SPSS的聚類分析在經濟地理中的應用
2016-05-13 01:38:32丁磊,馮小康
西部皮革 2016年8期
?
SPSS的聚類分析在經濟地理中的應用
1引語
經濟地理研究中,經常需要對所研究的區域進行經濟區劃分,以便進行分類指導。如何進行經濟區劃分呢?利用世界上著名的統計軟件SPSS(Statistical Program for Social Science)的聚類分析功能,效果相對比較理想。聚類分析法是理想的多變量統計技術,主要有分層聚類法和迭代聚類法(蘇金明,2000)。聚類分析也稱群分析是研究分類的一種多元統計方法。它的基本原理是:首先講一定數量的樣品(或指標)各自看成一類,然后根據樣品(或指標)的親疏程度,將親密程度最高的兩類進行合并;然后考慮合并后的類與其他類之間的親疏程度,再進行合并;重復這一過程,直至將所有的樣品(或指標)合并為一類。
對貴州省各州市的9個地區(貴陽、遵義、安順、黔南、黔東南、銅仁、畢節、六盤水、黔西南)進行經濟區劃分,就利用了SPSS的聚類分析功能。
2建立指標體系
2.1確定分類指標
進行經濟區劃分,應考慮的指標因素很多的。既要以經濟因素為主,又要考慮自然因素和社會因素;既要有直接指標,又要有間接指標;既要有影響經濟因素的指標,又要有經濟現象引起的指標;既要考慮經濟發展的現狀,又要考慮經濟發展的過程和經濟發展的未來方向;既要有可以查閱到或計算出確切數據的指標,又要有無確切數據的指標。
參考有關資料,我確定了對貴州省各地區進行經濟區劃分的指標。有確切數據的指標如表1所示,無確切的數據的指標有煤炭資源、油氣資源、建材資源和區位商貿。
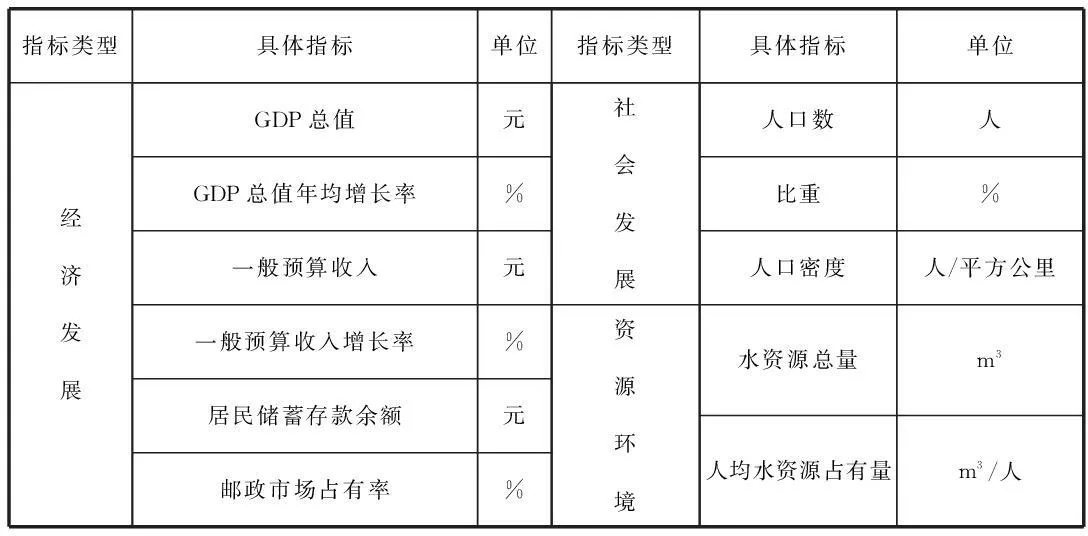
表1 經濟區劃分指標
2.2填充指標數據
參照《貴州省統計年鑒》2011卷、《貴州省水資源公報》等書,查得或計算出表1各具體指標的數據如表2所示。
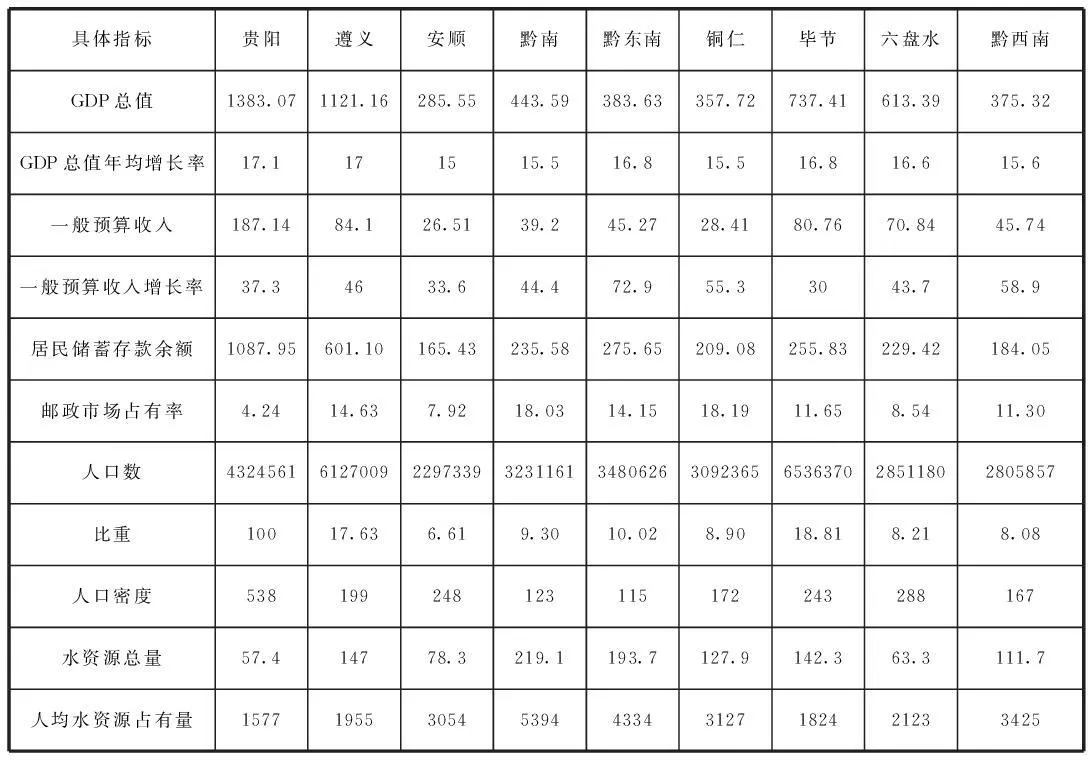
表2 貴州省各州市的9個地區經濟區劃分的指標數據(數據單位見表1)
2.3轉換指標數據
由于不同變量之間存在不同量綱、不同數量級,為使各個變量更具有可比性,有必要對數據進行轉換。目前進行數據處理的方法大致有三種,即標準化、極差標準化和正規化。為便于更直觀的比較各市之間同一指標的數值大小,采用了正規化轉換方式(張蘇江,2003)。其計算公式為:
公式中Xi為正規劃后的值,Xi為原值,Xmax為最大值,Xmin為最小值。
進行正規化轉換后,0≦Xi≦1。另外,對9個地區的煤炭資源、油氣資源、建材資源和區位商貿等指標也根據實際情況采用專家打分法,給出一個介于0-1的數。所有參與聚類分析的指標數據見表3。
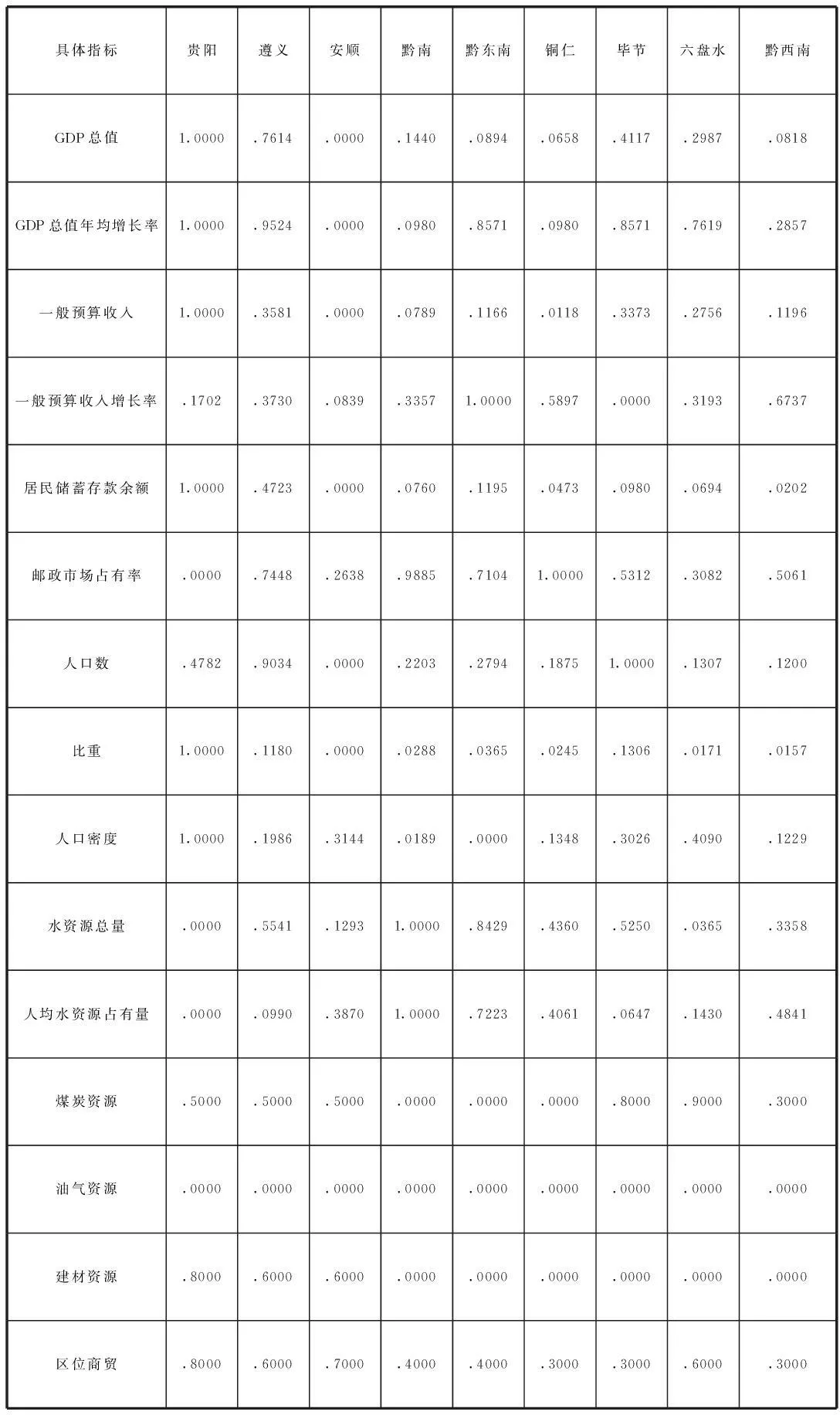
表3 貴州省各州市的9個地區經濟區的聚類分析數據
說明:1.表中數據保留四位小叔;2.小數點前面的0省略。
3聚類分析
根據表3數據,利用統計分析軟件SPSS對貴州省各州市的9個地區進行聚類分析,得出如下結果,包括表4、5、6和圖1。
3.1解析表1
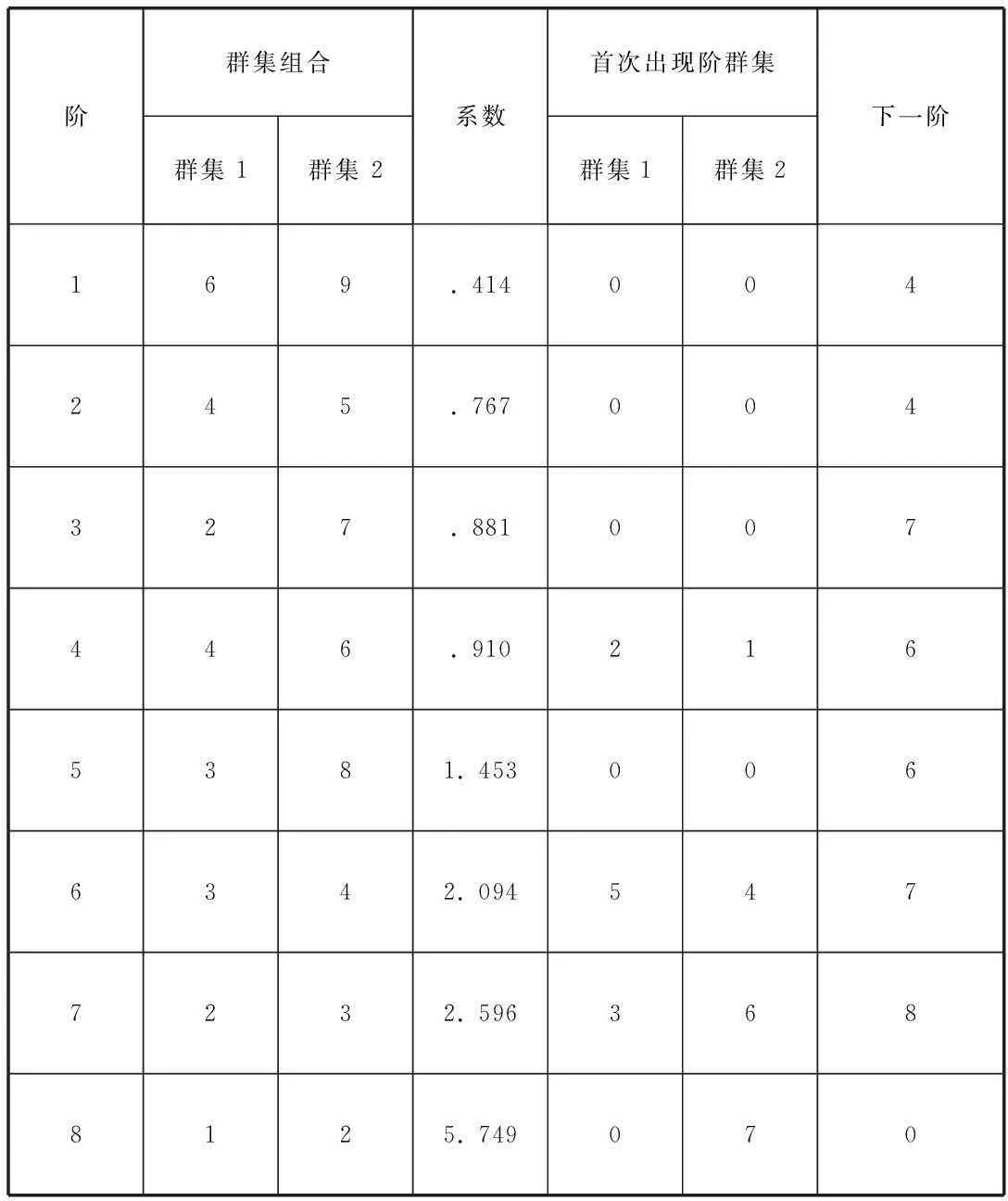
表4 聚類分析聚結表
說明:合并前的個案從1-9依次表示貴陽、遵義、安順、黔南、黔東南、銅仁、畢節、六盤水、黔西南
3.1.1聚類步驟。從1-9表示聚類的先后順序。
3.1.2個案合并。表示在某步中合并的個案,如第一步中個案6銅仁和個案9黔西南合并,合并以后用第一項的個案號表示生成的新類。
3.1.3相似系數。根據聚類分析的基本原理,個案之間親密程度最高即相似系數最接近1的,最先合并。因此該列中的系數與第一列的聚類步驟相對應,系數值從小到大排列。
3.1.4新類首次出現的步驟。對應于各聚類步驟參與合并的兩項中,如果有一個是新生的類,則在對應列中顯示出該新類在哪一步第一次生成。如第四步中該欄第一列顯示值為2,表示進行合并的兩項中第一項是在第二步第一次生成的新類。如果值為0,則表示對應項還是個案。
3.2解析表2
表5聚類分析水平冰柱圖表
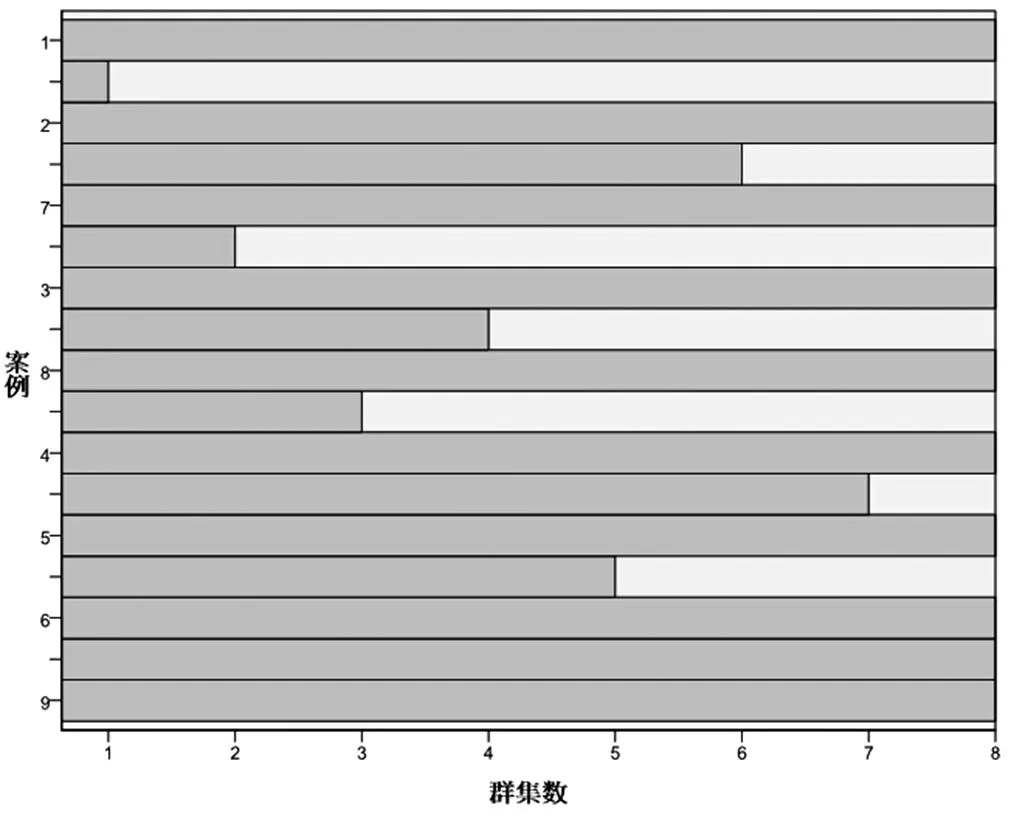
表4中,如果個案或新類在第n步合并,則表5中倒數第n步及以前合并項對應行之間的行中用X充填,沒有空格。例如表4中第一步為個案6和個案9合并,則表5中對應于第8步,個案6和個案9對應的行之間在第8步及以前用X充填。表4中第二步為個案4和個案5合并,則表5中對應于第7步,這兩個個案對應的行之間在第7步及以前用X充填。如此繼續下去,直至所有個案在最后一步聚為一類。
3.3解析圖1
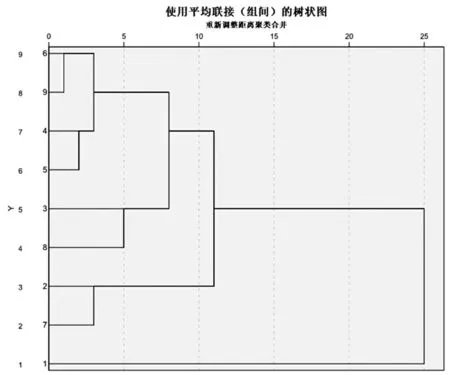
圖1 貴州地區9市經濟區域劃分聚類樹狀圖
圖1 清晰地表示了聚類的全過程。它將實際距離按比例0-25的范圍內,用逐級連線的方式連結性質相近的個案或新類,直至并為一類(張文彤,2002)。在該圖上部的距離標尺上根據需要選定一個劃分類的距離值,然后垂直標尺劃線,該垂線將于水平連線相交,則相交的交點數即為分類的類別數,相交水平連線所對應的個案聚成一類。例如,選標尺值為10,則所有個案分為4類,即銅仁、黔西南、黔南、黔東南為一類,安順和六盤水為一類,遵義和畢節為一類,貴陽為一類。若選標尺值為20,則聚為兩類,貴陽為一類,其余為一類。
4結論
對貴州各市州進行經濟區劃分,究竟化為幾個區合適,既不是越多越好,也不是越少越好,劃分經濟區的目的,就是要根據經濟區特點的不同,分類指導經濟活動,使人們的經濟活動更加符合當地的實際,使各經濟區能充分發揮各自自然、經濟、社會等方面的優勢,做到揚長避短,趨利避害,達到投入少、產出多,創造良好的經濟效益和社會效益的目的,分區太多,就失去了分區的意義,分區太少,則分類指導很難做到有的放矢。綜合,我認為分為四類比較合適。
從聚類分析中看出,銅仁和黔西南相似系數最大,最早聚合,明顯是一類,遵義和畢節相似系數較大,劃為一類;安順和六盤水歸為一類,黔南和黔東南地理位置就靠近,相似系數較大,作為一類,銅仁和黔西南聚為一類后又與黔南黔東南聚為一類的新類再聚為一類,9個市中,貴陽最為特殊,從經濟發展水平、發展速度、產業結構等各方面都與其他市區別很大,難以成為一類。因此,我們單獨把貴陽化為一類。根據以上的分析,把貴州省9個市州的經濟區劃分概括成表6。

表6 貴州省經濟區劃分
參考文獻:
[1]蘇金明,傅榮華,周建斌,張蓮花.統計軟件SPSS for Windows 實用指南[M].武漢;電子工業出版社,2000.
[2]貴州省統計局.貴州統計年鑒[M].北京:中國統計出版社,2011.
[3]張蘇江,許宗運.數據統計分析軟件SPSS的應用.畜牧和獸醫,2003(10):47-51.
[4]張文彤.SPSS11統計分析教程[M].北京:北京希望電子出版社,2002.
SPSS cluster analysis application in economic geography
丁磊1,馮小康2
(1.貴州師范大學喀斯特研究院,貴州 貴陽 550001;2.蘇州國環環境檢測有限公司,江蘇 蘇州 215100)
摘要:對貴州省各市州進行經濟地理分區,首先建立分類指標體系,然后查得或計算出有關數字并進行正規化轉化,最后利用SPSS進行聚類分析得出結論。
關鍵詞:貴州省;分類指標體系;SPSS;經濟區
Abstract:Secri the province by the economic geography partition, classification index system first, and then Chad or calculate the relevant Numbers and regularized transformation, finally using SPSS clustering analysis conclusion.
Key words:Guizhou province; Classification index system; SPSS; Economic zone
中圖分類號:K902
文獻標志碼:A
文章編號:1671-1602(2016)08-0077-03
作者簡介:丁磊(1991-),男,江蘇南京人。碩士,主要從事喀斯特生態建設與區域經濟的研究。馮小康(1991-),男,江蘇泰州人,碩士,主要從事環境工程的研究。
