SQL Server數(shù)據(jù)庫到HBase數(shù)據(jù)庫的模式轉(zhuǎn)換和數(shù)據(jù)遷移研究
2016-11-19 06:10:36張華東邵秀麗吳軍王志剛
智能計(jì)算機(jī)與應(yīng)用 2016年5期
關(guān)鍵詞:模式
張華東 邵秀麗 吳軍 王志剛
摘要:大數(shù)據(jù)背景下,SQL Server關(guān)系型數(shù)據(jù)庫的存儲容量暴漲,如何高效的實(shí)現(xiàn)把SQL Server數(shù)據(jù)庫中的數(shù)據(jù)遷移到HBase分布式數(shù)據(jù)庫,是亟需解決的一個(gè)關(guān)鍵問題。討論研究了兩種數(shù)據(jù)庫之間的差異之后,首先提出了數(shù)據(jù)庫模式之間的轉(zhuǎn)換,把SQL Server數(shù)據(jù)表的模式,按照不丟失關(guān)系的原則,轉(zhuǎn)換成HBase下的表模式;然后根據(jù)不同的表間關(guān)系的數(shù)據(jù)遷移的規(guī)則,實(shí)現(xiàn)SQL Server數(shù)據(jù)庫中的數(shù)據(jù)遷移到HBase數(shù)據(jù)庫。因?yàn)楸黹g轉(zhuǎn)換關(guān)系和數(shù)據(jù)遷移規(guī)則的預(yù)定義,實(shí)現(xiàn)了一鍵完成數(shù)據(jù)的遷移。
關(guān)鍵詞:SQLServer;HBase;遷移;模式;轉(zhuǎn)換
中圖分類號 TP393 文獻(xiàn)標(biāo)識碼 A
0 引言
SQL Server是關(guān)系型數(shù)據(jù)庫、按行存儲,而HBase是分布式的非關(guān)系型數(shù)據(jù)庫、按列存儲。由于各自的這些特點(diǎn),在建立數(shù)據(jù)庫表模式時(shí),SQL Server須指定表名、表中所有的字段及類型和主外鍵[1];而HBase在建立表模式時(shí),須指定表名、列族和行鍵,但具體的列族中有哪些列是在插入數(shù)據(jù)時(shí)以鍵值對的形式出現(xiàn),并且表間沒有主外鍵的關(guān)聯(lián)關(guān)系[2]。基于兩者的這些不同特點(diǎn),本文首先給出了SQL Server數(shù)據(jù)庫到HBase數(shù)據(jù)庫表模式轉(zhuǎn)換的解決方案。HBase數(shù)據(jù)庫中各個(gè)列族的數(shù)據(jù)會分散存儲到不同的節(jié)點(diǎn),而相互之間通過行鍵關(guān)聯(lián)[3][4]。在SQL Server中關(guān)系表的數(shù)據(jù),須存儲到同一張HBase表的不同列族,才能在不損失效率的情況下實(shí)現(xiàn)快速有效查找。如何根據(jù)表模式轉(zhuǎn)換的規(guī)則[5-6],從SQL Server數(shù)據(jù)庫中獲取到關(guān)聯(lián)的數(shù)據(jù),然后準(zhǔn)確的插入到HBase表的對應(yīng)列族中,文中研究給出了在適應(yīng)大數(shù)據(jù)量的情況下,基于分頁的數(shù)據(jù)遷移方案[7][8]。
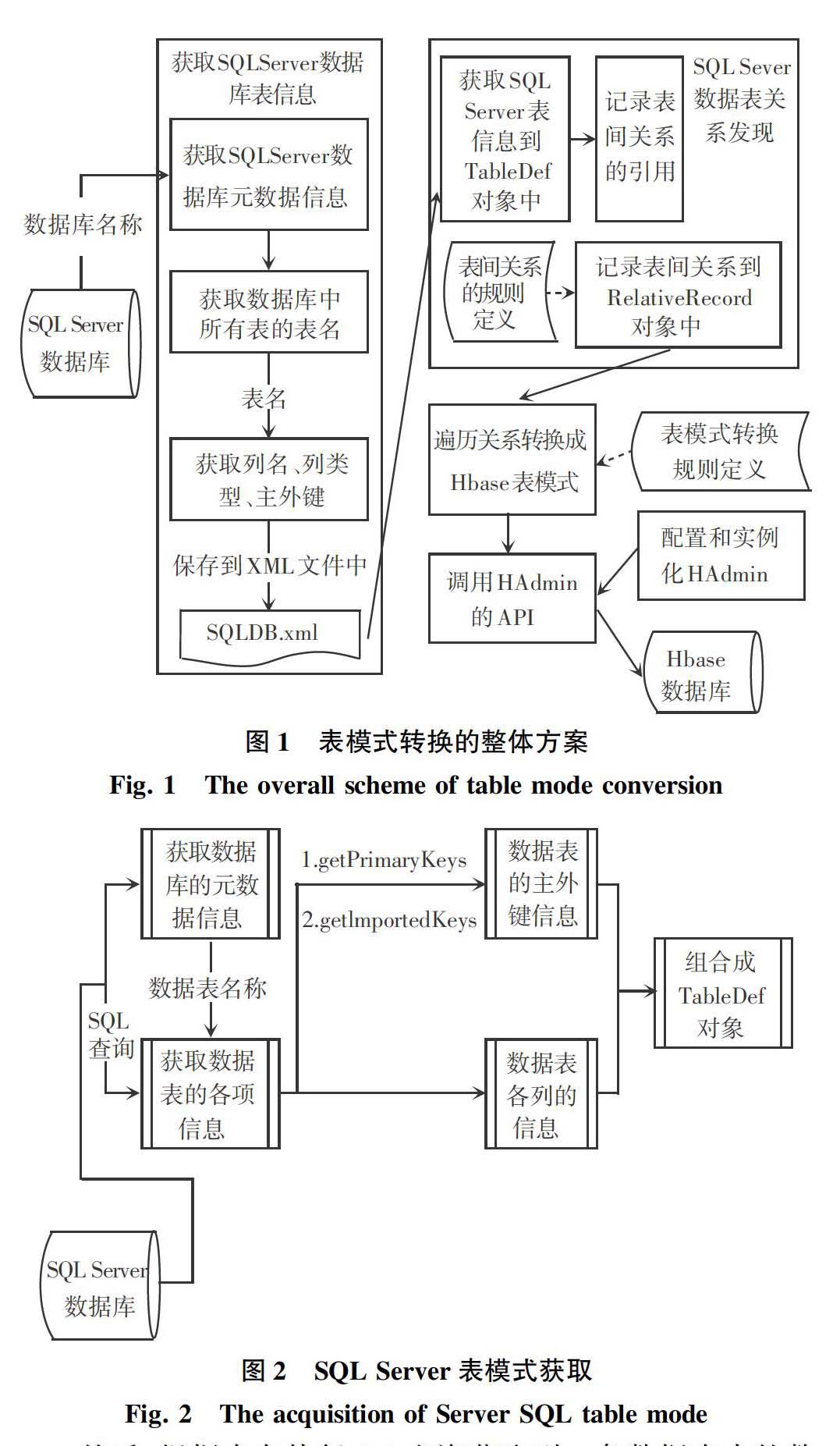
1 表模式轉(zhuǎn)換的整體解決方案
通過連接SQLServer數(shù)據(jù)庫,獲取指定數(shù)據(jù)庫中所有表的相關(guān)信息(列名、列類型、主鍵、外鍵),然后根據(jù)表間關(guān)系的規(guī)則定義去發(fā)現(xiàn)SQLServer數(shù)據(jù)表中的關(guān)系,最后根據(jù)表模式轉(zhuǎn)換規(guī)則定義,遍歷關(guān)系轉(zhuǎn)換成HBase表模式[9]。調(diào)用Java的工具包,配置和實(shí)例化HAdmin對象,調(diào)用添加HBase表列族的API函數(shù)把轉(zhuǎn)換后的表模式執(zhí)行到HBase數(shù)據(jù)庫,從而建立HBase表模式,整體方案如圖1所示。
2 獲取Sql Server數(shù)據(jù)庫表模式
數(shù)據(jù)庫表模式的主要信息包括表名、列名、列類型、列約束以及主鍵、外鍵信息。數(shù)據(jù)庫表模式的獲取,也就是先獲取到所有的數(shù)據(jù)庫表的表名稱,根據(jù)表名稱依次獲取主外鍵、列的相關(guān)信息,再將數(shù)據(jù)保存到TableDef的對象中,圖2給出了獲取Sql Server數(shù)據(jù)庫表模式的處理過程。
獲取Sql Server數(shù)據(jù)庫中指定數(shù)據(jù)庫的所有表的表模式按照如下步驟設(shè)計(jì)展開:
首先,執(zhí)行StringBuffer sql = new StringBuffer("Select NAME FROM ") .append(database).append("..SysObjects Where XType='U' ORDER BY Name");SQL查詢得到數(shù)據(jù)庫中所有的用戶表的表名稱,并保存到List
然后,根據(jù)表名執(zhí)行Sql查詢獲取到一條數(shù)據(jù)表中的數(shù)據(jù),得到結(jié)果集rs;rs.getMetaData()來解析提取到該數(shù)據(jù)表的元數(shù)據(jù)信息ma,至此就可以得到表的列數(shù)ma.getColumnCount(),以及各列的詳細(xì)信息,包括列名Ma.getColumnName(i)、列類型ma.getColumnTypeName(i)、列類型長度ma.getColumnDisplaySize(i),其中i表示當(dāng)前結(jié)果集中列的序號。
最后,就是獲取表的主外鍵和關(guān)聯(lián)關(guān)系信息,這也是把Sql Server數(shù)據(jù)庫表模式轉(zhuǎn)換到Hbase表模式的最重要的信息。具體的實(shí)現(xiàn)過程如下:
先通過meta =JDBCSqlTest.getConnection().getMetaData();取得數(shù)據(jù)庫連接元數(shù)據(jù),數(shù)據(jù)庫的元數(shù)據(jù)信息包括了數(shù)據(jù)庫中所有表的主鍵、外鍵及其他信息,這里只關(guān)注主外鍵的信息,并且可根據(jù)表名查找到指定表的主外鍵信息。
獲取數(shù)據(jù)庫表的主鍵的信息,可通過meta.getPrimaryKeys(null, null, tableName);獲取到主鍵信息引用key。表中的主鍵列,具有相同的主鍵名,主鍵列COLUMN_NAME通過key.getString("COLUMN_NAME")獲取,主鍵名PK_NAME則可通過key.getString("PK_NAME")得到。再使用key.next()可以獲取下一條主鍵信息,直到為空可以獲取到該表所有主鍵信息。
獲取數(shù)據(jù)庫表的外鍵的信息,可通過meta. getImportedKeys (null, null, tableName);獲取到外鍵信息頭指針forignKey。每個(gè)表可與其他多張表發(fā)生關(guān)聯(lián),因此就會有多組外鍵關(guān)系,每組外鍵關(guān)系都有特定的外鍵名,該表的哪幾列與另一張表的哪幾列關(guān)聯(lián)。這里表的外鍵信息記錄就比較復(fù)雜,下面做具體說明。
因?yàn)橥粋€(gè)外鍵關(guān)系,所關(guān)聯(lián)的數(shù)據(jù)庫表是唯一的,在關(guān)系記錄時(shí),使用外鍵名作為鍵值,通過實(shí)例化外鍵組對象時(shí),就可以唯一指定外鍵的關(guān)聯(lián)表。該表的外鍵列與關(guān)聯(lián)表的列就可以一一對應(yīng),從而完整記錄外鍵的關(guān)聯(lián)信息。使用forignKey.next()可以獲取下一條外鍵信息,直到為空即可得到該表所有外鍵信息。
以上獲取到的數(shù)據(jù)庫所有表的信息都會寫到一個(gè)XML文件中。XML文件是較為通用的數(shù)據(jù)交換的文件格式,作為一個(gè)中間結(jié)果的保存[10]。這里也是考慮到實(shí)現(xiàn)的擴(kuò)展性,以及可檢測性。如果用戶在經(jīng)過模式轉(zhuǎn)換后,對結(jié)果的正確性仍無法評判,就可以查看XML文件,如此即能較直接的發(fā)現(xiàn)不準(zhǔn)確的問題所在。
3 SQL Server表間關(guān)系的讀取
根據(jù)已經(jīng)獲取的SQL Server表模式信息,建立表模式對象間的引用關(guān)系。由此即可總結(jié)出關(guān)系查詢蘊(yùn)含的一般性的規(guī)律,按此規(guī)律則可自動(dòng)搜索表間的關(guān)系[11-12],從而依據(jù)不同的表間關(guān)系執(zhí)行不同的模式轉(zhuǎn)換。
讀取生成的SQL Server數(shù)據(jù)庫表的XML文件,首先判斷該表是否有外鍵,如果有,根據(jù)外鍵關(guān)系,可讀取外鍵關(guān)系表,然后遞歸檢查外鍵關(guān)系,直到該表沒有外鍵時(shí),按表名實(shí)例化該表的TableDef對象。對于有外鍵關(guān)系表的表實(shí)例化,須把外鍵關(guān)系表的對象的引用記錄下來,在接下來研究展開表間關(guān)系的發(fā)現(xiàn)時(shí),將能夠直接獲取到關(guān)系表的實(shí)例。
可以直接通過獲取到的TableDef對象的ForeignKeyGroup的pkTableName,得到關(guān)聯(lián)表的表名,遍歷TableDef列表找到表名相同的對象,返回對象,并將其加入到當(dāng)前表的關(guān)聯(lián)表的列表中即可。繼續(xù)判斷是否還有其他的外鍵關(guān)聯(lián)表,如果有可針對性地根據(jù)表名查到下一個(gè)關(guān)聯(lián)表的對象,加入到關(guān)聯(lián)表列表中。實(shí)現(xiàn)過程的查找步驟如下:
1)獲取到每個(gè)外鍵組的PKTableName即關(guān)聯(lián)表的表名;
2)根據(jù)表名查找到表對象,并返回;
3)把返回的表對象保存在該表的關(guān)聯(lián)表列表中。查找是否還有下一個(gè)關(guān)聯(lián)表,如果有則回到第一步繼續(xù)執(zhí)行。
查找過程中,通過表名查找TableDef列表,假設(shè)SQLServer表個(gè)數(shù)為n,每個(gè)表的關(guān)聯(lián)表的個(gè)數(shù)為k,最大時(shí)間復(fù)雜度為n*(n-k-1+n-k-2+…+n)=n*(kn-3k2/2+k/2)=kn2-3k2n/2+kn/2(即O(n2))。使用列表存儲表對象,最大時(shí)間復(fù)雜度較高,在實(shí)例化每個(gè)TableDef時(shí),考慮根據(jù)表名的頻繁查詢,可以使用Hash表結(jié)構(gòu),表名作為key值,實(shí)例對象作為value存儲。至此最大時(shí)間復(fù)雜度就變成了O(n)。
這樣就直接建立了表和相關(guān)聯(lián)表之間的直接引用關(guān)系,在查找表表間特定關(guān)系時(shí),能夠較快地獲取到關(guān)系間的特征,以及關(guān)聯(lián)表的詳細(xì)內(nèi)容詳情。
綜合上述得到的表間的關(guān)系,可通過深度遍歷每張表,從而找到與該表關(guān)聯(lián)的其他所有表的信息。但是對于實(shí)際的數(shù)據(jù)庫系統(tǒng),在建立表以及確定表間的關(guān)系的過程中,研究發(fā)現(xiàn)真正用于連接多張表的特征復(fù)雜查詢時(shí)[13-14],對關(guān)系表間的層次關(guān)系低于3層的這些表的查詢較為頻繁,而且此時(shí)也能夠滿足大多數(shù)系統(tǒng)的需求。
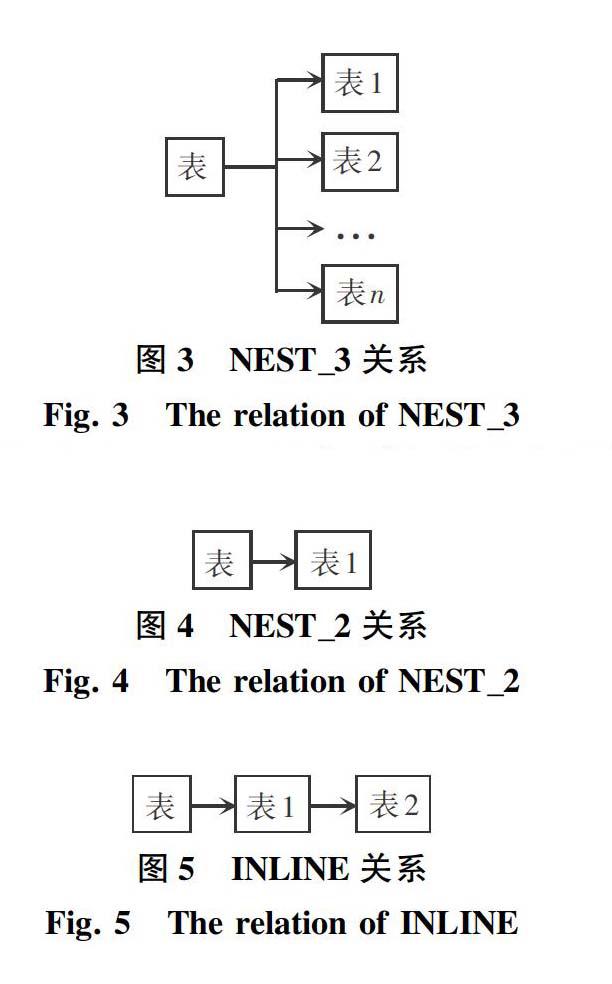
為簡化問題的復(fù)雜性,僅考慮3種表之間的關(guān)系。各類關(guān)系的內(nèi)容概述如下。
1) NEST_3關(guān)系。一張表包含兩張以上的關(guān)系表,如圖3所示。
圖3 NEST_3關(guān)系
Fig.3 The relation of NEST_3
通過遍歷所有Sql Server的表,執(zhí)行前述步驟得到表的列表,若關(guān)聯(lián)表的個(gè)數(shù)大于1,即認(rèn)為該表與關(guān)聯(lián)表之間是NEST_3的關(guān)系。此時(shí)該表作為關(guān)系記錄對象中的主表,關(guān)聯(lián)表的列表作為關(guān)系記錄中的關(guān)系表的列表。
2) NEST_2關(guān)系。一張表僅包含一張關(guān)系表,并且該關(guān)系表沒有其他關(guān)系表,如圖4所示。
通過遍歷所有Sql Server的表,執(zhí)行前述步驟得到表的列表,若關(guān)聯(lián)表的個(gè)數(shù)等于1,然后得到關(guān)系表。若關(guān)系表的關(guān)聯(lián)表的個(gè)數(shù)為0,則定義為NEST_2的關(guān)系。此時(shí)該表作為關(guān)系記錄對象中的主表,關(guān)聯(lián)表作為關(guān)系記錄中的關(guān)系表。
3) INLINE關(guān)系。一張表僅包含一張關(guān)系表,并且該關(guān)系表至少包含一個(gè)其他關(guān)系表,如圖5所示。
通過遍歷所有Sql Server的表,以上步驟得到的表的列表,若關(guān)聯(lián)表的個(gè)數(shù)等于1,然后得到關(guān)系表。若關(guān)系表的關(guān)聯(lián)表的個(gè)數(shù)大于0,則該關(guān)系為INLINE的關(guān)系。此時(shí)該表作為關(guān)系記錄對象中的主表,一級關(guān)系表和各個(gè)二級關(guān)系表分別作為多個(gè)INLINE關(guān)系的關(guān)系記錄中的關(guān)系表。
以上得到了所有自定義的關(guān)系,但是不難推知這種關(guān)系發(fā)現(xiàn)的算法,在得到全部自定義關(guān)系的同時(shí),會產(chǎn)生關(guān)系的包含,為此就需要去除已經(jīng)存在關(guān)系包含的關(guān)系,隨即將研究引進(jìn)一個(gè)去重的操作。
這里關(guān)系的查找,本文遵循的是逐個(gè)遍歷所有的TableDef表,并且根據(jù)每個(gè)表記錄的關(guān)聯(lián)表的個(gè)數(shù),決定查找的類型(NEST_3/NEST_2/INLINE)。比如,如前文所述的當(dāng)前表的關(guān)聯(lián)表的個(gè)數(shù),大于1時(shí),進(jìn)行NEST_3關(guān)系的查找;等于1時(shí),進(jìn)行NEST_2和INLINE關(guān)系的查找,進(jìn)一步地找到關(guān)聯(lián)表,再一步遞歸查找,但查找層數(shù)卻僅限為3。鑒于層數(shù)的限制,顯然可見此時(shí)的時(shí)間復(fù)雜度則為O(n)。
根據(jù)關(guān)系的定義進(jìn)行分析可知,重復(fù)的關(guān)系產(chǎn)生,必然是在2個(gè)表的關(guān)系和2個(gè)以上的表關(guān)系之間。更為確切地說,就是NEST_2關(guān)系的只可能與INLINE關(guān)系的關(guān)聯(lián)表重復(fù),或者與NEST_3中的其中一個(gè)關(guān)系重復(fù)。最終就會得到如下的關(guān)系形式。算法過程如下:
1) 遍歷所有的已找到的關(guān)系列表,當(dāng)前關(guān)系與列表中后面的每個(gè)關(guān)系依次比較。
2) 判斷當(dāng)前關(guān)系與被比較關(guān)系中哪方的關(guān)系類型是NEST_2,如果都不是則返回null,說明當(dāng)前關(guān)系不是重復(fù)的關(guān)系。其中一個(gè)是NEST_2,進(jìn)入下一步。
3) 若當(dāng)前關(guān)系NEST_2關(guān)系間的比較過程如圖6所示。
此時(shí),假定已找到關(guān)系的個(gè)數(shù)為n,去重的操作為兩兩之間的比較,總的比較次數(shù)為
,因此時(shí)間復(fù)雜度為O(n2)。
關(guān)系去重之后得到的關(guān)系中同一類別的關(guān)系,在同一個(gè)類型名稱下面作為其中的一個(gè)分組。獲取到的所有數(shù)據(jù)表的關(guān)系的信息都會保存到RelativeRecord對象列表中。
4 HBase表模式的創(chuàng)建
由于HBase表都是獨(dú)立的表,表間沒有關(guān)系建立的字段描述,因此在SQL Server表模式轉(zhuǎn)換到HBase表模式時(shí),須關(guān)注的就是表間的關(guān)系如何轉(zhuǎn)換到HBase的一張表中[15]。考慮到HBase表有列族的概念,每個(gè)列族又可以有不同的列,這就可以把表間關(guān)系記錄到HBase表的列族之間的關(guān)系,從而能夠較好地保存SQL Server表間的關(guān)系。以下分別對表和表間關(guān)系的轉(zhuǎn)換進(jìn)行分析。
首先是把每個(gè)基本表的表模式變換到Hbase表模式,變換的規(guī)則是Sqlserver的表名作為Hbase的表名,該表的表名同時(shí)作為Hbase第一個(gè)列族的列族名,該表的字段名作為該列族的列名,如圖7所示。重要的是,把該表的主鍵列指定為Hbase表的行鍵列。
逐個(gè)遍歷SQL Server數(shù)據(jù)庫獲取到的TableDef列表中的對象,根據(jù)TableDef的Name屬性實(shí)例化HTableDef對象,獲取到TableDef的主鍵,設(shè)置為HTableDef行鍵列。這一數(shù)據(jù)表的基本變換,就是確保所有的數(shù)據(jù)表在HBase中都有對應(yīng)的表名存在。實(shí)際執(zhí)行過程如圖8所示。
此后,將是根據(jù)關(guān)系中的主表的表名找到Hbase中對應(yīng)的Hbase表,繼而循環(huán)遍歷相關(guān)表,把相關(guān)表作為該Hbase表的列族加入,相關(guān)表的字段作為新列族的列,相關(guān)表的表名作為新列族的列族名稱,如圖9所示。
在定義HBase表的描述時(shí),其實(shí)僅需描述HBase表有哪些列族即可。研究指出每個(gè)列族有一些列,只是用于提供說明在數(shù)據(jù)導(dǎo)出完成后,整個(gè)HBase表的一個(gè)完整的結(jié)構(gòu)描述。為了做到SQL Server語法的解析通過[16],能夠更好地對結(jié)果數(shù)據(jù)集進(jìn)行精確篩選,也就是把原相關(guān)表中的列名作為HBase表中這個(gè)列族的列,保證了數(shù)據(jù)列名的一致性。
如前探討所述,通過給每一個(gè)表都建立了同名的HBase表,在遍歷關(guān)系的過程中,需要根據(jù)主表的表名,迅速定位到該HBase表的實(shí)例化對象。為了能夠在表的數(shù)量較為可觀時(shí),達(dá)成這一目的,即需在建立HBase對象時(shí),將每個(gè)HBase對象都保存到Map
其中,判斷是否有下一個(gè)關(guān)聯(lián)表,目的是把關(guān)聯(lián)表作為主表的列族添加到Hbase表的定義中。Hbase表在建立初始,需要制定HBase的表名和列族這些關(guān)鍵的信息,此時(shí)關(guān)于列族中的列的數(shù)目,在Hbase表的生成描述中,可以無需指定,而只是當(dāng)插入數(shù)據(jù)表中數(shù)據(jù)時(shí)再真實(shí)呈現(xiàn)每個(gè)列族中包含有哪些列即可。
為了保存表間的關(guān)系,HBase數(shù)據(jù)表的冗余存儲即已成為必須。每個(gè)關(guān)系中的主表在Hbase中都有對應(yīng)表名的表存在,在關(guān)系表模式的轉(zhuǎn)換過程中,假設(shè)關(guān)系有n個(gè),關(guān)系中關(guān)聯(lián)表的個(gè)數(shù)為k(k 把HBase表模式使用JAR包提供的API創(chuàng)建到HBase分布式數(shù)據(jù)庫中,其數(shù)據(jù)的流向和處理如圖11所示。 通過表模式轉(zhuǎn)換的操作把生成的Hbase表結(jié)構(gòu)創(chuàng)建到Hbase數(shù)據(jù)庫,可以循環(huán)遍歷已經(jīng)得到的Htable列表,根據(jù)Htable得到的Htable實(shí)例對象,首先檢查Hbase數(shù)據(jù)庫中是否已經(jīng)存在該表,若存在直接刪除,然后再重新創(chuàng)建該表。創(chuàng)建Hbase表時(shí),根據(jù)名稱實(shí)例化HTableDescriptor對象htd,向該對象加入Htable表的列族,最后HBaseAdmin對象執(zhí)行createTable(htd)即可把該Hbase表成功建立于Hbase數(shù)據(jù)庫中,創(chuàng)建過程如圖12所示。 很顯然,在妥善結(jié)束了Hbase表的描述后,此時(shí)關(guān)于HBase表的創(chuàng)建工作,只是遍歷n個(gè)表項(xiàng),也就是在O(n)的時(shí)間內(nèi)就會完成。 實(shí)現(xiàn)數(shù)據(jù)庫中多張數(shù)據(jù)表間存在關(guān)系,研究可以下面的3張表間的關(guān)系作為例子,說明程序?qū)崿F(xiàn)關(guān)系的查詢,及最后形成的Hbase結(jié)構(gòu)。 Comment表作為一個(gè)關(guān)系表,記錄User對Goods的評價(jià)信息,一個(gè)用戶可以對多個(gè)商品進(jìn)行評價(jià),同一個(gè)商品也能得到多個(gè)用戶的評價(jià),表間的關(guān)聯(lián)信息如圖13所示。在數(shù)據(jù)庫中則表現(xiàn)為NEST_3的關(guān)系形式,自動(dòng)轉(zhuǎn)換到HBase數(shù)據(jù)庫中。 通過執(zhí)行程序,NEST_3關(guān)系的發(fā)現(xiàn),會在XML文件中記錄,主表是哪張表,以及關(guān)系中的中間表和關(guān)系表的信息,其中Set集合中第一張表是中間表,第二張表是與主表間有NEST_3關(guān)系的表。此后先對Comment表展開基本的表模式轉(zhuǎn)換生成HTableDef對象,再查找RelativeRecord中以Comment為主表的所有的關(guān)系記錄,根據(jù)表間關(guān)系的轉(zhuǎn)換規(guī)則進(jìn)行表模式的轉(zhuǎn)換,把這種SQL Server數(shù)據(jù)庫中的關(guān)系模式也添加到HTabelDef對象中,由此也就完成了HTableDef對象的生成工作,接下來就是把HTableDef對象記錄的HBase表的模式插入到HBase數(shù)據(jù)庫中。最后循環(huán)遍歷HTable列表,完成HBase表模式的創(chuàng)建, 5 SQL Server數(shù)據(jù)庫數(shù)據(jù)遷移到HBase數(shù)據(jù)庫 根據(jù)SQLServer數(shù)據(jù)庫表的模式轉(zhuǎn)換規(guī)則,以及轉(zhuǎn)換后生成的HBase表,再結(jié)合HBase數(shù)據(jù)插入的特點(diǎn),就可以把已生成關(guān)系的表中的數(shù)據(jù)依次導(dǎo)入到Hbase數(shù)據(jù)庫中[17]。 在分析Hbase數(shù)據(jù)庫數(shù)據(jù)插入方法的基礎(chǔ)上,針對每個(gè)SQL Server數(shù)據(jù)表得到數(shù)據(jù)集,每一行按列名和對應(yīng)值實(shí)例化Put對象,Put對象實(shí)例化的參數(shù)為該行數(shù)據(jù)的主鍵值。如果是關(guān)聯(lián)表,根據(jù)主表外鍵的值作為關(guān)聯(lián)表的主鍵值,查詢得到關(guān)聯(lián)表的信息,進(jìn)而添加到Put對象中。最后執(zhí)行HBase接口,執(zhí)行到HBase數(shù)據(jù)庫中[18]。整體方案如圖14所示。 這里分為主表數(shù)據(jù)的導(dǎo)入和關(guān)聯(lián)表數(shù)據(jù)的導(dǎo)入。主表數(shù)據(jù)的導(dǎo)入相對比較簡單,只是查詢到所有的數(shù)據(jù),使用主鍵列的值作為行鍵實(shí)例化Put對象,再把列名和列對應(yīng)的值,依次添加到Put對象即可。關(guān)聯(lián)表數(shù)據(jù)的插入相對復(fù)雜,需要先根據(jù)關(guān)系獲取每個(gè)行鍵對應(yīng)的關(guān)聯(lián)表的數(shù)據(jù),然后再根據(jù)行鍵實(shí)例化對象,依次添加行數(shù)據(jù)的所有列和對應(yīng)的值添加到Put對象。其他后續(xù)把生成的Put對象列表,調(diào)用HBase數(shù)據(jù)庫的接口函數(shù)完成數(shù)據(jù)的導(dǎo)入。
HBase數(shù)據(jù)導(dǎo)入,需要使用Hbase數(shù)據(jù)表的行鍵值實(shí)例化Put對象,數(shù)據(jù)插入時(shí),還要制定需插入的鍵值對所在的列族。并且鍵值對中,值必須先根據(jù)對應(yīng)的Java基本數(shù)據(jù)類型轉(zhuǎn)化為byte[]字節(jié)數(shù)組,才能將其作為Put對象的參數(shù)值。
因?yàn)橹灰o定行鍵值,實(shí)例化Put對象,Hbase的API函數(shù)就能把數(shù)據(jù)插入到正確的位置。因此對關(guān)系表的導(dǎo)入,只需要找到該條關(guān)系表數(shù)據(jù)對應(yīng)主表的數(shù)據(jù)的主鍵,即對應(yīng)Hbase表的行鍵,就可以完成關(guān)系表的數(shù)據(jù)插入操作。下面將分別論述基礎(chǔ)表信息的導(dǎo)入和關(guān)聯(lián)表信息的導(dǎo)入。
5.1 基礎(chǔ)表信息的導(dǎo)入
基礎(chǔ)表信息的導(dǎo)入,循環(huán)遍歷HTable表,依次實(shí)現(xiàn)如下的操作過程。
1) 首先執(zhí)行Sqlserver 數(shù)據(jù)庫查詢操作,得到全部數(shù)據(jù)。逐條遍歷每條結(jié)果數(shù)據(jù),得到該條數(shù)據(jù)的行鍵值,使用該行健的值實(shí)例化Put對象。然后獲取該HTable表的表名列族的所有列以及對應(yīng)列的值,根據(jù)列族和列的名稱獲取該列的類型,再把對應(yīng)列的值轉(zhuǎn)換成字節(jié)數(shù)組,最后添加到Put對象中,完成該行一個(gè)列數(shù)據(jù)的導(dǎo)入。循環(huán)完成所有列值添加到put對象。
2) 把所有數(shù)據(jù)行生成的Put對象加入到List
5.2 關(guān)聯(lián)表信息的導(dǎo)入
關(guān)聯(lián)表信息的導(dǎo)入,按模式轉(zhuǎn)換的情況也分為3種情況。首先是循環(huán)遍歷所有的關(guān)系信息列表,然后依據(jù)相應(yīng)情況執(zhí)行下面的操作過程。
1) INLINE關(guān)系
INLINE關(guān)系的記錄形式中,包括了中間的關(guān)聯(lián)表信息,實(shí)質(zhì)上INLINE關(guān)系里主表和關(guān)聯(lián)的中間表之間包含有一組的NEST_2的關(guān)系,具體的數(shù)據(jù)導(dǎo)入可參見2)。2張表之間的INLINE關(guān)系,在數(shù)據(jù)導(dǎo)入時(shí)需借助于中間的關(guān)聯(lián)表,設(shè)計(jì)可概述如下:
先根據(jù)每頁的大小逐頁的得到主表的主鍵和外鍵值的集合,這里的主鍵值作為行鍵的值,用于實(shí)例化Put對象。
循環(huán)遍歷外鍵值的集合,根據(jù)對應(yīng)外鍵的值找到關(guān)系表與主表對應(yīng)的數(shù)據(jù)的行,把該INLINE關(guān)系表的數(shù)據(jù)逐行導(dǎo)入。先是執(zhí)行中間表和INLINE表的關(guān)聯(lián)查詢,其中篩選條件是2張表的關(guān)聯(lián)的鍵值相同并且中間表的主鍵值等于主表的外鍵關(guān)鍵列的值,即會得到對應(yīng)行鍵的INLINE表的所有主鍵值和外鍵值的集合。然后遍歷行鍵的值集合實(shí)例化Put對象,根據(jù)查詢得到的與行鍵相關(guān)的INLINE表的數(shù)據(jù)行, 向Put對象的列族中添加該行每列對應(yīng)的值,完成所有列與列值的添加,把Put對象添加到List
直到行鍵循環(huán)結(jié)束執(zhí)行Hbase的API函數(shù),一次執(zhí)行List
假設(shè)主表有m行數(shù)據(jù),則對應(yīng)的中間表至多有m行(數(shù)據(jù)表之間的一對一、多對一的關(guān)系)與之關(guān)聯(lián)。同理,中間表對應(yīng)的INLINE表至多有m行數(shù)據(jù)。根據(jù)主表查找中間表需要O(m)的時(shí)間,得到中間表之后,再查找INLINE表需要O(m)的時(shí)間。因此,在INLINE關(guān)系的數(shù)據(jù)導(dǎo)入,時(shí)間復(fù)雜度為O(n)。
2) NEST_2關(guān)系
NEST_2關(guān)系的模式轉(zhuǎn)換,先根據(jù)關(guān)系中主表的表名獲取到HBase表對象,
此后執(zhí)行Sql查詢,得到主表的主鍵和外鍵列對應(yīng)值的集合,保存到List
循環(huán)遍歷主鍵和外鍵值的集合,根據(jù)主鍵列的HBase中的數(shù)據(jù)類型,轉(zhuǎn)換生成字節(jié)數(shù)組rowKey,使用rowKey實(shí)例化Put對象。
根據(jù)關(guān)系表關(guān)系表的主鍵和與主表外鍵對應(yīng)的值,查詢得到關(guān)系表的數(shù)據(jù)結(jié)果集合。按行遍歷結(jié)果集合,按列名和值對應(yīng)的形式添加到Put對象中。所有的遍歷結(jié)束得到List
執(zhí)行Hbase的API函數(shù),把List
圖16 NEST_2關(guān)系表信息的導(dǎo)入
Fig. 16 Import of NEST_2 table information
這里NEST_2關(guān)系,是主表與直接外鍵關(guān)聯(lián)表的關(guān)系,假設(shè)主表有n行,與之關(guān)聯(lián)表就有n行,遍歷n行數(shù)據(jù),根據(jù)主表主鍵實(shí)例化對象,調(diào)用api插入HBase數(shù)據(jù)庫,其時(shí)間復(fù)雜度也就是O(n)。
3) NEST_3關(guān)系
這種關(guān)系的導(dǎo)入,就是多個(gè)Nest_2關(guān)系的導(dǎo)入。具體地,Nest_3關(guān)系中的主表和其他關(guān)聯(lián)表之間均按照NEST_2關(guān)系的導(dǎo)入方式進(jìn)行導(dǎo)入,循環(huán)遍歷所有的關(guān)聯(lián)表,完成NEST_3關(guān)系的導(dǎo)入。
6 實(shí)驗(yàn)結(jié)果對比分析
從SQL Server向HBase數(shù)據(jù)庫遷移數(shù)據(jù),因?yàn)橐A糁暗年P(guān)系,HBase數(shù)據(jù)庫中必然要有更多數(shù)據(jù)冗余,才能夠通過單張表把關(guān)系給記錄下來。數(shù)據(jù)庫中的關(guān)系越復(fù)雜,主表中的數(shù)據(jù)越多這種冗余就會越大。為了使數(shù)據(jù)遷移的結(jié)果較為明顯,以少量數(shù)據(jù)為例進(jìn)行對比說明,更為清楚。
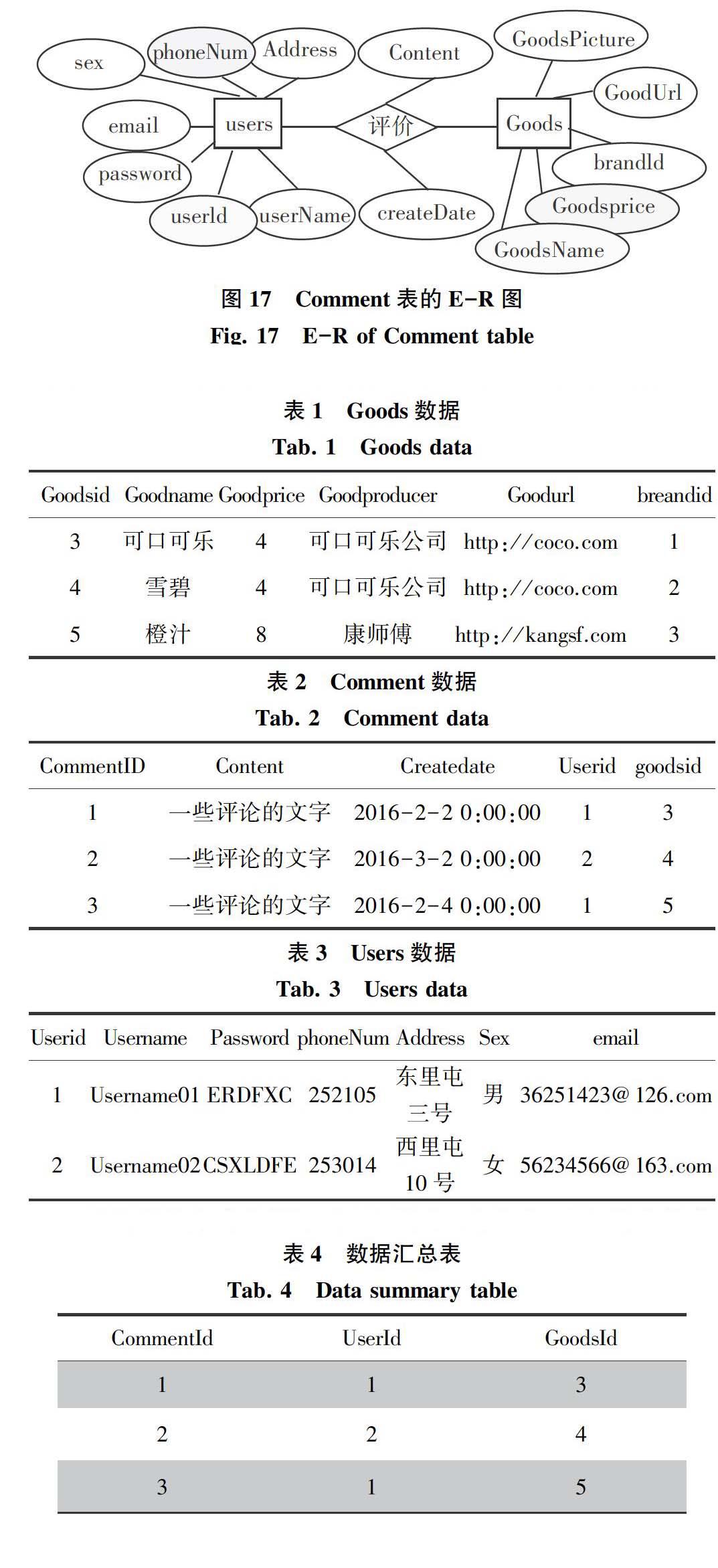
首先,對比說明中構(gòu)建了3張表,在SQL Server數(shù)據(jù)庫中的關(guān)系是NEST_3關(guān)系。Comment表記錄的是Users表中某個(gè)User對Goods表中某個(gè)Good的評價(jià)信息,很明顯形成了如圖17所示的ER關(guān)系。
圖17 Comment表的E-R圖
Fig.17 E-R of Comment table
其中,每張表對應(yīng)的實(shí)驗(yàn)數(shù)據(jù)如表1~表3所示。考慮到數(shù)據(jù)庫字段中/英文的差異,在實(shí)驗(yàn)數(shù)據(jù)的填寫上,既有中文、又有英文。而在研究的HBase數(shù)據(jù)庫中,中文的字段值在Scan查詢中是無法確認(rèn)查看的,而英文的字段值,卻能夠通過列的value屬性直接查看得到,從而驗(yàn)證導(dǎo)入數(shù)據(jù)的正確性。
根據(jù)當(dāng)前表中的數(shù)據(jù),匯總到同一張表中,可得綜合簡要結(jié)果。這里Comment表作為主表,根據(jù)Comment表的UserId/goodsId字段的值,可以得到如下的結(jié)果,如表4所示。
分析以上的關(guān)聯(lián)關(guān)系,可知Hbase表中應(yīng)該有3行數(shù)據(jù),每行數(shù)據(jù)的行鍵依次為1/2/3,行鍵的值轉(zhuǎn)換為byte[]字節(jié)數(shù)組后的值依次為\x00\x00\x00\x01,\x00\x00\x00\x02,\x00\x00\x00\x03。對應(yīng)行鍵1的Users列族的userId為1,即column=Users:userId, value=\x00\x00\x00\x01;Goods列族的goodsId為3,即column=Goods:goodsId, value=\x00\x00\x00\x03。其他類推,并且要確保列族的列的數(shù)量要與SQL Server表的字段數(shù)相同。
在此,針對HBase數(shù)據(jù)庫進(jìn)行查詢,由HBase查詢得到的結(jié)果數(shù)據(jù)集,能夠看出Goods和Users的重復(fù)內(nèi)容較多。Comment表中已經(jīng)有了Users和Goods表的主鍵的值,然而在Users和Goods列族中該列的值仍會重復(fù)出現(xiàn)。
由研究查詢結(jié)果還能看到Users和Goods列族中都有特殊的列,比如vipId/brandId,這2個(gè)列明顯是其他表的主鍵,當(dāng)前列族的外鍵。也就是NEST_3關(guān)系,并沒有遞歸到所有的關(guān)聯(lián)表,然后在同一張表中保存相關(guān)的數(shù)據(jù)。因此,這種模式轉(zhuǎn)換和數(shù)據(jù)遷移,只能夠有效的處理和保存原SQLServer數(shù)據(jù)表的比較直接的關(guān)聯(lián)表中關(guān)系。
7 結(jié)束語
本文通過設(shè)計(jì)和實(shí)現(xiàn)SQL Server數(shù)據(jù)庫中表模式的轉(zhuǎn)換和表中數(shù)據(jù)的遷移,分析了過程中算法實(shí)現(xiàn)和表間關(guān)系的定義,綜合考慮SQL Server數(shù)據(jù)庫和HBase數(shù)據(jù)庫之間的不同,針對彼此的特點(diǎn)實(shí)現(xiàn)了兩者數(shù)據(jù)庫中數(shù)據(jù)的一鍵模式轉(zhuǎn)換和數(shù)據(jù)遷移。通過對遷移前后,各數(shù)據(jù)庫中數(shù)據(jù)的對比分析,本文提出的解決方案能夠正確實(shí)現(xiàn)數(shù)據(jù)遷移,并且有效保留了SQL Server數(shù)據(jù)表間的關(guān)系。
HBase作為非關(guān)系型數(shù)據(jù)庫,在保留原有SQLServer數(shù)據(jù)表間關(guān)系的同時(shí),勢必形成數(shù)據(jù)的冗余。并且本文在表間關(guān)系的自動(dòng)發(fā)現(xiàn)的規(guī)則定義,僅考慮了3級的層次關(guān)系,對于一般的數(shù)據(jù)庫是適用的。在不同的應(yīng)用場景下,還需根據(jù)特定的需求設(shè)計(jì)具有針對性的表間關(guān)系的規(guī)則定義。
參考文獻(xiàn)
[1] 王堪美. 基于數(shù)據(jù)分發(fā)服務(wù)的監(jiān)控與存儲研究[D]. 北京:中國科學(xué)院大學(xué), 2013.
[2] 馮曉普. HBase存儲的研究與應(yīng)用[D]. 北京:北京郵電大學(xué), 2014.
[3] GEORG L. HBase: The Definitive Guide[J]. Andre, 2011, 12(1):1 - 4.
[4] TAYLOR R C. An overview of the Hadoop/MapReduce/HBase framework and its current applications in bioinformatics[J]. Bmc Bioinformatics, 2010, 11 Suppl 12(6):3395-3407.
[5] 李穎, 李建民, 林振榮. 用JSP/Servlet和JavaBeans技術(shù)實(shí)現(xiàn)SQL Server表與DBF文件的相互轉(zhuǎn)換[J]. 計(jì)算機(jī)與現(xiàn)代化, 2007(1):95-97.
[6] 劉雅輝. DBMS間模式轉(zhuǎn)換技術(shù)應(yīng)用研究[D]. 北京:北方工業(yè)大學(xué), 2009.
[7] 舒清錄. 基于.NET的異構(gòu)數(shù)據(jù)源數(shù)據(jù)遷移技術(shù)[J]. 計(jì)算機(jī)技術(shù)與發(fā)展, 2010, 20(3):109-112.
[8] 胡曉鵬, 李曉航, 李崗. 一種基于XML映射規(guī)則的數(shù)據(jù)遷移方法設(shè)計(jì)和實(shí)現(xiàn)[J]. 計(jì)算機(jī)應(yīng)用, 2005, 25(8):1849-1852.
[9] (美)George. HBase權(quán)威指南[M]. 北京:人民郵電出版社, 2013.
[10] 李雯, 謝輔雯, 鄒道明. XML數(shù)據(jù)交換技術(shù)的應(yīng)用與研究[J]. 計(jì)算機(jī)與現(xiàn)代化, 2008(1):91-93.
[11] 王晴. 關(guān)系數(shù)據(jù)庫與SQL Server教程(教材)[M]. 北京:中國人民大學(xué)出版社, 2009.
[12] 尼馬·賈拉利, 埃里克·塞德拉, 尼普恩·阿加瓦爾,等. 用于訪問關(guān)系型數(shù)據(jù)庫系統(tǒng)中的分層數(shù)據(jù)的高效索引結(jié)構(gòu): 美國,CN02819168.4[P].2005-01-05.
[13] KENT W. A simple guide to five normal forms in relational database theory[J]. Communications of the ACM,1983,26(2): 120-125.
[14] Cattell R. Scalable SQL and NoSQL data stores[J]. ACM SIGMOD Record, 2010, 39(4): 12-27.
[15] GEORGE L. HBase: the definitive guide[M]. Sebastopol, USA:O'Reilly Media, 2011.
[16] 孫兆玉, 朱鴻宇, 黃宇光. 一種SQL語法分析的策略和實(shí)現(xiàn)[J]. 計(jì)算機(jī)應(yīng)用, 2007, 27(S1):18-20,23.
[17] 邵開麗, 姜偉, 呂舉文. 一種大規(guī)模數(shù)據(jù)快速并行導(dǎo)入工具的研究與實(shí)現(xiàn)[J]. 計(jì)算機(jī)應(yīng)用與軟件, 2015,32(9):26-30.
[18] YANG J, FENG X. Loading Data into HBase[M]// WONG W E, ZHU T .Computer Engineering and Networking.Switzerland:Springer International Publishing, 2014:265-271.
猜你喜歡
文藝生活·中旬刊(2016年10期)2016-11-04 03:40:25
人間(2016年26期)2016-11-03 17:07:19
中國科技博覽(2016年22期)2016-11-01 15:51:16
電影文學(xué)(2016年16期)2016-10-22 10:48:34
經(jīng)營者(2016年12期)2016-10-21 08:06:21
現(xiàn)代經(jīng)濟(jì)信息(2016年19期)2016-10-20 17:39:15
中國科技博覽(2016年19期)2016-10-19 12:30:02
電腦知識與技術(shù)(2016年21期)2016-10-18 22:37:20
商場現(xiàn)代化(2016年22期)2016-10-18 19:37:38
中國市場(2016年33期)2016-10-18 13:05:21
