網絡新聞話題演化模式挖掘
2015-12-26 08:00:41趙旭劍張立李波張暉楊春明喻瓊
軟件 2015年6期
趙旭劍+張立+李波+張暉+楊春明+喻瓊+王耀彬


摘要:針對特定主題的新聞話題演化模式挖掘對于話題動態演化研究具有重要的研究意義和應用價值,能幫助人們清晰地梳理話題事件的來龍去脈,直觀地展現話題演化軌跡的邏輯結構。針對該需求,本文提出一種面向特定話題的網絡新聞話題演化模式挖掘方法,擬從挖掘話題演化邏輯的角度出發,針對特定話題(礦難事件)進行話題演化一般規律的深入分析,對話題演變過程進行階段化表示,建立話題演化模式。實驗結果表明,本文構建的特定話題演化模式具有較強的語義表達能力,符合話題邏輯。
關鍵詞:話題演化;演化模式挖掘;話題聚類;Text Rank
中圖分類號:TP391
文獻標識碼:A
DOI: 10.3969/j.issn.1003-6970.2015.06.001
本文著錄格式:趙旭劍,張立,李波,等,網絡新聞話題演化模式挖掘[J].軟件,2015,36(6): 1-6
Mining of the Topic Evolution Pattern of Network News
ZHAO Xu-jian, ZHANG Li, LI Bo, ZHANG Hui, YANG Chun-ming, YU Qiong, WANG Yao-bin
[Abstract] : Patterns mining for topic evolution of topic-specific news is of great significance and value in the researchon topic dynamic evolution. It can help people clearly sort out topics of the whole story and intuitively show the logicalstructure of the topic evolution track. According to the requirement, this paper proposes a pattern mining method fortopic-specific news evolution. Firstly, this method takes the in-depth analysis to the general rules of the topic evolutionfor the specific topic from the logical point ofview of the topic evolution discovery and then studies the topic evolutionstage representation to establish the topic evolution patterns. Experimental results show that the topic-specific evolutionpattern constructed in this paper has strong semantic expression ability, and accords with the topic logic.
[Key words]: Topic evolution; Evolution patterns mining; Topic cluster; Text rank
0 引言
隨著互聯網的發展,網絡資訊已進入人們生活中的方方面面,而網絡新聞更以其獨特的魅力在眾多傳統新聞方式中脫穎而出。網絡新聞相比于其他新聞方式具覆蓋面廣、使用率高、傳播效率高與親和力強等特點,人人可看,人人可說,使得它具有更加深遠的影響力。對于新聞話題的發展,從最早話題剛剛興起時的不成熟,到現在對話題演變研究的不斷挖掘,新聞話題目前已經擁有了一定的演化規律,而國內外的研究者們希望通過各種判別分析方式[1-6]再加上大量的同類話題的數據統計分析,總結推導出一套行之有效的新聞話題演化模式,建立一套新聞話題演化的發展模型。新聞話題的演化模式挖掘對于話題動態演化研究具有重要研究意義和應用價值,能幫助人們清晰地梳理話題事件的來龍去脈,直觀地展現話題演化軌跡的邏輯結構,對于政府進行輿情監控以及企業進行情報挖掘都有著十分重要的作用。
中文新聞話題演化模式挖掘研究工作大多集中于國內,大致分為兩類:基于統計學的模式挖掘[1-3]和基于邏輯分析的模式挖掘[4]。基于統計學的模式挖掘,其優勢是與事實契合度高,所有素材源于新聞報道,得出的結論符合分析內容,對于話題的結論可直接使用,針對各個話題得出其特點與熱點,比如說2009山西古交煤礦瓦斯爆炸事故,分析之后除了單純的煤礦事故,還會突出其瓦斯爆炸的事故特點,有著較強的特色分析能力。但其不足的地方是,太過于依賴新聞素材,有時如果報道太過雜亂,會影響其分析結果,容易出現熱點重復的問題。基于邏輯分析的模式挖掘,其優勢是話題演化形式分析全面,得出結果準確率高,利于分析。但缺點是,分析工作量大,針對比較成熟的話題分析方便,但是對于一個新的專題演化模式的挖掘有著較大難度。
本文結合了兩種新聞話題演化模式挖掘的優點,再引入時間模型,在統計的基礎上得出初步結論,再結合邏輯分析的方式,添加時間特征,通過多話題演化模式的對比,得出相應話題演化模式模型,增加了分析的準確率,提高了分析的效率。
1 話題演化模型
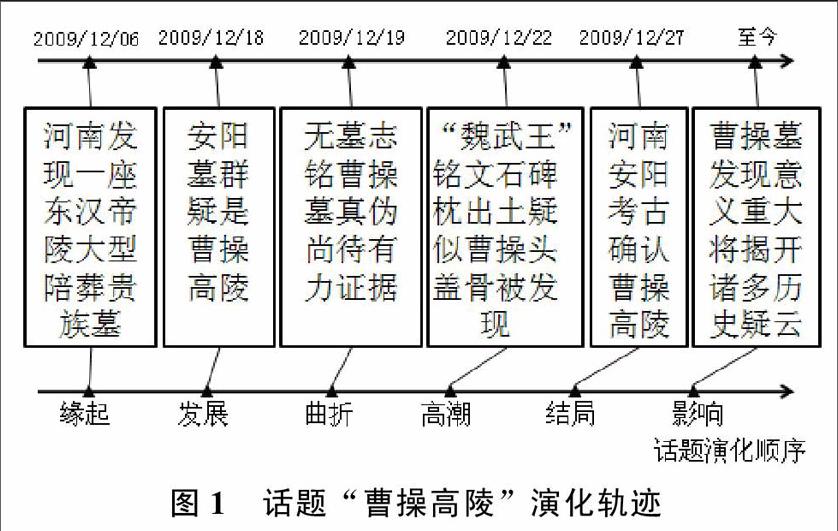
話題演化軌跡可以歸納為不同階段的話題特征所構成的時間序列,是指一個話題產生后,隨著時間的發展,從開始發展到高潮再到衰落,最后直至話題消亡的過程。如圖1所示,一個完整的話題演化過程具有與事件發展的時間順序一致的演化順序,完全符合人類的邏輯思維方式。因此,針對話題演化模式挖掘問題,我們首先要解決話題演化階段表示以及話題特征提取兩個問題。
1.1 新聞話題聚類
我們采用話題聚類的方法生成話題演化軌跡中的各個階段,以類簇中的特征來表示當前階段下話題的內容。對文檔進行聚類時,可以根據需要將新聞話題劃分成相應數量的類簇。話題演化聚類結束后,將目標新聞話題相關的新聞文檔序列組織成一系列類簇,每個類簇代表一個話題演化階段,而整個新聞文檔序列則全面體現了目標新聞話題的演化軌跡。K-means算法是最為經典的基于劃分的聚類方法[7,8],K-means算法的基本思想是:以空間中k個點為中心進行聚類,對最靠近他們的對象歸類。通過迭代的方法,逐次更新各聚類中心的值,直至得到最好的聚類結果[9]。一般都采用均方差作為標準度量函數,如公式1所示。k個聚類具有以下特點:各聚類本身盡可能的緊湊,而各聚類之間盡可能的分開,輸出結果是k個類簇的集合。
它假設對象屬性來白于空間向量,并且目標是使各個群組內部的均方誤差總和最小。假設有k個群組Si,i=1,2,…,k。μt是群組Si內所有元素Xt的重心,或叫中心點。
假設要把樣本集分為S個類別,算法描述如下:
(1)適當選擇S個類的初始中心;
(2)在第七次迭代中,對任意一個樣本,求其到S個中心的距離,將該樣本歸到距離最短的中心所在的類;
(3)利用均值等方法更新該類的中心值;
(4)對于所有的S個聚類中心,如果利用(2)(3)的迭代法更新后,值保持不變,則迭代結束,否則繼續迭代。
該算法的最大優勢在于簡潔快速,算法的關鍵在于初始中心的選擇和距離公式,滿足本文的文本處理要求。
1.2 話題特征提取
多篇新聞報道聚類后,類簇的核心思想(話題)是由文中的詞項來體現。通過詞語間的語義關系分析,找出最能代表該類簇核心內容的特征詞項。為了彌補傳統方法(TF-IDF模型)只計算文中詞語詞頻而沒有考慮詞項之間語義關系的不足,本文通過構建詞項間的Text Rank模型[10],分析多文檔間詞項的語義關系,抽取出有效關鍵詞。
Text Rank與Google提出的Page Rank非常類似,它本質是在以詞匯作為頂點、詞之間關聯作為帶權或無權,有向或無向邊的圖上進行random walk的過程[11]。Text Rank模型表示為一個帶權有向圖G=(V,E),由點集合V和邊集合E組成,E是VxV的子集,圖中兩點i,j之間的權重為Wiio。對于一個給定的點Vi,In( Vi)為指向該點的點集合,Out( Vi)為點Vi指向的點集合。點Vi的分數定義為:
其中,d為阻尼因數,取值范圍為0到1,代表從圖中某一特定點指向其他任一點的概率。在使用TextRank算法計算圖中點的分數時,需要給圖中的點指定任意的初值并遞歸計算知道某個詞語分數收斂,收斂后每個點都獲得一個分數,代表該點在圖中的重要性。需要注意,點的最后分數不受給定初值的影響,點的初值只影響該算法達到收斂的迭代次數。根據基于圖排序算法的基本理論,可以在具有語義關系的詞語之間連線構建Text Rank模型。根據詞語之間的相互“投票”,遞歸計算詞語分數,選擇分數較大的詞語為重要詞語,其中不和任何詞語有連線的詞語為孤立點。例如,“國家養老保險調整”專題新聞文本的詞語序列(如下所示),通過Text Rank模型計算得到詞項間的關聯關系(圖2所示)。
保險養老人員單位制度企業事業基金社會保障社保工作參保職工改革退休個人養老金試點管理農民待遇勞動建立農村發放規定機關參加上海推進問題統籌繳納確保完善實行續保國務院
構建Text Rank模型是根據待選關鍵詞詞語之間的語義相似關系大小來決定是否在兩個詞語之間建立邊。因此,Text Rank圖是帶權無向圖,邊的權重為兩個詞語之間的關聯度,通過詞語間的投票遞歸計算出權重,關鍵詞的選取按分數序列從高到低選擇,選取范圍可以根據需要設置。
2話題演化模式構建
構建話題演化模式,我們需要分為兩步來進行,第一步,構建同類主題不同話題各白的演化模式;第二步,對各個話題演化模式進行分析與總結,構建統一主題的演化模式。首先,我們對剔除噪聲后的關鍵詞提取結果進行分析,看其中是否存在具有代表意義的詞語,例如話題“2009黑龍江鶴崗煤礦爆炸”的聚類結果中存在“醫院…‘治療…‘心理…‘巷道…‘弟弟”這幾個非常獨特的詞語,這幾個詞語在其他聚類結果的關鍵詞提取中不曾出現過,而且在該類簇中的Text Rank值很大,因此,本文定義其為核心詞,用以表達該類簇的核心內容。同時,我們結合前期完成的話題時間抽取工作[12],根據文檔的話題時間對聚類結果進行二次整合,構建針對單一話題事件的演化模式序列。表1給出了話題“2009黑龍江鶴崗煤礦爆炸”的演化模式生成結果。
將同一主題下不同話題(礦難)的各個專題新聞進行演化模式序列的一致性對比分析,在每個演化階段提取具有相同或相似語義信息的關鍵詞作為該階段的“共性詞”,然后將這些詞組成的集合映射到該話題(礦難)相應的演化階段,作為該階段的話題特征,依次處理各個演化階段,進而構建統一主題的演化模式序列。整個處理流程如圖3所示。
3 實驗結果及分析
3.1實驗環境
本文采用利于分析的典型話題作為實驗的原始數據,數據來源于新浪新聞的專題新聞,我們選擇礦難專題作為測試話題。數據集包括21個專題、2175篇新聞報道,由于考慮到有些專題報道時間過長、鏈接失效或是報道相關度較低,本文對數據進行篩選后選用了其中六個篇幅量適中、報道全面的話題(“2009黑龍江鶴崗煤礦爆炸”181篇、“2009山西古交發生煤礦瓦斯爆炸事故”87篇、“2010河南平煤集團平禹四礦礦難”58篇、“2010河南伊川煤礦爆炸”46篇、“2011黑龍江煤礦透水事故”66篇、“2011云南曲靖師宗縣煤礦事故”97篇),其他話題的文檔作為參考與分析,不參與模型構建。
3.2 實驗結果
根據本文的方法,針對六個不同話題事件的礦難專題新聞,我們得到六個話題演化模式挖掘結果,圖4、圖5分別給出了話題“2009山西古交發生煤礦瓦斯爆炸事故”和話題“2010河南伊川煤礦爆炸”的演化模式序列。
生成了話題演化模式序列后,可以看出并不是每一個話題演化模式的都是一樣的,每個礦難話題都有自己的演化特點,但是大致都可以分為事件發生、救援工作展開、家屬反映、遇難人數與救援結果以及責任追究這五個方面,同時結合話題時間特征與話題邏輯順序的分析和理解,我們得到針對礦難話題的基本演化模式:同時,我們以基本演化模式為標準,對六個礦難話題事件的新聞話題演化軌跡進行了實驗評測,采用聚類算法的準確率來評測基本演化模式的性能,如表2所示。從實驗數據不難發現本文算法得到的基本演化模式具有較好的聚類準確率,對于特定話題的演化軌跡具有較好的語義表達能力,符合話題發展的邏輯順序。
4結論
本文針對網絡新聞話題演化研究的實際需求,提出一種面向特定話題的話題演化模式挖掘方法,從挖掘話題演化邏輯的角度出發,針對特定話題(礦難事件)進行話題演化一般規律的深入分析,對話題演變過程進行階段化表示,建立統一的話題演化模式。實驗結果表明,本文構建的特定話題演化模式具有較強的語義表達能力,符合話題邏輯。
參考文獻
[1] 趙華,趙鐵軍,于浩.面向動態演化的話題檢測研究[J].高技術通訊,2006, 16(12): 1230-1235.
[2] Blei D,Lafferty J. Dynamic Topic Models[C]//Proceedings of the International Conference on Machine Learning (ICML), Pittsburgh, PA, USA, 2006, 113-120.
[3] Wang X, McCallum A.Topic over Time:A Non-markov Continuous-time Model of Topical Trends[C]//Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 2006, 424-433.
[4] 趙旭劍,楊春明,李波,等.一種基于特征演變的新聞話題演化挖掘方法[J].計算機學報,2014, 04: 819-832.
[5] 鄭世卓,崔曉燕.基于半監督LDA的文本分類應用研究[J].軟件,2014, 35(1): 46-48.
[6] 曾利,李白力,譚躍進.基于動態LDA的科研文獻主題演化分析[J].軟件,2014, 35(5): 102-109.
[7] 陳磊磊.不同距離測度的K-Means文本聚類研究[J].軟件,2015, 36(1): 56-61.
[8] 徐步云,倪禾.白組織神經網絡和K-means聚類算法的比較分析[J].新型工業化,2014, 4(7): 63-69.
[9] Yu Bao Liu, Jia-Rong Cai, Jian Yin, Ada Wai-Chee Fu. Clustering Text Data Streams[J]. JCST, 2008, 23(1): 112-128.
[10]陳宏,陳偉.基于突發特征分析的事件檢測[J].計算機應用研究,2011, 28(1): 117-120.
[11] Pearson,K.The Problem of the Random Walk[J]. Nature. 1905, 72: 294.
[12]趙旭劍,金培權,岳麗華.TTP: -個面向中文新聞網頁的主題時間解析器[J].小型微型計算機系統,2013, 34(5): 1042-1049.
