基于MapReduce的海量圖像檢索技術(shù)研究
2016-12-05 09:33:59朱瑩芳
長沙民政職業(yè)技術(shù)學院學報 2016年1期
關(guān)鍵詞:特征
朱瑩芳
(江蘇信息職業(yè)技術(shù)學院,江蘇 無錫 214000)
基于MapReduce的海量圖像檢索技術(shù)研究
朱瑩芳
(江蘇信息職業(yè)技術(shù)學院,江蘇 無錫 214000)
隨著互聯(lián)網(wǎng)+技術(shù)的應用和普及,圖像數(shù)據(jù)在種類和數(shù)量上均呈現(xiàn)明顯的上升趨勢。如何從海量圖像集中檢索出所需的圖像已成為當下亟待解決的問題之一。文中嘗試利用Hadoop云平臺,并采用MapReduce分布式計算模型來進行海量數(shù)字圖像檢索,最終建立一個分布式的圖像檢索系統(tǒng)。實驗結(jié)果表明,無論在海量圖像的存儲能力還是檢索速度上,這種分布式圖像檢索方式和集中式的圖像檢索方式相比,有著更明顯的優(yōu)勢。
Hadoop;圖像檢索;MapReduce;分布式
隨著現(xiàn)代信息技術(shù)的飛速發(fā)展,以圖像、視頻為代表的復雜數(shù)據(jù)急劇增加,其中圖像信息的快速增長尤為突出。所以,如何實現(xiàn)對這些數(shù)據(jù)的有效管理,如何從海量數(shù)據(jù)中快速準確地檢索出所需的圖像,則成為當下的研究熱點。基于文本的圖像檢索作為一種傳統(tǒng)的檢索方法,并沒有對圖像本身的內(nèi)容加以分析和利用,已不能滿足發(fā)展需求,基于內(nèi)容的圖像檢索應運而生。
1.基于內(nèi)容的圖像檢索
基于內(nèi)容的圖像檢索(Content-Based Image Retrieval,CBIR),其基本思想是:依據(jù)圖像所包含的顏色、紋理、形狀及對象的空間關(guān)系等信息,從中提取出圖像特征,再進行特征匹配。
進行CBIR的研究需綜合認知心理學、數(shù)據(jù)庫、計算機視覺、人工智能、圖像處理、機器學習等各門學科的知識。由于CBIR是建立在對圖像內(nèi)容的理解和計算機視覺理論的基礎(chǔ)之上的,因此,對圖像內(nèi)容的描述不像基于文本的圖像檢索那樣依賴于用戶的手工標注,而是借助于從圖像中提取出來的顏色、紋理、形狀等視覺特征;同樣,對圖像的檢索也不僅僅是關(guān)鍵字的匹配,而演變?yōu)閳D像特征的相似度匹配。一般而言,可以將CBIR系統(tǒng)看作是介于信息用戶和數(shù)據(jù)庫(多媒體)之間的一種信息服務系統(tǒng)。圖1給出了一個典型的CBIR系統(tǒng)的基本框架。CBIR系統(tǒng)主要分為圖像庫建立子系統(tǒng)和圖像查詢子系統(tǒng)兩部分。首先使用特定的圖像特征提取算法提取出圖像的顏色、紋理、形狀等特征,然后把圖像的特征連同圖像一起存儲到圖像庫中,這樣就建立了基于內(nèi)容的圖像庫。圖像的查詢子系統(tǒng),其主要功能是負責和用戶的交互,以及用戶提交的待檢索圖像和庫存圖像之間的相似度度量,并按一定的相似度度量準則在圖像庫中進行特征匹配,最后依據(jù)相似度順序?qū)⒉樵兘Y(jié)果返回給用戶。
2.Hadoop云平臺的相關(guān)技術(shù)
Hadoop是一個由Apache基金會所開發(fā)的分布式系統(tǒng)基礎(chǔ)架構(gòu),它以分布式文件系統(tǒng)HDFS(Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的開源實現(xiàn))為核心,從而為用戶提供了系統(tǒng)底層細節(jié)透明的分布式計算和分布式存儲的編程環(huán)境。
2.1 Hadoop的體系結(jié)構(gòu)
在系統(tǒng)架構(gòu)中,首先主從式的主節(jié)點可以屏蔽底層的復雜結(jié)構(gòu),其次文件目錄的映射非常方便。正因為這兩個突出的優(yōu)點,使得主從式成為云計算系統(tǒng)中非常典型的系統(tǒng)架構(gòu)模式。同時,為減少單一主節(jié)點的負載,有部分主從式架構(gòu)在分層方向進行了一些改進。Hadoop從上層架構(gòu)上看是一種典型的主從式結(jié)構(gòu),主節(jié)點負責對整個系統(tǒng)的工作進行管理,并分發(fā)數(shù)據(jù);子節(jié)點負責數(shù)據(jù)的存儲、作業(yè)的運行。HDFS為分布式計算存儲提供了底層支持。主從式分布式文件存儲HDFS和主從式并行數(shù)據(jù)處理模型MapReduce構(gòu)成了Hadoop的基本架構(gòu)模型。
如圖2所示,在Hadoop主從結(jié)構(gòu)中,通常會把HDFS的主節(jié)點Name Node和Map Reduce中的作業(yè)主控程序Job Tracker都運行在Master節(jié)點上,而HDFS的數(shù)據(jù)節(jié)點Data Node和Map Reduce的子程序
Task Tracker則通常運行在同一個slave節(jié)點上。通過這樣的主從式體系結(jié)構(gòu),巧妙地實現(xiàn)了“計算向數(shù)據(jù)的遷移”。這種策略在處理海量數(shù)據(jù)時,可以有效地減少網(wǎng)絡中大規(guī)模數(shù)據(jù)移動所導致的開銷,只需將相對較小的計算程序分布到各個slave上就能實現(xiàn)分布式計算,節(jié)約了網(wǎng)絡帶寬,也就顯著地提高了整個系統(tǒng)的計算效率。
2.2 分布式文件系統(tǒng)HDFS
HDFS體系架構(gòu)采用master/slave模型。如圖3所示,云平臺中的節(jié)點被分成兩類:Name Node和Data Node,為簡化系統(tǒng)架構(gòu),HDFS集群中只有一個主節(jié)點Name Node,而Data Node可有若干個。其中Name Node充當master的角色,主要負責管理HDFS文件系統(tǒng),同時接受來自客戶端的請求;Data Node則主要用來存儲數(shù)據(jù)文件,HDFS把一個文件分割成一個或多個文件塊block,這些block存儲在一個或多個Data Node上。其中比較典型的部署是:在一臺性能相對較好的計算機上運行Name Node,集群中的其他計算機各運行一個Data Node;但若是運行Name Node的計算機的性能足夠好,也可以在該臺計算機運行一個或者多個Data Node。另一臺計算機上運行的Data Node數(shù)量則沒有嚴格限制,只要不突破計算機存儲能力的可承受范圍即可。
2.3 并行計算框架MapReduce
MapReduce是Google提出的一個軟件框架,基于它編寫的應用程序能夠運行于由上千個普通商業(yè)機器組成的集群上,并以一種可靠容錯的方式實現(xiàn)大規(guī)模數(shù)據(jù)的并行處理。Hadoop的MapReduce即是Google的MapReduce的開源實現(xiàn)。MapReduce模型受函數(shù)式編程語言的啟發(fā),其基本思想是:將要完成的任務分成Map(映射)和Reduce(歸約)兩步。首先,Map程序會將大的數(shù)據(jù)塊切分成多個特定大小的不相關(guān)數(shù)據(jù)塊;然后Map程序會在多個Data Node的節(jié)點上運行進行分布式計算;最后Reduce程序?qū)⒏鱾€Map程序的計算結(jié)果匯總,即可獲得最后的輸出文件。MapReduce框架的計算流程如圖4所示。
2.4 HBase簡介
HBase是bigtable的開源實現(xiàn),是建立在HDFS之上,具備高性能、高可靠性、列存儲、可伸縮、實時讀寫的數(shù)據(jù)庫系統(tǒng)。HBase介于Nosql和RDBMS之間,能且僅能通過主鍵(row key)和主鍵的range來檢索數(shù)據(jù),只支持單行事務 (可通過hive支持來實現(xiàn)多表join等復雜操作)。HBase主要用來存儲非結(jié)構(gòu)化和半結(jié)構(gòu)化的松散數(shù)據(jù)。與Hadoop一樣,HBase主要靠橫向擴展,通過不斷增加廉價的商用服務器來實現(xiàn)計算和存儲能力的增加。
3.基于Hadoop的圖像檢索系統(tǒng)
3.1 基于MapReduce的圖像存儲
在圖像數(shù)據(jù)量很大時,若把圖像放到HDFS中,對圖像的讀取將費時較多。如前所述,HBase是一個在HDFS上開發(fā)、面向列的分布式數(shù)據(jù)庫,若要實時地隨機讀/寫超大規(guī)模數(shù)據(jù)集,HBase將是一個理想的解決方案,在本文中,把庫存圖像的各特征以及存儲路徑存儲在HBase中。將圖像的ID作為HBase表的主鍵,將圖像和圖像特征分別作為表的兩個列族;圖像列族又分為圖像原文件和圖像縮略圖兩列;圖像特征列族分為顏色特征列、紋理特征列、形狀特征列三列。因在HBase中,在同一時間默認僅有一行數(shù)據(jù)可被鎖住,同時又由于行的寫入屬于原子操作,故我們設(shè)計使每個圖像的整體信息存儲在每一行,以方便讀寫。
由于圖像的特征提取是密集型計算,耗時較長,因此采用MapReduce分布式計算來完成圖像庫的特征提取是非常必要的。將特征提取出來后,把相應的圖像的ID、存儲的物理路徑、顏色特征、紋理特征、形狀特征等并行寫入HBase中。圖像的分布式存儲架構(gòu)如圖5所示,其具體的執(zhí)行流程如圖6所示。
3.2 基于MapReduce的圖像檢索
本文中采用了多特征綜合度量的算法,融合了圖像的顏色、紋理、形狀三種特征來進行檢索。檢索時,依據(jù)用戶設(shè)置的檢索方式來控制三種特征在檢索中所占的權(quán)重,本次權(quán)重分配方式如表1所示。
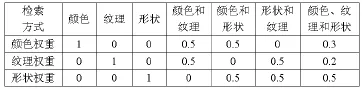
表1 各特征權(quán)重分配方式
假設(shè)圖像庫中共有N副圖像,那么庫中圖像可以用In(n∈{1,2,..,N})來表示,其相應的顏色、紋理和形狀特征可分別用Cn、Tn和Sn表示。用戶上傳的待檢索圖像是I0,其圖像的顏色、紋理和形狀特征分別用C0、T0和S0表示,三個特征的維數(shù)分別是L、M、Q。通過計算I0和In的相似度,可得到示例圖像和圖像庫中某副圖像的顏色相似度DCn、紋理相似度DTn以及形狀相似度DSn,分別表示為:
本文中,圖像及其特征都是存儲在HBase中的,
當HBase的數(shù)據(jù)集非常大的時候,掃描搜索整個表都要花費很長時間。為提高效率,本文使用MapReduce計算模型對圖像的檢索進行并行計算。圖像的并行檢索架構(gòu)如圖7所示,具體流程如圖8所示。在整個Map Reduce任務中,輸入的是HBase中的圖像表。整個流程主要分為以下幾步:(1)在Map階段,首先從HDFS的分布式緩存中讀取示例圖像,提取其特征值,與HBase中的圖像進行特征比較和相似度匹配。將〈相似度,圖像ID〉鍵值對作為map的輸出。(2)對map輸出的所有〈相似度,圖像ID〉鍵值對按相似度進行排序和重新劃分,再輸入到reducer。(3)在Reduce階段,收集所有〈相似度,圖像ID〉鍵值對,再對這些鍵值對按相似度排序,把前N(N是用戶設(shè)置的檢索結(jié)果數(shù))個鍵值對寫入到HDFS。(4)最后輸出與示例圖像相似度最高的圖像的ID。
4.系統(tǒng)平臺搭建以及測試分析
4.1 圖像存儲的性能測試
實驗中的圖像主要來源于網(wǎng)上下載,包括一些動物素材和植物素材,其他部分直接從網(wǎng)頁抓取的。圖片有大有小,有幾K的,也有幾M的。共收集了圖片20000張左右,大小約5.1G。
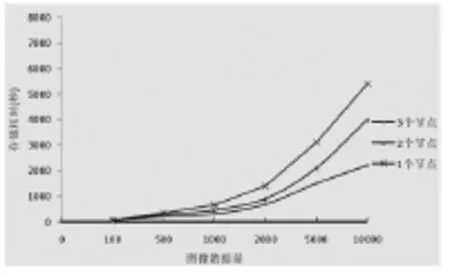
實驗中,分別測試了在不同的圖像數(shù)量以及使用不同的節(jié)點數(shù)的情況下,圖像存儲的所花費的時間。其中采用了100張、500張、1000張、2000張、5000張、10000張共六個圖像數(shù)量。在節(jié)點數(shù)量的選擇上,分別在1個、2個、3個節(jié)點下進行了測試。實驗結(jié)果如圖9所示。
從圖中可見,當圖像數(shù)量低于100時,節(jié)點數(shù)對存儲耗時的影響很小。不過,在100到500之間的某個數(shù)量開始,分布式存儲的優(yōu)勢就顯現(xiàn)了。
隨著圖像數(shù)量的不斷增長,三個節(jié)點消耗的存儲時間相比兩個節(jié)點所消耗的時間減少得越來越多,兩個節(jié)點消耗的時間相比一個節(jié)點所消耗的時間也減少得越來越多。此外,當圖像數(shù)量大于500張后,單個節(jié)點所消耗的存儲時間呈指數(shù)級增長;而兩個節(jié)點和三個節(jié)點的分布式存儲所消耗的時間則增長得相對較慢。當圖像數(shù)量大于2000張后,兩個節(jié)點和三個節(jié)點的分布式存儲耗時均呈線性增長。在此情況下,Map任務數(shù)已多于三個,某些節(jié)點在同一時刻會被分配多個Map任務,而一個節(jié)點同一個時刻卻僅能執(zhí)行一個Map任務。由此可見,圖像越多,增加存儲的節(jié)點數(shù)量就越能提高圖像特征提取和存儲的效率;反之,若圖像較少,則不應使用過多的節(jié)點來進行存儲。
4.2 圖像檢索的性能測試
實驗中分別測試了HBase總行數(shù)不同和所使用的節(jié)點數(shù)不同的情況下檢索的耗時。首先,HBase總行數(shù)分別選擇 400、800、2500、4000、5000、6000、18000、20000;其次,在節(jié)點數(shù)量的選擇上,分別在1個、2個、3個節(jié)點下進行了測試,實驗結(jié)果如圖10所示。
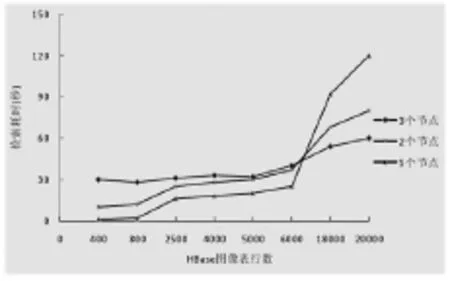
從圖中可見,在HBase的總行數(shù)小于6000時,節(jié)點數(shù)越多,檢索消耗的時間反而越長,這說明此種情況下由于數(shù)據(jù)量相對較小,HBase傾向于把數(shù)據(jù)集中存放于一個節(jié)點上。若HBase沒有將數(shù)據(jù)分布式存儲,那么使用多個節(jié)點來并行計算反而會增加系統(tǒng)開銷,從而延長檢索時間,因此就出現(xiàn)了圖10中所看到的情況。之后,隨著數(shù)據(jù)量的逐漸增加,HBase會把數(shù)據(jù)分布存儲到各個節(jié)點上,這樣就可以利用MapReduce的并行計算優(yōu)勢了。由此可見,檢索超大規(guī)模的圖像庫,適當?shù)卦黾庸?jié)點數(shù)量,可顯著提高檢索效率。
[1]Yixin Chert,James Z.Wang Robert Oovetz.Content-based image retrieval by clustering[C].International Multimedia Conference Proceedings of the fifth ACM SIGMM International Workshop,November 2003:193-200.
[2]Flickner M,Sawhney H,Niblack W.Query by image and video content:The QBIC system[C].IEEE Computer,1995,28(9):23-32.
[3]Pentland A.,Rosalind W.,Stanley S.,1996.Photobook:content-based manipulation of image databases.International Journal of Computer Vision,18(3):233-254.
[4]孫君頂.基于內(nèi)容的圖像檢索技術(shù)研究[D].西安電子科技大學,2005.4.
[5]張良將.基于Hadoop云平臺的海量數(shù)字圖像數(shù)據(jù)挖掘的研究[D].上海交通大學,2013.1.
[6]楊志文.云計算技術(shù)指南:應用、平臺與架構(gòu)[M].北京:化學工業(yè)出版社,2010,10.
[7]Fay Chang,Jeffrey Dean,et al.Bigtable:A Distributed Storage System for Structured Data[C].7th OSDI,2006,276-290.
TP391.41
B
1671-5136(2016)01-0121-03
2016-03-16
朱瑩芳,江蘇信息職業(yè)技術(shù)學院物聯(lián)網(wǎng)工程學院教師。
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化(高中版.高考數(shù)學)(2022年3期)2022-04-26 14:04:16
數(shù)學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數(shù)學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
