利用隨機森林的高分一號遙感數據進行城市用地分類
2016-09-02 06:59:23郭玉寶池天河劉吉磊楊麗娜
測繪通報 2016年5期
關鍵詞:分類
郭玉寶,池天河,彭 玲,劉吉磊,楊麗娜
(1.中國科學院遙感與數字地球研究所,北京 100101; 2. 中國科學院大學,北京 100049)
?
利用隨機森林的高分一號遙感數據進行城市用地分類
郭玉寶1,2,池天河1,彭玲1,劉吉磊1,2,楊麗娜1
(1.中國科學院遙感與數字地球研究所,北京 100101; 2. 中國科學院大學,北京 100049)
為了探究國產高分一號衛星遙感影像數據面向城市用地分類的實際應用方法和效果,本文以北京市某區域為例,基于高分一號PMS數據,使用隨機森林、支持向量機、最大似然法3種分類器進行了城市用地分類對比研究。結果表明,隨機森林和支持向量機的總體分類精度明顯優于最大似然法;最大似然法在運算時間上明顯優于隨機森林和支持向量機。綜合分析發現,隨機森林算法表現更優。它既能保證分類精度,又能保持一定的時間效率,更適合高分辨率、大數據量、多特征參數的高分一號遙感影像分類的實際生產應用。
隨機森林;城市用地;高分一號;圖像分類
城市用地是城市各種經濟活動的場所,是市民居住生活的空間,也是城市生態環境質量評估、城市規劃建設的重要指標。城市用地類型多種多樣,結構復雜是影響遙感影像分類精度的主要原因。高分辨率遙感影像具有豐富的空間結構和紋理信息,合理利用這些信息可有效提高分類精度[1]。在遙感影像分類中,由于影像類型特點不同,研究區類型種類復雜,各種分類器也各具優缺點,很難找到一個同時合適多種需求的分類器[2-3]。隨機森林(random forests,RF)作為集成分類中的一種,因其運算速度較快,分類精度較好,較穩定等特點被廣泛應用于醫學、經濟、制造業等各個領域的數據挖掘、數據分類。在遙感中也廣泛用于多光譜、多時相、多源數據結合分類應用[4]。
近年來,基于高分辨率遙感衛星數據的遙感信息分類技術在城市用地分類中得到廣泛應用,常用的高分辨率數據有Landsat TM、QuickBird、IKONOS、World View、資源三號等[5]。隨著國產衛星的發展和高分辨率衛星的相繼發射,我國高分辨率數據自給率有了很大提升。“高分一號”(GF-1)衛星于2013年4月升空,星上搭載了兩臺2 m分辨率全色/8 m分辨率多光譜相機,4臺16 m分辨率多光譜相機。GF-1衛星是太陽同步回歸軌道衛星,軌道高度為645 km,傾角為98.050 6°。全色波段光譜范圍為0.45~0.90 μm,多光譜波段光譜范圍為0.45~0.52 μm,0.52~0.59 μm,0.63~0.69 μm,0.77~0.89 μm;幅寬為60 km,重訪周期為4 d(側擺時),覆蓋周期為41 d(不側擺時)。目前應用國產衛星數據進行城市遙感方面的研究是一個較新的研究點,且基于GF-1衛星遙感數據的應用研究比較少。GF-1衛星遙感數據面向城市用地分類的實際應用效果有待探究。
本文以GF-1衛星多光譜和全色影像為主要數據源,以北京市某區域為例,探討利用集成學習中的隨機森林算法進行城市用地分類的技術方法,并將隨機森林與SVM、最大似然法兩種傳統分類方法進行效率、精度對比分析,為隨機森林算法在城市用地分類方面的應用提供可行的參考依據。運用GF-1衛星影像作為研究數據源,以期推動GF-1數據在城市遙感分類領域的應用,為解決智慧城市中用地規劃、建設和改造方面的問題作出貢獻。
一、研究方法與原理
1. 隨機森林
隨機森林是由Leo Breiman和Adele Cutler于2001年提出的一種集成學習方法[6],是一種基于分治法原理的集成學習策略,是若干決策樹集成的分類器,相較于決策樹其更加穩健,泛化性能更好[7]。隨機森林核心思想是對輸入樣本在記錄數據(行)和特征變量(列)的使用上隨機化。它通過隨機選擇向量生長成決策樹,每棵樹都會完全生長,而不需要修剪,并且在生成決策樹時,每個節點都是從隨機選出的幾個變量中最優分裂產生,生成所有決策樹之后,用投票的方法對所有決策樹的分類結果進行綜合,得出最終結果[7-8]。森林中每一棵樹都依賴于一個隨機向量,森林中的所有向量都是獨立分布的。隨機森林的預測精度與單個樹的強度和樹間的相關性有關[6]。
隨機森林決策樹學習過程為:①隨機從訓練樣本N中有放回地抽樣n個作為決策樹的輸入樣本;②從M個樣本特征中隨機選取m個特征,作為每一個結點的輸入樣本特征,其中m遠小于M;③以m個特征的最優分裂作為該結點的分裂規則;④每一棵決策樹均最大限度地生長,不剪枝。
由于生成決策樹的過程是獨立的,隨機森林算法便于并行計算,在處理大數據時表現優異。尤其在處理高維數據分類時,更能體現出隨機森林的速度快、精度高、穩定性好的優勢[9]。對于決策樹分類,隨機森林對于大規模數據集有較高的準確率,并可估算特征變量的重要性[10]。
應用隨機森林模型分類器需要設定2個重要參數:①生成樹個數(number_of_trees),該值決定了模型中集成的決策樹個數。該值越大模型收斂性越好,但運行時間增加,且當樹的個數過多時,模型會出現過飽和現象。②隨機抽取最大特征數(max_features),該值表示生成每一棵決策樹時從特征空間中隨機抽取特征的最大數。該值越大模型中每棵決策樹強度越大,但決策樹間相關性也增大。因此,max_features需根據oob誤差率來調優,以達到一定精度。
隨機森林分類器的優點為[6]:①算法精度高;②可以處理大數據集,無需對大量的輸入特征變量進行刪減;③可以給出變量的重要性估計;④在模型建立過程中可以產生一個對一般誤差的無偏估計,不會過度估計;⑤可以有效處理缺失數據的情況;⑥產生的森林模型易于保存和未來重復利用;⑦可以擴展到無類別數據中,進行非監督分類。
2. 其他方法
支持向量機(SVM)由Vapnik V等在1995年首先提出,是建立在統計學習理論和結構風險模型最小原理基礎上的一種學習方法,是從線性可分情況下的最優超平面發展而來的。SVM能夠在有限樣本信息的條件下,在學習精度和學習效果之間找到最佳平衡[11]。支持向量機具有小樣本學習、抗噪聲性能好、學習效率高和適合推廣等優點,被廣泛用于遙感影像處理領域,一些主要的應用如高光譜遙感分類、遙感影像融合、土地利用類型分類等。SVM方法尋找最佳超平面的思路與RF邊緣最大化的思想有一定的相似性。
最大似然法(max likelihood)是一種基于統計識別理論的方法[7]。它假定各類分布函數為正態分布,用統計方法根據貝葉斯判決準則,選擇訓練樣本集,建立非線性判別規則,計算各分類樣區的歸屬概率進行分類。該方法樣本較多時收斂性較好,并且相對其他方法簡單、運算速度快,是一種廣泛應用的遙感分類方法。
二、材料與試驗
本文從北京市“高分一號”高分辨率遙感影像中選取北京城區東北部分,覆蓋面積約16 km2,影像接收時間為2013年5月29日,共5個波段。多波段影像具有4個波段,空間分辨率為8 m;全色影像1個波段,空間分辨率為2 m;研究區域內有建筑、道路、植被、水域和普通地面等。該地區地勢比較平整,城市地物目標種類豐富。
軟件平臺使用EnMap-Box結合ENVI 5.1。EnMap-Box是德國一款基于ENVI/IDL二次開發的遙感處理工具箱軟件,集成了許多種機器學習算法,可進行數據分類、回歸處理及精度評價。
1. 數據預處理
本研究利用數字高程模型(DEM)和控制點數據對影像做了幾何校正。然后,利用HPF(high pass filter)融合方法將全色波段和多光譜波段進行圖像融合。該算法能簡單、快速地將高頻的空間信息與低頻的光譜信息融合,保證圖像能夠兼顧地物的空間和光譜特征[12]。結合實地對比勘測的數據,參考常用分類系統,將該地區地物分為5類即建筑用地、道路、水體、植被、裸地。通過對影像進行解譯,所選樣本中不同地物光譜特征具有良好的區分性,滿足分類要求。
常用的分類特征主要有NDVI、波段反射率等光譜特征,為提高分類精度,研究中還使用了紋理特征,主要包括均值、方差、熵、同質性等,這些紋理特征通過計算灰度共生矩陣獲得。對所有的特征進行內部歸一化處理,以排除紋理特征和光譜特征在數值和類型上的不同所產生的影響。
2. 隨機森林建模
本試驗中訓練樣本為42 437個,特征為37個。經過對結果的分析比較,隨機森林分類器參數max_features取值為6,number_of_trees取值為100時,結果相對穩定。因此按照分析選擇該參數組合(6,100)進行分類,分類結果如圖1所示。
從圖中可以看出,最大似然法分類器的分類結果總體上明顯劣于SVM和RF。SVM和RF的分類結果總體差別不大,但是各類別之間差別較大,主要是裸地和道路,裸地和建筑用地的區分方面。
三、結果與分析
結合實地調查和影像解譯數據,分別對3種分類器的分類結果建立混淆矩陣進行精度檢驗,計算出3個分類器的總體分類精度和Kappa系數見表1。從表1中可以看出,隨機森林的分類精度和Kappa系數最高,隨機森林整體分類效果最好。支持向量機的分類精度相對隨機森林較低,但是僅差1.39%,整體分類結果也較優。最大似然法在3種分類結果中相對最差。從表1看出,3種方法對植被分類較好,用戶精度方面,隨機森林和支持向量機甚至達到100%。但裸地分類精度方面隨機森林和支持向量機均比較差,分別只有66.78%和59.14%。雖然最大似然法對裸地的生產者精度較高達86.58%,但是用戶精度較低且出現道路和裸地混分現象,這是導致最大似然法的整體分類精度相對較低的主要原因。3種方法均出現建筑用地、裸地和道路3類不同程度的混分情況。經過對比研究區的實際情況,發現研究區中裸地和道路相連、相接,同時裸地與建筑用地相間,容易出現混分現象。
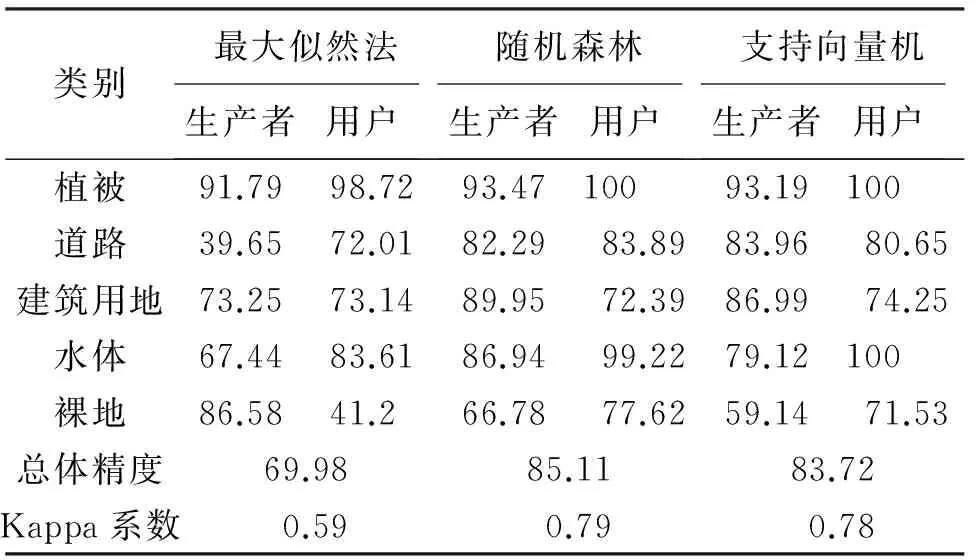
表1 3種方法精度評價表 (%)
在分類運算速度方面,隨機森林分類器分類樹設置為100時,分類時間為3763 s,最大似然法用時497 s,支持向量機時間最長為8235 s,約2 h 17 min。最大似然法雖然總體分類精度令兩者有14%~15%的差距,但分類速度是最快的。支持向量機運算速度最慢,耗時超過2 h。隨機森林雖然總體精度是最高的但是分類耗時約為最大似然的7.57倍,比支持向量機快約1倍。因此整體角度上,隨機森林分類器相較于支持向量機和最大似然法分類效果較好。
四、結束語
本文結果表明相比兩種常用的傳統方法,隨機森林具有較好的提取精度、較快的分類速度,但是隨機森林方法提取效果受決策樹個數的影響。為保證算法既有較快的運算速度又能滿足所需精度,應選擇合適的生成樹個數。如何根據應用區域和精度目標估算適合的決策樹個數、最小分裂條件等模型參數,還需要進一步分析與研究。本文結果也證明了隨機森林算法在GF-1衛星數據影像的城市用地分類上具有良好的適用性,這對于擴大高分系列衛星數據的應用具有一定實際意義。
[1]馮盺,杜世宏,張方利,等.基于多尺度融合的高分辨率影像城市用地分類[J].地理與地理信息科學,2013,29(3):43-47.
[2]NIKUNJ C O, KAGAN T. Classifier Ensembles: Select Realworld Applications[J]. Information Fusion,2008,9(1):1-37.
[3]呂京國.基于神經網絡集成的遙感圖像分類與建模研究[J].測繪通報,2014(3):17-20.
[4]劉海娟,張婷,侍昊,等.基于RF 模型的高分辨率遙感影像分類評價[J].南京林業大學學報(自然科學版),2015,39(1):99-103.
[5]王野.基于資源三號衛星影像的城市綠地信息提取方法探討[J].測繪工程,2014,23(7):65-67.
[6]BREIMAN L. Random Forests [J]. Machine Learning,2001,45(1):5-32.
[7]王棟,岳彩榮,田傳召,等.基于隨機森林的大姚縣TM遙感影像分類研究[J].林業調查規劃, 2014,4(39):1-5.
[8]雷震.隨機森林及其在遙感影像處理中應用研究[D].上海:上海交通大學,2012.
[9]劉毅,杜培軍,鄭輝,等.基于隨機森林的國產小衛星遙感影像分類研究[J].測繪科學,2012,37(4):194-196.
[10]李欣海.隨機森林模型在分類與回歸分析中的應用[J].應用昆蟲學報,2013,50(4):1190-1197.
[11]張錦水,何春陽,潘耀忠,等.基于SVM的多源信息復合的高空間分辨率遙感數據分類研究[J].遙感學報,2006,10(1):49-57.
[12]鄭著彬,李俊,任靜麗.HPF圖像融合技術在大理市遙感影像中的運用探討[J].云南地理環境研究,2007,19(6):96-98.
Classification of GF-1 Remote Sensing Image Based on Random Forests for Urban Land-use
GUO Yubao,CHI Tianhe,PENG Ling,LIU Jilei,YANG Lina
10.13474/j.cnki.11-2246.2016.0159.
2015-04-13
國家自然科學基金青年科學基金(41201397)
郭玉寶(1989—),男,碩士,主要研究方向為遙感在智慧城市中的應用。E-mail:17022793@qq.com
P23
B
0494-0911(2016)05-0073-04
引文格式: 郭玉寶,池天河,彭玲,等. 利用隨機森林的高分一號遙感數據進行城市用地分類[J].測繪通報,2016(5):73-76.
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
