基于數據場的出租車軌跡熱點區域探測方法
2016-06-05 14:57:58周勍,秦昆,2*,陳一祥,李志鑫
地理與地理信息科學 2016年6期
周 勍,秦 昆,2*,陳 一 祥,李 志 鑫
(1.武漢大學遙感信息工程學院,湖北 武漢 430079;2.地球空間信息技術協同創新中心,湖北 武漢 430079;3.南京郵電大學地理與生物信息學院,江蘇 南京 210023)
基于數據場的出租車軌跡熱點區域探測方法
周 勍1,秦 昆1,2*,陳 一 祥3,李 志 鑫1
(1.武漢大學遙感信息工程學院,湖北 武漢 430079;2.地球空間信息技術協同創新中心,湖北 武漢 430079;3.南京郵電大學地理與生物信息學院,江蘇 南京 210023)
利用空間聚集模式探測方法可以從出租車軌跡中挖掘城市熱點區域,從而為城市規劃和交通管理提供支持。數據場借鑒物理學中場的理論,通過定量化計算數據對象間的相互作用,可分析空間數據的聚集模式。針對軌跡數據的特點,該文提出了一種利用數據場勢值閾值法探測軌跡點的聚集模式,從而提取城市熱點區域的方法。該方法首先在軌跡空間上劃分網格,將軌跡點映射在網格中,并利用數據場勢函數計算各網格單元的勢值,然后利用單一閾值或多閾值分割法提取城市熱點區域。以武漢市的出租車軌跡為例進行實驗,利用單峰直方圖閾值法進行高勢值區域篩選,得到軌跡聚集區域,從而提取城市熱點區域。且通過武漢市節假日與非節假日多時段的提取結果的對比分析,得到城市熱點區域的時空分布模式。進一步研究將該文方法擴展到時空聚集模式探測,以多角度分析城市熱點的時空動態變化。
出租車軌跡;空間聚集模式;數據場;閾值法;城市熱點探測
0 引言
不斷積累的出租車軌跡構成了蘊含人們出行模式和城市熱點等信息的地理時空大數據。通過對軌跡數據進行時空挖掘,可以分析居民出行的移動時空特征,同時識別熱點路徑和區域[1],從而為城市道路交通規劃和公共出行服務等方面提供輔助支持。
城市熱點是指城市中居民出入次數較多、交通流量較大的區域,是人們密集出行的體現[2,3]。利用空間聚集模式探測方法從軌跡數據中提取城市熱點區域已成為研究熱點。目前,進行熱點探測的方法主要有以G統計量方法為代表的局部空間自相關統計量方法[2,3]和空間掃描統計法[4-6]。其中,局部空間自相關統計量能揭示空間單元與其相鄰近的空間單元屬性特征值之間的相似性或相關性,可用于識別不同空間位置上可能存在的不同空間聚集模式。空間掃描統計采用移動窗口法,在研究區域內建立活動圓形窗口對數據進行掃描統計,通過所有位置在所有大小窗口中的最大對數似然比值探測最有可能存在聚集性的區域。但上述方法操作不夠靈活,對于數據量大的軌跡數據的計算效率不夠高,且對數據分析結果的空間可視化輔助手段不夠直觀。
受物理學中萬有引力的啟發,類比質點之間相互吸引的理論,數據場理論在數據空間中構造一個球形對稱的虛擬引力,位于其中的每個數據對象視為具有一定質量的粒子,且受到其他對象的聯合作用[7]。數據場理論已逐漸應用于相關領域,如圖像分割[8-10]、人臉識別[11]和土地定級[12,13]等。將數據場應用在軌跡數據提取熱點的分析中,既可發現任意形狀的聚集類簇,也可區分各聚集類簇所代表的熱點區域的熱度差別。趙鵬祥和秦昆等將數據場與決策圖理論相結合,并基于出租車上下車點進行了城市熱點區域識別[14,15]。但決策圖理論方法將每個軌跡點視為計算對象,其計算效率對于數據量大的軌跡數據集較低。本文將數據場與閾值法和網格法相結合,提出了一種軌跡數據集聚區域探測方法。該方法在出租車軌跡中劃分網格,并將軌跡點映射至各網格單元中。以網格單元為數據對象構造數據場空間,視網格單元為計算對象,以此降低計算成本,提高計算效率。再采用閾值分割法,對利用勢函數計算后的網格勢值進行篩選,提取出高勢值網格所覆蓋的區域,從而探測出武漢市的城市熱點區域,并分析其時空分布特征。
1 基本原理與方法
李德毅于2002年將場的概念引入數據挖掘領域,提出了數據場理論,這是一種利用物質粒子間的相互作用及其場描述方法刻畫抽象數域空間的理論[16]。類似物理場的矢量強度函數和標量勢函數描述,數據場理論引入勢函數形式化描述數據間多對一的作用關系。物理場中的等勢線或等勢面也被引入數據場勢值的可視化中,即通過對勢值結果構造勢表面以描述數據的分布[17]。
1.1 數據場主要理論
(1)數據對象輻射鄰域。對于數據對象p∈D的輻射鄰域NR(Pi)定義為以p為核心、R為輻射半徑的球體區域,如式(1)所示:
NR(p) = {p∈D|dist(p,q)≤R}
(1)
式中:D為數據集;dist(p,q)表示D中點p和q之間的距離。其中輻射半徑R定義為:
(2)

(2)勢函數。數據場中各對象間的影響關系可由勢函數得到的勢值來量化。給定空間Ω,勢函數需要滿足以下條件[8]:1)φ(x)是其定義域空間上的連續、光滑的有限函數,這個條件主要使得勢函數連續可導;2)φ(x)具有各同向性;3)φ(x)是對象O到場點x的距離的單值遞減函數,距離為0時,φ(x)達到最大值,距離趨于無窮大時,φ(x)→0。
數據場將勢值計算定義如下:已知空間Ω中任意一個數據對象y,其鄰域內包含n個數據對象X={x1,x2,…,xn},任一數據對象x對數據點y的輻射影響如式(3)所示;數據對象y的勢值即y受到鄰域內所有數據對象的影響總和,如式(4)所示。
(3)
(4)
式中:m表示數據對象x的質量,本文軌跡點的質量視為1,網格單元質量視為網格內所含軌跡點的質量總和;‖x-y‖表示點x與y之間的距離;影響因子σ∈(0,+∞),其含義與最優解中的σ一致;k∈N,為距離指數,本文中k值選為2。
(3)勢熵法確定最優σ。對于σ因子的確定,李德毅等[16]提出了一種利用勢熵來確定最優解的方法,通過計算勢熵來衡量勢場分布的合理性,最終選取勢熵最小的σ作為最優的影響因子。勢熵H的計算如式(5)所示:
(5)

1.2 軌跡點聚集模式探測方法
出租車軌跡數據中涵蓋著乘客的出行目的和移動模式。若某區域聚集的軌跡點越多,說明該區域對乘客的“吸引力”越大,且其相鄰一定范圍內的區域也會聚集著較多的乘客。這種區域對軌跡點的影響以及區域之間相互影響的現象符合數據場中數據質點相互“吸引”的假設理論,因此可用數據場中的勢函數來量化這種影響。若某區域具有較高勢值,便表明該區域聚集了較多的軌跡點,則可視為城市熱點區域。
因此,本文利用網格劃分法將軌跡數據進行區域單元劃分,然后基于數據場理論,提出了一種探測軌跡點聚集區域的方法。該方法定義了一個由n個軌跡點對象構成的軌跡數據空間P={p1,p2,…,pn},一個由l個類組成的類簇C=(c1,c2,…,cl)。
算法的具體描述如下:
輸入:數據集P={p1,p2,…,pn}。
輸出:熱點區域集合c1和非熱點區域集合c2,以及熱點區域個數NumHotspots和非熱點區域個數NumNonhot。
步驟1:劃分網格。以500 m×500 m為單元間隔,在軌跡數據空間上得到由s個網格單元構成的空間網格集合N=(N1,N2,…,Ns)。
步驟2:計算網格質量和質心。網格的質量可表明網格所在的區域單元對軌跡點的吸引力。假設落在網格單元Ni內的k個軌跡點集合為PNi={PNi1,PNi2,…,PNij,…,PNik},則該網格單元的質量MNi如式(6)所示。
(6)
式中:mPNij為網格Ni內的軌跡點PNij的質量。根據網格內的軌跡點,計算網格單元Ni的質心(XNi,YNi),如式(7)和式(8)所示。
(7)
(8)
步驟3:按式(2)篩選輻射范圍涵蓋Ni的網格點集合Qi。
步驟4:求解最優σ。首先任意選取幾組σ,根據Qi,分別計算各σ下各網格單元Ni的勢值。然后根據式(5)計算勢熵,最后以勢熵最小原則獲取優化的影響因子。
步驟5:根據最優σ計算各網格單元勢值。
步驟6:通過閾值分割熱點。Rosin提出一種基于單峰直方圖選取閾值的方法[18],即假設在直方圖的低值區域會有一個明顯的單峰。本文將該方法應用于勢值頻數直方圖中(圖1)。首先根據步驟5計算出的勢值繪制頻數直方圖,并將頻數峰值點與直方圖最右最低點連成直線;然后求取各直方圖頂點到該直線的距離。最后,根據最短距離所在的點確定閾值T。

圖1 勢值頻數單峰直方圖
除了上述自動計算單一閾值外,還可根據多段閾值分割方法對熱點程度進行分級,如等間隔劃分法(Equal Interval)、分位數分類法(Quantile)、標準差分類(Standard Deviation)和自然斷點分類(Natural Breaks)等方法。
步驟7:根據步驟6計算出的閾值T,將軌跡網格分為兩類,即熱點和非熱點。若采用多閾值分割法,則將軌跡網格分為多級熱點區域和非熱點區域。依次對每個網格點進行判定,若某網格點勢值φ(Ni)>T,則該網格所涵蓋的軌跡點為熱點,并將該點加入到相應的熱點集合中;反之,該數據點為非熱點,將其加入非熱點集合中。
步驟8:輸出探測結果數據集并結束。
2 實驗與分析
2.1 實驗數據
本文選擇武漢市2014年5月1日、7日和10日約2 500輛出租車的軌跡數據,分別代表節假日、工作日和周末3種狀態下的軌跡。其中,針對每天的數據選取8:00-9:00、12:00-13:00、18:00-19:00和23:00-0:00 4個時段進行分析,每個時段約含50多萬個軌跡點。
首先提取乘客上下車點。將車輛原始軌跡數據按照車輛ID和時間排序,“重車”和“空車”狀態改變的軌跡點即為上下車點。其中,從“空車”狀態變為“重車”狀態的點為上車點,反之為下車點。本文對上述各個時段的數據進行上下車點提取,每個時段包含30 000多個上下車點。由于武漢市面積較大,分布在郊區的上下車點數據較少,所以本文主要選取武漢市三環內的上下車點數據進行實驗分析。在上下車點數據空間中劃分500 m×500 m大小的網格單元,約得到3 000多個網格單元(圖2a),其中,包含軌跡點的網格約1 500個(圖2b)。

圖2 網格劃分示意
2.2 算法的實驗比較
如圖3所示,本文以2014年5月1日8:00武漢市三環內的出租車軌跡數據為實驗數據,分別利用基于數據場的軌跡點集聚區域提取方法和Getis-Ord G算法進行比較實驗,以驗證數據場方法的有效性。對于Getis-Ord G統計量的計算,本文將軌跡網格中各網格單元內的上下車點數量作為屬性觀察值,分析乘客上下車行為的高發區域,即城市熱點區域。兩種算法提取結果如圖4(彩圖見封3)所示。

圖3 實驗數據
如圖4a所示,Getis-Ord G統計量可識別高值的空間聚集(熱點區)和低值的空間聚集(冷點區)。對于基于數據場的軌跡點集聚區域提取方法,首先對軌跡網格數據進行勢值計算,再利用等勢線將計算結果可視化,以輔助熱點區域的初步分析。如圖4b所示,通過等勢線直觀的疏密情況可初步得到漢口區域和武昌火車站附近的熱點區域。該結果與Getis-Ord G統計量方法得到的熱點區域基本相符。

圖4 聚集區域探測結果對比
但是Getis-Ord G統計量的熱點區域探測結果范圍過大,不夠具體和直觀,而由于可以對勢值進行分析,因此基于數據場的軌跡點集聚區域提取方法對熱點區域的分析更加靈活(圖5,彩圖見封3)。如圖5a所示,數據場方法既可以通過自動計算單一閾值一次性得到勢值的高值聚集區和低值聚集區,又可以通過多閾值設置,分割出不同熱點程度的熱點區域。圖5b所示結果是利用考慮了數據分布統計特征的自然段點(Natural Breaks)方法進行的閾值劃分,從而得到4個級別的熱點區域,其中一級熱點區域為軌跡點最聚集的區域。此外,數據場勢值閾值分割后得到的熱點區域更為具體。可將熱點圖層與OpenStreetMap圖層疊加,將圖5b中的一級區域放大得到圖5c和圖5d,可知5月1日8:00的一級熱點網格所覆蓋的區域正是漢口火車站和武昌火車站及其周邊區域。因此,數據場閾值法對于從軌跡數據中挖掘城市熱點既有適用性,也有更靈活、更直觀的優勢。
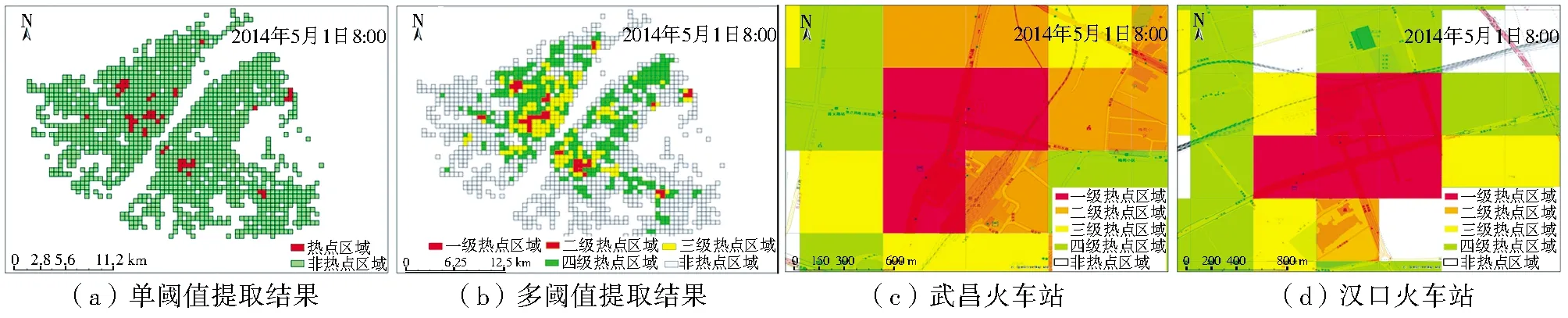
圖5 基于數據場的軌跡點集聚區域提取方法
2.3 武漢市熱點區域時空分析
利用基于數據場的軌跡點集聚區域提取方法對武漢市2014年5月1日、7日和10日的軌跡數據按時段進行聚集分析,選用單峰閾值法設定單一閾值提取熱點區域,并將提取結果與OpenStreetMap帶POI數據的底圖疊加,以更好地分析熱點網格所覆蓋的城市區域。早、晚高峰時段熱點分布如圖6、圖7所示(彩圖見封3),圖中紅色區域即為勢值高的熱點區域,綠色區域為非熱點區域。
為了更好地分析武漢市熱點區域的時空分布特點,本文根據武漢市城市功能區域特征,將熱點區域類型劃分為車站、休閑娛樂中心、住宅區、醫院、景點區和寫字樓辦公區域6類。從圖6可見,早上(8:00-9:00)的城市熱點區域主要分布在武漢市萬松街青松社區和友誼社區等大型住宅區和武漢市第一醫院等大型醫院附近;在工作日,該時段內分布在寫字樓辦公區的上下車點較多;在節假日,該時段的熱點區域還會分布在武昌火車站和漢口火車站。
中午(12:00-13:00)的城市熱點區域(圖略)在住宅區分布相對較少,而主要分布在武漢市光谷步行街和武漢國際廣場等集餐飲、購物、娛樂一體的大型商業休閑中心附近。在節假日和周末,市民出游導致中午時段的熱點區域分布在戶部巷、黃鶴樓等景點區附近。在工作日,景點區附近的上下車點較少,除了商業休閑中心之外,寫字樓辦公區附近會成為熱點。
從圖7可見,傍晚(18:00-19:00)的城市熱點區域主要分布在住宅區、寫字樓辦公區和休閑娛樂中心。因為在節假日時,該時段是市民就餐逛街的黃金時段,而在工作日時,該時段是市民下班返家高峰期。晚上(23:00-24:00)的熱點區域(圖略)主要分布在住宅區以及部分休閑娛樂中心,而醫院等區域相對較少。在這個時段內,只有酒吧等部分休閑娛樂場所在營業,結束夜生活的市民會在這些娛樂中心附近打車。在工作日,加夜班導致部分寫字樓辦公區域也會在該時段出現熱度不高的熱點區域。
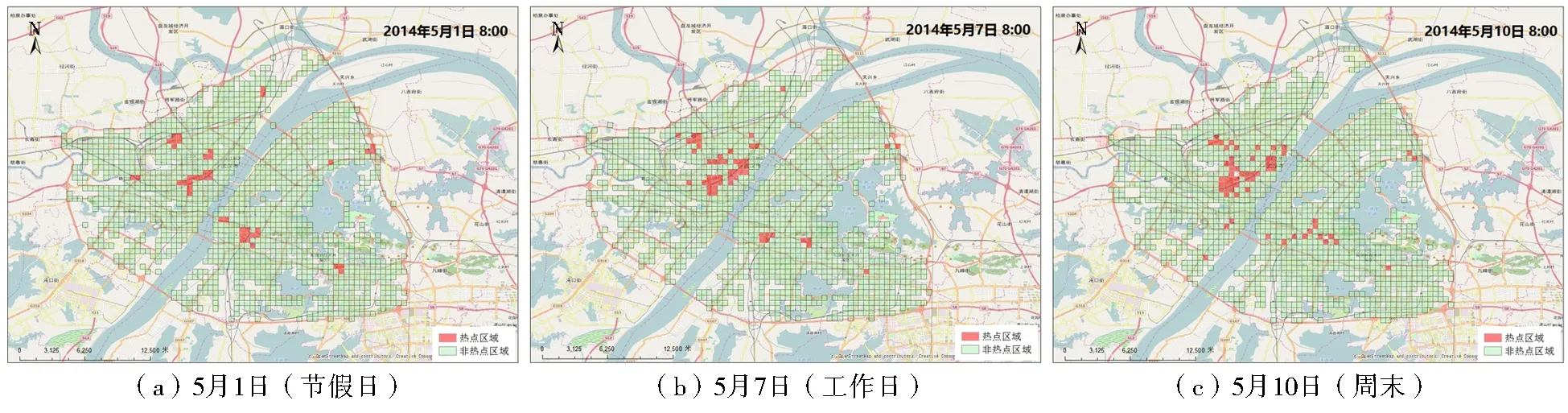
圖6 武漢市8:00熱點區域專題圖
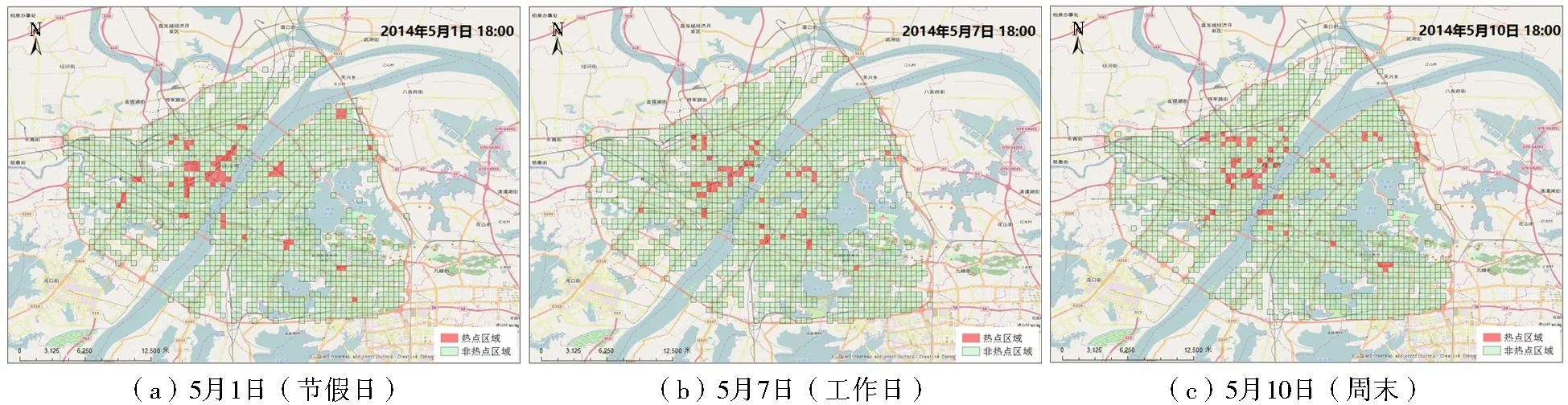
圖7 武漢市18:00熱點區域專題圖
綜上可見,武漢市熱點區域中,既有隨著時間變化分布的熱點區域,也有持續型熱點區域。變化型熱點區域有辦公區和大型醫院所在處,該熱點區域在工作日熱點數量會顯著增多,在節假日相對較少。這與辦公區一般只在工作日開放以及醫院部分科室節假日不上班等社會普遍現象相符。此外,戶部巷和司門口等景點區域和休閑娛樂區域也是變化型熱點區域,在節假日的熱點數量會比工作日多,這與市民多選擇在節假日和周末出游的現象相符。而武漢市的持續型熱點區域有大型社區聚集地和火車站區域。作為居住場所,社區是市民出發和返回的日常選擇點,常為熱點區域。武漢市作為全國交通樞紐,火車站客流量位于全國前列,因而火車站附近也為持續型熱點區域。
3 結論
本文提出一種基于數據場的軌跡點集聚區域提取方法,結合網格法對軌跡數據空間進行區域子單元劃分以提高運算效率,對于計算出的勢值,再采用閾值法對其進行分析。本文實驗中選用單峰直方圖選取單一閾值,將軌跡網格數據分為熱點與非熱點兩類,從而探測武漢市熱點區域。本文方法能夠有效探測出租車軌跡數據的集聚區域,挖掘更為具體的城市熱點區域。通過對2014年5月1日、7日和10日3天不同時段數據提取出的熱點進行對比分析,并與實地POI區域疊加,得到武漢市具有持續熱點的區域,如大型社區和火車站等;同時得到隨時間變化而變化的熱點區域,如辦公區域、大型醫院所在處以及景點區域。本文所使用的數據場閾值法還存在一些不足之處,如網格單元大小的劃分、閾值自動設定方法的多樣化等。后期將進一步基于數據場理論研究出租車軌跡的高效聚類以及出租車軌跡數據中的停留點等特征點的聚類。
[1] 馬云飛.基于出租車軌跡點的居民出行熱點區域與時空特征研究[D].南京:南京師范大學,2014.
[2] 陳一祥,秦昆,馮霞.一種使用局部空間統計量的高分辨率影像顯著結構提取方法[J].武漢大學學報(信息科學版),2014,39(5):531-535.
[3] 王培安,羅衛華,白永平.基于空間自相關和時空掃描統計量的聚集比較分析[J].人文地理,2012,27(2):119-127.
[4] 馬越,李曉松,張彥利.掃描統計量在傳染病監測應用中的空間尺度選擇[J].現代預防醫學,2011,38(9):1601-1604.
[5] 唐咸艷,仇小強,黃天壬,等.空間掃描統計在廣西肝癌空間格局中的應用研究[J].中國衛生統計,2009(2):114-116.
[6] 李小洲,王勁峰.空間掃描統計量方法中候選聚集區域生成的快速算法[J].地球信息科學學報,2013,15(4):505-511.
[7] 淦文燕,李德毅,王建民.一種基于數據場的層次聚類方法[J].電子學報,2006,34(2):258-262.
[8] WU T,QIN K.Data field-based mechanism for three-dimensional thresholding[J].Neurocomputing,2012,97:278-296.
[9] WU T,QIN K.Image data field for homogeneous region based segmentation[J].Computers & Electrical Engineering,2012,38(2):459-470.
[10] 吳濤,秦昆.利用云模型和數據場的圖像分割方法[J].模式識別與人工智能,2012(3):397-405.
[11] 王樹良,鄒珊珊,操保華,等.利用數據場的表情臉識別方法[J].武漢大學學報(信息科學版),2010,35(6):738-742.
[12] 韓元利,王海軍,夏文芳.基于k階數據場的城鎮土地定級模型[J].武漢大學學報(信息科學版),2009,34(3):370-373.
[13] 劉耀林,唐旭,何建華.基于數據場的空間分析技術及其在土地定級中的應用[J].武漢大學學報(信息科學版),2009,34(9):1009-1013.
[14] ZHAO P X,QIN K,YE X,et al.A trajectory clustering approach based on decision graph and data field for detecting hotspots[J].International Journal of Geographical Information Science,2016(1):1-27.
[15] ZHAO P X,QIN K,ZHOU Q,et al.Detecting hotspots from taxi trajectory data using spatial cluster analysis[A].ISPRS Annals of Photogrammetry,Remote Sensing and Spatial Information Sciences[C].2015,2(4):131-135.
[16] 李德毅,劉常昱,杜鹢,等.不確定性人工智能[J].軟件學報,2004,15(11):1583-1594.
[17] 趙衛偉.數據場聚類及其實現[D].南京:中國人民解放軍理工大學,2003.
[18] ROSIN P L.Unimodal thresholding[J].Pattern Recognition,2001,34(11):2083-2096.
Hotspots Detection from Taxi Trajectory Data Based on Data Field Clustering
ZHOU Qing1,QIN Kun1,2,CHEN Yi-xiang3,LI Zhi-xin1
(1.SchoolofRemoteSensingandInformationEngineering,WuhanUniversity,Wuhan430079;2.CollaborativeInnovationCenterofGeospatialTechnology,WuhanUniversity,Wuhan430079;3.CollegeofGeographicandBiologicInformation,NanjingUniversityofPostandTelecommunications,Nanjing210023,China)
The taxi trajectory data contains abundant information about urban functions,city structures and citizen activities.Analyzing spatial aggregation pattern of taxi trajectory data can detect some different distributions of urban function areas like city hotspots,traffic jam areas and so on,which can support urban planning and management.Referring to the field theory from physics,data field theory analyzes spatial aggregation pattern by quantifying the interaction among data objects.This paper proposes a method to extract city hotspots area which combines the data field theory and the threshold segmentation.Firstly,the grids are divided over the trajectory space in the method,and trajectory points are mapped to each grid cell.And then,the potential value of each grid is calculated based on potential function.After that,the threshold classification method which includes the single threshold method and multiple threshold method,is used to divide the grid data into hotspots area and non-hotspots area.Based on the data field detecting method and unimodal thresholding classification method,the paper finishes the trajectory data analysis in Wuhan City and obtains the characteristics of spatio-temporal distribution of hotspots at the different times of a day during the holiday and non-holiday.Further study will focus on extending the data field theory to the spatio-temporal level,and analyzing the dynamic change of city hotspots area at multi-perspective.
taxi trajectory data;spatial aggregation pattern;data field;threshold;detection of hotspots
2016-09-02;
2016-10-23
國家自然科學基金項目(41471326);中央高校基本科研業務費專項資金項目(2042015kf0183)
周勍(1991-),女,碩士研究生,研究方向為空間數據分析與挖掘。*通訊作者E-mail:qink@whu.edu.cn
10.3969/j.issn.1672-0504.2016.06.009
U491.1
A
1672-0504(2016)06-0051-06
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
