民間藝術(shù)資源的云存儲技術(shù)研究
2016-05-03 02:46:06李小波田中娟葉振
智能計算機(jī)與應(yīng)用 2016年2期
關(guān)鍵詞:云計算
李小波 田中娟 葉振
摘要: 我國民間藝術(shù)資源平臺的建設(shè)和研究是當(dāng)前文化藝術(shù)領(lǐng)域面臨的一項(xiàng)重要而緊迫的課題,存在著諸多挑戰(zhàn)。在大數(shù)據(jù)時代背景下,采用云計算和云存儲技術(shù)是一個必然的趨勢。文中介紹了Hadoop云計算與云存儲技術(shù),提出了基于Hadoop的民間藝術(shù)資源云存儲平臺建設(shè)方案。構(gòu)建基于Hadoop的民間藝術(shù)資源云存儲平臺具有可行性和有效性。
關(guān)鍵詞:民間藝術(shù);云計算;云存儲;Hadoop
中圖法分類號:TP311.13 文獻(xiàn)標(biāo)志碼:A 文章編號:2095-2163(2016)02-
Research on cloud storage technology of folk art resources
Xiaobo Li 1, Zhongjuan Tian 2, Zhen Ye 1
(1 College of Engineering and Design, Lishui University, Lishui 323000, China;
2 College for Nationalities (Minzu), Lishui University, Lishui 323000, China)
Abstract: The construction and research of Chinese folk art resources platform is an important and urgent task in the culture and art field, and there are many challenges. In the big data era, the use of cloud computing and cloud storage technology is an inevitable trend. This paper introduces the Hadoop cloud computing and cloud storage technology, puts forward the development scheme of folk art resources cloud storage platform based on Hadoop. The construction of folk art resources cloud storage platform based on Hadoop is feasible and effective.
Key words: folk art; cloud computing; cloud storage; Hadoop
我國民間藝術(shù)源遠(yuǎn)流長,多彩多姿,內(nèi)涵豐富,深刻地影響和滋養(yǎng)著我們的民族精神與民族性格。在全球經(jīng)濟(jì)一體化,我國社會快速發(fā)展的當(dāng)下,隨著強(qiáng)勢文化的沖擊融合,許多優(yōu)秀的民間藝術(shù)和民族文化正在逐漸走向流失消亡。對于民間藝術(shù)的保護(hù),以往在思路及方法上都比較單一。如創(chuàng)建一個博物館,將民間的藝術(shù)品進(jìn)行精彩集中展現(xiàn),但這種方式對于許多民間藝術(shù)的保護(hù)卻不具現(xiàn)實(shí)可行性;而且,在各地大量興建博物館,也將帶來資金和展示空間不足等諸多問題。隨著計算機(jī)和網(wǎng)絡(luò)等現(xiàn)代信息技術(shù)的飛速發(fā)展,采用新興的數(shù)字化信息技術(shù)對民間藝術(shù)資源進(jìn)行傳承和保護(hù),不僅是現(xiàn)階段文化繁榮和發(fā)展提出的時代課題要求,而且也為我國珍貴民間藝術(shù)的傳統(tǒng)接續(xù)和創(chuàng)意加入提供了可行思路,同時更為信息技術(shù)的應(yīng)用拓展了廣闊的前景實(shí)施空間[1-2]。《中華人民共和國非物質(zhì)文化遺產(chǎn)法》自2011年6月1日開始實(shí)施,其中的第十三條就提出了明確的規(guī)定:“文化主管部門應(yīng)當(dāng)全面了解非物質(zhì)文化遺產(chǎn)有關(guān)情況,建立非物質(zhì)文化遺產(chǎn)檔案及相關(guān)數(shù)據(jù)庫。除依法應(yīng)當(dāng)保密的外,非物質(zhì)文化遺產(chǎn)檔案及相關(guān)數(shù)據(jù)信息應(yīng)當(dāng)公開,便于公眾查閱。”[3]
1 民間藝術(shù)資源保護(hù)面臨的挑戰(zhàn)
國內(nèi)宣傳、文聯(lián)、文化等部門意識到民間藝術(shù)資源保護(hù)的必要性和迫切性,著手積極探索和實(shí)踐民間藝術(shù)資源的保護(hù)和傳承工作。時至今日,我國民間藝術(shù)資源的數(shù)字化傳承和保護(hù)工作尚未全面展開,仍然屬于起步階段,各項(xiàng)工作有待進(jìn)一步深入,其數(shù)據(jù)資源平臺的建設(shè)和研究將是一項(xiàng)長期而艱巨的工作。
各地民間藝術(shù)種類繁多,地域特點(diǎn)突出,相關(guān)數(shù)據(jù)資源的保護(hù)面臨著諸多挑戰(zhàn),分析論述如下:
(1)民間藝術(shù)資源數(shù)據(jù)持續(xù)增長。隨著民間藝術(shù)資源的保護(hù)和傳承工作的不斷深入開展,大量的數(shù)據(jù)接入互聯(lián)網(wǎng),由此帶來了數(shù)據(jù)量的迅猛增長。數(shù)據(jù)量由之前的MB,GB級別,躍升到現(xiàn)在的TB,甚至是PB級別。
(2)數(shù)據(jù)資源來自不同的數(shù)據(jù)源。民間藝術(shù)資源種類眾多,且獲取的數(shù)據(jù)源各不相同。由于其數(shù)據(jù)結(jié)構(gòu)不同,既包括結(jié)構(gòu)化的數(shù)據(jù),也含有半結(jié)構(gòu)化和非結(jié)構(gòu)化的數(shù)據(jù)。因而需要利用合適的方法對獲取的數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理,將其轉(zhuǎn)化為統(tǒng)一的格式,并采用科學(xué)模式實(shí)現(xiàn)數(shù)據(jù)的存儲和管理。熱后進(jìn)行數(shù)據(jù)的處理分析,再利用可視化等技術(shù)手段給用戶提供效果展示。這就需要一整套的大數(shù)據(jù)處理流程[4]。
(3)民間藝術(shù)資源數(shù)據(jù)缺乏共享。目前國內(nèi)相關(guān)部門的民間藝術(shù)資源庫往往是獨(dú)立設(shè)計、并研發(fā)完成的,因而其資源是分散且孤立的,相互之間沒有進(jìn)行有機(jī)的整合。各資源庫之間的信息互不兼容,不僅造成資源庫的重復(fù)建設(shè),也會由于缺乏共享而導(dǎo)致資源的浪費(fèi)[5]。
(4)存儲成本高。構(gòu)建民間藝術(shù)資源的數(shù)據(jù)中心需要大量的資金投入,在傳統(tǒng)的存儲管理模式下,相關(guān)部門要購置各自的服務(wù)器,配備相應(yīng)的場所和技術(shù)人員,而時下的許多單位并不具備相應(yīng)的資金和技術(shù)能力。而且當(dāng)前的服務(wù)器無法滿足更高需求時,就要決策購進(jìn)新式服務(wù)器[5]。
2 Hadoop云計算與云存儲技術(shù)
云計算是近期網(wǎng)絡(luò)技術(shù)、特別是互聯(lián)網(wǎng)蓬勃興起后出現(xiàn)的熱門研發(fā)領(lǐng)域之一,是當(dāng)前信息行業(yè)發(fā)展的最新潮流趨勢。云計算通過分布式技術(shù)將大量的計算資源通過高速網(wǎng)絡(luò)進(jìn)行連接,并通過虛擬化技術(shù)構(gòu)成一個虛擬的計算資源共享池,云系統(tǒng)管理者在后臺對該資源共享池施行統(tǒng)一的配置、管理和監(jiān)控,而當(dāng)前臺的用戶需要使用計算資源時,就可以通過互聯(lián)網(wǎng)隨時隨地接入,并且是以按需付費(fèi)的模式交付用戶使用。自2006年,云計算概念提出以后,眾多廠商陸續(xù)趁勢推出了各自的云計算架構(gòu)和系統(tǒng),推動著云計算從簡單的概念迅速邁入成熟的實(shí)施階段。
在此基礎(chǔ)上,云存儲延伸了云計算的概念,現(xiàn)已成為一種新型的數(shù)據(jù)存儲模式。云計算平臺是一種以海量數(shù)據(jù)為計算核心的分布式系統(tǒng),如果在該平臺之上配置大量的存儲設(shè)備,使得該平臺擁有了海量的數(shù)據(jù)存儲能力,即可將其作為云存儲平臺來進(jìn)行設(shè)定使用[6]。
Hadoop 是一個直接針對云計算和云存儲而提出的開源模型[7],可以在普通的硬件設(shè)備組成的集群上進(jìn)行部署和運(yùn)行,是目前實(shí)現(xiàn)云計算和云存儲的主要平臺之一。該平臺已經(jīng)由包括Microsoft, Amazon,IBM和Google等在內(nèi)的多家知名IT公司所采選和使用。其中,HDFS、MapReduce和HBase是Hadoop平臺的三大核心技術(shù)。在此,對這3項(xiàng)核心技術(shù)給出如下分析與概述。
2.1 HDFS
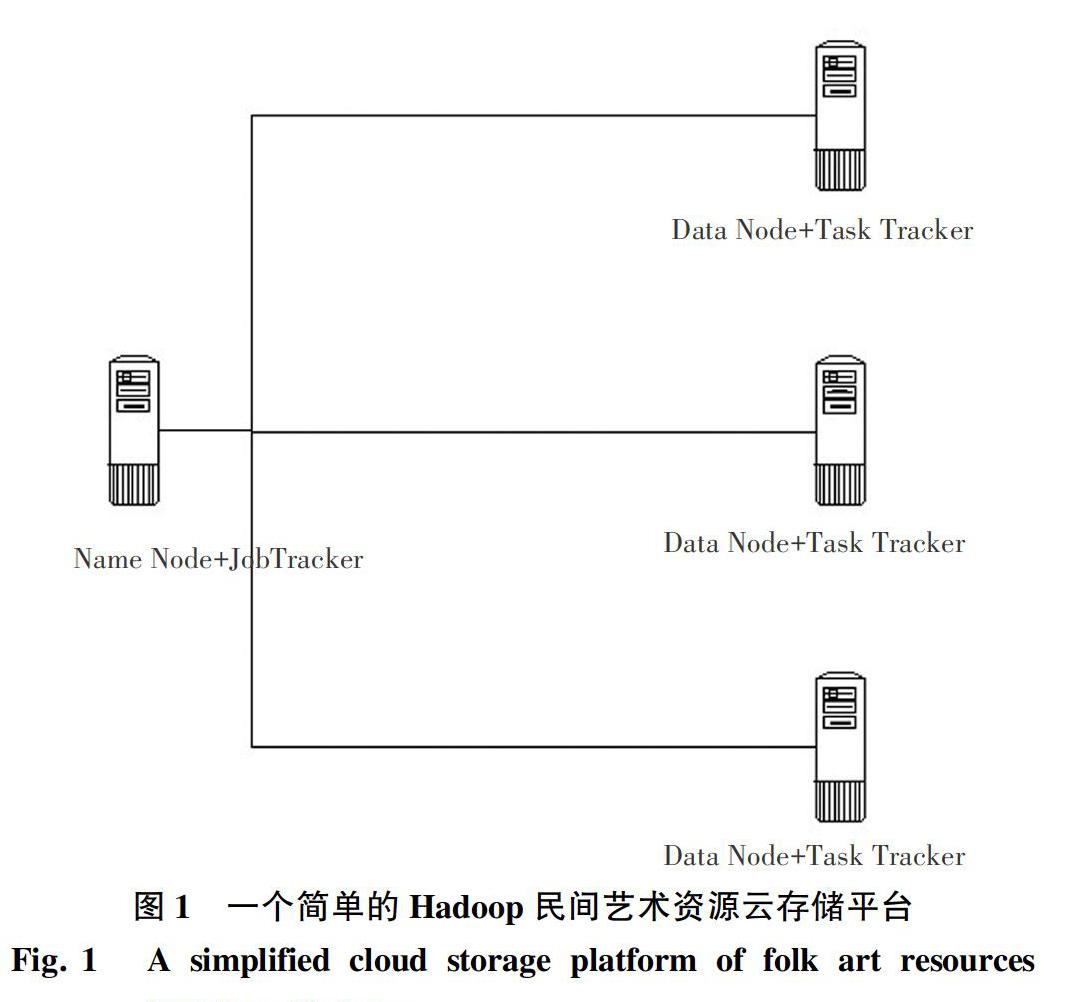
HDFS(Hadoop distributed file system)是一個采用主從結(jié)構(gòu)體系框架的分布式文件系統(tǒng)[8]。和現(xiàn)有的分布式文件系統(tǒng)不同的是,HDFS更注重容錯性和鏈接廉價硬件設(shè)備的兼容性,能完全運(yùn)行在性能普通的電腦集群上,采用上述設(shè)計的目的即是希望基于很小的預(yù)算或者現(xiàn)有的機(jī)器就能實(shí)現(xiàn)大數(shù)據(jù)量的保存和讀取。在HDFS中,一個集群包括一個NameNode和多個DataNode。采用一個NameNode的體系設(shè)計將使得整體系統(tǒng)架構(gòu)更加簡潔[9]。
2.2 MapReduce
MapReduce 是Google提出的一種并行編程模型[10],由于Hadoop的強(qiáng)大功能和簡潔架構(gòu),當(dāng)前已經(jīng)構(gòu)建面世多種實(shí)現(xiàn),其中,除Google的官方實(shí)現(xiàn)外,Hadoop的MapReduce模型是具有最高使用頻度的。具體來說,MapReduce的編程可通過map和reduce兩個階段得以推進(jìn)并完成,其中map函數(shù)從底層分布式文件系統(tǒng)接收輸入的一組鍵值對,再通過并行操作,產(chǎn)生一組中間結(jié)果的鍵值對,將其傳遞給reduce函數(shù)。reduce函數(shù)并行處理,將中間結(jié)果以鍵值進(jìn)行合并,最終產(chǎn)生一個規(guī)模更小的結(jié)果值集合,輸出到底層分布式文件系統(tǒng)。MapReduce計算任務(wù)由一個JobTracker和多個TaskTracker 協(xié)作完成[9]。
2.3 Hbase
Hbase是運(yùn)行在Hadoop平臺上的非結(jié)構(gòu)化數(shù)據(jù)存儲數(shù)據(jù)庫[11],其中的全部數(shù)據(jù)均存儲在底層HDFS文件系統(tǒng)上,而且支持Hadoop的MapReduce編程模型。Hbase數(shù)據(jù)行記錄包括3個基本類型:行關(guān)鍵字(Row Key)、時間戳(Time Stamp)和列(Column)。在各類型中,行關(guān)鍵字是數(shù)據(jù)表的主鍵,數(shù)據(jù)的每次操作都有與之關(guān)聯(lián)的時間戳,列又可以劃分為多個列簇(Column Family)。雖然從概念視圖呈現(xiàn)上得知,每個Hbase表由許多行組成;但在物理存儲上,Hbase采取基于列存儲的模式存儲數(shù)據(jù)記錄。而且,Hbase可以動態(tài)地增加列,如此則為民間藝術(shù)數(shù)據(jù)庫的表格設(shè)計提供了很強(qiáng)的靈活性。
本文中,研究構(gòu)建的Hadoop民間藝術(shù)資源云存儲平臺具有以下特點(diǎn):
(1)可擴(kuò)展性。具有存儲可擴(kuò)展和計算可擴(kuò)展性,可以按需擴(kuò)展,能夠滿足民間藝術(shù)資源數(shù)據(jù)持續(xù)增長的需求。
(2)通用性。分布式文件系統(tǒng)和Hbase數(shù)據(jù)庫能夠處理數(shù)據(jù)結(jié)構(gòu)完全不同的異構(gòu)數(shù)據(jù),MapReduce 的并行編程模型適合處理異構(gòu)大數(shù)據(jù)。
(3)共享性。用戶只要聯(lián)網(wǎng),即能在任何時間、任何地方到云上方便地存取數(shù)據(jù)。
(4)低成本。該存儲平臺可以運(yùn)行在普通的微機(jī)上,不需要昂貴大型系統(tǒng)的條件限制及底層支持。
4 結(jié)束語
云計算和云存儲作為新興的網(wǎng)絡(luò)計算和存儲技術(shù),在大數(shù)據(jù)時代具有廣泛的應(yīng)用及前景。構(gòu)建基于Hadoop的民間藝術(shù)資源云存儲平臺具有可行性和有效性,能夠應(yīng)對當(dāng)前民間藝術(shù)資源傳承和保護(hù)工作所面臨的挑戰(zhàn)。
參考文獻(xiàn):
[1] 彭冬梅, 潘魯生, 孫守遷. 數(shù)字化保護(hù)——非物質(zhì)文化遺產(chǎn)保護(hù)的新手段[J]. 中國書畫, 2006(1): 47-51.
[2] 劉海青. 數(shù)據(jù)庫技術(shù)在非物質(zhì)遺產(chǎn)保護(hù)中的運(yùn)用研究——以紅河哈尼族彝族民間藝術(shù)數(shù)據(jù)庫創(chuàng)建為例[J]. 數(shù)字技術(shù)與應(yīng)用, 2010(9): 155-157.
[3] 譚必勇, 張瑩. 中外非物質(zhì)文化遺產(chǎn)數(shù)字化保護(hù)研究[J]. 圖書與情報, 2011(4): 8-11.
[4] 劉智慧, 張泉靈. 大數(shù)據(jù)技術(shù)研究綜述[J]. 浙江大學(xué)學(xué)報(工學(xué)版), 2014, 48(6): 957-972.
[5] 吳明珠, 陳瑛. 基于云存儲技術(shù)的教育資源構(gòu)建與共享[J]. 計算機(jī)教育, 2014(7): 40-44.
[6] 張龍立. 云存儲技術(shù)探討[J]. 電信科學(xué), 2010(S1): 71-74.
[7] The Apache Software Foundation. Apache Hadoop Project [EB/OL]. [2016-02-13]. http://hadoop.apache.org/.
[8] D Borthakur. HDFS Architecture Guide [EB/OL]. [2013-02-14]. http://hadoop.apache.org/docs/r1.0.4/hdfs_design.html.
[9] 崔杰, 李陶深, 蘭紅星. 基于Hadoop的海量數(shù)據(jù)存儲平臺設(shè)計與開發(fā)[J]. 計算機(jī)研究與發(fā)展, 2012, 49(S1): 12-18.
[10] J Dean, S Ghemawat. MapReduce: simplified data processing on large clusters[J].
Communications of the ACM, 2008, 51(1): 107-113.
[11] 張智, 龔宇. 分布式存儲系統(tǒng)HBase關(guān)鍵技術(shù)研究[J]. 現(xiàn)代計算機(jī)(專業(yè)版), 2014(32): 33-37.
[12] 黎宏劍, 劉恒, 黃廣文,等. 基于Hadoop 的海量電信數(shù)據(jù)云計算平臺研究. 電信科學(xué), 2012(8): 80-85.
[13] 林清瀅. 基于Hadoop 的云計算模型[J]. 現(xiàn)代計算機(jī)(專業(yè)版), 2010(7): 114-116, 121.
猜你喜歡
數(shù)字技術(shù)與應(yīng)用(2016年9期)2016-11-09 22:56:18
數(shù)字技術(shù)與應(yīng)用(2016年9期)2016-11-09 00:07:05
知音勵志·社科版(2016年8期)2016-11-05 04:28:47
電腦知識與技術(shù)(2016年21期)2016-10-18 23:34:52
電腦知識與技術(shù)(2016年21期)2016-10-18 23:24:44
電腦知識與技術(shù)(2016年21期)2016-10-18 22:11:15
科技視界(2016年22期)2016-10-18 14:33:46
中國新通信(2016年16期)2016-10-18 10:49:17
大學(xué)教育(2016年9期)2016-10-09 08:54:03
科技視界(2016年20期)2016-09-29 13:34:06
