基于遺傳算法的反例理解
2016-11-21 05:20:41李雅黃少濱李艷梅遲榮華郎大鵬
哈爾濱工程大學(xué)學(xué)報(bào) 2016年10期
關(guān)鍵詞:模型
李雅,黃少濱,李艷梅,遲榮華,郎大鵬
(哈爾濱工程大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,黑龍江 哈爾濱 150001)
?
基于遺傳算法的反例理解
李雅,黃少濱,李艷梅,遲榮華,郎大鵬
(哈爾濱工程大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,黑龍江 哈爾濱 150001)
在復(fù)雜系統(tǒng)的錯(cuò)誤定位過程中,為了尋找合適的證例,提出一種結(jié)合模型檢測技術(shù)的基于遺傳算法的反例理解算法。利用遺傳算法,針對模型檢測中的模型具有初始狀態(tài),狀態(tài)之間有相應(yīng)的遷移關(guān)系等特點(diǎn),初始化種群、設(shè)計(jì)適應(yīng)度函數(shù)并進(jìn)行指向性的變異操作。實(shí)驗(yàn)表明該算法能快速有效的獲得最近證例,幫助模型檢測的反例理解。
模型檢測;遺傳算法;反例理解;錯(cuò)誤定位
模型檢測[1]是一種驗(yàn)證有限狀態(tài)并發(fā)系統(tǒng)(模型)是否滿足給定規(guī)約的方法[1-2]。當(dāng)驗(yàn)證的模型不滿足給定規(guī)約時(shí)給出反例是模型檢測的一個(gè)顯著特點(diǎn)。反例是證明模型違反給定規(guī)約的執(zhí)行軌跡。調(diào)試者可以通過分析反例,理解錯(cuò)誤產(chǎn)生的原因,對系統(tǒng)或模型進(jìn)行修正。然而反例并沒有明確指出模型錯(cuò)誤的原因,需要調(diào)試者根據(jù)自己的經(jīng)驗(yàn)定位錯(cuò)誤,這需要花費(fèi)大量的時(shí)間才有可能找到真正的錯(cuò)誤,因此使用自動(dòng)化的方法從反例中獲取有用的信息,幫助用戶定位錯(cuò)誤,是目前的研究熱點(diǎn)。許多研究人員致力于研究錯(cuò)誤定位的算法,提出了許多經(jīng)典的算法,如基于路徑的語法級(jí)最弱前置條件的輔助算法[3],利用克雷格插值的證明方法[4],基于因果關(guān)系模型的方法[2,5],基于可滿足性的方法[6-7],以及基于證例和反例差異的方法[8-11]。本文的方法也是基于證反例的差異,證例是模型的一種遷移路徑,并且滿足待驗(yàn)證規(guī)約。為了獲得與反例最接近的證例,本文提出了一種利用遺傳算法獲取證例的方法。遺傳算法 (genetic algorithm, GA)是1975年由John Holland[12]教授提出,在許多研究領(lǐng)域都得以應(yīng)用,例如自動(dòng)控制、數(shù)據(jù)挖掘[13]、機(jī)器學(xué)習(xí)、組合優(yōu)化[14]等。在軟件方面主要用于測試用例的自動(dòng)生成和優(yōu)化選擇,它從代表問題可能潛在解集的一個(gè)種群開始,通過選擇、交叉和變異等操作,使種群逐漸集中于搜索空間中越來越好的區(qū)域。演化的代數(shù)主要取決于代表問題解的收斂狀態(tài),末代種群中的最佳個(gè)體作為問題的最優(yōu)近似解。因此本文構(gòu)建一種基于遺傳算法的,具有普適性的求解最近證例的方法。該方法用Kripke結(jié)構(gòu)來刻畫系統(tǒng)行為,用線性時(shí)態(tài)邏輯LTL描述需要驗(yàn)證的規(guī)約,針對模型檢測中模型的特點(diǎn)初始證例種群,使用兩個(gè)適應(yīng)函數(shù)對應(yīng)的最佳個(gè)體進(jìn)行交叉操作,具有指向性的變異操作,最終獲得末代種群中的最佳個(gè)體,即最近證例。相對于其他的獲取證例的方法,本文在證例搜索的過程中引入啟發(fā)式信息,提高系統(tǒng)狀態(tài)空間搜索的效率,并且由于遺傳算法不依賴于具體問題而直接進(jìn)行搜索,所以本文的方法適用性更強(qiáng),應(yīng)用范圍更廣。
1 模型檢測與GA的基本理論
1.1 模型檢測相關(guān)定義
模型檢測中通常使用狀態(tài)遷移圖來描述系統(tǒng)模型,Kripke結(jié)構(gòu)是一種常用的狀態(tài)遷移圖。本文的待驗(yàn)證模型以Kripke結(jié)構(gòu)表示,首先給出Kripke結(jié)構(gòu)的定義。
令V={v1,v2,…,vn}是一個(gè)有限布爾變量集,Dv1,Dv2,…,Dvn分別為v1,v2,…,vn的數(shù)據(jù)域,定義在V上的Kripke結(jié)構(gòu)為:
定義1 Kripke結(jié)構(gòu)是一個(gè)四元組K=(S,I,T,L)其中:S?Dv1,Dv2,…,Dvn是有限狀態(tài)集合,I?S是初始狀態(tài)集,T?S×S是狀態(tài)遷移關(guān)系,標(biāo)記函數(shù)L:S→2v標(biāo)記在狀態(tài)S真變量的集合。
定義2 定義在Kripke結(jié)構(gòu)K上的路徑π是一個(gè)狀態(tài)序列π=s0,s1,s2…,其中s0∈I,si∈S , i∈N, π(i)=si;πi=si,si+1,si+2…。Path(K)表示K中所有路徑的集合。
定義3 線性時(shí)態(tài)邏輯LTL在每一個(gè)時(shí)刻,只有一個(gè)可能的次態(tài),LTL公式的語法定義如下:
φ::= ⊥| ┬ |p| (φ) | (φ∧φ) | (φ∨φ) | (φ→φ) | (Xφ) | (Fφ) |(Gφ) | (φUφ) | (φWφ) | (φRφ)
其中p是取自某原子集的任意命題原子。X、F、G、U、W和R為時(shí)態(tài)連接詞。分別表示為“下一個(gè)狀態(tài)”(neXt),“某未來狀態(tài)”(Future),“所有未來狀態(tài)”(Globally),“直到”(Until),“弱-直到”(Weak-until)和“釋放”(Release)。
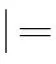
1) π|=p?p∈L(s0)
3) π|=φ1∧φ2?π|=φ1且π|=φ2
4) π|=φ1∨φ2?π|=φ1或π|=φ2
5) π|=φ1→φ2?只要π|=φ1就有π|=φ2
6) π|=Xφ?π2|=φ
7) π|=Gφ ? ?i≥1, πi|=φ
8) π|=Fφ ? ?i≥1, πi|=φ
9) π|=φUφ ? ?i≥1, 使得πi|=φ并且?j=1,2,…,i-1,有πj|=φ
10) π|=φWφ ? ?i≥1,使得πi|=φ并且?j=1,2,…,i-1,有πj|=φ或者?k≥1 ,有πk|=φ
11) π|=φRφ?或者?i≥0,使得πi|=φ,并且?j=1,2,…,i,有πj|=φ;或者?k≥1,有πk|=φ
Biere等提出的有界模型檢測(bounded model checking,BMC)不同于傳統(tǒng)的符號(hào)模型檢測[15],它在有限長度k(稱其為限界)的范圍內(nèi)查找反例。如果在限界k內(nèi)沒有發(fā)現(xiàn)反例,則增加k的值直至問題變得難解,或者達(dá)到預(yù)先設(shè)定的上界。
根據(jù)LTL語義,BMC問題可以規(guī)約為命題可滿足問題,若M為Kripke結(jié)構(gòu)的待驗(yàn)證模型,f為BMC要驗(yàn)證規(guī)約的否定形式的公式,k為界限,第i個(gè)和第i+1個(gè)周期的狀態(tài)為Si和Si+1,狀態(tài)轉(zhuǎn)換關(guān)系為Ti(Si,Si+1),則BMC轉(zhuǎn)換公式可以表示為:[[M,f]]k。
定義5 (BMC轉(zhuǎn)換公式) 設(shè)M為Kripke結(jié)構(gòu),f為待驗(yàn)證的LTL規(guī)約說明否定形式的NNF公式,k為整數(shù),則BMC轉(zhuǎn)換公式為
(1)
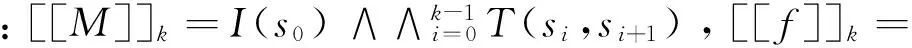
在有界模型檢測方法中,將式(1)轉(zhuǎn)換為CNF格式的SAT問題,并用SAT求解器求解,即可驗(yàn)證模型是否滿足給定規(guī)約。在界限k內(nèi),反例的長度為k,基于界限模型檢測的路徑和反例定義如下:
定義6 反例 在Kripke結(jié)構(gòu)K上,對LTL公式f和界限k,若有π|=kf,則稱π為f的反例。
定義7 證例 在Kripke結(jié)構(gòu)K上,對LTL公式f和界限k,若有π|=kf,且π∈Path(K),則稱π為f的證例。
1.2 反事實(shí)依賴
D.Lewis[16]提出的基于反事實(shí)的原因定義為通過搜索與反例最近證例定位錯(cuò)誤的方法提供了邏輯基礎(chǔ)。Lewis認(rèn)為不同源自于“cause”,如果原因c不發(fā)生則所產(chǎn)生的影響e也不會(huì)發(fā)生,并將原因的定義建立在反事實(shí)依賴的基礎(chǔ)之上。其中反事實(shí)依賴的定義為:
定義8 反事實(shí)依賴 設(shè)在世界w中有命題e和c,則反事實(shí)ce為真,當(dāng)且僅當(dāng)
1)世界w中,命題e和c同時(shí)為真;(即:c(w)∧e(w));
2)存在世界w’,有c(w′)∧e(w′)∧
定義9 (原因) 設(shè)在世界w中,命題c和e同時(shí)為真。則在w中c是e的原因,當(dāng)且僅當(dāng)在世界w′中,ce。
定理1 設(shè)f是待驗(yàn)證規(guī)約,t是反例,w是離t最近的證例,c是t中與w中取值不同的變量的集合,則c是f的原因。
證明:根據(jù)假設(shè)有,在w中有c(w)∧f(w)。假設(shè)存在某條與w不同的路徑w′,有c(w′)∧f(w′),并且d(t,w′)≤d(t,w)。則w′中存在一些其他的與w不同的變量v?D,那么這些變量v在t中的取值必然與w′中的不同。于是d(t,w′)>d(t,w),矛盾,因此w′不存在。在t中有cf,c是f的原因。
1.3 遺傳算法
遺傳算法(GA)是模仿自然界生物遺傳進(jìn)化過程中的“物競天擇、適者生存”的思想,是一種全局尋優(yōu)搜索算法,它首先對問題的可行解進(jìn)行編碼,組成染色體,然后通過模擬自然界的進(jìn)化過程,對初始種群中的染色體進(jìn)行選擇、交叉和變異,通過一代代進(jìn)化來找出最優(yōu)適應(yīng)值的染色體來解決問題。遺傳算法具有很強(qiáng)的全局搜索能力和較強(qiáng)的自適應(yīng)性,適合解決連續(xù)變量函數(shù)優(yōu)化問題和離散變量的優(yōu)化組合問題。
遺傳算法計(jì)算簡單,具有超高的全局搜索能力[17]。在模型檢測中,模型以Kripke結(jié)構(gòu)給出并具有初始狀態(tài),在設(shè)計(jì)遺傳算法的初始種群時(shí),每個(gè)個(gè)體的第一個(gè)基因片段必須是模型的初始狀態(tài),因此初始種群的個(gè)體數(shù)相對較小,算法比較容易達(dá)到收斂狀態(tài)。
定義8給出了最近證例需要滿足的條件,不僅需要滿足待驗(yàn)證規(guī)約還應(yīng)該與反例的距離最近,給遺傳算法應(yīng)用于反例理解提供了適當(dāng)?shù)倪m應(yīng)度函數(shù)。因此遺傳算法適用于模型檢測的中的證例搜索。
表和的遞歸定義
2 基于遺傳算法的證例生成
本節(jié)討論利用遺傳算法來生成與反例最近的證例的算法。反例是當(dāng)模型不滿足待驗(yàn)證規(guī)約時(shí)生成的一條狀態(tài)的序列。證例同樣是模型中的一條狀態(tài)遷移路徑,但是它不違反待驗(yàn)證規(guī)約。最近證例就是離反例最近的證例。本文利用遺傳算法,將最近距離和對于待驗(yàn)證規(guī)約的可滿足度作為檢測最近證例的適應(yīng)度,而最終求得最近證例,幫助自動(dòng)的定位錯(cuò)位。
2.1 編碼
遺傳算法中首要問題就是編碼問題,也是設(shè)計(jì)遺傳算法時(shí)的一個(gè)關(guān)鍵步驟。常見的編碼方法有字符串表示法和鄰接基因位編碼法。本文采用的是字符串編碼方法。按照路徑上狀態(tài)的順序進(jìn)行編碼,具體實(shí)現(xiàn)方式是:按照路徑上狀態(tài)的出現(xiàn)順序,以及標(biāo)簽變量的值進(jìn)行編碼。以圖1的Kripke結(jié)構(gòu)為例,有限長度路徑π=(s0,s1,s2),L(s0)={p,q},L(s1)={q,r}和L(s2)={r}。若狀態(tài)s0編碼為110,s1編碼為011,s2為001。則路徑π的編碼為110011001。
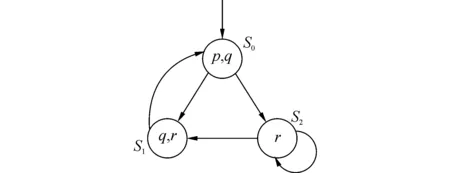
圖1 一個(gè)簡單的Kripke結(jié)構(gòu)Fig.1 A simple Kripke structure
2.2 初始種群生成
在遺傳算法的初始種群中,如果每個(gè)個(gè)體都具備一定的精度且個(gè)體間多樣性較強(qiáng)時(shí),則可以提高算法搜索效率,加速算法收斂。在模型檢測中,模型被表示成一個(gè)Kripke結(jié)構(gòu),而所求的證例具有特定起始點(diǎn),也就是從初始狀態(tài)集的某一個(gè)起始狀態(tài)出發(fā)的系統(tǒng)運(yùn)行路徑。因此與隨機(jī)生成初始群體的方法不同, 本文生成初始種群的方法是基于特定起始點(diǎn)的,試圖能夠快速產(chǎn)生具有一定精度和較強(qiáng)多樣性的初始種群。如定義2所示,系統(tǒng)的運(yùn)行路徑是一個(gè)狀態(tài)的無限序列:
本文中模型的驗(yàn)證使用的是有界模型檢測,反例的長度為k,需要考慮路徑上是否存在循環(huán)。路徑可以表示為
式中:u和v是有限長度的狀態(tài)序列,u=s0,s1……,si-1,v=si,si+1……,sk,i 給定長度k(k≥1),考察從初始狀態(tài)集I單步可達(dá)的所有狀態(tài)的集合S1。依次考察S1中的每一個(gè)狀態(tài)s1,若從s1出發(fā),不存在遷移,則這一狀態(tài)為死鎖狀態(tài);若存在不止一條的遷移,則隨機(jī)選取一條遷移執(zhí)行,獲得路徑中的下一個(gè)狀態(tài)。重復(fù)以上過程,直至得到第k個(gè)狀態(tài)。 如果考察的模型含有n(n∈N+)個(gè)初始狀態(tài),從每個(gè)初始狀態(tài)出發(fā)的遷移數(shù)分別是:x0,x1……,xn,則初始種群的大小為:x0+x1+……+xn。 2.3 適應(yīng)度 為了體現(xiàn)染色體的適應(yīng)能力,引入了對問題中的每一個(gè)染色體都能進(jìn)行度量的函數(shù),叫適應(yīng)度函數(shù)。通過適應(yīng)度函數(shù)來決定染色體的優(yōu)、劣程度,它體現(xiàn)了自然進(jìn)化中的優(yōu)勝劣汰原則,它是評(píng)價(jià)新解優(yōu)劣的唯一標(biāo)準(zhǔn)。 一般而言,適應(yīng)度函數(shù)是直接由目標(biāo)函數(shù)變換而成的,有時(shí)也要根據(jù)問題的要求,對目標(biāo)函數(shù)進(jìn)行一定的適應(yīng)度尺度變換。模型檢測中的證例,需要是模型中的路徑,并且要滿足待驗(yàn)證規(guī)約。與此同時(shí)要求解與反例最近的證例,證例w與反例t的距離d(w,t)越短越好,因此需要將種群中的個(gè)體對于待驗(yàn)證規(guī)約的滿足度s和d(w,t)共同作為遺傳算法的適應(yīng)度函數(shù)。 本文基于有界模型檢測,按照定義5和表1可以得到待驗(yàn)證規(guī)約的CNF形式的公式[[f]]k,滿足度s即基于式子[[f]]k。例如布爾公式: (2) 如圖1的路徑π=s0,s1,s2={x1=1,x2=1,x3=0,x4=0,x5=1,x6=1,x7=0,x8=0,x9=1}滿足布爾公式(2)中的8個(gè)子句,不滿足子句x3∨x6∨x7∨x9,因此s=8。 本文中的個(gè)體編碼采用的是字符串編碼方式,因此d(w,t)采用字符串的編輯距離來度量[18],值得注意的是路徑上的每個(gè)狀態(tài)記為一個(gè)字符。由于反例中也包含了許多值得遺傳給后代的有益信息,在生成初始種群時(shí)并沒有將反例排除在外,并且一般情況下適應(yīng)度越高越好,因此在本算法中使用d(w,t)+1的倒數(shù),可使求倒數(shù)不出現(xiàn)錯(cuò)誤。 定義10 對于給定的規(guī)模為n的群體P={π1,π2,…,πn},t為反例,個(gè)體πi∈P(i=1,2,…,n)的適應(yīng)值為F(πi),適應(yīng)度函數(shù)為一維二元向量: (3) 2.4 遺傳操作 簡單遺傳算法的遺傳操作主要有三種:選擇(selection)、雜交(crossover)和變異(mutation)。改進(jìn)的遺傳算法大量擴(kuò)充了遺傳操作,以達(dá)到更高的效率。 2.4.1 具有多評(píng)價(jià)指標(biāo)的選擇操作 遺傳算法中的選擇操作就是用來確定如何從父代種群中按某種方法選取哪些個(gè)體遺傳到下一代種群中的一種遺傳運(yùn)算。選擇操作建立在對個(gè)體的適應(yīng)度進(jìn)行評(píng)價(jià)的基礎(chǔ)上。使用選擇算子(也叫復(fù)制算子reproduction operator)來對種群中的個(gè)體進(jìn)行優(yōu)勝劣汰操作:適應(yīng)度較高的個(gè)體被遺傳到下一代的概率較大;適應(yīng)度較低的個(gè)體被遺傳到下一代的概率較小。 2.4.2 交叉 在選擇算子的作用下,得到了新一代的個(gè)體,但是這些個(gè)體都是從上一代存活下來的,本質(zhì)上還是上一代的個(gè)體,因此這些個(gè)體之間必須經(jīng)過相互之間的交叉以產(chǎn)生新的個(gè)體,通過相互交換優(yōu)秀的基因,使得整個(gè)種群向更優(yōu)的方向進(jìn)化。遺傳算法中的交叉算子對算法進(jìn)行全局搜索方面起到了重要的作用。本文采用的是一種通用的算子:“常規(guī)交叉法”。該交叉算子的使用非常的直觀和簡單。 首先是選擇兩個(gè)父代進(jìn)行交叉,選擇的方式是根據(jù)個(gè)體的適應(yīng)度來決定的。然后產(chǎn)生一個(gè)區(qū)間[1,N]的隨機(jī)數(shù)k作為交叉位。基于本文的編碼,在選擇交叉位時(shí)將一個(gè)狀態(tài)作為一個(gè)完整的基因片段。也就是說,如圖2所示N=3,當(dāng)選定的隨機(jī)數(shù)k=2時(shí)交換的位置實(shí)際是個(gè)體編碼的位置6(變異和修正的位置計(jì)算與此相同)。最后就是產(chǎn)生子代1和子代2,子代1交叉位之前的基因來自父代1交叉位之前的基因,而交叉位之后的基因則從父代2中按順序選取那些沒有出現(xiàn)過的基因,以補(bǔ)充完整整個(gè)解。子代2也是進(jìn)行相似的處理。圖3給出了這種交叉法的一個(gè)例子。 圖2 交叉操作Fig.2 Crossover operation 在完成交叉操作之后,常規(guī)的交叉方法容易產(chǎn)生非法的解,因此要對解進(jìn)行修正。如圖2中子代1存在兩個(gè)011(圖1中的s1)狀態(tài),為了最大的保持父代和新產(chǎn)生的基因片段,在原父代中刪除交換來的基因片段中含有的狀態(tài),最終去除了重復(fù)狀態(tài)的父代基因加上交叉來的基因完成了基因的修復(fù)。這樣做既保留了父代基因也添加了交叉來的基因,對原基因和新基因進(jìn)行了保持。例如圖2交叉后的子代1,進(jìn)行的子代修正操作如圖3所示。 圖3 子代基因修正Fig.3 Gene correction 2.4.3 變異 從遺傳算法的觀點(diǎn)來看,解的進(jìn)化主要靠選擇機(jī)制和交叉策略來完成,變異只是為選擇、交叉過程中可能丟失的某些遺傳基因進(jìn)行修復(fù)和補(bǔ)充,變異在遺傳算法的全局意義上只是一個(gè)背景操作。變異操作產(chǎn)生新的搜索點(diǎn),擴(kuò)大搜索空間,避免算法過早收斂到局部最優(yōu)解,起著提高種群多樣性和搜索算子的雙重作用。 在使用遺傳算法進(jìn)行證例發(fā)現(xiàn)時(shí),交叉操作導(dǎo)致新一代種群生成許多無效的路徑。鑒于此,本文提出了具有修正功能的定向變異策略。 具體的定向變異策略具體過程如下: 1)對每個(gè)個(gè)體,考察其是否屬于Path(K)。 2)如果存在不屬于Path(K),找到所有的錯(cuò)誤遷移的起始狀態(tài),并計(jì)算其單步可達(dá)狀態(tài)集合。從中隨機(jī)選擇一個(gè)狀態(tài)作為變異后的狀態(tài)。 2.5 算法描述 輸入:K,f,T/*K表示Kripke結(jié)構(gòu)的模型,f為待驗(yàn)證規(guī)約,T為算法的最大迭代次數(shù)*/ 輸出:w,F(xiàn)(w) /*w表示最優(yōu)證例,F(xiàn)(w)為w的適應(yīng)值 */ 開始 1)按照基于特定起始點(diǎn)的方法得到初始種群Y。 2)計(jì)算種群Y中個(gè)體的適應(yīng)度,并獲得最大適應(yīng)度向量Fmax。 3)如果為達(dá)到預(yù)定最大迭代次數(shù),依據(jù)選擇策略,對選出的個(gè)體進(jìn)行交叉,并且修正新一代個(gè)體。 4)進(jìn)行具有指向性的變異操作。 5)產(chǎn)生新一代種群Y,計(jì)算適應(yīng)度,獲得最大適應(yīng)度向量Ftemp。 6)如果Ftemp優(yōu)于Fmax則將Ftemp賦給Fmax,返回3),如果Ftemp次于Fmax,則結(jié)束循環(huán)。 7)從種群中選擇所需的最優(yōu)個(gè)體。 結(jié)束 3.1 正確性與可終止性 基于遺傳的證例搜索算法是可終止的,算法有兩種結(jié)束方式:1)執(zhí)行的每一代操作都有一個(gè)最大的適應(yīng)度值,若經(jīng)過遺傳操作交叉和變異之后產(chǎn)生的新一代的最大適應(yīng)度值比其父代的最大值沒有增大;2)算法執(zhí)行完預(yù)定的最大迭代次數(shù)[19]。因此計(jì)算過程最多在T次迭代后結(jié)束,T為預(yù)先設(shè)定的最大迭代次數(shù),即本文的算法滿足可終止性。遺傳算法的適應(yīng)度函數(shù)保證了所求解最優(yōu),選擇操作的修正和定向的變異保證所求解是模型中的路徑,這也就保證了本文算法滿足正確性。 3.2 時(shí)間復(fù)雜度分析 探討基于遺傳算法的證例生成算法的時(shí)間復(fù)雜度,首先要確定模型的狀態(tài)數(shù)n,遷移數(shù)為t,初始狀態(tài)的遷移數(shù)x0,x1…,xm,則種群規(guī)模L=x0,x1…,xm,k為路徑的最大長度,則初始化種群的時(shí)間復(fù)雜度為O(Lk)。對種群進(jìn)行交叉操作的時(shí)間復(fù)雜度為O(Lk/2)。變異操作中判斷一個(gè)個(gè)體是否是正確路徑的時(shí)間復(fù)雜度為O(kt),計(jì)算單步可達(dá)狀態(tài)集合的時(shí)間復(fù)雜度為O(t)。而對種群進(jìn)行適應(yīng)度計(jì)算的時(shí)間復(fù)雜度為O(Lk)。 通過上述分析可知,基于遺傳算法的證例生成算法的最大時(shí)間復(fù)雜度為O(kt),k表示最大路徑長度是一個(gè)常數(shù)。 3.3 實(shí)驗(yàn)結(jié)果 為了驗(yàn)證本文的算法,實(shí)現(xiàn)了一個(gè)java語言的編寫的遺傳算法的證例生成程序。程序運(yùn)行環(huán)境為雙核Intel Core i5-4210U @ 1.70 GHz 2.40 GHz處理器,內(nèi)存為4 GB,操作系統(tǒng)為64位的Windows 7。 表2 實(shí)驗(yàn)分析結(jié)果 從表2中數(shù)據(jù)可以看出,Mutex2模型驗(yàn)證是生成反例最長,算法生成的最優(yōu)解與反例相差為1,算法的分值最高需要的人工操作也最少。相反AFS-1與Policy模型的φ1規(guī)約的分值為0,是由于反例的長度為2,最優(yōu)解與反例的距離為2,也就是反例上所有的狀態(tài)都被認(rèn)為是錯(cuò)誤的,這就需要更多的人工操作來判斷結(jié)果是否正確。表2中GN表明算法能在極少的進(jìn)化步驟內(nèi)就能找到最優(yōu)解,本文算法很快能達(dá)到收斂狀態(tài),效率很高。 本文將遺傳算法引入模型檢測中的反例理解,提出了一種利用遺傳算法,獲取最近證例的算法,充分的利用了反例中的信息和模型的特點(diǎn),得出如下結(jié)論: 1)使用遺傳算法可以快速準(zhǔn)確的找到反例的最近證例,對于復(fù)雜度很高的模型有很好的魯棒性; 2)使用多個(gè)評(píng)價(jià)指標(biāo)和定向的變異策略,不僅能在極少的進(jìn)化次數(shù)內(nèi)找到最優(yōu)解,并且具有很好的收斂性,使得算法的時(shí)間復(fù)雜度顯著降低。 由于遺傳算法具有良好的并行性,本文提出的算法可以擴(kuò)展為相應(yīng)的并行搜索算法,以加快求解速度。 [1]CLARKE E, GRUMBERG O. Model checking[M]. Cambridge: MIT Press, 1999. [2]BEER I, BEN-DAVID S, CHOCKLER H, et al. Explaining counterexamples using causality[J]. Formal methods in system design, 2012, 40(1): 20-40. [3]WANG Chao, YANG Zijiang, IVANIF, et al. Whodunit? Causal analysis for counterexamples[M]//GRAF S, ZHANG Wenhui. Automated technology for verification and analysis. Berlin Heidelberg: Springer, 2006: 82-95. [4]黃宏濤, 黃少濱, 陳志遠(yuǎn), 等. 基于克雷格插值的反例理解方法[J]. 吉林大學(xué)學(xué)報(bào): 理學(xué)版, 2013, 51(1): 94-100. HUANG Hongtao, HUANG Shaobin, CHEN Zhiyuan, et al. Understanding counterexamples based on Craig interpolation[J]. Journal of Jilin university: science edition, 2013, 51(1): 94-100. [5]HALPERN J Y, PEARL J. Causes and explanations: a structural-model approach. Part I: Causes[J]. British journal for the philosophy of science, 2005, 56(4): 843-887. [6]SüLFLOW A, FEY G, BLOEM R, et al. Using unsatisfiable cores to debug multiple design errors[C]//Proceedings of the 18th ACM Great Lakes symposium on VLSI. New York, 2008: 77-82. [7]CHEN Yibin, SAFARPOUR S, MARQUES-SILVA J, et al. Automated design debugging with maximum satisfiability[J]. IEEE Transactions on computer-aided design of integrated circuits and systems, 2010, 29(11): 1804-1817. [8]GROCE A, VISSER W. What went wrong: explaining coun-terexamples[M]//BALL T, RAJAMANI S K. Model Checking Software. Berlin Heidelberg: Springer, 2003, 2648: 121-136. [9]GROCE A, CHAKI S, KROENING D, et al. Error explanation with distance metrics[J]. International journal on software tools for technology transfer, 2006, 8(3): 229-247. [10]CHAKI S, GROCE A, STRICHMAN O. Explaining abstract counterexamples[C]//Proceedings of the 12th International Symposium on Foundations of Software Engineering. Newport Beach, 2004: 73-82. [11]WANG Tao, ROYCHOUDHURY A. Automated path generation for software fault localization[C]//. Proceedings of the 20th IEEE/ACM International Conference on Automated Software Engineering. New York, 2005: 347-351. [12]HOLLAND J H. Adaptation in Natural and Artificial Systems[M]. Cambridge: MIT Press, 1992. [13]陳國彬, 張廣泉. 基于改進(jìn)遺傳算法的快速自動(dòng)組卷算法研究[J]. 計(jì)算機(jī)應(yīng)用研究, 2015, 32(10): 2996-2998. CHEN Guobin, ZHANG Guangquan. New algorithm for intelligent test paper composition based on improved genetic algorithm[J]. Application research of computers, 2015, 32(10): 2996-2998. [14]曲志堅(jiān), 張先偉, 曹雁鋒, 等. 基于自適應(yīng)機(jī)制的遺傳算法研究[J]. 計(jì)算機(jī)應(yīng)用研究, 2015, 32(11): 3222-3225. QU Zhijian, ZHANG Xianwei, CAO Yanfeng, et al. Research on genetic algorithm based on adaptive mechanism[J]. Application research of computers, 2015, 32(11): 3222-3225. [15]BIERE A, CIMATTI A, CLARKE E M, et al. Bounded model checking[J]. Advances in computers, 2003, 58: 117-148. [16]LEWIS D. Causation[J]. The journal of philosophy, 1973, 70(17): 556-567. [17]施小純. 基于反例搜索的啟發(fā)式模型檢測算法的研究[D]. 北京: 中國科學(xué)院研究生院(軟件研究所), 2004: 49-50. SHI Xiaochun. A heuristic algorithm for model-checking based on counter example finding[D]. Beijing: Institute of Software Chinese Academy of Sciences, 2004: 49-50. [18]HUTH M, RYAN M. Logic in Computer Science: Modeling and Reasoning about Systems[M]. London: Cambridge University Press, 2004. [29]張健沛, 李泓波, 楊靜, 等. 基于歸屬不確定性的變規(guī)模網(wǎng)絡(luò)重疊社區(qū)識(shí)別[J]. 電子學(xué)報(bào), 2012, 40(12): 2512-2518. ZHANG Jianpei, LI Hongbo, YANG Jing, et al. Variable scale network overlapping community identification based on identity uncertainty[J]. Acta electronica sinica, 2012, 40(12): 2512-2518. [20]LEUE S, BEFROUEI M T. Counterexample explanation by anomaly detection[M]//DONALDSON A, PARKER D. Model Checking Software. Berlin Heidelberg: Springer , 2012: 24-42. [21]WING J M, VAZIRI-FARAHANI M. A case study in model checking software systems[J]. Science of computer programming, 1997, 28(2/3): 273-299. An algorithm for explanation counterexamples by use of a genetic algorithm LI Ya,HUANG Shaobin,LI Yanmei,CHI Ronghua,LANG Dapeng (College of Computer Science and Technology, Harbin Engineering University, Harbin 150001, China) In order to seek the appropriate witness to help fault location of a complex system, a counterexample understanding algorithm in combination with a model checking technique on the basis of a genetic algorithm was proposed. The model used for model checking has an initial state, and the transfer relationship exists between the corresponding states. Therefore, a population was initialized. Also, a fitness function was designed and a directive mutation operation was conducted. Experimental results demonstrate that the algorithm can find the nearest witness rapidly and effectively and help the counterexample understanding of model checking. formal method; model checking; genetic algorithm; explanationing counterexample; fault localization 2015-09-01. 日期:2016-08-29. 國家科技支撐計(jì)劃課題(2012BAH08B00). 李雅(1985-), 女, 博士研究生; 黃少濱(1965-), 男, 教授,博士生導(dǎo)師. 李雅,E-mail:liya_heu@163.com. 10.11990/jheu.201509006 網(wǎng)絡(luò)出版地址:http://www.cnki.net/kcms/detail/23.1390.u.20160829.1421.048.html TP311.5 A 1006-7043(2016)10-1394-07 李雅,黃少濱,李艷梅,等. 基于遺傳算法的反例理解[J]. 哈爾濱工程大學(xué)學(xué)報(bào), 2016, 37(10): 1394-1399. LI Ya,HUANG Shaobin,LI Yanmei, et al. An algorithm for explanation counterexamples by use of a genetic algorithm[J]. Journal of Harbin Engineering University, 2016, 37(10): 1394-1399.




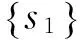
3 算法分析與實(shí)驗(yàn)結(jié)果
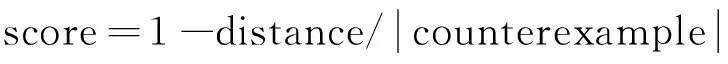

4 結(jié)論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
