使用GA初始化CGHMM參數的軸承故障診方法
2016-05-19 09:09:32陸汝華顏文燕湘南學院軟件與通信工程學院湖南郴州423000
噪聲與振動控制 2016年2期
陸汝華,顏文燕(湘南學院軟件與通信工程學院,湖南郴州423000)
?
使用GA初始化CGHMM參數的軸承故障診方法
陸汝華,顏文燕
(湘南學院軟件與通信工程學院,湖南郴州423000)
摘要:連續高斯混合密度隱馬爾可夫模型(ContinuousGaussian MixtureHidden Markov Model, CGHMM)在故障診斷領域得到了廣泛應用,取得了較好效果。CGHMM訓練模型較大、局部最優,但模型參數初始化值會直接影響迭代收斂速度和模型效用。全局最優的遺傳算法(GeneticAlgorithm, GA)初始化CGHMM模型參數,為CGHMM訓練提供了一個好的初始值,不僅可以加快收斂速度,還可以得到一個更好的模型。通過GA初始化CGHMM、CGHMM訓練和CGHMM診斷過程等三個方面的仿真實驗和比較分析可以得出,該方法具有訓練速度快和CGHMM模型好的優點。在最后的CGHMM診斷仿真實驗中,該方法診斷精度為100%,高于經典方法的96%,表明GA確實可以成功應用于CGHMM參數初始化,是一種可行的故障診斷方法。
關鍵詞:振動與波;遺傳算法;初始化;連續高斯混合密度隱馬爾可夫模型;故障診斷
在旋轉機械設備中,滾動軸承是應用最為廣泛、同時也是最重要的部件之一,其運行狀態好壞直接影響整個設備的性能、壽命、功能和效率,如果滾動軸承發生故障,往往會導致異常噪聲和振動,嚴重時還會損壞設備,造成工業生產效率下降,甚至帶來嚴重事故和安全問題[1],因此,對滾動軸承進行在線監測與故障診斷,及時準確檢測出軸承工作狀態具有十分重要的應用價值和意義[2]。在這種背景環境中,如何針對滾動軸承的微弱故障特征進行故障診斷是成為機械領域的熱點和難點問題之一[3]。
故障診斷實質上是一個模式識別過程,近年來,學者們相繼提出各種故障特征分類有效方法,除了神經網絡和支持向量機等之外,研究數量較多、性能效果較好的還有隱馬爾可夫模型(Hidden Markov Model,HMM)[4]。HMM分為離散HMM(DHMM)和連續HMM(CHMM),基于高斯密度混合函數的CHMM又稱為CGHMM。與DHMM相比,CGHMM涉及到更為復雜的數學模型,能夠得到更高的診斷精度,當然是以運算速度作為代價。也正因為如此,學者對CGHMM方法進行了多種改正,尤其是在HMM訓練算法中對HMM參數的初始化問題上面。對于數據量大的CGHMM而言,隨機初始化導致訓練算法的迭代過程很難收斂,不僅造成訓練時間的延長,不停的數據運算也會降低數據精度,因而出現了使用聚類算法等初始化方法[5]。但HMM訓練算法(經典的Baum-Welch算法)只是一種局部最優的梯度下降算法,在訓練過程中存在陷入局部的缺點,而遺傳算法(Genetic algorithm,GA)可以克服這個缺陷[6]。因此,作者利用GA的全局搜索能力優化CGHMM訓練過程,得到全局最優的CGHMM模型。最后仿真實驗中的各種實例驗證了該方法的有效性,為軸承故障診斷提供了一種新方法。
1 CGHMM訓練模型
CGHMM模型包括初始概率分布π,狀態轉移概率A和觀察值概率B,而B=(μ,σ2,ω)又由均值矢量μ、協方差矩陣σ2和權值ω三個參數組成,可以說CGHMM模型包含五個參數,記為λ=(π,A,μ,σ2,ω)。對CGHMM模型進行訓練,即CGHMM五個參數π、A、μ、σ2、ω的迭代重估過程,通常采用Baum-Welch算法[7]。首先是輸入一系列觀察值,并初始化五個參數值π、A、μ、σ2、ω,再根據CGHMM訓練算法不斷迭代獲得新的模型參數,使輸出概率P(O/λ)達到最大[7]。
CGHMM參數可以采取隨機初始化方法,不過會造成很多次的迭代才能收斂,這樣不僅增長訓練運行時間,也會降低數據運算精度。有不少研究者提出采用k-means聚類算法進行初始化,這樣基于觀察值序列的初始化會使初始模型來源于樣本數據,在一定程度上優化訓練算法。但是,由于CGHMM是一個含有隱變量的統計模型,在Baum-Welch迭代重估過程中存在陷入局部的缺點,只能找到一個局部最大的輸出概率P(O/λ),也就是局部最優的CGHMM參數π、A、μ、σ2、ω。GA算法依據自然界適者生存、優勝劣汰的進化機制來搜索和計算問題最優解,主要特點是群體搜索策略和群體中個體之間的信息交換,搜索不依賴于梯度信息[8],因此,使用GA初始化CGHMM參數進行CGHMM訓練,以達到全局最大的輸出概率P(O/λ),獲得全局最優的CGHMM模型,以便在軸承故障診斷過程中能夠得到更好的診斷效果。
2 GA初始化CGHMM參數的改進算法
GA是全局最優的搜索算法,當確定個體組成的種群之后,使用適應度函數通過一系列選擇、交叉、變異等操作獲得最優的個體[9],詳細算法流程如圖1所示。

圖1 遺傳算法流程圖
在圖1所示流程圖中,GA初始化CGHMM參數主要包括如下幾個步驟。
(1)個體的定義與組成結構
在CGHMM初始模型中,π、A的選取對模型性能影響不大,可以隨機初始化,這里只考慮GA初始化其它三個參數μ、σ2、ω,獲得參與CGHMM訓練的初始模型。但不可將μ、σ2、ω三個參數作為個體,不僅是因為三類組成個體增加程序的復雜性,還因為這三者之間存在一定關聯,并不是獨立無關的三個變量。也不能將CGHMM模型中的B作為個體,因為在CGHMM模型中,B又是由三個參數μ、σ2、ω組成,通過GA算法之后即使獲得了B值,也無法分別確定μ、σ2、ω的值。考慮到三個參數μ、σ2、ω可通過觀察值序列計算得出,因此定義觀察值序列為個體,獲得最優個體之后,再根據最優個體計算出μ、σ2、ω三個參數的值,得到最優的CGHMM初始模型。
不過,GA算法輸出的最優個體只是一串二進制符號,需要確定個體組成才能知道如何參與運算。而個體組成與原始信號特征提取有關,記觀察值序列長度為T,MFCC特征提取維數為L,每一個浮點數對應的二進制位數為M,個體的組成結構如圖2所示,可以看出,一個個體包括T×L×M位二進制碼。

圖2 個體的組成結構
(2)個體適應度函數定義
適應度是生物學中用于表示物種對生存環境適應的程度,在GA中是選擇和評價個體的依據。CGHMM模型的好壞取決于輸出概率P( O/λ)是否盡可能最大,O是輸入的觀察序列樣本,λ是CGHMM訓練的初始模型,其中μ、σ2、ω參數由GA獲得的個體分別計算得出的均值、方差和權值。以多樣本觀察序列為CGHMM訓練數據,記為,N為樣本數,則定義個體適應度函數為
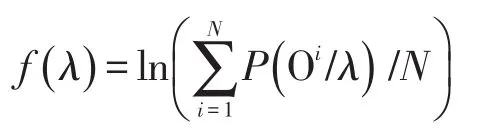
(3)遺傳算子
遺傳算子包括選擇、交叉、變異等基本操作,在算法中執行的次數是迭代次數乘以遺傳代數。
選擇操作使用通常的輪盤賭算法,從已有的種群中根據概率選擇一些個體來產生下一代,而這個概率與個體的適應值函數成正比關系。設種群中個體數為n,個體i的適應度函數為Fi,個體i被選擇的概率為Pi,則存在下列比例關系

從種群ZQ中選擇一個個體的基本步驟分為四步。
Step2:產生一個0到sum之間的隨機數;
Step 3:將種群ZQ中所有個體根據適應度大小值從小到大排序;
Step 4:從種群ZQ中第1個個體開始,將適應度值與后面個體的適應度值依次相加,直到累加和大于等于sum,最后一次加進去的個體即為選擇的新個體。
對選擇之后的個體按交叉概率Pc執行交叉操作,通過兩個父代的部分結構加以替換組成新的個體,是獲取優秀個體最重要的步驟,GA的搜索能力得以飛躍性提高。由于CGHMM模型中個體的復雜性和個體間線性關系的特殊性,需要通過線性組合完成交叉。設線性組合系數為λ1和λ2,個體Oi和Oj的交叉公式為

交叉之后的新個體按變異概率Pm隨機生成幾個位置點對父代執行變異操作,以便繁殖更優秀的后代,獲得更優的個體,同時也保持了種群中個體的多樣性。
(4)獲得新種群
種群通過隨機初始化獲得多個個體,但經過選擇、交叉、變異等操作多次循環之后的新種群并不一定優于舊種群,為了讓每次繁殖至少不會降低最大適應度,最確定新種群之前,先判斷舊種群的最大個體適應度是否大于新種群的最大個體適應度,如果是,則將舊種群最大適應度對應的個體替換新種群中最小適應度對應的個體,以保證新種群最大個體適應度只增不減。
3 故障診斷仿真實驗
3.1仿真實驗準備
(1)數據準備
在CGHMM訓練與診斷中,所使用的原始數據是6202 CM深溝球滾動軸承,在轉速為1 800 r/min運行速度下采集的音頻信號。然后將音頻信號進行預處理,劃分為256幀長的多段部分重疊幀、12維MFCC進行特征參數提取,最后得到長度36的觀察值序列。采集的數據包括軸承正常音、內圈異音、外圈異音、滾動體異音、保持架異音等五種工作狀態下的音頻信號各50個,每一種的前20個作為CGHMM訓練樣本,后30個用于CGHMM故障診斷測試。
(2)參數設置
通過不斷反復實驗,采用自編程序測試不同參數設置的診斷效果,最后得到一組效果最好的參數值。在GA中,種群中個體數為50,因為MFCC參數絕對值最大數在500以內,因此浮點數轉換為二進制串的位數為9,最重要的兩個參數交叉概率和變異概率分別為0.88和0.02。在CGHMM模型中,狀態數設置為7,混合高斯數設置為3,以完成CGHMM訓練和故障診斷實驗。
3.2 GA初始化CGHMM實驗
實驗采用的GA包括兩種方法,方法一:個體選擇三個參數μ、σ2、ω隨機初始化種群,經過選擇、交叉、變異等操作之后獲得新種群;方法二:個體定義為觀察值序列O,經過選擇、交叉、變異等操作之后,再從舊種群最大適應度和新種群最小適應度中的較大者選擇,以獲得新種群。都以種群內最大適應度變化很小為收斂條件,兩種方法各自運行50次的繁殖代數實驗結果比較如表1所示。從繁殖代數的最大值、最小值和平均值可以說明,方法二的收斂速度遠遠快于方法一。

表1 遺傳算法繁殖代數
為了能夠直觀顯示迭代過程,方法一與方法二都選取一次繁殖代數接近平均值的實驗,每一次繁殖之后獲得的種群最優適應度和平均適應度如圖3所示。從圖中可以得出,方法二的最優適應度和平均適應度都高于方法一,并且,方法二的曲線變化更加平滑,基本是一直上升,50次迭代即達到收斂條件,這也正說明了利用GA初始化CGHMM的有效性。

圖3 繁殖過程的適應度變化圖
3.3 CGHMM訓練實驗
為了驗證方法的有效性,訓練實驗與后面的診斷實驗都包括兩種方法,即本文方法和經典方法,分別使用GA和k-means算法初始化CGHMM參數進行模型訓練。CGHMM模型的初始化值直接影響到CGHMM訓練模型的好壞,訓練時不同迭代階段的輸出概率變化能直觀顯示出模型的優化過程。以正常音訓練過程的前50次迭代為例,每一次迭代之后的輸出概率如圖4所示。
在圖4中,本文方法的起步概率較大,是因為使用了GA初始化CGHMM參數的緣故,正因為如此,收斂速度非常快,只需要迭代10次就達到收斂條件,而經典方法迭代了28次才收斂,最終的收斂概率本文方法也高于經典方法,表明本文方法訓練過程的速度和效果都要優于經典方法。

圖4 訓練迭代過程的輸出概率
3.4 CGHMM診斷階段輸出概率實驗
多個模型訓練好了之后,便可以進入診斷階段。訓練過程中的輸出概率能夠說明模型好與壞的變化方向,但并不能表明其診斷效果也是相同的變化。為了更進一步測試故障診斷方法的診斷效果,本小節對故障診斷過程中各種故障類型數據在所有模型下的輸出概率進行了比較。以30個測試用正常音數據為例,分別使用本文方法和經典方法,在所有故障類型模型下的平均輸出概率(因為輸出概率太小,取其對數作為縱坐標值)如圖5所示,圖中未畫的部分代表輸出概率為零。
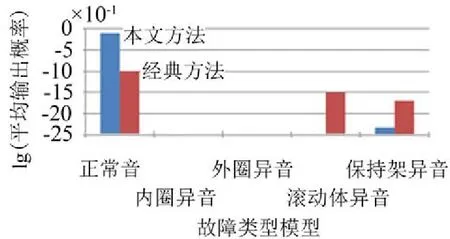
圖5 診斷階段正常音的平均輸出概率
總的來說,正常音模型下的輸出概率都是最高,兩種方法的診斷效果都好。不過,為了比較本文方法與經典方法診斷效果好的程度與深度,著重于從下面三個方面分析:
(1)正常音模型下的輸出概率,本文方法高于經典方法;
(2)滾動體異音和保持架異音兩個模型下的輸出概率,本文方法低于經典方法;
(3)正常音模型與其它模型下的輸出概率差距,本文方法大于經典方法。
本文方法在三個方面都優于經典方法,并且本文方法在正常音模型與其它模型下的輸出概率差距較大,從診斷過程表明,將GA引入到CGHMM模型訓練確實是一種可行方法。
3.5 CGHMM診斷精度實驗
最終故障診斷精度直接決定著故障診斷方法的好壞,分別使用本文方法和經典方法,以最大輸出概率為匹配結果,對正常音、內圈異音、外圈異音、滾動體異音、保持架異音等五類故障狀態30個測試用數據所獲得的診斷精度如圖6所示。

圖6 診斷精度
本文方法每一類測試用數據的診斷精度都達到100 %,所有數據測試全部正確,總的診斷精度也是100 %。經典方法對150個數據測試共有6個誤識,總的診斷精度為96 %,可以得出,本文方法優于經典方法。
4 結語
基于GA和HMM建模的基本理論,提出了一種故障診斷新方法:CGHMM訓練階段使用GA初始化CGHMM參數。在介紹了該方法總體框架和重要步驟之后,從GA初始化CGHMM、CGHMM訓練過程、CGHMM診斷階段輸出概率、CGHMM診斷精度等四個方面詳細描述實驗仿真的過程與結果,并將本文方法與其它方法進行了比較分析,得出了本文方法效果較好的結論。
參考文獻:
[1]艾延廷,馮研研,周海侖.小波變換和EEMD-馬氏距離的軸承故障診斷[J].噪聲與振動控制,2015,35(1):235-239.
[2] GAO Hui- zhong, Liang Lin, CHEN Xiaog- uang, et al. Feature extraction and recognition for rolling element bearing fault utilizing short- time fourier transform and non-negative matrix factorization[J]. Chinese Journal of Mechanical Engineering, 2015, 1:96-105.
[3]梁雙印,潘作為,祖勇海,等.短時有效值包絡分析在風機軸承故障診斷中的應用[J].噪聲與振動控制,2015,35 (4):48-51.
[4] Cody Hudson, Bernard Chen, Dongsheng Che. Hierarchically clustered HMM for protein sequence motif extraction with variable length[J]. Tsinghua Science and Technology, 2014, 6:635-647.
[5]章登義,歐陽黜霏,吳文李.針對時間序列多步預測的聚類隱馬爾科夫模型[J].電子學報,2014,12:2359-2364.
[6] Sunil Nilkanth Pawar, Rajankumar Sadashivrao Bichkar. Genetic algorithm with variable length chromosomes for network intrusion detection[J]. International Journal of Automation and Computing, 2015, 3:337-342.
[7]陸汝華,段盛,楊勝躍,等.基于CGHMM的軸承故障音頻信號診斷方法[J].計算機工程與應用,2009,45(11):223-225+234.
[8] Kong Haipeng, Li Ni, Shen Yuzhong. Adaptive double chain quantum genetic algorithm for constrained optimization problems[J]. Chinese Journal of Aeronautics, 2015, 1:214-228.
[9] Morteza Vadood, Majid Safar Johari, Ali Reza Rahai. Relationship between fatigue life of asphalt concrete and polypropylene/polyester fibers using artificial neural network and genetic algorithm[J]. Journal of Central South University, 2015, 5:1937-1946.
Fault Diagnosis Method of Bearings Based on CGHMM Initialization by Genetic Algorithm
LU Ru-hua , YAN Wen-yan
( School of Softwareand Communication Engineering, Xiangnan University Chenzhou 423000, Hunan China)
Abstract:Thecontinuous Gaussian mixturehidden Markov model (CGHMM) hasbeen widely and successfully used in fault diagnosis. However, the traditional CGHMM has some inherent disadvantages, such as the model complexity, the local optimization, low iterativeconvergencespeed and modeling effect dueto initialization of CGHMM parameters. In this paper, the CGHMM model parameters initialized by genetic algorithm were used as the reasonable initial values for CGHMM training. Using this method, the convergence speed can be accelerated and a better effect of modeling can be obtained. Through the simulation experiments in three aspects of CGHMM initialized by genetic algorithm, the CGHMM training process and the CGHMM diagnosis process, it was verified that this method have the advantages of fast training speed and better CGHMM model. The CGHMM diagnosis result demonstrates that the diagnosis precision can achieve 100 %, which ishigher than that of 96 % of theclassical method. Thisresult showsthat thegenetic algorithm can beapplied to CGHMM parameter initialization, andtheproposedmethodisafeasiblemethodfor fault diagnosis.
Key words:vibration and wave; genetic algorithm; initialization; continuous Gaussian mixture hidden Markov model (CGHMM); fault diagnosis
通訊作者:顏文燕(1986-),女,湖南人,碩士,主要研究方向為光通信技術、智能信息處理。E-mail:yanwenyan333@163.com
作者簡介:陸汝華(1980-),女,湖南人,碩士,主要研究方向為模式識別、智能信息處理。
基金項目:國家自然科學基金青年資助項目(61402540);湖南省教育廳資助科研項目(13C879);湘南學院[2012]125號NO2計算機應用技術創新訓練中心項目;湘南學院“十二五”重點學科計算機應用技術學科資助項目。
收稿日期:2015-09-14
文章編號:1006-1355(2016)02-0180-05
中圖分類號:TP206+.3
文獻標識碼:ADOI編碼:10.3969/j.issn.1006-1335.2016.02.040
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
