基于改進協同過濾算法的圖書網站個性化推薦模型構建研究
2016-03-15 01:26:16李敬明程家興
長春師范大學學報 2016年2期
李敬明,程家興,張 偉,方 賢
(1.安徽新華學院信息工程學院,安徽合肥 230088;2.合肥工業大學管理學院,安徽合肥 230009;
3.安徽大學計算機科學與技術學院,安徽合肥 230031)
?
基于改進協同過濾算法的圖書網站個性化推薦模型構建研究
李敬明1,2,程家興1,3,張偉1,方賢1
(1.安徽新華學院信息工程學院,安徽合肥 230088;2.合肥工業大學管理學院,安徽合肥 230009;
3.安徽大學計算機科學與技術學院,安徽合肥 230031)
[摘要]協同過濾是推薦系統應用最廣泛的方法,其中項目之間的相關性是影響推薦算法質量的關鍵因素之一,針對基本協同過濾算法中未充分利用項目之間的相關系數,且算法的計算量也會隨著用戶和項目的不斷增加呈現出爆炸性的增長,從而導致推薦質量低下等問題,本文提出了一種基于聚類分析的改進協同過濾算法。該算法加入項目相關性計算,利用聚類分析算法提高推薦算法效率,并將其應用于圖書網站個性化推薦模型的構建。仿真實驗表明,這種改進后的算法在收斂速度與算法準確性方面取得了顯著的提高。
[關鍵詞]改進協同過濾;聚類分析;個性化推薦;圖書推薦
1研究背景
近年來,隨著網絡信息資源的不斷豐富和發展,如何精準地向每個用戶推薦他們最感興趣的項目是目前各大網站保持用戶粘性和競爭力的關鍵技術,推薦系統在許多領域都表現出它的巨大應用潛力,尤其在電子商務領域應用更為廣泛,如一些大型的在線閱讀網站與圖書網站都不同程度地使用了各種個性化推薦系統[1]。協同過濾技術[2]是個性化推薦系統中最成功的推薦技術,通過分析歷史數據,將興趣相近的用戶作為目標用戶的鄰居放入鄰居集中,找出鄰居集中用戶感興趣的項目并推薦給當前用戶。目前使用的協同過濾算法是基于用戶-項目評價矩陣的,沒有考慮項目與項目之間的關系對最終推薦結果的影響,并且當用戶-項目矩陣不斷增加時,算法的計算量也在不斷增加,最終導致結算法的計算量大、可擴展性差及推薦結果的可信度低等。為了解決當前協同過濾技術存在的一系列問題,研究者們基于已有的算法提出了多種改進的算法思想并加以應用。根據項目之間的相似性計算提出了基于評分預測的協作過濾方法[3]、利用算法精簡評分矩陣維數而提出的維數簡化算法[4]等。
本文采用了一種基于聚類分析的改進協同過濾算法,使用k-means聚類算法將現有的用戶進行聚類,使同一個聚類中用戶的興趣度最為相似。在預測評分時加入項目之間的相似性,提高預測評分的精確度。并將其應用于優化圖書網站的個性化推薦質量。
2相關工作
協同過濾技術通過分析用戶的歷史數據,生成與目標用戶興趣相似的用戶并組成鄰居集,并將鄰居用戶集中感興趣的項目推薦給當前用戶,即產生top-N推薦集。在傳統基于用戶的協同過濾算法中,輸入當前用戶的待處理數據通常是一個m*n的用戶-項目評價矩陣R=(ratingij)(i∈m,j∈n);m是用戶的數目,n是項目的數目。ratingij表示第i個用戶對第j個項目的評分。在本文構建的模型中,ratingij通常為-1~5中的一個整數,其中-1表示其沒有瀏覽過該書籍,0則表示用戶閱讀了該項目但卻沒有進行評價,1~5數值的大小表示用戶對該書籍的喜愛程度。在其它推薦系統中,比如電子商務的推薦系統中我們也可以使用0~1中的一個整數表述用戶是否購買了某件商品,進而進行數據表述的工作。圖書個性化推薦系統用戶-項評分矩陣如下:

協同過濾技術的關鍵就是通過計算用戶之間的相似性為當前用戶找到一個最近鄰居集(Neighbor),并按照相似性的大小進行排序,根據鄰居用戶提供的信息篩選出當前用戶最可能感興趣的項目并進行推薦。例如:對一個當前用戶u,使用Person相關度或者目前常用的向量空間相似度計算其與用戶集中的任一用戶ua的相似性sim(u,ua),按大小進行排序形成用戶u的最近鄰居集neighbor∈{sim(u,u1),sim(u,u2),…,sim(u,um-1)},并且滿足sim(u,u1)>sim(u,u2)>…>sim(u,um-1)。這里,我們使用Person相關度計算用戶之間的相似性,計算公式如下:

(1)

當產生了當前用戶u的最近鄰居Neighbor之后,將包括用戶u在內的所有用戶評分項目合集減去當前用戶的所有已評分項目,得到當前用戶u的待預測評分項目合集Iu。并且計算用戶u對每一個項目i∈Iu的預測評分,篩選出評分最高的前n項,即產生top-N推薦集推薦給當前用戶,用戶對待預測項目的預測評分計算公式如下:

(2)
3基于改進協同過濾算法的圖書網站個性化推薦模型的構建
3.1基于項目相關性的改進協同過濾算法
目前,基于用戶的協同過濾技術發展已經十分成熟,但其有明顯的缺點,即沒有考慮到項目之間的相關性。比如預測當前用戶對一本歷史類書籍的評分時,可能會將鄰居用戶閱讀的傳記類書籍和偵探類書籍一起考慮進去并進行評分,很明顯,傳記類書籍對最后預測評分的影響要比偵探類書籍的大,但基于用戶的協同過濾技術會將兩者同等地考慮進去,降低了最終的推薦質量。
本文采用了一種基于項目屬性計算項目之間相關性rel(i,ip)的改進協同過濾算法,并由此計算受不同項目之間相關性所影響的最終預測評分。通常使用Person相關度來計算項目之間的相關性,但此方法不具有客觀性,容易受用戶的主觀影響。不能客觀反映項目之間的相關性,導致最終的推薦質量不精準。因此,本文使用了基于項目屬性矩陣的項目相關性計算。存在一個項目屬性矩陣Attr={attrij},其中attrij表示第i個項目是否具有第j個屬性,且其值為0或1中的任一整數,0表示該項目不具有該屬性,1表示具有。Attr項目屬性矩陣如下:

基于項目屬性計算項目相似性計算公式如下:
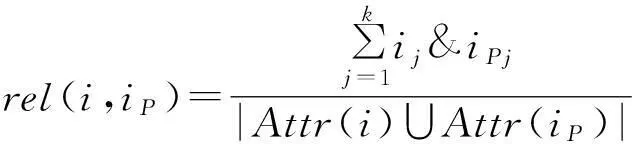
(3)


(4)
當引入項目相關性之后,用戶相似性計算就改進為以下公式:

(5)
其中,sim(ua,ub)iP表示的是用戶a和用戶b基于待預測項目iP的相似性。最后,將(5)式代入(2)式中得到以下新的預測評分公式,并選出最近鄰居集和產生top-N推薦。

(6)
3.2基于聚類分析的K-means算法優化協同過濾技術
協同過濾算法擴展性較差,每次進行個性化推薦時都要計算當前用戶與數據庫中每一個用戶的相似性,之后才能得到最近鄰居集并產生top-N推薦。當用戶-項矩陣過大時,計算量就會變得十分巨大,也會造成最終的推薦質量低下,不能達到預期額推薦期望。因此,可以使用聚類分析對協同過濾技術進行優化,提高個性化推薦質量。
聚類分析[5-6]是模式識別和數據壓縮領域的一個重要問題,是非監督學習的重要方法,我們可以事先對數據庫提供的用戶信息使用聚類分析算法進行聚類,使得在同一聚類中的用戶行為興趣的相似性較大,處于不同聚類的任兩個用戶的相似性即興趣相似度較小。當有用戶需要進行個性化推薦時,直接計算出該用戶屬于哪一個聚類。并在該聚類中產生最近鄰居集Neighbor,進而產生top-N推薦。這樣便極大地簡化了推薦過程。當有過大的用戶-項矩陣時,不會有過多的計算量,并且優化了推薦質量。
K-means是基于劃分的聚類算法[7-8],該算法簡單且易于使用,運行速度快,與其它聚類算法相比應用更加廣泛。設k是算法在數據集上輸出的聚類數量,數據集是n個圖書網站用戶構成集合{I1,I2,…,In},并隨機在數據集中找出k個用戶作為初始聚類中心,分別計算剩下的每個用戶與每個初始聚類中心的距離,并將此用戶其分配給距其距離最近的聚類中心所在的聚類,然后更新每個聚類的聚類中心,直到準則函數收斂[9]。
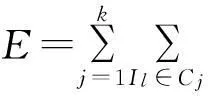
(7)
其中,gj是聚類Cj的聚類中心,且l∈{1,2,…,n},j∈{1,2,…,k},下面對k-means算法的實現過程簡要概述:
第一步,輸入:包含n個對象的項目集以及所需的聚類個數k;
第二步,初始化k個聚類中心{g1,g2,…,gk},其中gj∈In,j∈{1,2,…,k},In是所有用戶的集合;
第三步,使每一個聚類Cj與聚類中心gj相對應,In=In-{g1,g2,…,gk};
第四步,從In第一個元素I1開始計算與各個距誒中心的相似度,并將其放入最相似的聚類中心gj所屬聚類Cj中,并在In集合中除去該對象,直到集合In為空;

第六步,輸出k個聚類。
3.3基于改進協同過濾算法的圖書網站個性化推薦模型
對基本協同過濾算法中的項目相關性以及利用聚類算法降低計算復雜度等兩方面進行了上述改進,并將其應用于圖書網站個性化推薦建模中。具體步驟如下:
第一步,導入網站數據中的圖書屬性表和用戶評價表。根據圖書屬性表中的數據使用式(3)和式(4)聯合計算圖書之間的相關性;
第二步,根據3.2給出的步驟對網站用戶進行聚類,使處于相同聚類的用戶最相似;
第三步,根據用戶評價表使用式(5)計算用戶之間的相似性,并將前一百的用戶作為目標用戶的最近鄰居集,并通過最近鄰居集找出目標用戶的待預測評分書籍集合;
第四步,使用式(6)計算預測評分,并將評分前十的書籍作為推薦項目(top-N)推薦給用戶。
4實驗及結果分析
4.1實驗數據集及評價標準
常用的評價推薦系統推薦質量的度量主要包括統計精度度量方法和決策支持精度度量方法兩類[10-11],根據本文的實驗情況,這里我們使用平均絕對方差MAE方法。該方法通過計算當前用戶待預測項目的預測評分和實際評分的偏差作為度量來檢查推薦系統推薦結果的精確性。MAE值越低,推薦系統的推薦質量越低。
設當前用戶的預測評分集合為{iP1,iP2,…,iPn},用戶實際的評分集合為{i1,i2,…,in},則MAE值得計算如下:

(8)
以上基于聚類分析優化的協同過濾技術有效地避免了傳統協同過濾技術中出現的各種問題,我們選擇某圖書閱讀網站提供的數據,根據數據集中提供的描述文件采用18277條評價數據。共有2622名用戶參與了評價6609本書籍的評價,實驗采用了Matlab軟件處理實驗數據。
我們將所有數據集中的圖書分為15個屬性分類:懸疑、名著、影視、經管、社科、生活、武俠、歷史、傳記、人物、恐怖、推理、言情、幻想、學術,共有屬性極大個數設為5,如表1所示。
產生一個m*n輸入矩陣,該矩陣是用戶-圖書評價矩陣,矩陣中每個值都是-1~5中的一個整數,值的高低代表了用戶對該評價書籍的喜愛程度。0表示用戶閱讀了該書籍卻沒有進行有效的評價,-1表示用戶沒有閱讀該書籍,部分數據如表2 所示。
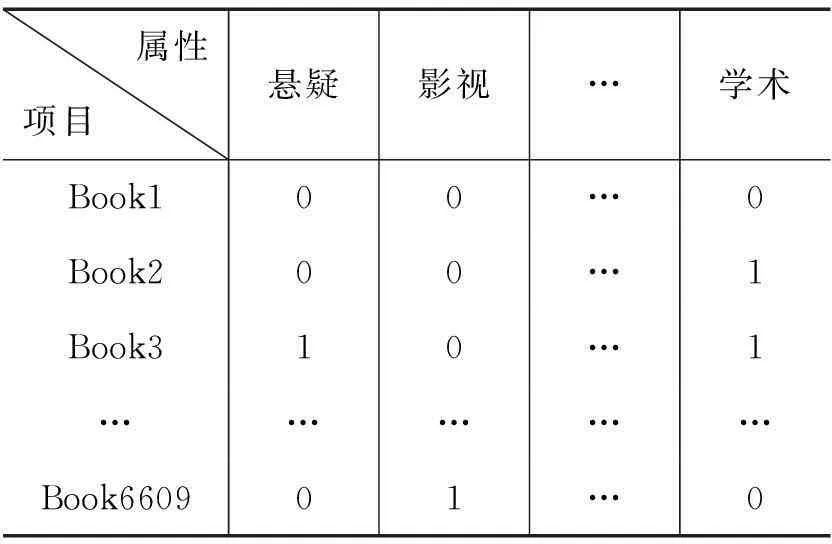
表1 圖書屬性表

表2 用戶-評價表
當目標用戶進入時,服務器提取其歷史瀏覽日志,計算它與各個聚類中心的相似度,并將其分入最相似的一個聚類中。之后用(5)式計算目標用戶與當前聚類中每一個對象基于未評分圖書項目的相似度,并按照大小順序進行排列,產生當前用戶的最近鄰居集。找出最近鄰居集中所有鄰居已評分圖書的合集,除去其中當前用戶已評分的圖書項目,得到待預測評分的圖書候選集。使用(6)式計算當前用戶對所有未評分圖書的預測評分并按大小進行排列,選出前6項評分最高的圖書推薦給當前用戶,即產生top-N推薦集。
4.2實驗數據集及評價標準
將實驗得到的MAE值結果繪制成表格數據如表3所示,并與使用其它沒有進行優化的協同過濾算法得到的結果進行比較。

表3 MAE值分析表
使用Matlab繪圖結果如圖1和圖2所示。

圖1 MAE值分析表

圖2 收斂時間分析表
未采用聚類優化的協同過濾算法效率不高,收斂速度較慢,且當數據量過大時,推薦結果質量比較差,從MAE值分析表(圖1)中可以看出,采用聚類之后的算法得到的結果相比而言質量較高,能準確地推薦給用戶所希望看到的書籍。從收斂時間分析表(圖2)中可以看出,采用了聚類的算法收斂速度較快,實際操作中更能滿足企業用戶和閱讀用戶的需求。因此,給予項目相關性改進后的協同過濾算法得到的結果更加良好,值得進一步進行推廣。
5結語
基本的協同過濾算法是從用戶相似鄰居的角度,分析用戶興趣并自動進行推薦。此算法在信息量適度的情況下具有良好的效率,在進行網站數據分析時數據量通常十分龐大,使用基本算法時每次推薦都必須要在計算用戶與其它所有用戶的相似性之后再進行推薦,效率較低。使用聚類算法使得每次推薦的搜索范圍和計算量都大大降低,并且由于加入了項目之間的相似性計算,其推薦質量相對于基本的協同過濾算法得到了很大的提升。
[參考文獻]
[1]Sivapalan S,Sadeghian A,Rahnama H,et al.Recommender systems in e-commerce[C].World Automation Congress, IEEE,2014:179-184.
[2]張騰季.個性化混合推薦算法的研究[D].杭州:浙江大學,2013.
[3]Sarwar B,Karypis G,Konstan J,et al.Item-based collab—orative filtering recommendation algorithms[C]. Proceeding of the 10th international World Wide Web Conference,New York,ACM Press,2010:285-295.
[4]鄧愛林,朱揚勇,施伯樂.基于項目評分預測的協同過濾推薦算法[J].軟件學報,2003,14(9):1621-1628.
[5]Jiawei Han,Micheline Kamber.數據挖掘概念與技術[M].北京:機械工業出版社,2005:185-218.
[6]于文倩.聚類相關知識簡介[J].電子世界,2014(11):190.
[7]崔丹丹.K-Means聚類算法的研究與改進[D].合肥:安徽大學,2012.
[8]沈艷,余冬華,王昊雷.粒子群K-means聚類算法的改進[J].計算機工程與應用,2014(21):125-128.
[9]張雪鳳,張桂珍,劉鵬.基于聚類準則函數的改進K-means算法[J].計算機工程與應用,2011,47(11):123-127.
[10]吳發青,賀樑,夏薇薇,等.一種基于用戶興趣局部相似性的推薦算法[J].計算機應用,2008,28(8):1981-1985.
[11]梁天一,梁永全,樊健聰,等.基于用戶興趣模型的協同過濾推薦算法[J].計算機應用與軟件,2014(11):261-263.
[12]皮佳明.基于用戶興趣變化的協同過濾推薦算法研究[D].昆明:云南財經大學,2014.
The Research on Construction of Library Website Personalized Recommendation Model Based on Improved Collaborative Filtering Algorithm
LI Jing-ming1,2,CHENG Jia-xing1,3, ZHANG Wei1,FANG Xian1
(1.School of Information Engineering, Anhui Xinhua University, Hefei Anhui 230088, China;2.School of Management, Hefei University of Technology, Hefei Anhui 230009, China;3.School of Business, Anhui Finance and Economics University, Hefei Anhui 230031, China)
Abstract:Recommend system based on collaborative filtering algorithm has been widely used at present. Correlation between the two projects has not been considered in the basic collaborative filtering algorithm. There is a explosive growth of the compute when the users’ and the projects’ volume has been huge, which it reduces the quality of recommendation. An improvement collaborative algorithm based on clustering analysis is proposed in this paper. The project correlation calculation is added to collaborative filtering algorithm, which it is applied to build personal book recommend model. The experiments show that the improved algorithm can achieve good recommending quality.
Key words:improved collaborative filtering; clustering analysis; personalized recommendation; book recommendation
[作者簡介]李敬明(1979- ),男,講師,博士研究生,從事智能計算與數據挖掘研究。
[基金項目]國家自然科學基金項目“面向交易和服務過程的民營中小型銀行經營模式及相關政策研究”(71403001);安徽省教育廳人文社會科學研究重點項目“體制外金融與安徽小微企業對接服務機制和風險防范研究”(SK2013A011)。
[收稿日期]2015-12-12
[中圖分類號]TP319.3
[文獻標識碼]A
[文章編號]2095-7602(2016)02-0040-06
