基于大數(shù)據(jù)的政府決策水平的實(shí)證研究
2016-11-17 02:09:11李立煊
現(xiàn)代交際 2016年7期
關(guān)鍵詞:大數(shù)據(jù)效率
李立煊
摘要:科學(xué)技術(shù)的快速發(fā)展是當(dāng)前社會(huì)的真實(shí)寫照,大數(shù)據(jù)的出現(xiàn)就是高新技術(shù)快速發(fā)展的最好例子。大數(shù)據(jù)給產(chǎn)業(yè)升級(jí)、技術(shù)創(chuàng)新、拓展就業(yè)等帶來(lái)深刻的影響,政府積極應(yīng)對(duì)大數(shù)據(jù)帶來(lái)的挑戰(zhàn)是提升政府決策水平的一個(gè)關(guān)鍵因素。本文以廣州市政府工作人員為研究對(duì)象,通過問卷調(diào)查獲取第一手?jǐn)?shù)據(jù),并且采用SPSS統(tǒng)計(jì)軟件進(jìn)行了研究,9個(gè)研究假設(shè)都通過了驗(yàn)證。本文研究證明,大數(shù)據(jù)的開放性和數(shù)據(jù)利用率有利于提高政府工作人員與職位的匹配度、有利于提高政府的決策水平的提高。
關(guān)鍵詞:大數(shù)據(jù);政府;工作人員;效率
中圖分類號(hào):C96文獻(xiàn)標(biāo)識(shí)碼:A文章編號(hào):1009-5349(2016)07-0024-03
大數(shù)據(jù)是當(dāng)前科學(xué)技術(shù)發(fā)展的一個(gè)較為顯著的特征,它有力地促進(jìn)了相關(guān)產(chǎn)業(yè)的提升、提高了科學(xué)技術(shù)的革新水平,對(duì)生產(chǎn)和社會(huì)生活產(chǎn)生了深遠(yuǎn)的影響。在這一場(chǎng)大數(shù)據(jù)帶來(lái)的全新革新過程中,政府要建立高效的服務(wù)型政府就必須面臨大數(shù)據(jù)所帶來(lái)的挑戰(zhàn)和機(jī)遇,通過積極利用大數(shù)據(jù)的各種絕佳促進(jìn)作用,提高政府的決策和宏觀調(diào)控的能力。政府的高效運(yùn)作,關(guān)鍵在于人,在于人的素質(zhì)。雖然很多的文獻(xiàn)都在研究大數(shù)據(jù)的發(fā)展對(duì)產(chǎn)業(yè)、對(duì)經(jīng)濟(jì)、對(duì)社會(huì)變革帶來(lái)的各種機(jī)遇和挑戰(zhàn),但很少有文獻(xiàn)從大數(shù)據(jù)的角度來(lái)研究政府如何通過大數(shù)據(jù)來(lái)提高政府的決策水平。本文從這個(gè)角度來(lái)對(duì)此問題進(jìn)行初步研究。廣州作為廣東的省會(huì)城市,也是廣東經(jīng)濟(jì)創(chuàng)新發(fā)展的重要引擎之一,所以廣州市政府的工作人員的素質(zhì),尤其是在大數(shù)據(jù)方面的應(yīng)對(duì)水平對(duì)提高政府決策水平是至關(guān)重要的。本文通過數(shù)據(jù)的分析,研究廣州市政府工作人員在政府決策層次上的水平,并探究影響他們決策水平的深層次的原因,希望能對(duì)政府的決策工作有所幫助。
一、研究假設(shè)與模型構(gòu)建
(一)研究假設(shè)
本文的研究假設(shè)是建立在前人的研究成果基礎(chǔ)上,并且對(duì)其成果進(jìn)行批判性吸收,結(jié)合本文的實(shí)際研究情況而做出的。政府和企業(yè)一樣,都需要提升創(chuàng)新驅(qū)動(dòng)的能力,決策者都需要實(shí)現(xiàn)決策過程和水平的轉(zhuǎn)變,而這個(gè)過程的轉(zhuǎn)變,依靠的是政府對(duì)大數(shù)據(jù)的處理能力,擁有一個(gè)良好的大數(shù)據(jù)資源環(huán)境是政府決策的重要基礎(chǔ)。因?yàn)樵诖髷?shù)據(jù)環(huán)境中,政府人員可以建立暢通的內(nèi)部數(shù)據(jù)的共享機(jī)制,并且有效提高數(shù)據(jù)的使用效率。具體來(lái)說(shuō),在綜合前人研究成果的基礎(chǔ)上,本文的研究假設(shè)如下:
假設(shè)H1:數(shù)據(jù)開放性有利于人才評(píng)價(jià)的準(zhǔn)確性的提高。
假設(shè)H2:數(shù)據(jù)利用率有利于人才與職位的匹配度的提高。
假設(shè)H3:數(shù)據(jù)利用率有利于人才評(píng)價(jià)的準(zhǔn)確性的提高。
假設(shè)H4:數(shù)據(jù)開放性有利于人才與職位的匹配度的提高。
假設(shè)H5:人才評(píng)價(jià)的準(zhǔn)確性有利于人才與職位的匹配度的提高。
假設(shè)H6:人才評(píng)價(jià)的準(zhǔn)確性有利于政府的決策水平的提高。
假設(shè)H7:人才與職位的匹配度有利于政府的決策水平的提高。
假設(shè)H8:數(shù)據(jù)開放性能顯著性地提高政府的決策水平。
假設(shè)H9:數(shù)據(jù)利用率能顯著性地提高政府的決策水平。
(二)模型構(gòu)建
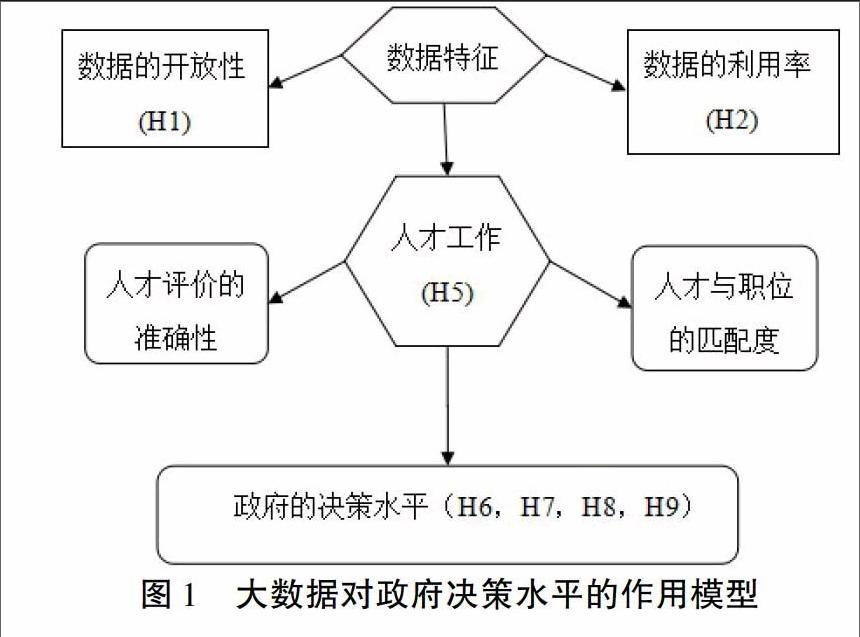
本文在積極吸收前人的研究成果的基礎(chǔ)上,并且結(jié)合本文研究對(duì)象的實(shí)際情況,尊重廣州市政府工作人員對(duì)大數(shù)據(jù)使用的情況,特地構(gòu)建了大數(shù)據(jù)在提高政府決策水平上模型。
圖1大數(shù)據(jù)對(duì)政府決策水平的作用模型
二、實(shí)證分析
本文在提出研究假設(shè)和構(gòu)建研究模型之后,為了得到第一手的數(shù)據(jù),特地設(shè)計(jì)了具有針對(duì)性的問卷,問卷的發(fā)放對(duì)象主要是廣州市政府的工作人員,調(diào)查對(duì)象非常明晰。問卷設(shè)計(jì)好后,先進(jìn)行了20名的試調(diào)查,然后針對(duì)問卷存在的問題再完善問卷,然后得出最終的調(diào)查問卷。本研究的問卷一共發(fā)放300份,回收到的有效問卷是285份,有效回收率為95%。
(一)問卷的信度和效度檢驗(yàn)
1問卷的信度分析
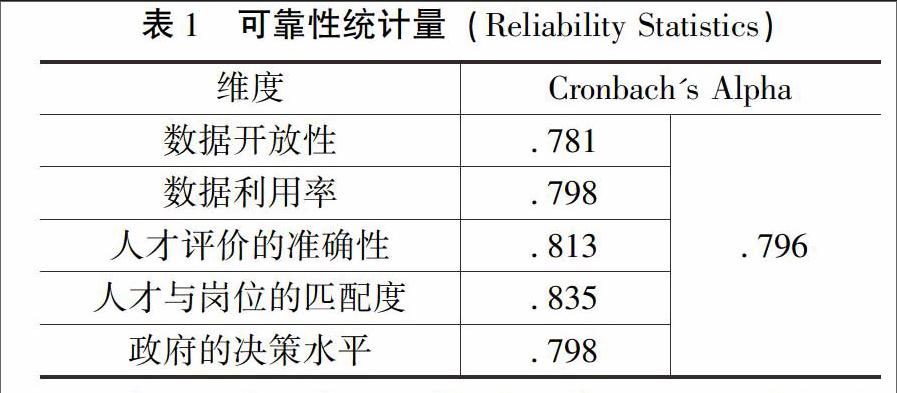
信度反映了測(cè)量工具所得到的結(jié)果的一致性或穩(wěn)定性,是被測(cè)特征真實(shí)程度的指標(biāo)。為了檢驗(yàn)問卷的內(nèi)部一致性,采用SPSS200的可靠性分析,測(cè)量各個(gè)量表及組成維度之間的Cronbach'sα系數(shù),具體見表3-8內(nèi)部一致性分析(N=20)。根據(jù)經(jīng)驗(yàn)α,當(dāng)α系數(shù)大于070時(shí),表示問卷信度良好,在可接受范圍內(nèi)。
在表3-8中,數(shù)據(jù)開放性的α值是0781,數(shù)據(jù)利用率的α值是0798,人才評(píng)價(jià)的準(zhǔn)確性的α值是0813,人才與崗位的匹配度的α值是0835,政府的決策水平的α值是0798,而總量表的Cronbach'sα 系數(shù)達(dá)到0796,因此本問卷的一致性信度很好,可以進(jìn)行問卷調(diào)查和數(shù)據(jù)統(tǒng)計(jì)分析。
2問卷的效度分析
本文主要運(yùn)用因子分析的方法對(duì)量表的效度進(jìn)行分析。在做因子分析之前,首先要用KMO和Bartlett球體檢驗(yàn)法來(lái)驗(yàn)證所用量表是否適合做因子分析。
一般認(rèn)為,KMO統(tǒng)計(jì)值大于09時(shí)效果最佳,07以上可以接受,05以下則不宜做因子分析。本分析中,KMO統(tǒng)計(jì)量值是0886,說(shuō)明本問卷具有較高的效度,可以進(jìn)行問卷訪問和數(shù)據(jù)分析。
(二)問卷的描述性統(tǒng)計(jì)分析
廣州市政府的工作人員主要為男性,年齡主要是青壯年,學(xué)歷主要是碩士學(xué)歷。這些都說(shuō)明,廣州市政府的工作人員的整體結(jié)構(gòu)還是比較合理的。
(三)研究建設(shè)檢驗(yàn)
1人才評(píng)價(jià)的準(zhǔn)確性的回歸檢驗(yàn)
以人才評(píng)價(jià)的準(zhǔn)確性為因變量,而自變量為數(shù)據(jù)的開放性和數(shù)據(jù)的利用率,構(gòu)筑并且檢驗(yàn)它們的回歸方程。
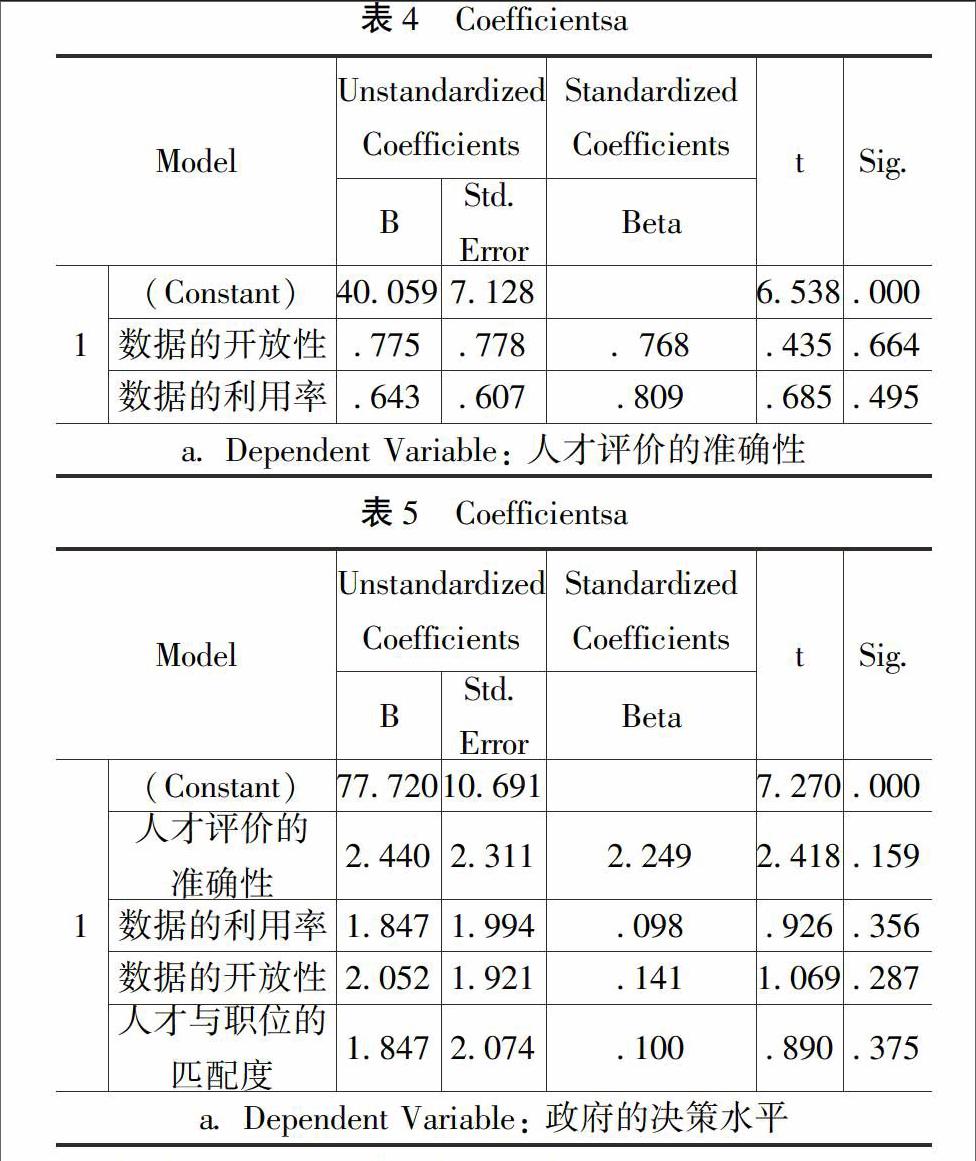
從表4中可以看到,方程常數(shù)項(xiàng)的顯著性水平為0000,小于005,表示常數(shù)項(xiàng)應(yīng)出現(xiàn)在方程中。根據(jù)回歸分析結(jié)果,按照各因子對(duì)人才評(píng)價(jià)的準(zhǔn)確性的影響程度進(jìn)行由大到小排序,分別為數(shù)據(jù)的開放性和數(shù)據(jù)的利用率。
構(gòu)建回歸方程:人才評(píng)價(jià)的準(zhǔn)確性=40059+0775*數(shù)據(jù)的開放性+0643*當(dāng)數(shù)據(jù)的利用率。回歸系數(shù)都是大于05,說(shuō)明對(duì)人才評(píng)價(jià)的準(zhǔn)確性的影響是積極作用。所以,以下研究假設(shè)都得到驗(yàn)證:
假設(shè)H1:數(shù)據(jù)開放性有利于人才評(píng)價(jià)的準(zhǔn)確性的提高;
假設(shè)H3:數(shù)據(jù)利用率有利于人才評(píng)價(jià)的準(zhǔn)確性的提高。
2.政府的決策水平的回歸檢驗(yàn)
以政府的決策水平為因變量,而自變量為:人才評(píng)價(jià)的準(zhǔn)確性、數(shù)據(jù)的利用率、數(shù)據(jù)的開放性、人才與職位的匹配度,構(gòu)筑并且檢驗(yàn)它們的回歸方程。
構(gòu)建回歸方程:政府的決策水平=77720+244*人才評(píng)價(jià)的準(zhǔn)確性+1847*當(dāng)數(shù)據(jù)的利用率+2052*數(shù)據(jù)的開放性+1847*人才與職位的匹配度。回歸系數(shù)都是大于05,說(shuō)明對(duì)人才評(píng)價(jià)的準(zhǔn)確性的影響是積極作用。所以,以下研究假設(shè)都得到驗(yàn)證:
假設(shè)H6:人才評(píng)價(jià)的準(zhǔn)確性有利于政府的決策水平的提高。
假設(shè)H7:人才與職位的匹配度有利于政府的決策水平的提高。
假設(shè)H8:數(shù)據(jù)開放性能顯著性地提高政府的決策水平。
假設(shè)H9:數(shù)據(jù)利用率能顯著性地提高政府的決策水平。
3.人才與職位的匹配度的回歸檢驗(yàn)
以人才與職位的匹配度為因變量,而自變量為:人才評(píng)價(jià)的準(zhǔn)確性、數(shù)據(jù)的利用率、數(shù)據(jù)的開放性,構(gòu)筑并且檢驗(yàn)它們的回歸方程。
a Dependent Variable: 人才與職位的匹配度
構(gòu)建回歸方程:人才與職位的匹配度=1701+0532*人才評(píng)價(jià)的準(zhǔn)確性+1223*當(dāng)數(shù)據(jù)的利用率+602*數(shù)據(jù)的開放性。回歸系數(shù)都是大于05,說(shuō)明對(duì)人才評(píng)價(jià)的準(zhǔn)確性的影響是積極作用。所以,以下研究假設(shè)都得到驗(yàn)證:
假設(shè)H2:數(shù)據(jù)利用率有利于人才與職位的匹配度的提高。
假設(shè)H4:數(shù)據(jù)開放性有利于人才與職位的匹配度的提高。
假設(shè)H5:人才評(píng)價(jià)的準(zhǔn)確性有利于人才與職位的匹配度的提高。
三、結(jié)論及建議
(一)研究結(jié)論
本文基于廣州市政府工作人員的視角,研究大數(shù)據(jù)對(duì)政府決策的支撐問題。理論貢獻(xiàn)主要表現(xiàn)在將大數(shù)據(jù)驅(qū)動(dòng)的管理研究運(yùn)用于政府決策中,分析在大數(shù)據(jù)的背景下,政府在人才工作方面如何做出科學(xué)決策。實(shí)證分析了數(shù)據(jù)利用率和開放性這兩個(gè)數(shù)據(jù)特征變量對(duì)人才評(píng)估準(zhǔn)確性等人才變量影響的相關(guān)機(jī)制和路徑過程。同時(shí),基于人才評(píng)估準(zhǔn)確性和人才與崗位匹配度這兩個(gè)中介變量基礎(chǔ)上,研究發(fā)現(xiàn)政府?dāng)?shù)據(jù)的開放性和利用率對(duì)政府在人才工作方面的決策水平起正向影響。因此,上述研究是對(duì)大數(shù)據(jù)在政府決策領(lǐng)域發(fā)展相關(guān)文獻(xiàn)的有益補(bǔ)充。
本文研究結(jié)果對(duì)現(xiàn)代化建設(shè)進(jìn)程中的廣州市政府人才管理工作也具有重要啟示。首先,本研究發(fā)現(xiàn)提高數(shù)據(jù)的開放性和利用率不僅有利于提高社會(huì)各方面對(duì)人才評(píng)價(jià)的準(zhǔn)確性,還有利于提升人才與崗位的匹配度。因此,政府可以建立大數(shù)據(jù)開放平臺(tái),充分公開人才信息,如專利發(fā)明數(shù)量、論文發(fā)表量,科研成果等數(shù)據(jù),便于社會(huì)監(jiān)督,提供人才評(píng)價(jià)的準(zhǔn)確性。同時(shí),政府也可以制定相關(guān)的法律法規(guī)來(lái)規(guī)范數(shù)據(jù)統(tǒng)計(jì),保障數(shù)據(jù)來(lái)源的真實(shí)性和數(shù)據(jù)處理過程的透明度,這樣不僅對(duì)人才數(shù)據(jù)可以做到匯總,還可以實(shí)現(xiàn)人才數(shù)據(jù)的可追溯性,進(jìn)而提高人才數(shù)據(jù)資源利用率,發(fā)揮信息資源應(yīng)有的價(jià)值,真正做到“崗得其人”,“人適其崗”的用人原則,把最符合崗位素質(zhì)要求的人配置到最適宜的崗位上。其次,本研究發(fā)現(xiàn)基于人才評(píng)價(jià)的準(zhǔn)確性和人才與崗位的匹配度這兩個(gè)中介變量的基礎(chǔ)上,數(shù)據(jù)的開放性和利用率均正向影響政府在人才工作方面的決策水平。因此,政府人才工作的服務(wù)創(chuàng)新,可以借助建立人才數(shù)據(jù)庫(kù),推動(dòng)廣州市地區(qū)的大數(shù)據(jù)在人才工作方面的開發(fā)、研究、創(chuàng)新和應(yīng)用。政府在實(shí)際工作中,往往會(huì)遇到很多人才工作方面的決策問題,而對(duì)大數(shù)據(jù)的有效利用是解決此類問題的最佳手段。如人才市場(chǎng)上存在著信息不及時(shí)、信息不全面和信息不對(duì)稱等弊端,政府很難根據(jù)現(xiàn)有的人才信息做出正確的人才決策,而大數(shù)據(jù)則可以很好地幫助政府避免上述人才信息弊端。同時(shí),政府可以增加人才檔案的流動(dòng)性,規(guī)范數(shù)據(jù)的完備性,減少資料傳遞過程中的缺失風(fēng)險(xiǎn),數(shù)據(jù)的開放性和利用率提升了人才決策的速度和準(zhǔn)確性。
(二)研究反思
雖然本研究在某些問題上進(jìn)行了比較深度的研究,也取得了某些比較成熟的成果,但是研究還存在一些問題,這些問題是現(xiàn)在,尤其是未來(lái)的繼續(xù)研究需要深思的問題。雖然本文的研究對(duì)象是廣州市政府的工作人員,他們?cè)诖髷?shù)據(jù)的應(yīng)對(duì)和處理方面具有一定的能力和條件,但是城市政府工作對(duì)數(shù)據(jù)的開放性和利用率會(huì)高于農(nóng)村鄉(xiāng)鎮(zhèn)等基層政府,這就導(dǎo)致城市政府電子政務(wù)工作正如火如荼地開展,而鄉(xiāng)村地區(qū)卻依然落后,設(shè)備依然不完善,觀念依然沒有轉(zhuǎn)換,行政效率依然低下。因此,后續(xù)研究有必要擴(kuò)大調(diào)研范圍。
首先,本研究所考慮的自變量不太豐富,因?yàn)樵谟绊懻疀Q策水平的自變量中因素是很多的,大數(shù)據(jù)僅僅是影響政府決策的一個(gè)關(guān)鍵因素。社會(huì)因素、經(jīng)濟(jì)發(fā)展、政府自身因素、政策因素等等都是影響政府決策水平的關(guān)鍵因素,這些因素的系統(tǒng)研究,應(yīng)該是將來(lái)研究的一個(gè)重要方面。
另外,本研究的樣本數(shù)量不夠多,代表性不是很高。因?yàn)楸狙芯康臅r(shí)間、人力和財(cái)力的有限,不能做到大規(guī)
模的問卷調(diào)查,發(fā)放的有效問卷也只是285份,雖然符合大樣本的要求,但是為了更好地提高樣本的代表性,建議未來(lái)的研究應(yīng)該把樣本數(shù)量提高到500份。
參考文獻(xiàn):
[1]彭海軍.大數(shù)據(jù)背景下的政府行為模式轉(zhuǎn)換[J]. 中國(guó)新通信,2015,09.
[2]蔡立輝,楊欣翥.大數(shù)據(jù)在社會(huì)輿情監(jiān)測(cè)與決策制定中的應(yīng)用研究[J].行政論壇,2015,02.
[3]洪莉,孫文浩.大數(shù)據(jù)背景下官方統(tǒng)計(jì)工作面臨的機(jī)遇和挑戰(zhàn)[J].中國(guó)集體經(jīng)濟(jì),2015,09.
[4]李艷萍.基于大數(shù)據(jù)的公共信息預(yù)警機(jī)制探析[J].圖書館學(xué)刊,2015,02.
[5]陳明奇.大數(shù)據(jù)國(guó)家發(fā)展戰(zhàn)略呼之欲出——中美兩國(guó)大數(shù)據(jù)發(fā)展戰(zhàn)略對(duì)比分析[J].人民論壇,2013,15.
猜你喜歡
甘肅教育(2020年14期)2020-09-11 07:57:42
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2020年5期)2020-06-02 09:19:08
商周刊(2017年9期)2017-08-22 02:57:49
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國(guó)記者(2016年6期)2016-08-26 12:36:20
時(shí)代英語(yǔ)·高二(2015年1期)2015-03-16 00:08:11
中國(guó)衛(wèi)生(2014年11期)2014-11-12 13:11:32
體育師友(2011年2期)2011-03-20 15:29:29
