一種基于反饋信息的視覺圖像背景建模方法
2016-01-05 05:26:30孫志偉高明亮李海濤倪廣魁
山東理工大學學報(自然科學版) 2015年2期
孫志偉, 高明亮, 李海濤, 倪廣魁
(1.山東理工大學 電氣與電子工程學院, 山東淄博 255049;
2.國網山東省電力公司 萊蕪供電公司, 山東萊蕪 271100)
一種基于反饋信息的視覺圖像背景建模方法
孫志偉1, 高明亮1, 李海濤1, 倪廣魁2
(1.山東理工大學 電氣與電子工程學院, 山東淄博 255049;
2.國網山東省電力公司 萊蕪供電公司, 山東萊蕪 271100)
摘要:高斯混合模型已經廣泛應用于視覺圖像的運動目標提取.但傳統高斯混合模型存在靜止前景融入背景的問題.為了解決這個問題,提出了一種特定場景下基于反饋信息的背景模型更新改進算法.首先采用基于形狀特征的目標分類器將前景目標識別為行人和車輛,然后通過多目標跟蹤判斷目標是否靜止,進而將前景目標識別為靜止行人,運動行人,車輛三種模式,最后將跟蹤與分類的結果與高斯模型的更新相結合,根據分類后反饋的信息對不同的分類區域采取不同的學習率更新.實驗結果表明,該方法能夠有效地解決特定場景中前景融入背景的問題.
關鍵詞:高斯混合模型;靜止前景;多目標跟蹤;目標分類;反饋信息
移動目標異常行為識別是計算機視覺領域中最為活躍的研究方向之一.其核心是從圖像序列中檢測、識別、跟蹤移動目標,提取移動目標的行為特征,根據行為特征對異常行為進行識別和判斷,并對異常行為進行預警.
目標檢測是行為分析的基礎,近年來得到廣泛的研究.Stauffer與Grimson提出的高斯混合模型(GaussianMixtureModel,GMM)[1-2]是目前常用的方法.Wayne[3]等對Stauffer與Grimson的方法進行了詳細的分析.Zivkovic[4]等提出了一種自適應的調整高斯分布個數的方法.Lee[5]將學習率與時間建立聯系,使學習算法具有了自適應性,進一步提高了收斂速度.Bouttefroy[6]等提出了兩種不同的學習因子,改善了“飽和像素”的現象.其它的改進方法還有文獻[7-9].
以上各種改進算法,雖然在檢測效果上有一定的提高,但對于運動前景更新的問題均沒有得到很好解決.當運動的前景出現靜止時,GMM會將其融入到背景當中,這將對移動對象的隱藏判斷出現遺漏.例如一個人出現在停車場,長時間停留,不進入車內,可能會發生異常行為,如盜竊等行為.在這種情況下,該人應該被持續檢測為前景.但GMM會在一定時間后將其融入背景.為了解決靜止前景融入背景的問題,本文首先對行人與車輛進行了區分,進一步將行人區分為靜止與運動兩種狀態,然后通過對高斯模型分區域更新.
1高斯混合模型(GMM)
運動目標的檢測方法主要有時間差分法、光流法、背景減除法等.其中GMM是目前常用的方法[1,5].
GMM是一種基于像素的建模過程.對于圖像中的每一個像素點,設它在1~t時刻的像素值為(X1,…,Xi,…,Xt),并對這些像素值使用K個高斯分布進行描述,則Xt的概率密度函數可表示為
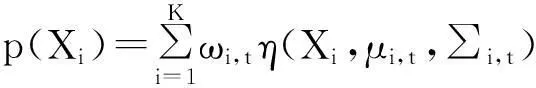
(1)
式中:K=5為高斯分布的個數(通常取值為3~5,);ωi,t為t時刻第i個高斯分布的權值;μi,t與∑i,t分別為t時刻第i個高斯分布的均值向量;協方差矩陣η(Xi, μi,t, ∑i,t)服從均值為μi,t方差∑i,t的高斯分布
η(Xi,μ,∑)=
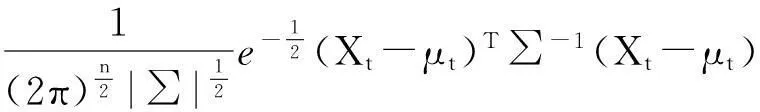
(2)
式中n是Xi的維數,取n=3.為了避免復雜的矩陣求逆運算,通常假定每個像素的各個顏色通道相互獨立,且具有相同的方差,可將協方差矩陣表示為
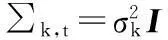
(3)
式中Ι表示3×3的單位矩陣.
初始化過程:利用第一幀圖像各個點的像素值初始化第一個高斯分布的均值,即μ=X,并賦以較大的方差σ2(取σ=30)和權值為1的權重ω,其余高斯模型的均值和權重賦為零,方差賦以較大的值.
對新圖像幀的每個當前彩色向量值Xt,按K個高斯模型ωi,t/σi,t降序進行匹配,若滿足‖Xt-μi,t‖/σi,t<τ,i/[1…K],(其中τ(>0)為匹配閾值,本文τ=2.5),則認為Xt與第i個高斯模型匹配,反之不匹配.匹配時背景模型的權重按式(4)進行更新:
ωi,t=(1-a)ωi,t-1+α
(4)
對于匹配上的高斯分布,按公式更新如式(5).
μi,t=(1-β)μi,t-1+βXt
(5)
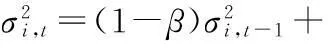
β(Xt-μi,t)T(Xt-μi,t)
(6)
β=αη(Xt|μi,t,σi,t)
(7)
式中α為學習率,該值越大,前景融入背景速度越快,文中取α=0.005.
不匹配時背景模型的權重按式(8)進行更新:
ωi,t=(1-α)ωi,t-1
(8)
同時,對ωi,t/σi,t值最小的高斯分布進行替換,新加入的高斯分布初始化為較小的權值和較大的方差,均值為當前像素值.
每一個像素點參數更新完畢后,對權值進行歸一化處理:
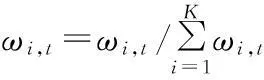
(9)
ωi,t值較大,則該高斯分布出現的概率較高,而σi,t值較小,像素值的波動較小,所以ωi,t/σi,t值越大代表該模型為背景的概率越大.對歸一化后的K個分布按照ωi,t/σi,t比值由大到小重新排序,取前N個高斯分布作為背景模型,其余高斯分布為運動前景模型.
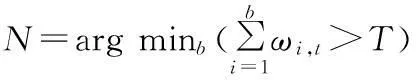
(10)
式中T為閾值,取T=0.8.
為提高模型的收斂速率,采用LEE提出的更新參數模型[5],并引入一個新的模型參數ci,t,初始化時令ci,t=0.對每一個匹配上的高斯分布:
ci,t=ci,t-1+1
(11)
均值和方差的更新率β:
β=(1-α)/ci,t+α
(12)
2基于反饋信息的背景建模
2.1算法原理
本文提出了一種基于反饋信息的背景更新算法.從后續處理來看,運動行人區域,車輛區域和背景區域所采取的更新策略相同,將它們統稱為其它區域.而對于靜止行人區域,將此區域學習率置零,從而控制此區域的前景融入.算法原理如圖1所示.
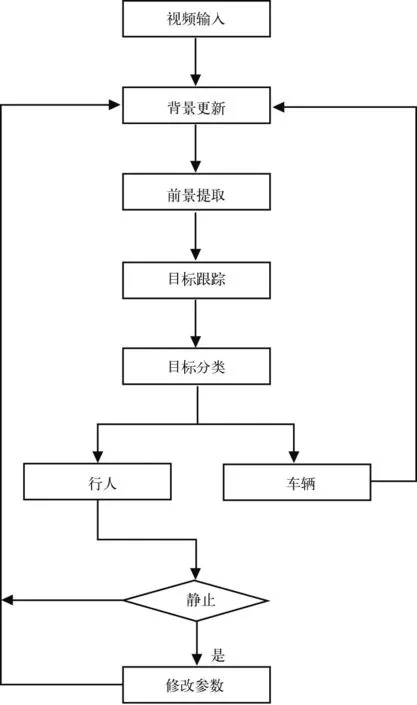
圖1 算法流程
對于背景模型初始化后的每一幀,首先進行前景提取,對于達到輪廓閾值的真實前景目標進行跟蹤.跟蹤過程中,先對目標進行分類,對于車輛,直接按原始模型與背景一起更新.對于行人,運用同一目標中心點之間的距離判斷目標是否靜止.對于非靜止目標區域,按照原始設定參數更新高斯模型;對于靜止目標,采用零學習率更新以此控制其融入前景.針對不同類型類目標,采用不同的更新率,從而防止需要持續監測的前景目標融入背景.在算法實施的過程中的難點問題主要在于視頻場景中的多目標跟蹤以及運動目標分類.
2.2方法實現
先對檢測出的前景目標進行跟蹤和分類,然后運用反饋信息對高斯模型進行更新.
2.2.1多目標跟蹤
在運動目標跟蹤的過程中,先建立目標模板,然后采用運動目標的位置信息與顏色信息作為特征,對運動目標進行連續的識別.
新目標判斷.如果一個運動目標完全進入場景后,被檢測出來的相應區域沒有任何目標模板與之相對應,即可判定該區域可能有新的運動目標,為該新進目標建立相應的臨時模板信息并進行跟蹤.當該目標被連續跟蹤的幀數達到給定的閾值(本文設定為15幀),可以判斷該目標為場景中的真實目標,否則就認為該目標為虛假的目標,應該放棄對該目標的繼續跟蹤,并清空該目標相應的模板信息.
目標丟失判斷.如果某個運動目標模板沒有與任何檢測到的運動區域相匹配,可以認為該目標被遮擋了或者是由于場景的復雜性導致該目標沒有被檢測到,此時認為該目標可能丟失,暫時停止跟蹤.當該目標被連續判定為丟失的幀數達到給定的閾值(本文設定為15幀),就確定該目標丟失.
目標離開判斷.考慮兩種目標離開場景的情況:一是目標走出了監控的范圍.如果運動目標的矩形框接觸到監控范圍的邊界線,就放棄對目標的跟蹤;二是運動目標還沒走出監控的范圍,而是被長時間的被判定為丟失的情況.一旦目標被判定為離開,就清空該目標相應的模板信息.
考慮到實際監控場景中運動目標在相鄰兩幀之間的距離較小,Polana等人[10]采用矩形框的質心作為跟蹤特征.設Po,i(xi,yi)是第i個目標模板的中心坐標,Pd,j(xj,yj)是第j個檢測到的區域的中心坐標,計算兩個坐標之間的歐式距離d:
(13)
如果d小于閾值dTh,取dTh=3,則初步判定第i個目標與第j個區域可能是同一個目標.
在得到初步判定結果之后,計算相應目標模板區域與檢測區域顏色直方圖.采用具有視覺一致性的HSV顏色空間,先提取H分量和S分量,并將H分量分為32個小空間,S分量分為8個小空間,然后統計目標圖像中像素點落在各個小空間中的數量,得到各自的顏色直方圖hist,最后對顏色直方圖hist進行歸一化,使得:
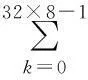
(14)
(15)
其中hist1、hist2分別為目標模板區域與檢測區域顏色直方圖,B為兩個直方圖的巴氏距離(Bhattacharyya Distance).B越小,說明兩個顏色直方圖的相似程度越大;反之,兩個顏色直方圖的相似程度越小.當B<0.4時,在跟蹤的基礎上確定兩個目標為同一目標.
2.2.2模型分類更新
針對本文研究的存在行人和車輛的場景,分類器設計如圖2所示.
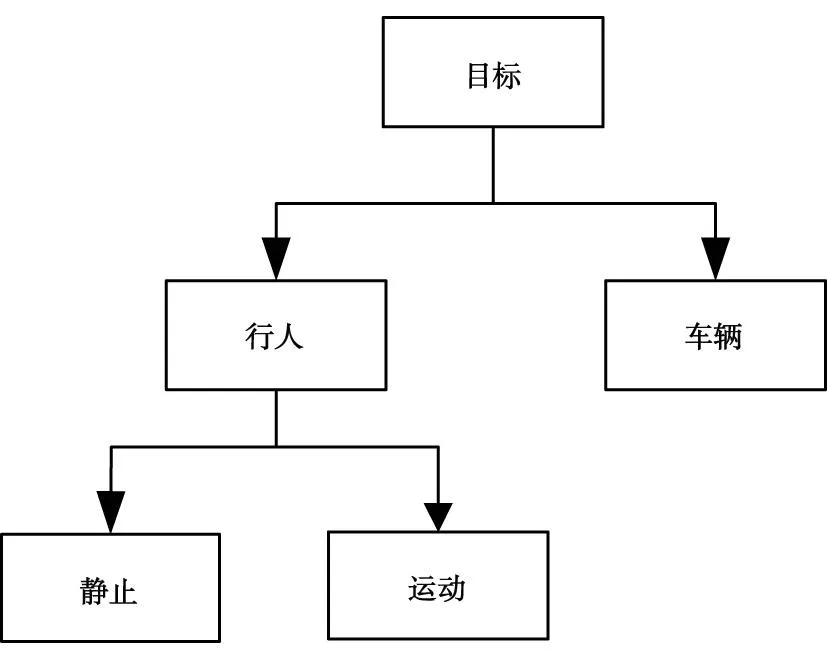
圖2 分類器設計
第一層分類器將檢測出的前景目標分為行人和車輛兩大類;第二層分類器將第一層分類器識別出的行人進一步分為靜止行人,運動行人兩類.
對于第一層分類器,提取出前景目標后,采用Collins[11]與Toth[12]提出的方法,計算離散度Dispersion、目標輪廓擬合矩形長寬比AspectRatio和輪廓面積ConArea作為分類判斷因子,判斷出行人與車輛.
(16)
AspectRation=RHeight/RWidth
(17)
其中,CLength為輪廓的周長,RHeight與RWidth分別為目標輪廓擬合矩形的高、寬.第一層分類效果圖3所示,其中黃色框標記出的目標代表運動車輛,紅色框記出的目標代表行人.

圖3 人車分類
對于第二層分類器,前景檢測提取出目標后,引入參數靜止幀數sCount并初始化為零.首先對每一個真實目標兩幀之間的距離進行判斷,如果兩幀之間的距離閾值d小于靜止距離閾值sTh,(本文取sTh=3),則認為該目標可能靜止,sCount加1;如果連續靜止幀數sCount>15,則認為該目標靜止.第二層分類效果如圖4所示.

圖4 靜止目標分類
從圖4可以看出,該方法對行人的運動和靜止狀態進行了判斷,能夠識別出了行人從靜止轉為運動的狀態,并成功對現有目標的消失、新目標的出現情況做出了正確處理.
3結果分析
實驗硬件平臺為CPU3.2GHz、內存4G的臺式電腦,軟件平臺為VS2008,用C++編程,測試視頻序列大小為352×288.為將文中算法與傳統算法[1]的檢測結果作比較,參數設置如本文所述.視頻序列第646幀,664幀,670幀如圖5所示.

圖5 實驗結果對比
圖5第646幀為目標從運動到靜止的第一幀,靜止目標在第670幀從傳統方法中完全消失.由實驗結果可以看出,靜止目標在傳統方法中逐漸從前景中消失,這樣會對后續的分析產生不利影響.而本文根據特定場景,判斷出不應該從前景消失的目標,成功的防止了特定靜止前景目標的錯誤融入,為后續分析提供了基礎.
4結束語
針對存在行人和車輛的場景,提出了一種檢測與跟蹤、分類的反饋信息相結合的模型參數更新方法.實驗結果表明,該方法能夠有效地防止運動前景融入背景的問題,為后續行為分析工作的開展,如檢測運動目標突然靜止,徘徊等移動物體的異常行為分析和識別奠定了基礎.
參考文獻:
[1] Stauffer C, Grimson W E L. Adaptive background mixture models for real-time tracking [C] //Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Fort Collins: IEEE, 1999: 246-252.
[2] Stauffer C, Grimson W E L. Learning patterns of activity using real time tracking [J]. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 2000, 22(8): 747-757.
[3] Power P W, Schoonees J A. Understanding background mixture models for foreground segmentation [C]// Proceedings Image and Vision Computing, Auckland: University of Auckland, 2002: 267-271.
[4] Zivkovic Z. Improved adaptive gaussian mixture model for background subtraction [C] //Proceedings of the 17th International Conference on Pattern Recognition. Cambridge: IEEE, 2004, 2: 28-31.
[5] Lee D. Effective gaussian mixture learning for video background subtraction [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(5): 827-832.
[6] Bouttefroy P L M, Bouzerdoum A,Phung S L,etal. On the analysis of background subtraction techniques using gaussian mixture models [C] //The 35th Int. Conf. Acoustics, Speech, and Signal Processing. Dallas: IEEE, 2010: 4 025-4 045.
[7] Zivkovic Z, Heijden F. Efficient adaptive density estimation per image pixel for the task of background subtraction [J]. Pattern Recognition Letters, 2006, 27(7): 773-780.
[8] Christian W, Michel J J. Integrating a discrete motion model into GMM based background subtraction [C]// International Conference on Pattern Recognition. Istanbul: IEEE, 2010: 9-12.
[9] Lin H H, Chuang J H, Liu T L. Regularized background adaptation: a novel learning rate control scheme for gaussian mixture modeling [J]. IEEE Transactions on Image Processing, 2011, 20(3): 822-836.
[10]Polana R, Nelson R, Nelson A. Low level recognition of human motion [C]// Proc. of IEEE Computer Society Workshop on Motion of Non-Rigid and Articulated Objects. Austin: IEEE, 1994: 77-82.
[11]Lipton A J, Kanade T R. A system for video surveillance and monitoring: VSAM final report [R]. Carnegie Mellon University: Technical Report CMU-RI-TR-00-12, 2000.
[12]Toth D, Aach T. Detection and recognition of moving objects using statistical motion detection and Fourier descriptors [C]// Mantova: ICIAP, 2003: 430-435.
(編輯:劉寶江)
收稿日期:2014-09-11
基金項目:山東省優秀中青年科學家科研獎勵基金(博士基金)(BS2014DX009)
作者簡介:孫志偉,男,zwsun1386@sina.com; 通信作者:高明亮,男,253583414@qq.com
文章編號:1672-6197(2015)02-0061-05
中圖分類號:TP391.9
文獻標志碼:A
AGMMbackgroundmodelingalgorithmbasedonfeedbackinformation
SUNZhi-wei1,GAOMing-Liang1,LIHai-tao1,NIGuang-kui2
(1.SchoolofElectricalandElectronicEngineering,ShandongUniversityofTechnology,Zibo255049,China;
2.LaiwuPowerSupplyCompany,StateGridShandongElectricPowerCompany,Laiwu271100,China)
Abstract:Gaussian Mixture Modelhas been widely used in video object extraction. However, theproblemin traditional GMM is that the still foreground pixel are often blendedin background pixel. To solve this problem, this paper proposed a novel rate control scheme based on feedbackinformation. First, the proposed method divided theobjects into pedestrians andcars. Second, a multiple object tracking algorithm is proposed to determine whether the target was stationary, then the detected objects can be classified to still pedestrians, moving pedestrians and cars. At last, different regionsareadoptedto different learning rate depending on the feedback of the tracking and classification results. Experiments show the improved algorithm can solve the problem of still foreground pixel blendedin background pixel.
Key words:Gaussian Mixture Model; still foreground; multiple object tracking; object classification; information feedback
