基于GPU的信息融合并行方法研究*
2016-06-30 07:06:47張興浦陳世友
艦船電子工程 2016年6期
鄧 婕 張興浦 陳世友
(1.武漢數(shù)字工程研究所 武漢 430205)(2.海軍海南地區(qū)裝備修理監(jiān)修室 三亞 572018)
基于GPU的信息融合并行方法研究*
鄧婕1張興浦2陳世友1
(1.武漢數(shù)字工程研究所武漢430205)(2.海軍海南地區(qū)裝備修理監(jiān)修室三亞572018)
摘要針對多傳感器信息融合處理時延大和高實時性要求之間的矛盾,提出一種基于GPU的并行計算方法,并針對并行方法進行了模擬仿真。實驗結果表明,GPU并行方法適用于信息融合技術,為解決融合算法耗時大的問題提供了一種新思路。
關鍵詞信息融合; 并行計算; GPU; CUDA
Class NumberTP391
1引言
多傳感器信息融合可以通過綜合處理多個傳感器的信息來獲取單個傳感器無法取到的信息,降低檢測對象的不確定性,并減少干擾造成的影響,提高判斷和決策的準確度和可信度。然而因為現(xiàn)有算法的高復雜性,導致隨著傳感器數(shù)量的增加,數(shù)據(jù)源增多導致數(shù)據(jù)量增大,以及信息表現(xiàn)形式的多種多樣、信息間關系復雜性的增加,導致信息融合過程在目標密集環(huán)境下耗時呈指數(shù)增長。然而嵌入式系統(tǒng)對信息融合處理過程的實時性要求非常高,因此需要一種有效的方法將多傳感器處理過程并行化,通過充分協(xié)調計算機性能來解決高實時性和大任務量之間的矛盾。
在信息融合領域,已有大量關于并行計算方法的研究,如國外的Pankaj[1]、國內的丁龍[2]和夏學知[4]等都想到了利用群機進行任務分配的并行方法;Davis PB等就提出了基于超立方體多處理器的并行數(shù)據(jù)融合算法[4];郭強從融合模塊角度提出了基于卡爾曼濾波的數(shù)據(jù)融合算法[5],丁龍等[6]和周樂儒等[7]均提出了用于輻射源識別的并行系統(tǒng)。而萬文福[8]、何勇[9]和施炎龍[10]等還嘗試了多種單機并行算法的設計和實現(xiàn),并取得了良好的結果。在上述各情況中,程序數(shù)據(jù)都存儲在內存中,直接由CPU讀取并由CPU程序調度執(zhí)行,最后由CPU返回運行結果。本文提出一種基于GPU的程序并行方法,將程序數(shù)據(jù)存儲在GPU顯存中,并由GPU程序讀取和調度。
CPU由于其體系結構限制,大部分片上資源都用于控制和緩存,導致實際計算單元非常有限,無法滿足各種應用日益增多的需求。GPU進行大規(guī)模集成運算的能力以及存儲器帶寬都要比CPU強很多,再加上通用計算技術的飛速發(fā)展,使GPU從最初的只能單純進行圖像的渲染和輸出工作轉化為可對很多領域的計算進行處理。英偉達公司提出來統(tǒng)一并行通用計算架構(Compute Unified Device Architecture, CUDA),這一架構作為GPU的編程平臺支持類似C語言的軟件開發(fā)語言,并支持CPU和GPU協(xié)同工作,其中CPU負責串行計算,GPU負責并行計算并由CPU進行調度工作。
本文針對現(xiàn)有信息融合系統(tǒng)結構的特點,結合GPU并行編程方法,設計出一種適用于CPU、GPU多層次多線程并行計算的方法,并進行了仿真實驗。
2算法架構流程
常用的信息融合系統(tǒng)數(shù)據(jù)處理過程都是單線程模型,線程在程序的生命周期內不斷循環(huán),具體流程如圖1所示。

圖1 單線程循環(huán)流程圖
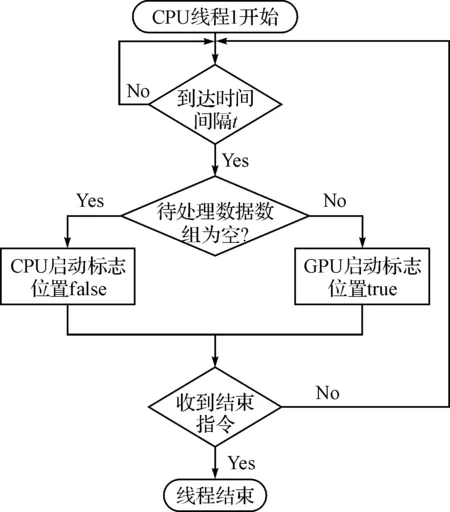
并行后的流程如圖2,系統(tǒng)設置一個時間間隔t和兩個CPU線程,采用流水線方式,CPU線程1將t秒內收到的數(shù)據(jù)存入數(shù)組,t秒達到后由CPU線程2轉移到GPU,然后在下一個t秒內,線程1繼續(xù)進行數(shù)據(jù)收集,而線程2啟動N個GPU線程同步進行數(shù)據(jù)處理,這樣實現(xiàn)了CPU與GPU的并行工作。而在GPU上,采用最簡單的線程分配方法,即每個數(shù)據(jù)分配一個線程進行處理,實現(xiàn)了GPU上多線程的并行,因而實現(xiàn)了CPU、GPU多層并行。圖3是CUDA程序執(zhí)行流程圖,由于GPU受CPU調度控制,因此CPU稱為主機端,GPU稱為設備端。CUDA程序由主機端串行程序和設備端并行函數(shù)(稱為Kernel函數(shù))組成,串行程序會進行數(shù)據(jù)的準備和GPU線程啟動前各項環(huán)境的準備,準備好后調用Kernel函數(shù),并在調用時指明調用的線程個數(shù)。
每一次GPU并行計算的過程,都包括主機端準備、主機端調用設備端、設備端執(zhí)行和設備端返回結果四個階段,一個CUDA程序中可以包含多次GPU并行過程,如圖3中就指示了至少兩次并行過程。
3實現(xiàn)方法
基于圖2所設計的算法流程圖,結合圖3說明的CUDA程序執(zhí)行流程圖,進行實驗的模擬和仿真。實驗中沒有進行完整融合流程的并行,而是挑選了預處理模塊進行并行,即簡化了圖2中GPU線程的工作,進行了如圖4的流程模擬。因為對圖1原始融合過程進行計算時間的分析后發(fā)現(xiàn),每次循環(huán)內,預處理模塊花費的時間約占時間的70%,因此選用這個最具有代表性的模塊進行了實驗。
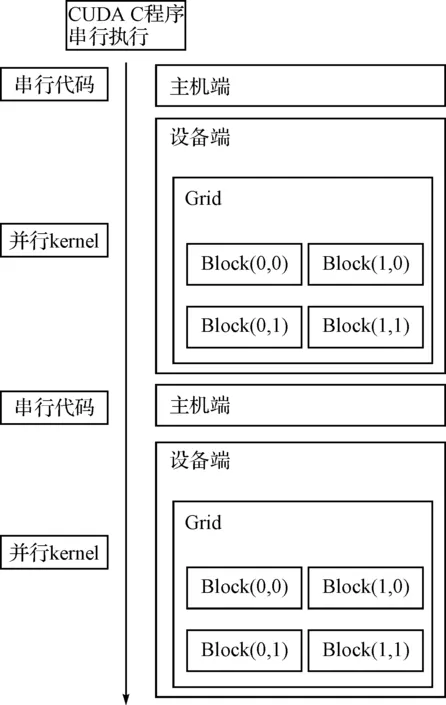
圖3 CUDA程序執(zhí)行流程圖

圖4 CUDA程序執(zhí)行流程圖
3.1實驗環(huán)境
CUDA環(huán)境主要分為:硬件、操作系統(tǒng)、C/C++編譯器和CUDA工具包。硬件主要是指GPU設備,必須是支持CUDA的GPU。實驗項目中使用的是英偉達顯卡GTX970,CPU端使用8核處理器和8GB內存;操作系統(tǒng)為Windows 7專業(yè)版,64位操作系統(tǒng);編譯器為Visual Studio 2010旗艦版。CUDA工具包需要在操作系統(tǒng)和編譯器都安裝完畢后才能安裝,安裝過程中會自動生成對應編譯器插件。
3.2時間結果
選取兩組模擬數(shù)據(jù)進行并行,選取時間間隔t為1s,在保證計算結果正確的前提下,挑選部分時間結果見下表1、表2,表格中第一行為編號;第二行為某一秒并行的數(shù)據(jù)個數(shù),第三行列出當秒內數(shù)據(jù)GPU計算所花的真正時間。
3.3性能分析
因為不同數(shù)據(jù)會采取不同的預操作,所以表中時間波動屬于正常范圍。由表可知,在每個時間間隔1s內,GPU真正計算時間花費最多的約為0.1s,最少的不到0.01s,完全符合期望的流水線計算。
然而算法中,時間間隔t的選擇有一定的局限性。因為多個GPU線程并行執(zhí)行時,沒有考慮線程間數(shù)據(jù)相關聯(lián)的問題,所以一定要保證t時間內的數(shù)據(jù)相互獨立。如果t的選擇太小,會導致每次并行數(shù)據(jù)太少,GPU利用率太低;如果t的選擇太大,會導致采集到的數(shù)據(jù)屬于同一條航跡,影響融合結果的正確性。實驗中的1s是在保證了數(shù)據(jù)間獨立的情況下能取到的最大時間間隔,每秒最多收集到四個數(shù)據(jù)即每次最多并行四個數(shù)據(jù),而GTX970有1664個核,使用率還不到0.5%,所以算法可用于更復雜的融合環(huán)境,能保證在相同的時間內擁有更高的GPU的利用率。

表1 并行后處理數(shù)據(jù)一時間

表2 并行后處理數(shù)據(jù)二時間
4結語
本文設計了一種基于GPU的并行信息融合方法,提出了CPU和GPU多層并行融合的算法思想,并進行了實驗驗證,證明了結果的正確性,并行效率滿足常用融合環(huán)境需求。介紹了算法對于時間間隔參數(shù)選擇的局限性,并說明了如何選擇參數(shù)來保證高效和正確的計算結果,為解決信息融合過程時延大的問題提供了一種友好的解決方案。
參 考 文 獻
[1] Pankaj Gupta, Guru Prasad. A scalable portable object oriented framework for parallel multisensor data-fusion applications in HPC systems[J].Proc. of the SPIE,2004,5434:295-306.
[2] 丁龍,王寶樹,喬向東等.基于群機并行的數(shù)據(jù)融合算法設計與實現(xiàn)[J].計算機工程與應用,2001,37(19):92-94.
[3] 夏學知,涂葵.多傳感器數(shù)據(jù)融合并行處理技術[J].計算機應用,2005,25(8):1814-1817.
[4] Davis PB, Cate D, Abidi MA. Parrallel Data Fusion on a Hypercube Multiprocessor[J]. Processing of SPIE Conference on Sensor Fusion,1990,1383(11):515-529.
[5] Guo Q, Yu SN. The multisensory data fusion parallel algorithm based on Kalman filtering[C]// Computational Electromagnetics amd Its Application 2004. Proceedings. ICCEA 2004. 2004 3rd International Coference on. IEEE,2004:573-576.
[6] 丁龍,王寶樹,喬向東,等.基于群機并行的數(shù)據(jù)融合算法設計與實現(xiàn)[J].計算機工程與應用,2001,37(19):92-94.
[7] 周樂儒.數(shù)據(jù)融合系統(tǒng)中并行目標識別的研究與實現(xiàn)[J].計算機工程,2006,32(5):189-191.
[8] 萬文福.基于PVM的數(shù)據(jù)融合并行任務調度[J].艦船電子工程,2006,26(3):5-12.
[9] 何勇,張必銀.多傳感器數(shù)據(jù)融合并行處理方法研究[J].艦船電子工程,2011,31(8):56-59.
[10] 施巖龍,王雪,陸小科.面向多雷達數(shù)據(jù)融合的并行數(shù)據(jù)編排框架研究[J].現(xiàn)代雷達,2015,37(10):39-42.
Parallel Method Techniques for Information Fusion Based on GPU
DENG Jie1ZHANG Xingpu2CHEN Shiyou1
(1.Wuhan Digital Engineering Institute, Wuhan430205)(2.Navy Supervision Office for Equipment Repair in Hainan Area, Sanya572018)
AbstractIn order to solve the contradiction between large-time delay and high real-time requirement of multi sensor information fusion, A parallel method based on GPU is proposed and simulated. The result of simulation shows that the method is effective, which provides new mentality to solve the large time-cosuming of information fusion algorithm.
Key Wordsinformation fusion, parallel computing, GPU, CUDA
*收稿日期:2015年12月4日,修回日期:2016年1月19日
作者簡介:鄧婕,女,碩士研究生,研究方向:信息融合技術。張興浦,男,碩士研究生,高級工程師,研究方向:電子與信息工程。陳世友,男,博士,研究員,研究方向:信息融合技術、信息系統(tǒng)技術。
中圖分類號TP391
DOI:10.3969/j.issn.1672-9730.2016.06.010
