一種基于加權LDA模型的文本聚類方法
2016-07-05 02:00:46張春杰張志遠
中國民航大學學報 2016年2期
關鍵詞:數據挖掘
李 國,張春杰,張志遠
(中國民航大學a.計算機科學與技術學院;b.中國民航信息技術科研基地,天津 300300)
?
一種基于加權LDA模型的文本聚類方法
李國a,b,張春杰a,b,張志遠a,b
(中國民航大學a.計算機科學與技術學院;b.中國民航信息技術科研基地,天津300300)
摘要:針對傳統聚類算法在處理大規模和高維文本聚類時存在的不足和局限性,提出了新的以LDA(latent dirichlet allocation)模型為基礎的聚類方法。通過LDA主題模型挖掘得到文本之中的潛在主題分布以及不同主題內的詞語分布,分別計算文本在“文本-主題”特征空間和“主題-詞語”特征空間的相似度,然后對兩者線性加權,獲得最終的文本相似度。利用經典的K-Means算法,在中英文語料庫上進行的實驗表明,與單純地利用VSM結合K-Means相比,具有較好的聚類效果。
關鍵詞:LDA;向量空間模型;數據挖掘;文本聚類;K-Means
伴隨著互聯網近年來飛快的發展,圖書期刊、企業和個人信息、政府報告、多媒體資源和社會新聞等數據的規模都在快速膨脹,而以上這些內容的基本呈現方式,大都是非結構化的文本。由于這些文本信息發布的類別和渠道非常龐雜,人們想要在其中快速準確地獲取有效的信息變得十分困難,在花費了大量的時間和精力后往往也只是事倍功半。如何從這些海量文本中準確高效地獲取人們真正想要得到的有用信息已成為目前迫切需要解決的問題。作為一種無監督機器學習方法,文本聚類算法已在文本自動整理、數字圖書館服務和檢索結果的組織等方面獲得了比較廣泛的應用。因為事先不用對這些文本進行類別的手工標記,也無需訓練過程,所以在文本的處理方面具有較高的簡便靈活性,也日趨受到研究人員越來越多的關注。
在傳統的文本聚類中,應用最廣泛的文本模型當屬向量空間模型(vector space model,VSM)。該模型是由Salton等[1]于1969年提出來的,其采用文本中的詞作為特征項,將文本集構造成一個高維、稀疏的文本-詞語矩陣。但是VSM模型將詞語僅當成一個標量,忽視了其在文本中的內在含義,無法辨別同義和多義詞。但在計算文本相似度時,同義詞和多義詞具有相當重要的作用。另外,由于文本和詞語數量通常都特別巨大,直接采用VSM模型產生的矩陣不僅維度高且極度稀疏,計算效率較低,因此在聚類之前通常需要對文本-詞語矩陣進行降維操作[2]。目前高維矩陣的降維有多種方法,如概念索引(concept indexing,CI)、基于矩陣奇異值分解理論的隱含語義分析(latent semantic analysis,LSA)[3],以及多元統計分析理論中的主成分分析(principal component analysis,PCA)等[4]。特征提取也是一種有效的降維方式,常用方法包括信息增益(information gain,IG)、卡方(chi-square,CS)、術語強度(term strength,TS)及互信息(mutual information,MI)等[5]。上面所介紹的算法都是基于大規模語料的,在統計學基礎之上得到對文本類別具有較大作用的特征項,但是在特征選擇過程中都沒有考慮非結構化文本數據中的潛在主題信息,沒有從詞語的語義角度對文本所要選擇的特征進行分析,因此在聚類效果上依然不是特別好。
近年來,一些學者開始研究利用LDA進行降維并將其應用于文本聚類中。鄭誠等[6]使用LDA中的主題分布作為特征項,由于選取的特征項過少,在計算文本相似度時必然會丟失大量有效信息,對文本的區分力度也明顯不夠。王振振等[7]使用不同主題內詞語的分布作為特征項,由于未考慮文本-主題之間的關系,對文本的區分度也存在一定影響。針對上述方法存在的缺陷,本文的特征選擇是基于LDA主題模型,利用建模之后的“主題-詞語”分布和“文本-主題”分布作為特征選擇的結果,發掘出文本之中潛在的主題信息,將文本用主題表示,將文本中的詞語映射到主題之中,分別計算文本在“文本-主題”特征空間和“主題-詞語”特征空間的相似度,然后對其進行線性加權,得到最終的相似度結果。使用該方法,在文本聚類時能有效降低文本表示的維度,同時又能解決同義和多義詞的問題。在中英文語料上進行的聚類實驗表明,較其他聚類算法,本文所提算法的聚類結果更好。
1 研究與方法
1.1LDA概率主題模型
主題是一個較抽象的概念,表達了文本中的一種潛在主旨,一般采用詞語相應于主題的條件概率分布描述。詞語與主題關系越密切,條件概率就越大,相反的話就越小。概率主題模型通過統計文本中詞的概率分布,確定每個詞語在相應主題的概率,最終將文檔表示成不同概率的主題集合。
作為概率主題模型的前身,潛在語義分析(LSA)提出了語義維度,打破了以VSM為主導的單純以詞頻作為文本表示的模式,實現了文本在低維空間上的隱含語義表示。其通過奇異值分解(singular value decomposition,SVD)構造一個新的隱形語義空間。它把非結構化的文本量化為將詞語作為向量空間維度中的一個點,假設在此空間之中的文本都包含特定的語義,且并非無規律分布。自然語言的文本是由一個個詞語構成的,這些詞語又是在相應的文本當中去理解它們的真實含義,因此這里體現了一種“詞語-文本”的雙重關系。但LSA在處理同義詞問題上效果仍然不是很理想,且由于SVD的計算時間較長,算法效率方面往往無法保證。另外,在最終的結果矩陣中存在結果在很多維度上是負數,對此并無相應的物理解釋。20世紀90年代后期,Hofmann等[8]在LSA的基礎上提出了概率潛在語義分析(probabilistic latent semantic analysis,PLSA)算法,與LSA有著類似的思想,在PLSA模型中同樣也加入了一個隱含的變量層,但其是以概率的形式來說明LSA的問題,大致思想是把文本和詞語同等對待,將語料庫中的每一篇文本和詞語映射成一個維度不高的語義空間中的一個點。經過這一處理,既可以解決矩陣維度過高的難題,又可以將文本中詞語和詞語間的內在聯系構建出來,而且在該語義空間上幾何距離越接近的詞語,它們的語義也就越接近,它在一定程度上可以緩解文本模型中“一詞多義”的問題。但PLSA最大的缺點就是其在文本層缺少了數學中的概率模型,使得算法過程中的參數數量會隨著文本數量的增多而增加,很容易出現過度擬合的問題。Blei等[9]通過引入狄利克雷先驗分布擴展了PLSA模型,克服了PLSA在文本表示時的種種不足,即LDA概率主題模型。
在LDA概率主題模型中,首先需介紹“文本集”、“文本”和“詞語”的概念,以此表示文本類的數據,其定義如下:
1)詞語數據集中的基本單位,可以由數據集中的詞表序列{1,2,…,V}選取,用w表示,并且w∈{1,2,…,V}。
2)文本由N個詞語所構成的組合,用w表示,其表達式是w =(w1,w2,…,wn),這里wn指的是文本之中的第n個詞語。
3)文本集由M篇文本所構成的文本語料庫,這里用D表示,其表達式是D =(w1,w2,…,wm),其中wm指的是文本集之中的第m篇文本。
LDA的主要思想是把文本集中的每一篇文本表示成主題這一變量的分布,對于每一個潛在主題,則利用詞語的概率分布來表示。這里,Blei有著如下的假設:①狄利克雷分布的維數和文本集之中主題的數量一致,這個K是固定和已知的;②文本中主題與詞語上的概率用參數矩陣β來表示,這其中每個元素代表的是主題zi于詞語wj上的概率(在文中,變量的下標表示的是這個變量在文本集之中的序號,變量的上標代表的是這個變量的取值范圍或值,如這里的zi代表的是主題z的值是i),而且這個參數也是固定的。
依據上面的假設,可以得到文本主題的分布參數θ、文本d中主題z和Nd個詞語w在已給定參數α和β的情況下的聯合分布概率為

對式(1)在θ上求積分并且在主題z上求和,可得到邊緣概率分布如下
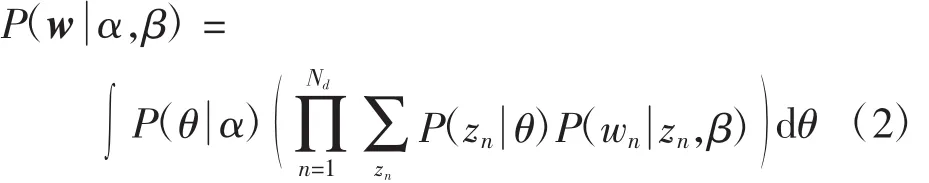
利用式(2)可求得文本集之中所有文本的邊緣分布概率,進而求得文本集D的概率分布為
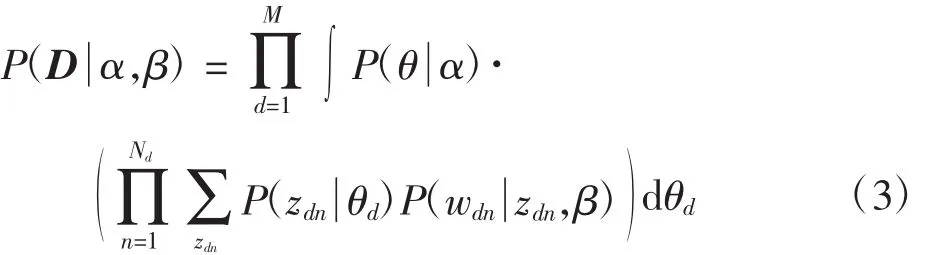
圖1是LDA的概率圖模型,從中可知LDA是一個三層模型:參數α和β都是文本集層的參數,只有等所有文本集都生成完成后才會更新一次;變量θ指的是文本層的變量,當每一篇文本生成結束之后就會更新;而變量z和w都是詞語層的變量,每個詞語的生成就表示它們要更新一次。
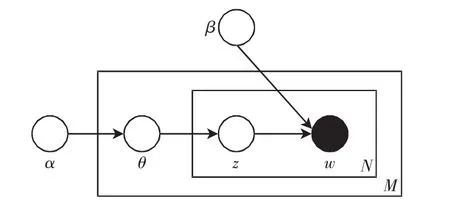
圖1 LDA概率圖模型Fig.1 Probability graph model of LDA
因為上式含有多個隱變量,直接通過推導求出會十分困難,因此需要得到其近似解。本文選用更好的Gibbs抽樣來求解參數,下面詳細介紹Gibbs抽樣算法。
1.2Gibbs抽樣
按照Blei在LDA模型中的假設,Dirichlet分布的參數α和主題分布的參數β在文本的生成過程中是固定值,所以針對某一個文本d而言,其隱含變量后驗概率分布為
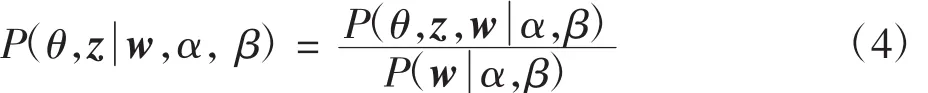
在此,按照貝葉斯理論可得到

這里P(z)只與參數θ相關,而P(w z)只與參數φ相關,所以在參數θ和φ上分別積分,得到
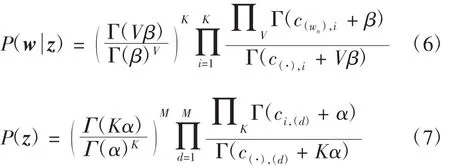
其中:c(·),i表示文本中的所有詞語屬于主題i的數量;表示所有文本集中詞語wn屬于主題i的數量;c(·),(d)表示當前d中全部主題出現的數量;ci,(d)表示當前d中主題i出現的次數。然而式(4)中的P(α,β)仍然不能求得,它與文本集中全部詞語的主題分布情況相關。
故可把文本集中的全部詞語視作離散的變量空間,這其中每個變量的狀態可從主題集合中選取,進而構建了馬爾可夫鏈,再依據P(θ,φw,α,β)對所有的變量采樣,在馬爾可夫鏈穩定后,對其中的所有變量狀態進行統計,可根據最終的統計量來估計目標概率的分布。
在更新鏈的狀態時,可以采用Gibbs抽樣方法[10],這里需計算P(z-n, w)。針對文本d中的第n個位置上的詞語,其條件概率分布為
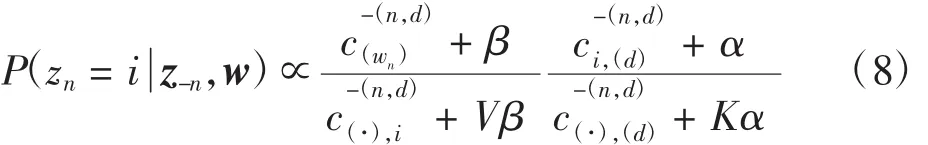
其中:i表示主題的編號,i∈{1,2,…,K};統計量c的下標表示此統計量之中樣本的條件,上標指的是此統計量之中樣本的范圍;(·)代表在對應維度上的元素全集;-(x)表示在對應維度上取x的補集,所以這里的表示除了第d篇文本之中第n個位置的詞語所屬于的主題之外,文本集中剩余詞語被賦予主題i的數量,其余統計量的定義與此類似。這里,式(8)的前半部分表示的是詞語wn從屬于主題i的概率,后半部分表示的是文本d中主題i的概率。這兩部分分別對應于本文所論述的“主題-詞語”分布和“文本-主題”分布。
詳細采樣過程如下:
2)按照均勻分布,在[0,1]之中隨機選取一個值P 且0<P≤1;
3)按照P在P(i)上屬于的變量值當做新的主題。
而Gibbs采樣的更新步驟如下:
1)初始化馬爾可夫鏈的初始狀態zi,其取值范圍是{1,2,…,K};
2)按照式(8)的概率分布更新所有zi;
3)多次迭代后,當馬氏鏈穩定之后,這時的目標分布達到收斂,此刻zi的取值就是最終分布的隨機變量的樣本。
利用這時的zi估算LDA中的參數,其表達式為
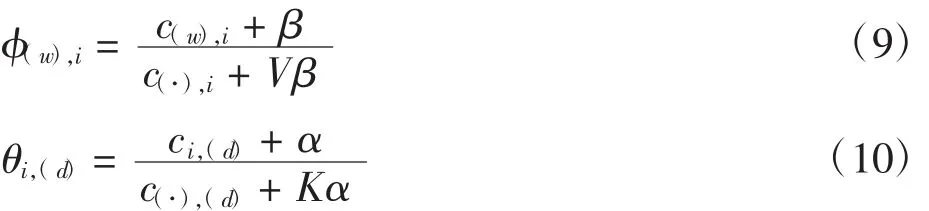
通過這些參數,可以預測新文本中詞語w在已有w和z的前提下對應的主題z和它的后驗分布。
1.3加權LDA的文本建模
1.3.1語料選擇
為驗證算法的有效性,本文分別在中文和英文語料集合上對算法進行了試驗。其中,英文語料使用的是20-News-Group語料庫,特別選取了其中的10個類:comp.graphics,comp.sys.ibm.pc.hardware,motorcycles,rec.sport.baseball,rec.sport.hockey,sci.electronics,sci. med,sci.space,soc.religion,talk.politics.guns。每個子類分別取500篇文檔,共5 000篇。中文語料使用的是復旦大學中文語料庫,選取了其中的10個子類:Agriculture,History,Space,Sports,Politics,Environment,Economy,Computer,Education,Law。每個子類選取了100篇文本,一共1 000篇。
1.3.2LDA主題數的選擇
主題數目K的確定對于LDA模型的準確率至關重要。通過LDA的建模過程可知,多項分布θ和φ的狄利克雷先驗分布的參數分別對應于α和β,通過其自然共軛的性質,P(w,z)的值可以通過對θ和φ積分計算得到。P(w,z)= P(w|z)P(z),并且φ和θ單獨出現于第一項和第二項,對φ積分獲得第一項值為[11]
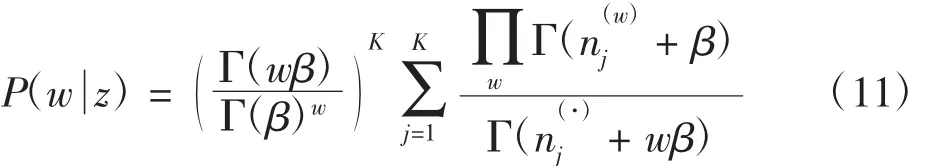
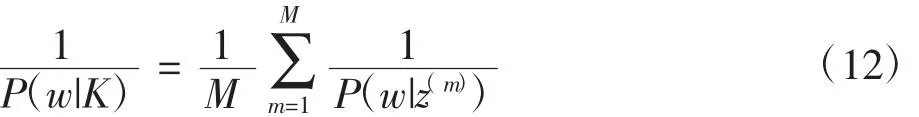
其中,M為Gibbs抽樣算法迭代次數。
1.3.3文本相似度計算
LDA主題模型是在統計學基礎上,通過文檔集的潛在信息,將文檔映射到基于隱含主題的特征空間上,并且將主題映射到詞語的特征空間上。VSM模型首先是基于詞頻統計的理論,利用文本中詞語的TFIDF值在向量維度上對2篇文本進行相似度計算。TFIDF思想中的IDF理論從本質上來講是一種有效的在文本表層知識方面抑制噪聲的加權處理方法,雖然在相似度計算上可以取得不錯的效果,但同時由于只是在詞表層方面對文本進行探究,必然會丟失掉大量文本的深層語義信息。另一方面,利用LDA主題模型挖掘得到文本內部的潛在主題知識,在一定程度上彌補了前者在相似度計算方面的不足,但由于文本映射到主題空間的維度相對較低,導致在計算時文本信息的完整性很難保證,進而對于文本類別的區分能力顯得不夠。所以,本文把以上二者進行有機結合,在文本詞語和潛在主題兩個不同層次計算文本之間的相似度。由于考慮了各自模型的優勢,彌補兩者的不足之處,進而保證了最終文本聚類的質量。
在主題-詞語這個特征空間上,對每一個主題選擇前N(本文實驗取N=100)個特征詞,計算每一個特征詞在整個文檔集中的TF-IDF權重,再結合文檔-主題這個特征空間,利用線性加權求和的方法,將其進行結合,從而有效地提高計算文本相似度的質量。
文檔di在主題-詞特征空間上的向量可表示為di_LDA1=(w1,w2,…,wn),其中n為從所有K個主題中所選擇的詞匯數量。則文本di、dj基于主題-詞特征空間的余弦相似度為
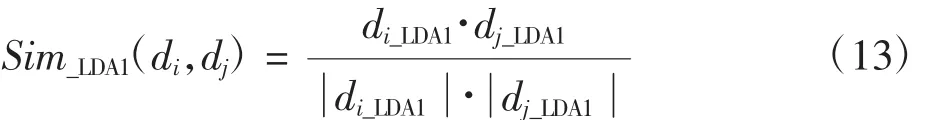
文檔di在文本-主題特征空間上的向量可表示為di_LDA2=(z1,z2,…,zK),其中K表示主題的個數。則文本之間基于文本-主題特征空間的余弦相似度為Sim_LDA2(di,dj)。本文將這兩種相似度進行線性融合,計算公式為
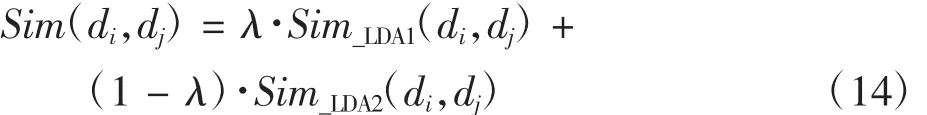
其中λ∈(0,1)為線性參數,表示主題-詞模型和文檔-主題模型按一定比例的加權求和。
2 結果與分析
本文選用經典的K-means聚類算法,用F值來作為最終實驗好壞的評價指標。F度量值是將實驗的準確率和召回率聯合起來對實驗結果進行評估的綜合性指標。其中,準確率P(i,j)和召回率R(i,j)可分別定義為

其中:nij是聚類j中隸屬于類別i的文本數目;ni是類別i的文本數目。對應的F度量值定義為
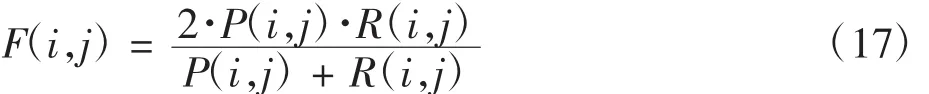
全局聚類的F度量值定義為
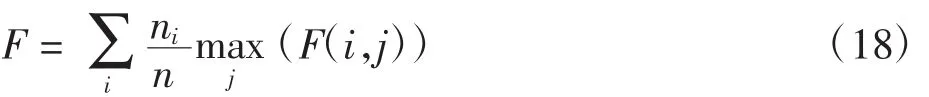
2.1實驗步驟
在對文本進行LDA建模前,先要對語料庫中的文本進行相應的處理,這里包括去停用詞以及對于中文語料的分詞,進而將文本表示為詞向量的形式。由于LDA主題模型使用的是詞袋模型,因此在對中文語料進行分詞操作之后,中英文語料的建模過程是基本相同的。在建模過程中,使用Gibbs抽樣算法得到實驗過程中需要的參數,具體設置為α= K/50、β=0.01,Gibbs抽樣次數為2 000。實驗中的λ值依次從0.01取到0.99,經過多次實驗,當λ為0.85時聚類質量最高。通過實驗研究了主題數目K對Gibbs抽樣算法的影響。當K取不同值時分別運行Gibbs抽樣算法,觀察-logP(w|K)值的變化。在英文語料上的實驗結果如圖2所示。

圖2 英文語料-logP(w|K)與K的關系圖Fig.2 Relationship of topic number K and -logP(w|K)
由圖2可以看出,對于20-News-Group英文語料,K值取50的時候,-logP(w|K)的值最大,證明這時文本集中對于信息的有效程度擬合達到最優。同理,經過實驗得知復旦大學中文語料當主題數K取80的時候-logP(w|K)的值最大。因此后續實驗英文語料和中文語料主題數K的值分別取50和80。
2.2實驗結果及分析
當確定最優主題數后就利用LDA模型對文本進行聚類。實驗結果如圖3和圖4所示。
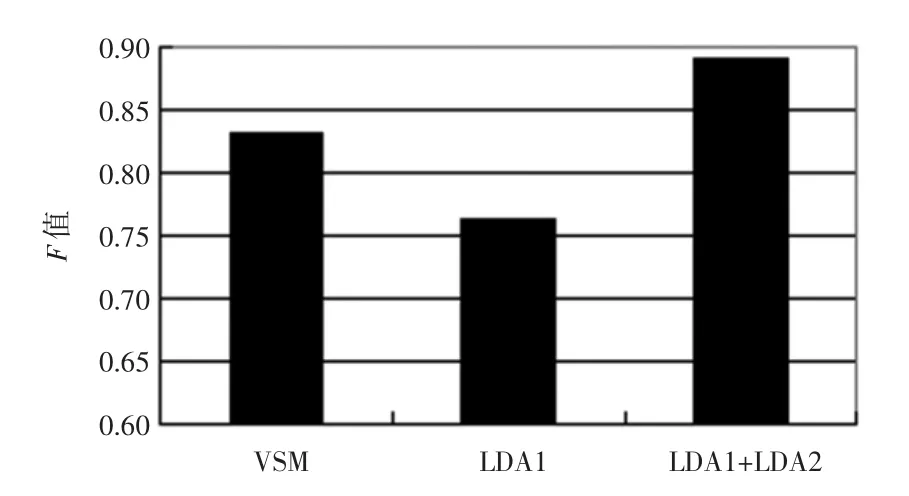
圖3 20-News-Group英文語料基于平均F值的比較結果Fig.3 20-News-Group English corpora comparison based on average value F
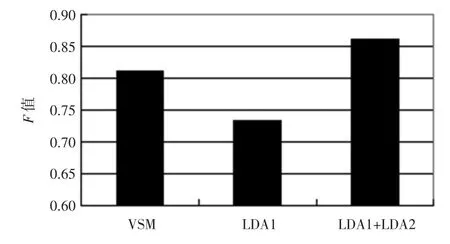
圖4 復旦大學中文語料基于平均F值的比較結果Fig.4 Fudan University Chinese corpora comparison based on average value F
圖中的VSM指將文本集中所有不同詞語作為特征時的文本聚類結果;LDA1指僅利用文本-主題這一特征空間作為特征項時的聚類結果;LDA1+LDA2指將文本-主題和主題-詞語這2個特征空間聯合起來作為特征項時進行的文本聚類的結果。
從圖中可以看出,單獨使用文本-主題特征空間進行聚類效果很差,這是因為K比較小,選取的特征值數量不夠。而將文本-主題和主題-詞這兩個特征空間聯合起來作為進行聚類卻可以明顯地提高F值,比單獨使用VSM結合K-means提高了近5%,獲得了較好的聚類效果。
3 結語
通過將LDA主題模型與傳統的文本聚類方法有效結合,在原來單純的以詞頻為基礎的空間向量模型中加入了文本的深層次語義知識,利用本文方法具有以下優點:
1)可以明顯地提高文本相似度的計算準確性。
2)本文通過LDA對文本進行建模,使文本映射到“文本-主題”和“主題-詞語”這2個特征空間中,一方面增強了向量表示文本的語義含義,另一方面大大縮小了文本表示的向量維度。
3)由于在文本聚類時加入了文本的潛在主題,使聚類效果有了明顯的提高。
4)中英文語料庫的對比聚類實驗證明,本文算法結果要好于單純使用VSM模型的聚類結果。
參考文獻:
[1]唐果.基于語義領域向量空間模型的文本相似度計算[D].昆明:云南大學,2013.
[2]孫昌年,鄭誠,夏青松.基于LDA的中文文本相似度計算[J].計算機技術與發展,2013(1):217-220.
[3]DEERWESTER S,DUMAIS STA. Indexing by latent semantic analysis [J].Journalofthe Societyfor Information Science,1990,41(6):391-407.
[4]高茂庭,王正歐.幾種文本特征降維方法的比較分析[J].計算機工程與應用,2011,42(30):157-159.
[5]王剛,邱玉輝,蒲國林.一個基于語義元的相似度計算方法研究[J].計算機應用研究,2008(11):3253-3255.
[6]鄭誠,李鴻.基于主題模型的K-均值文本聚類[J].計算機與現代化,2013(8):78-80,84.
[7]王振振,何明,杜永萍,等.基于LDA主題模型的文本相似度計算[J].計算機科學,2013,40(12):229-232.
[8]HOFMANN T. Unsupervised learning by probabilistic latent semantic analysis[J].Machine Learning,2001,42(1):177-196.
[9]BLEI D,NG A,JORDAN M. Latent dirichlet allocation[J].Journal of Machine Learning Research,2003(3):993-1022.
[10]GRIFFITHS T L,STEYVERS M. Finding scientific topics[J]. PNAS,2004,101(1):1137-1145.
[11]石晶,胡明,石鑫,等.基于LDA模型的文本分割[J].計算機學報,2008,31(10):1865-1873.
(責任編輯:楊媛媛)
Text clustering method based on weighted LDA model
LI Guoa,b,ZHANG Chunjiea,b,ZHANG Zhiyuana,b
(a. College of Computer Science and Technology;b. Airport Engineering Research Base,CAUC,Tianjin 300300,China)
Abstract:In order to overcome the shortcomings and limitations of traditional clutering algorithms in dealing with largescale and high dimension text clustering,a text clustering method is presented based on weighted LDA(latent dirichlet allocation)model. Two distributions are obtained by LDA: the topic distribution and the word distribution of different topics hidden in the text,which are then combined as the text feature to obtain the final text similarity. Using the classic K-Means algorithm in both English and Chinese corpus,the experimental results show that compared with the pure VSM combined with K-Means,this algorithm has better clustering effect.
Key words:LDA;vector space model;data mining;text clustering;K-Means
中圖分類號:TP18
文獻標志碼:A
文章編號:1674-5590(2016)02-0046-06
收稿日期:2015-04-01;修回日期:2015-04-23基金項目:國家自然科學基金項目(61201414,61301245,U1233113)
作者簡介:李國(1966—),男,河南新鄉人,教授,博士,研究方向為智能信息處理.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
