節點,將其節點屬性值作為待分類特征屬性,對來自所有領域的接口進行向量化,采用KNN算法進行分類。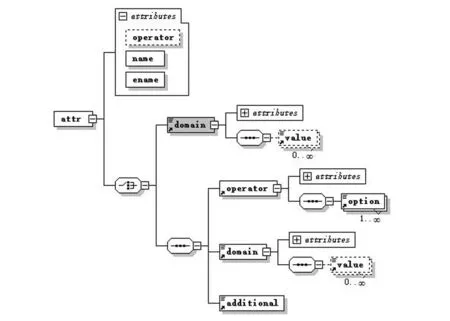
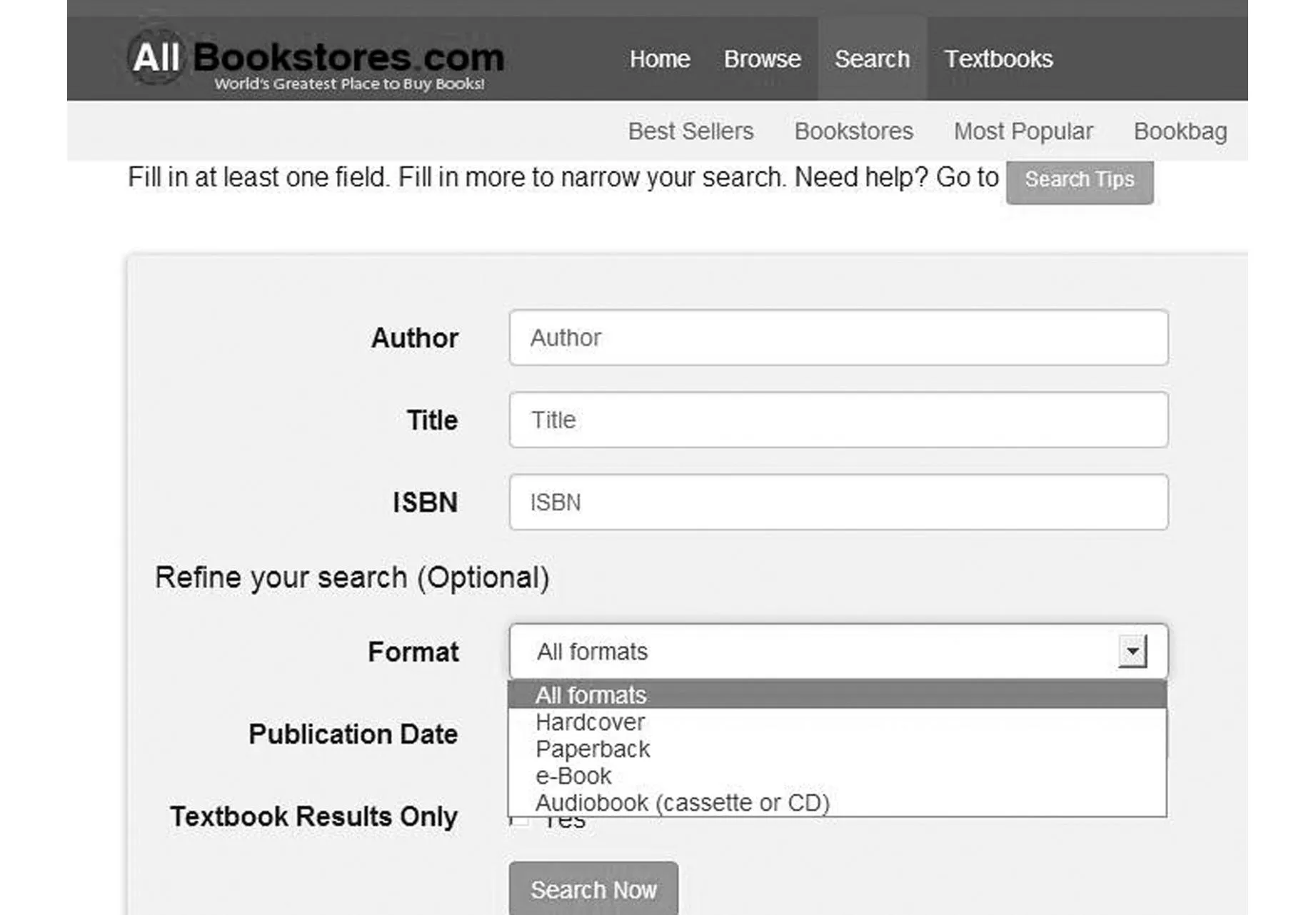
圖3 查詢表單節點的XML Schema結構
2.2節點語言學相似度計算
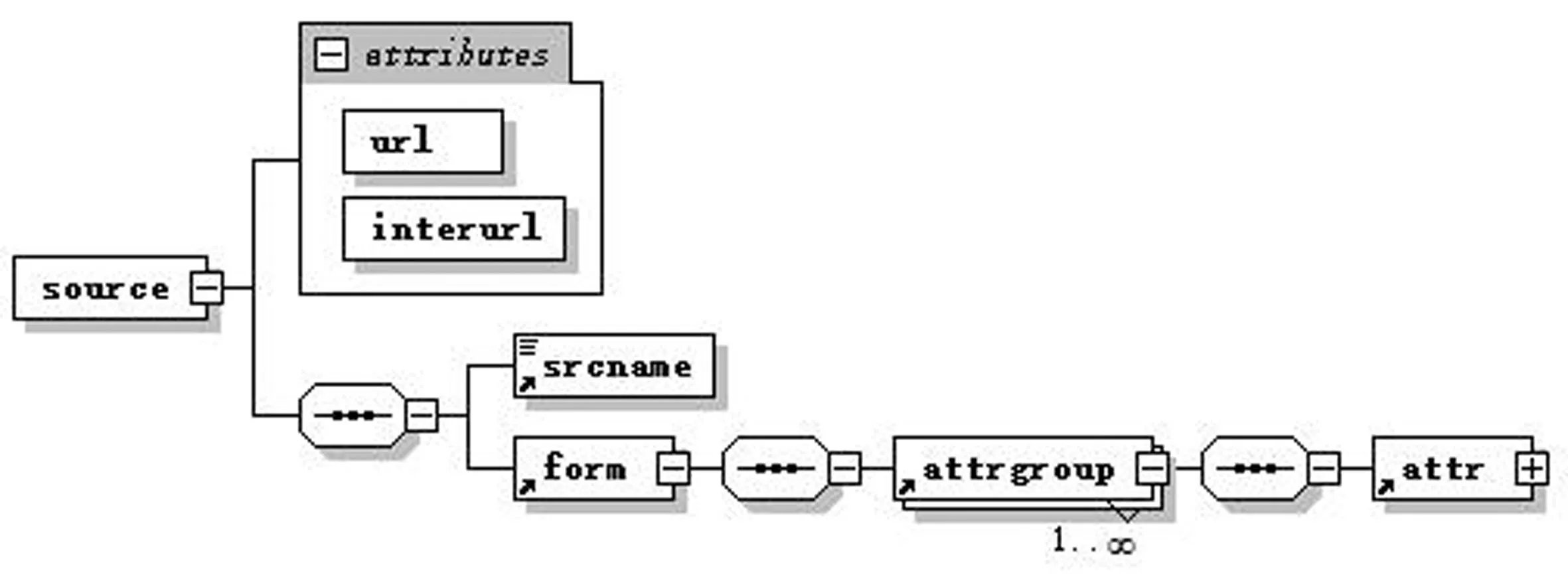
對于查詢接口XML schema,其屬性元素是代表其數據來源,表示結構如下:
因此直接判斷此節點值,有助于提高查詢匹配的效率,本文采用對此節點屬性值的語言學相似度lingSim()來判斷相似性。對于查詢接口t1和樣本t2(t2∈T),其獲取的屬性值為v(t1)和v(t2)
對v(t1)和v(t2)名稱字符串進行預處理,主要是實現字符串的拆分、去除一些虛詞和特殊連字符等,分解成獨立的單詞集(tokens)S1T1和S2T2,然后進行語相似性分析,主要是采用基于wordnet來計算語義相似度。語言學相似度計算如公式(1)所示。
(1)
其中,
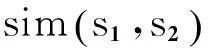
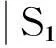
2.3查詢接口屬性選擇及權值計算
為了實現查詢接口快速分類,需要在分類前獲取所有的查詢接口對應的接口屬性元素的name值,選擇策略是只要在查詢接口集中有接口增減情況,都需要重新獲取其屬性。形成屬性name值的集合。
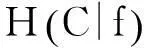
其中,ci(i=1,2,…m)為文本分類系統中的類別,p(ci)是指每個類別的出現概率。
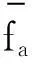
其中
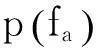
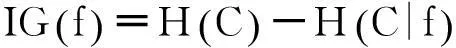
(2)
其次是屬性權值計算,目前比較常用的特征屬性權重計算函數有布爾函數、TF-IDF、 WIFD函數、以及TF-IWF 等,在文本文檔分類中使用最普遍的是TF-IDF 權值計算公式,TF-IDF基本思想是:如果一個詞在特定文檔中出現的次數越多,說明它在該文檔中的重要性越大,說明它區分文檔內容屬性的能力越強,如果一個詞在所有的文檔中都出現,說明它區分文檔內容屬性的能力越低[12]。如果查詢接口增多,其對應的屬性文本集也增大,需要對特征屬性的分類能力進行判斷,采用TF-IDF算法賦予接口屬性不同的權值,是為了跟據屬性特征貢獻大小實現查詢接口文本的向量化。
3基于 XML Schema的Deep Web查詢接口分類實現
3.1分類過程
本文提出的查詢接口分類是通過對查詢接口文本的XML表示,建立XML Schema,按照此XMLschema的結構,實現對不同查詢接口信息提取。主要是通過數據源名稱的語言學相似性能夠直接判斷哪些屬于同一個數據源的查詢接口。然后再對于不能夠直接判斷的查詢接口采用KNN分類算法進行分類,以確定其所屬類別。
設用戶查詢接口t和的查詢接口樣本集T(c1,c2,…,cm),其包含m個類別。對t進行分類,將其歸類到某個類別ci(i=1,2,…m)的過程如下:
1)對t和所有查詢接口ti(ti∈T),建立其對應的XML格式文檔(從網頁頁面中獲得)和XML schema樹。
2)對所有查詢接口ti,獲得所有查詢接口XML schema樹中的和元素,建立所對應的數據源名稱集V(T)和查詢接口屬性名稱集A(T)。
3)對于V(T),采用基于wordnet的語義分析,利用公式(1)計算t中的數據源名v(t)與V(T)中所有數據源名v(ti)∈V(T)的語言學相似度ingSim(v(t),v(ti))。
4)對于指定語言學相似度閾值σ,若存在一個或者多個lingSim(v(t),v(ti))>σ,則按照所屬接口所在的類別進行分類。如果對于所有的樣本V(T),其lingSim(v(t),v(ti))<σ,則需要對屬性名稱集A(T)根據IG方法計算公式(2)進行分類特征選擇,通過TF-IDF權值方法計算特征屬性權值,建立特征-接口矩陣和向量空間模型(VSM),將所有查詢接口ti向量化為特征空間向量di(x1,x2,…,xn)。
5)將t表示為和ti一致的特征向量d0(x1,x2,…,xn)。
6) 根據距離函數計算d0和di的相似度,可以使用兩向量之間歐氏距離計算,選擇與d0相似度最大(距離最小)的k個文本作為d0的k個最近鄰。利用歐氏距離計算公式為:
(3)
其中xil和x0l分別指di和d0的第l個屬性。
(7) 根據d0的k個最近鄰,計算文本類別相應的權重, 計算公式為:
(4)
其中S(di,d0)表示文本向量di與文本向量d0之間的相似度; 類別屬性函數為:
(8) 比較各類的權重,將待分類文本t0歸入權重最大的類別。
3.2案列分析
我們選擇了UCUI提供的TEL-8數據集,從其中的4個類c1:Arefares、類c2:Automobiles、類c3:Books和類c4:Jobs分別選取5個查詢接口作為樣本集,再選擇測試查詢接口。由于在這些領域中的許多查詢接口是來來自同一個數據源,因此我們分兩種情況進行測試:一是選擇來自相同數據源的查詢接口;二是選擇非相同數據源的查詢接口。
在對新的查詢接口分類前需要獲得樣本集中的所有接口和 節點屬性值,獲得其數據源名稱集V(T)和查詢接口屬性名稱集A(T)。則對于我們選擇的20個查詢接口:
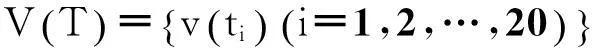

表1 v(t)和V(T)中各數據源語言學相似度
(1)在選擇了Arefares領域中來自同一數據源Orbitz Flight中的兩個查詢接口t和t1,如圖4(a)、4 (b)所示,t1在樣本接口集中,t作為測試數據進行測試。
其接口v(t)和V(T)中各數據源語言學相似度如表1所示。
我們選取相似度閾值σ=0.9,則判斷查詢接口t∈c1(t5所屬的領域)。
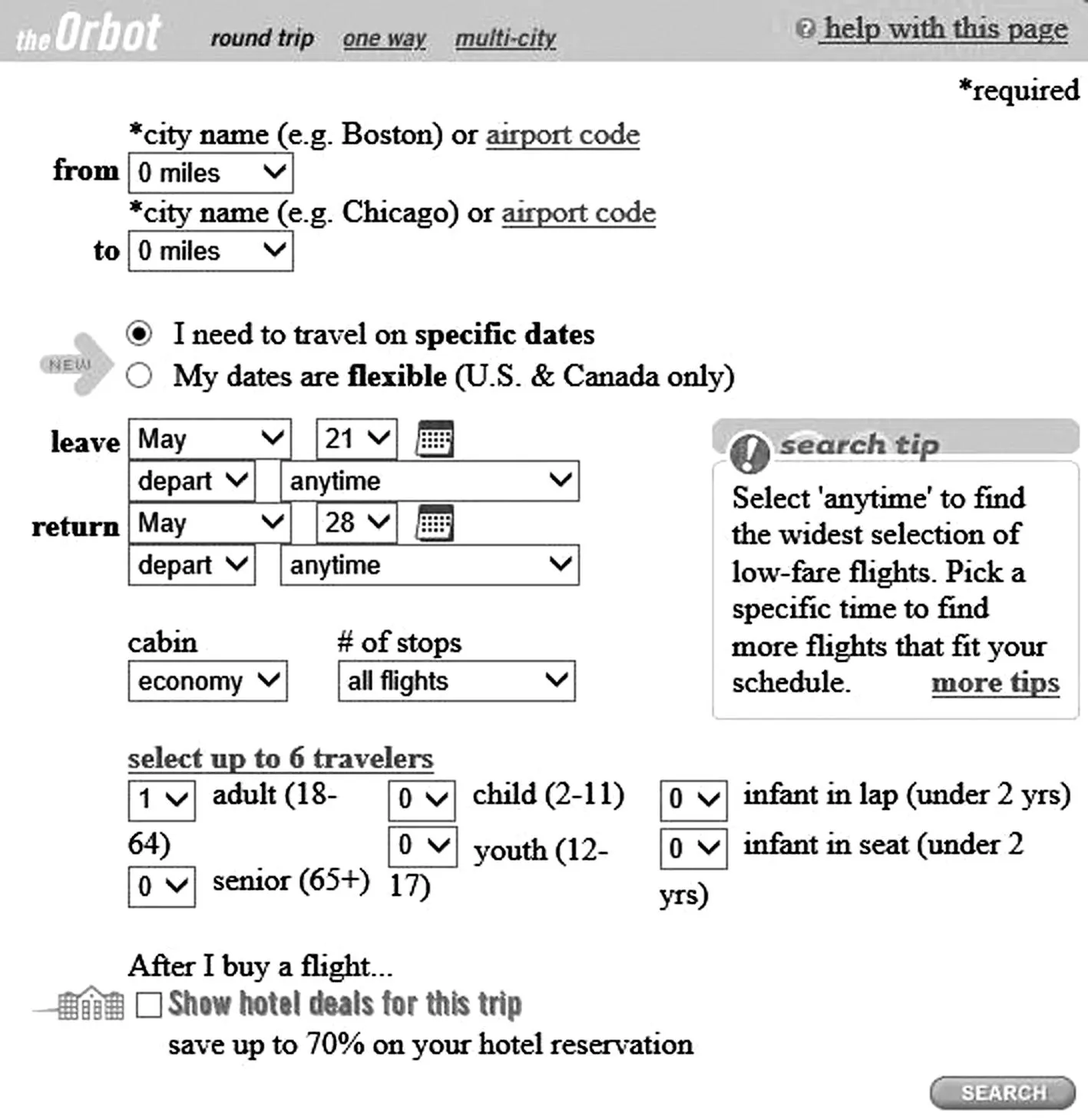
(a) Orbitz Flight中的查詢接口t
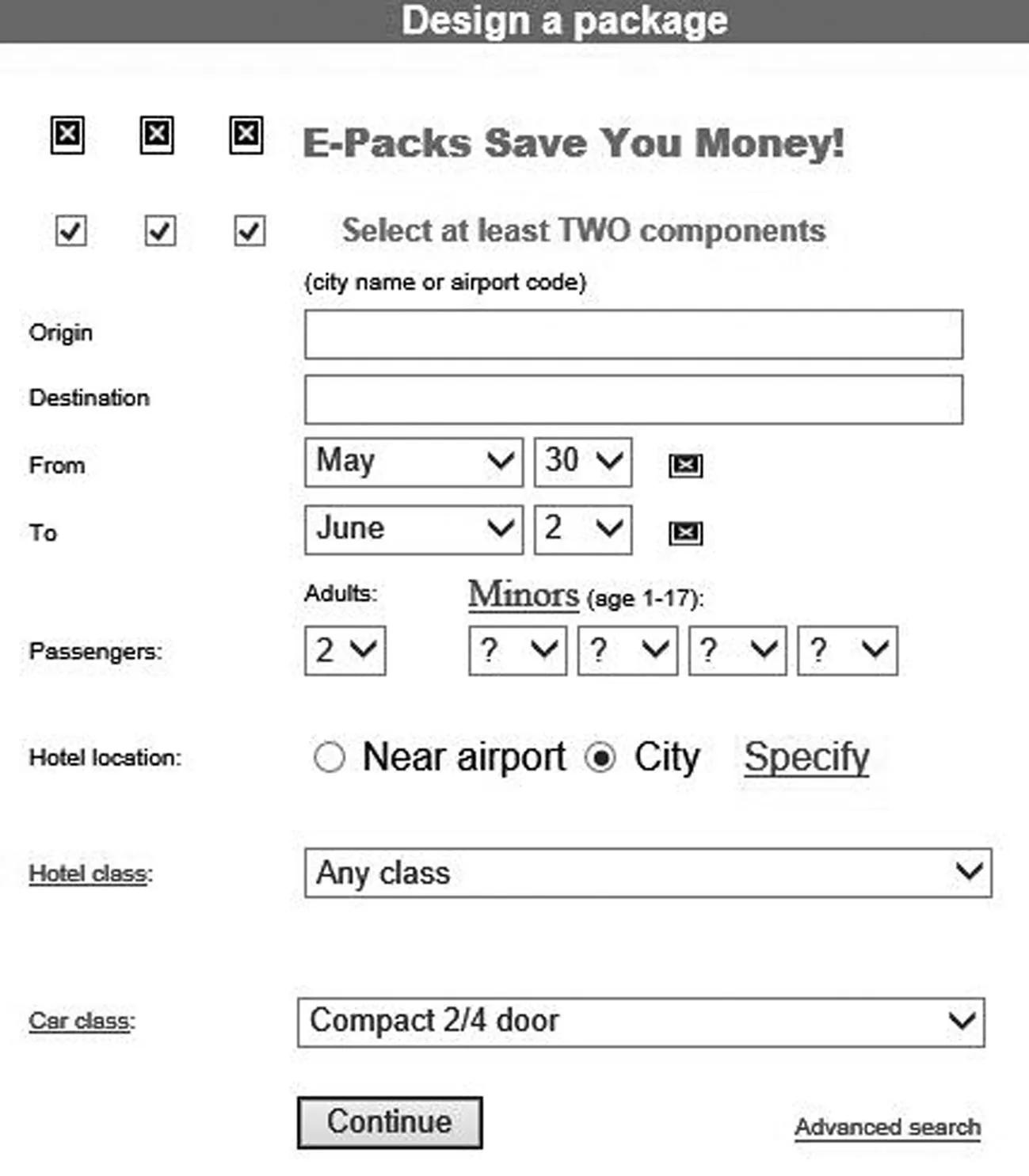
(b)Orbitz Flight中的查詢接口t1
(2)隨機選擇一個Books領域的查詢接口t,計算其和所有V(T)中的數據源名稱都不相似,因此采用KNN分類算法進行分,取k=3。我們通過IG方法選擇了10個分類特征屬性:
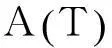
然后再構建特征向量空間模型VSM,對查詢接口進行向量化為di(i=1,2,…,20)。對于待分類接口t,也采用個同樣的方法進行向量化為d0。
d0={0,0,0,0,0,0.5,0,0.5,0.377964473,0}
則d0與di的相似度如表2所示。
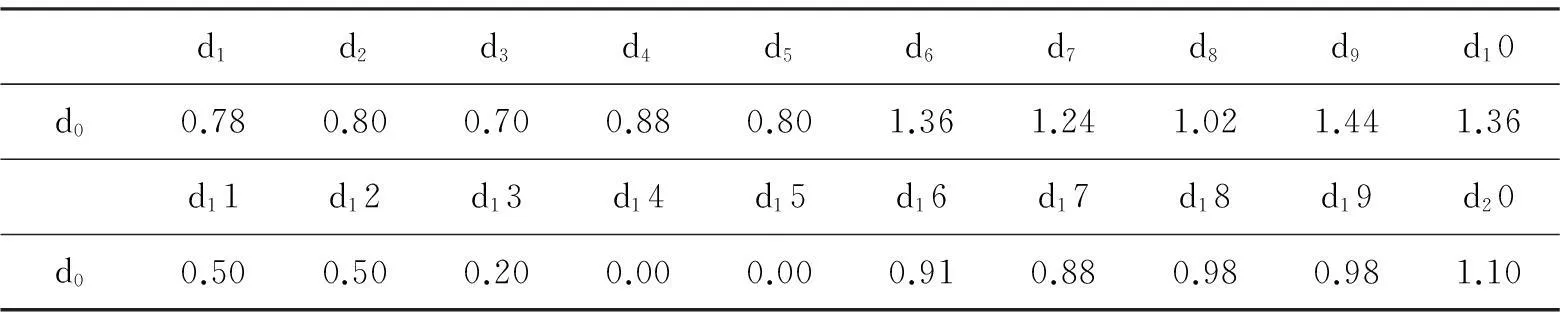
表2 dj與di的相似度
根據表2的相似度可獲得d0的3個近鄰為{d13,d14,d15};再根據類別權重的計算公式(4)計算類別權重,查詢接口t歸為c3。
5結束語
Deep Web數據查詢接口是實現Deep Web數據檢索的有效手段,擔由于Deep Web在線數據數量巨大,查詢接口也是紛繁多樣,為了實現數據的快速檢索,需要對多樣的查詢接口進行分類,使其能夠實現某個領域數據的快速定位和檢索,本文提出實現方案能夠結合數據源屬性的語義判斷,通過KNN算法有效地解決這一問題,提高 Deep Web在線數據庫的檢索效率。
參考文獻:
[1]BERGMAN M K. The Deep Web: surfacing hidden value[EB/OL].[2014-6-18].http://www.brightplanet.com/2012/06/the-deep-web-surfacing-hidden-value/.
[2]劉偉, 孟小峰, 孟衛一. Deep Web 數據集成研究綜述[J].計算機學報, 2007,30(9): 1475-1489.
[3]Liu Tantan,Wang Fan,Agrawal G.Instance discovery and schema matching with applications to biological Deep Web data integration[C].Washington,IEEE International Conference on Bioinformatics & Bioengineering,2010.
[4]曹慶皇, 鞠時光, 楊曉琴. 基于關聯挖掘和語義聚類的Deep Web復雜匹配方法[J].計算機應用研究,2009,26(12):4613-4616.
[5]Research on Deep Web Query InterfaceClustering Based on Hadoop[J].Journal of Software,2014, 9(12):3057-3062.
[6]WangYing; LiHuilai; ZuoWanli;et al.Ontology-Based Approach to Integrate Deep Web Query Interfaces[J]. Advanced Science Letters,2012(4):220-223.
[7]Zhang H,Berg AC, Maire M. Discriminative nearest neighbor classification for visual category recognition[C].Los Alamitos,CA,IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR′06),2006.
[8]George M, Christiane F. WordNet: An Electronic Lexical Database[M].Massachusetts:MIT Press,1998.
[9]Peter Harrington著,李銳,李鵬,曲亞東,等,譯.機器學習實戰[M].北京:人民郵電出版社,2013.
[10]范明,孟小峰,等,數據挖掘概念與技術[M].北京:機械工業出版社,2001.
[11]周由,戴牡紅.語義分析與TF-IDF方法相結合的新聞推薦技術[J].計算機科學,2013,40(11A):267-300.
責任編輯:程艷艷
Research on Query Interface Classification of Deep Web Based on XML Schema
GOU Heping, JING Yongxia, WU Duozhi
(Department of Information Technology, Qiongtai Normal University, Haikou 571100, China)
Abstract:Deep Web online database contains a lot of information, but their utilization is not high because of the difficult information retrieval. A query interface classification method based on XML Schema is proposed. XML Schema document of the data query interface is established, which realizes the first classification through the linguistic similarity of data source name; According to the label attribute of query interface, a vector space model is established to realize the vectorization of query interface, then KNN algorithm is used for secondary classification, which reduces the computing cost brought by KNN classification algorithm, improving the efficiency of Deep Web data retrieval.
Keywords:Deep Web; XML Schema; query interface; classification
中圖分類號:TP391
文獻標志碼:A
文章編號:1009-3907(2016)04-0013-06
作者簡介:茍和平(1978-),男,甘肅慶陽人,副教授,碩士,主要從事分布式計算、數據挖掘方面研究。
基金項目:海南省自然科學基金項目(20156241);海南省高等學校科學研究項目(Hnky2015-72);瓊臺師范高等專科學校科研項目(qtky201404)
收稿日期:2015-10-28