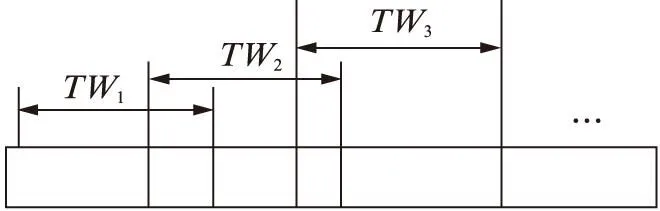
2.1 數據采集與指標選取


2.2 基于MIB信息熵統計的網絡異常檢測及算法
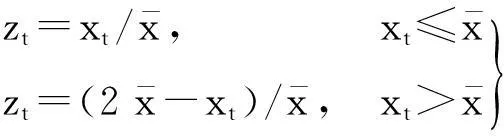
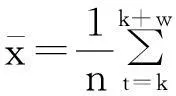
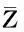
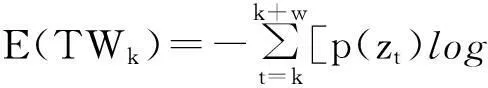
3.1 時間窗口MIB數據信息熵的計算
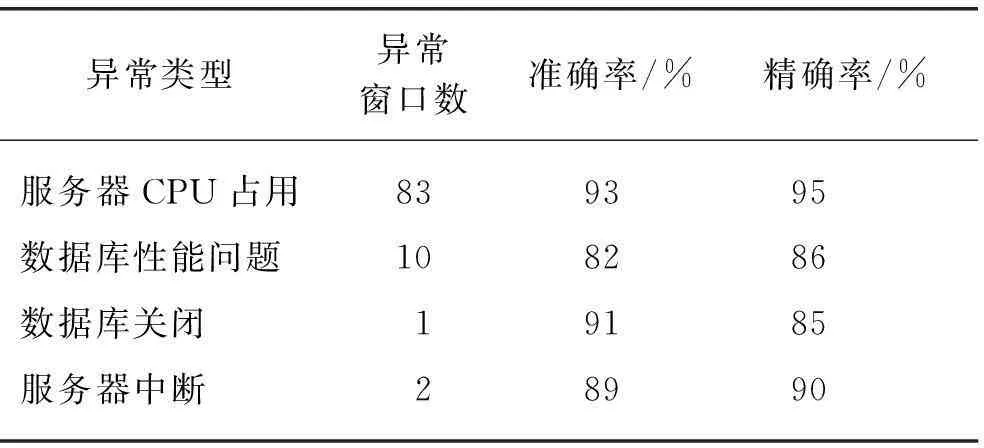
3.2 異常檢測實驗及分析
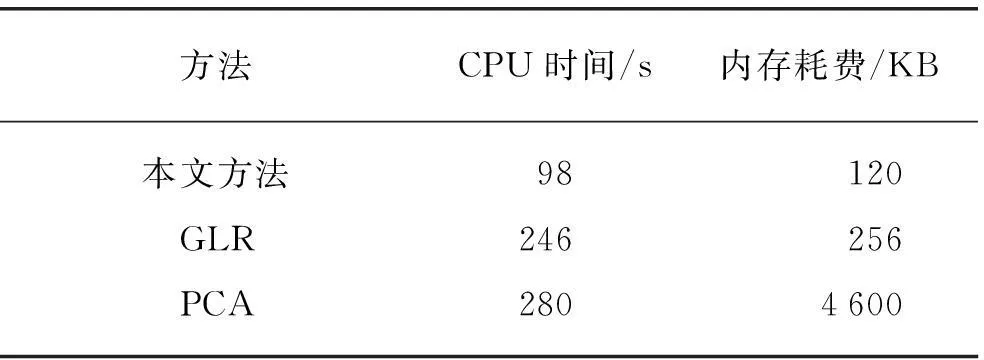
3.3 與其他方法的比較