基于遺傳聚類的配電變壓器運行狀態參數數據修復研究
2016-07-05 20:33:03朱江峰單林森黃建楊
科技風 2016年18期
朱江峰 單林森 黃建楊

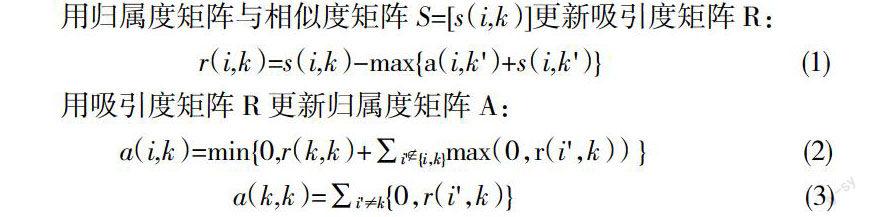
摘 要:為了減少配網設備運行大數據在采集以及傳輸的過程中容易發生的丟失或者損壞,保證配網設備運行檢修工作質量,提高整個電網的安全穩定性。本文結合了不完整信息系統原理、近鄰傳播聚類原理以及遺傳優化算法原理,提出了一種面向配網設備運行狀態的遺傳聚類數據修復方法,充分有效的對大規模、復雜、不完整的配網設備運行參數進行分析以及修復。通過對實際配電變壓器設備運行狀態參數數據進行驗證,結果表明所提出的方法有效的分析和修復了配電變壓器設備運行狀態參數數據,具有實際應用價值。
關鍵詞:配網設備;運行參數;近鄰傳播聚類;遺傳優化;數據修復
隨著當代電力科學的迅速發展,電力行業的配電變壓器設備運行狀態參數正以前所未有的速度增長,配電變壓器設備運行狀態參數處于大數據時代。配網信息的大數據在采集以及傳輸的過程中都容易發生丟失或者損壞,導致配網設備運行檢修工作質量下降,從而影響整個電網的工作質量。因此,針對配電變壓器設備的不完整運行狀態參數進行模式挖掘與填充修復的相關研究,有助于配電大數據信息的有效利用,對將強、健康智能電網的建設有著重要意義[ 1 ]。
傳統數據填充方法沒有充分考慮到數據對象之間的相關性,這就會導致填充的精度嚴重降低,如基于馬氏距離的缺失值的填充算法、基于貝葉斯網絡的缺失數據填充算法、決策樹算法中屬性缺失值的研究等[ 2-4 ]。上述傳統數據填充方法通常簡單的利用已有數據對缺失數據進行填充,并未考慮到數據對象的類別特征,使得填充值容易受到噪聲的干擾,導致填充結果不精確。
本文提出了一種基于遺傳聚類的不完整信息填充方法,通過把數據對象劃分為完整數據集與不完整數據集,先對完整數據集進行聚類,聚類過程中利用遺傳優化原理對聚類參數進行多次迭代優化得出聚類中心點。之后計算不完整數據點與每個聚類中心的相似度,把不完整數據點劃分到相似度最大的類中,由于同一類數據相關性強,即可利用同一類數據中的完整數據對不完整數據進行填充,避免噪聲對填充值的干擾,并有效提高缺失數據的填充精度。
1 基于遺傳聚類的不完整數據修復理論
近鄰傳播(Affinity Propagation, AP)聚類算法是一種基于密度分布函數的方法的無監督聚類算法,是由Frey等人于2007年首次提出[ 5 ]。AP算法將所有數據樣本均作為潛在聚類中心,自適應于數據樣本進行聚類,無需預先設置類別數量。在程序運行中不斷迭代搜索合適的聚類中心,自動識別聚類中心的位置以及聚類數目。其中,吸引度(Responsibility)表示以數據點k為數據點i聚類中心的適合程度,記做r(i,k)。而歸屬度(Availability)則表示數據點i選擇數據點k為聚類中心的適合程度,記做a(i,k)。
AP聚類算法通過消息傳播逐步實現對聚類中心的逼近,并通過如下更新規則對吸引度矩陣R=[r(i,k)]與歸屬度矩陣A=[a(i,k)]進行迭代更新[ 2 ]:
首先,計算N個數據點的相似度值,建立相似度矩陣S矩陣,同時設定偏向參數。其次,設置最大迭代次數maxits值,迭代計算吸引度矩陣R和歸屬度矩陣A,并根據r(k,k)+a(k,k)值判斷是否為聚類中心(若(r(k,k)+a(k,k))>0則構成一個聚類中心;反之,則不是聚類中心)。最后,對于數據點i,選擇r(i,k)+a(i,k)最大的數據點k為其真正聚類中心。值得注意的是,當迭代次數超過maxits值或多次迭代不發生改變時終止迭代。
遺傳優化(Genetic Optimization)算法依據親本初始化解,通過復制、交叉以及突變等操作產生子代的解,淘汰適應度較低的解以增加對最優解的逼近效果。本文引入遺傳算法對傳統近鄰AP聚類中阻尼系數?姿、迭代次數最大值(maxits值)等聚類參數進行優化,用以提高聚類精度。遺傳算法的具體過程包括編碼方式及初始化、適應度函數設計、遺傳操作、終止條件以及解碼等五個環節[ 6 ]。在對數據進行聚類之后,由于同一類中的數據相似度高,不同類中的數據相似度低,本文利用與缺失屬性的對象在同一個類當中的數據對象的相應屬性的加權值作為該屬性的預測值。這種方法的關鍵在于確定各數據對象的加權系數,為了能夠客觀準確的確定加權系數,本文采用信息論中熵值的概念,通過數據對象間的相似度提供的信息來確定加權系數。
2 仿真實例分析
2.1 基于遺傳聚類的不完整數據修復的實現
為了驗證本文所提出的遺傳聚類算法對不完整數據的修復效果,本文使用基于PYTHON語言的仿真測試軟件進行仿真測試,選取了國家電網公司某地區配網設備的運行臺賬數據中50個型號為S9-M-500/10,500kV配電變壓器設備運行狀態參數中的配電變壓器短路阻抗、短路損耗、空載損耗、電壓等級、絕緣介質以及額定容量等六類數據指標形成的指標向量作為樣本數據。聚類時,根據遺傳優化的結果,最大迭代次數maxits取10000次;聚類中心不變的最大迭代次數convits取50次;阻尼系數?姿取0.8。經過1468次迭代計算,聚類中心不變次數達到了最大值50次,停止迭代,計算得到樣本聚類3個。
根據訓練樣本聚類情況,參考樣本數據,并依據國際行業標準《ANSI/IEEE C57.123-2010 變壓器損耗測量指南》以及《ANSI/UL 506-2008 專用變壓器的安全標準》等文件對配電變壓器設備運行狀態的評定,樣本聚類符合以下描述:
樣本聚類1:以樣本16為聚類中心,包括樣本16、8、12、15、19、21、24、25、27、28、50等,此類樣本設備服役時間為3年及3年以下,數據反映設備運行狀況良好,穩定性較高。
樣本聚類2:以樣本35為聚類中心,包括樣本1、2、3、4、6、7、9、10、13、14、17、20、22、23、26、29、30、31、32、33、34、36、37、38、39、40、41、42、43、44、45、46、48、49等,此類樣本設備服役時間為4-8年,數據反映設備運行狀況一般,存在著一定的設備損耗,穩定性與新設備相比,有所降低。
樣本聚類3:以樣本47為聚類中心,包括樣本5、11等,此類樣本設備服役時間為9年及9年以上,數據反映設備運行狀況較差,設備損耗比較嚴重,設備運行穩定性較低。
根據對樣本數據的有效聚類,本文選取了5個含有缺失數據的配電變壓器設備運行狀態參數數據數據樣本進行修復填充。修復結果與原設備參數進行對比,修復樣本1至5的修復精度分別為:98.73%、95.89%、94.38%、100%以及100%。
2.2 仿真對比實驗結果分析
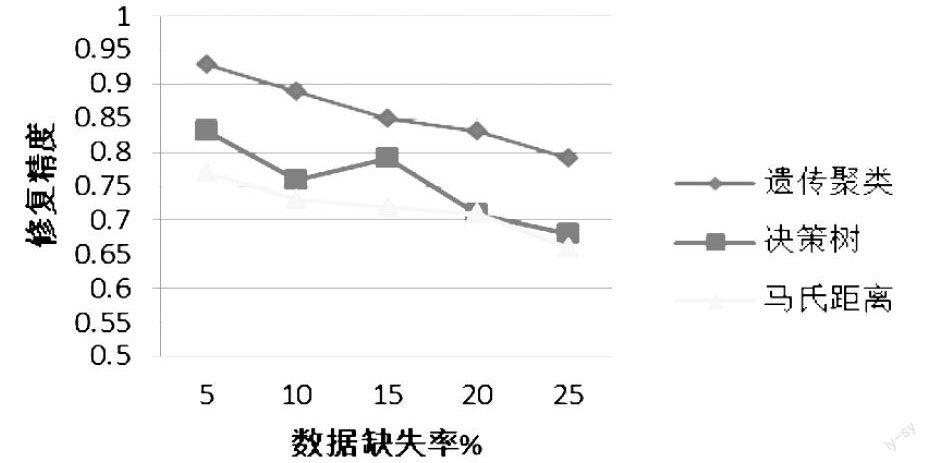
為了測試本文提出的算法的性能,將本文提出的算法同基于決策樹的缺失數據修復算法、以及基于馬氏距離的缺失數據修復算法進行比較,實驗結果如圖1所示。
由圖1可知,隨著數據缺失率的增長,基于決策樹、基于馬氏距離以及本文提出的基于遺傳聚類三種數據修復算法的修復精度均有所下降。在以上三種算法中,本文提出的算法有效避免了不同類對象對數據填充的影響,因而修復精度明顯高于另外兩種算法。
除此之外,當數據缺失率超過15%時,隨著缺失數據的增加,基于決策樹的缺失數據修復算法以及基于馬氏距離的缺失數據修復算法的修復精確度急劇降低,而本文提出的算法則比較穩定,充分說明本文提出的算法對待缺失率較高的數據集中依然能保持良好的效果。
3 結論
由于配電變壓器設備運行狀態參數數據在采集和傳輸過程中容易丟失,導致了大數據的不完整性,阻礙了大數據的分析精度。本文提出將一種直接針對不完整數據進行遺傳聚類的方法應用于配電變壓器設備運行狀態參數數據分析上,給出了配電變壓器設備運行狀態參數數據的相似度度量方式,在此基礎上利用遺傳聚類算法對不完整配電變壓器設備運行狀態參數數據進行聚類。最后,利用數據聚類結果對不完整設計數據進行填充。
實驗結果表明,本文提出的算法能夠有效地對不完整配電變壓器設備運行狀態參數數據進行聚類,同時能夠對不完整配電變壓器設備運行狀態參數數據進行有效填充。
參考文獻:
[1] 田冰冰,劉念,劉琨等.基于改進蟻群算法的變壓器診斷數據的約簡[J].電力系統保護與控制,2011,39(1):96-99,122.
[2] 冷泳林,張清辰,魯富宇等.基于AP聚類的不完整大數據填充[J].計算機工程與應用,2015,(10):123-127,141.
[3] 李宏,阿瑪尼,李平等.基于EM和貝葉斯網絡的丟失數據填充算法[J].計算機工程與應用,2010,46(5):123-125.
[4] 冷泳林,陳志奎,張清辰等.不完整大數據的分布式聚類填充算法[J].計算機工程,2015,(5):19-25.
[5] 刁贏龍,盛萬興,劉科研等.大規模配電網負荷數據在線清洗與修復方法研究[J].電網技術,2015,(11):3134-3140.
[6] 黃毅成,楊洪耕.改進遺傳K均值算法在負荷特性分類的應用[J].電力系統及其自動化學報,2014,26(7):70-75.
作者簡介:
朱江峰(1974-),男,漢族,浙江紹興人,國家電網浙江省電力公司紹興供電公司,高級工程師,碩士、研究方向:配電變壓器檢測、數據修復;
單林森(1981-),男,漢族,浙江紹興人,國家電網浙江省電力公司紹興供電公司,工程師,學士,研究方向:配電信息技術、模式識別;
黃建楊(1982-),男,漢族,浙江諸暨人,國家電網浙江省電力公司諸暨供電公司,工程師,碩士,研究方向:配電變壓器檢測、模式識別;
