基于Apriori算法的網絡社區知識形成影響因素分析
2015-12-25 00:57:28徐凡
科技視界 2015年18期
徐 凡
(西南科技大學,四川 綿陽 621010)
關聯規則是數據挖掘中最常用的方法,關聯規則挖掘的主要目的是從大量的數據中尋找關聯性,為決策分析提供理論支持[1]。關聯規則運用最經典的運用是購物籃分析“啤酒與尿布”的例子。而關聯規則中最常運用到的是Apriori 算法,它能夠根據用戶提供的條件有效的進行數據挖掘。
1 Apriori 算法及其特點
Agrawal 等人在1993年首次提出關聯規則,該規則主要用于挖掘數據之間的關聯性,對事物之間的親密度進行描述。關聯規則可描述為:設I={i1,i2,…,in}是項目集,D 是全體事務的集合,集合T∈I,即T 為I 的子集,每個事務有唯一的TID 標識。關聯規則就是形如X=>Y 的蘊含式,其中X∈I,Y∈I 且X∩Y=φ,X 稱為規則的條件,Y 稱為規則的結果[1]。運算結果通過支持度和可信度進行約束。
關聯規則中的支持度(Support)S 表示D 中有S%的事務同時包含X 和Y,即事務集中同時包含X 和Y 的事務數與所有事務數之比,記作Support(X,Y)=P(X∪Y)。置信度(Confidence)C 表示D 中有C%的事務同時也包含Y,即包含X 和Y 的事務數與包含X 的事務數之比,記作Confidence(X,Y)=P(Y/X)=P(X∩Y)/P(X)[2]。運用關聯規則進行數據挖掘就是要挖掘出滿足用戶設定的最小支持度和置信度的規則。我們把同時滿足用戶設定的最小支持度和最小置信度的規則稱為強規則。關聯規則的數據挖掘,一般分為兩步:首先找出所有滿足用戶設置的最小支持度的項目集,其次利用最大數據項集所生成的關聯規則,根據用戶指定的最小置信度確定規則的取舍,最后得到強關聯規則[1]。
Apriori 算法作為經典的關聯規則算法,其算法的實現是通過對數據庫進行掃描從候選項集中找出頻繁項,不斷對候選項計數來完成的。它使用的是逐層搜索的迭代方法,通過對前一項集的探索來發現符合該次條件的項集。也就是說,Apriori 算法的基本思想是通過對數據庫的多次掃描以發現所有符合條件的頻繁項。在第k 次掃描中只考慮具有同一長度k 的所有項集。在后續的掃描中,首先以前一次所發現的所有頻繁項集為基礎,生成所有新的候選項集。然后掃描數據庫D,計算這些候選項集的支持度,最后確定候選項集中哪些可成為頻繁項集。重復上述過程直到再也產生不出新的頻繁項集。在計算過程中,Apriori 算法需要不斷重復連接與剪枝這兩個步驟。然而該算法也存在潛在的問題,即當數據容量龐大時,生成的候選項集數量太多,會降低該算法的計算效率,同時大量規則的產生也讓用戶難以選擇,這也是在運用Apriori 算法是需要解決的問題[3]。
2 數據準備
2.1 數據來源
為研究網絡社區中知識形成過程中哪些因素對其產生了影響,本文通過對網絡社區中知識形成過程進行分析,著重思考了在知識形成中哪些因素會影響到個人對網絡社區知識的吸收,重點考慮了九個方面的因素來分析,主要包括參與的目的性、成員級別、個人專業知識、知識接收者的知識結構、回帖數量、表達方式、回帖者態度、信息源、社區參與者的線下關系這九個方面,分析了以上九個方面的因素對知識形成產生的影響。通過網絡問卷調查的方式,共收獲共119 份問卷,為文章提供了原始數據。
2.2 數據預處理
對于部分數據,參與調研者的態度并不是很明確,因此通過運用SPSS19.0 對已有數據進行了數據轉換,同時,由于調查者的使用時間與使用頻率不在考察的范圍,因此對問卷中的關于使用時間與使用頻率的數據進行了刪除,將問卷結果轉化為布爾型數據,將結果中的肯定結構標為“1”,否定結果標注為“0”,并對數據中的九個項目進行了從I1 到I9 的編號,即I1=目的性,I2=成員級別,I3=個人專業知識、I4=知識結構、I5=回帖量、I6=表達方式、I7=回帖者態度、I8=信息源、I9=社區參與者的線下關系,部分數據整理結果如表1 所示:
3 基于Apriori 算法的數據分析
在對數據進行基礎分析后,進入數據分析階段。文章運用SPSS clemention12.0 對數據進行Appriori 運算。關聯規則設置中,文章將I1設置為后項,其他八項設為前項,將最小支持度設置為40%,最低置信度為80%,對其他的選項進行設置后開始運行,其運行結果部分如表2 所示。
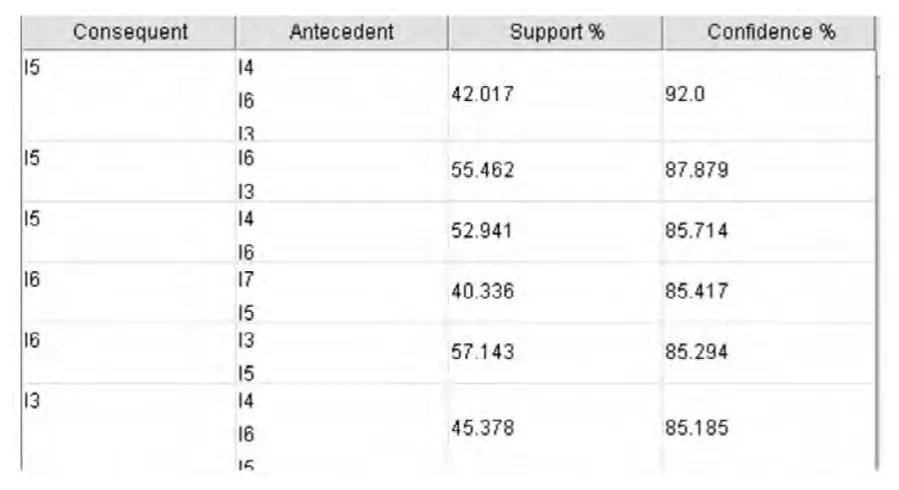
表2 運算結果
對運行結果進行分析,可知,I4、I6、I3 同時出現的頻率為42%,置信度達到了92%,這說明這三個項目在整個運算中非常重要,此規則為強關聯。這表明知識結構、表達方式、個人專業知識同時影響了網絡社區成員知識的形成。I6、I3 同時出現的置信度為87%,這說明這一項目集在整個事務中起著很大的影響,即在網絡社區知識形成中,表達方式、個人專業知識同時影響著社區成員知識形成。I4、I6 同時出現的置信度為85%,這表明在網絡社區知識形成中,社區成員的知識結構與表達方式同時影響著社區成員知識形成的行為。I7、I5 同時出現的置信度為85%,它表明在整個事務中,二者同時出現的行為對整體有很大的影響,即在研究網絡社區知識形成中,回帖者態度與回帖量同時影響著社區成員新知識的形成。I3、I5 同時出現的置信度為85%,即在此研究中,個人專業知識與回帖量同時影響著網絡社區知識形成行為。I4、I6、I5 同時出現的置信度為85%,這表明知識結構、表達方式、回帖量同時對網絡社區知識的形成產生重要的影響。I4、I3、I5 同時出現的置信度為85%,這表明個人專業知識、知識結構與回帖量同時影響著社區成員知識形成行為。I4、I3 同時出現的置信度為84%,這表明在網絡社區知識形成中成員知識結構與個人專業知識同時對其產生了很大的影響。I8、I6 同時出現的置信度為84%,表明信息源與表達方式同時影響著社區成員的知識形成。I6 產生影響的置信度為83%,即在影響網絡社區成員知識形成中知識的表達方式產生了很大的作用。I6、I5 同時出現的置信度為82%,表明表達方式與回帖者態度同時影響了社區知識形成行為,I7、I6 同時出現的置信度為82%,表明回帖者態度與表達方式同時對網絡社區知識形成產生了很大的影響。I8、I3 同時出現的置信度為82%,表明信息源與專業知識同時影響了網絡社區知識的形成。在支持度為42%時I8、I3 同時出現的支持度為82%,再一次表明信息源與專業知識同時對網絡社區知識的形成產生了很大的影響。I4、I5 同時出現的置信度為81%,這表明知識結構與回帖量同時對網絡社區知識形成產生了大的影響。I4、I5 同時出現的支持度為55%,置信度為81%,它說明知識結構與回帖量同時影響著網絡社區知識的形成。I5 出現的置信度為81%,它表明在網絡社區知識形成中回帖量對其產生了大的影響。I9、I5 同時出現的置信度為81%,即在網絡社區知識形成中,線下關系與回帖量同時產生了大的影響。I7、I3 同時出現的置信度為81%,它表明回帖者態度與個人專業同時影響了知識對網絡社區知識的形成。I8、I6 同時出現的置信度為80%,表明信息來源與表達方式同時影響了網絡社區知識形成。
從以上數據分析我們可以發現,在這些統計項中,I5 與I6 出現的次數最多,即回帖量與知識表達方式對網絡社區知識形成產生最重要的影響,因此對于網絡社區回帖量以及發帖中的表達方式規范的管理非常的重要,因為他對網絡社區成員對于知識的篩選與吸收產生了很大的影響。在所有的項集中,I3 出現的頻率也非常的高,即知識分享者的專業對社區成員知識形成具有很大的影響作用。I8、I3 即信息源與專業知識、I4、I5 即知識結構與回帖量同時出現的可能性非常高。
4 結論
通過以上數據分析我們發現,回帖量與知識表達方式對網絡社區知識形成產生非常重要的影響,對于多數網絡社區成員來說,登陸網絡社區僅僅屬于瀏覽狀態,并沒有特別的目的,這也在研究中有所體現,因此對于多數社區成員,回帖量成為選擇閱讀內容的標準。同時對于社區成員來說,內容的表達方式如文字、圖片、視頻等也影響到了其對知識的篩選。有些社區成員偏向于對圖片內容的閱讀與吸收,而有些卻潛意識的選擇視頻圖像形式的知識。由上述數據分析可以得到社區知識的表現方式有極大的影響。而知識分享者的專業知識這一因素成為影響網絡社區知識形成的重要因素在于它體現了其分享的知識的可信程度,影響了社區成員對社區知識的選取與轉化程度。
同時由上述結果可以發現,信息源與專業知識、知識結構與回帖量是項目同時出現頻率最高的兩組,即其中的一個因素出現,另一個因素也隨之出現。信息來源與專業知識的同時出現表明網絡社區成員在對關注信息發布者的個人專業時,同時會關注轉載來的信息的來源,也就是說當網絡社區成員關注他人的知識的專業性時在選擇其他知識時也會關注其知識來源,這在一定程度上表明了社區成員對信息可信度的考量。社區成員個人的知識結構與回帖量的同時出現則表明當社區成員由于個人知識結構出現欠缺在進行知識選擇時,回帖數量會成為其考慮因素,因為回帖數量代表了知識的積累量,因此在對網絡社區知識形成影響因素進行分析時二者同時出現的可能性非常大。
需要指出的是,這里的影響因素側重于研究影響社區成員將社區知識轉化為個人知識的因素,即哪些因素影響了網絡社區中成員對已有知識的接收與轉化,因此研究結果會與之前的研究可能存在一定的差別。
[1]廖開際.數據倉庫與數據挖掘[M].北京大學出版社,2008,11.
[2]劉耀南.Apriori 算法的分析及應用[J].佛山科學技術學院學報:自然科學版,2012,30(3).
[3]張仁壽,羅林開,葉凌君.Apriori 算法對高技能人才市場工資價位影響因素的實證分析[J].中國軟科學,2010(1).
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
當代陜西(2021年2期)2021-03-29 07:41:24
幸福(2018年33期)2018-12-05 05:22:42
Coco薇(2017年11期)2018-01-03 20:59:57
媽媽寶寶(2017年3期)2017-02-21 01:22:28
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
中國科技信息(2016年14期)2016-07-31 21:16:32
中國塑料(2016年3期)2016-06-15 20:30:00
