采用機器學習的聚類模型特征選擇方法比較
2017-01-13 09:04:57趙瑋
華僑大學學報(自然科學版) 2017年1期
關(guān)鍵詞:機器學習
趙瑋
(北京聯(lián)合大學 應(yīng)用科技學院, 北京 100101)

采用機器學習的聚類模型特征選擇方法比較
趙瑋
(北京聯(lián)合大學 應(yīng)用科技學院, 北京 100101)
針對機器學習聚類模型在特征選擇時存在的問題,首先,對特征選擇在聚類模型中的適用性進行分析并對其進行調(diào)整和改進.然后,基于R語言中的遞歸特征消除(RFE)特征選擇方法和Boruta特征選擇方法進行特征選擇算法設(shè)計.最后,應(yīng)用聚類內(nèi)部有效性指標,對在線品牌忠誠度聚類模型優(yōu)化結(jié)果進行分析,進而對特征選擇方法進行比較研究.結(jié)果表明:Boruta特征選擇方法更具優(yōu)勢. 關(guān)鍵詞: 特征選擇; 聚類模型; 機器學習; 遞歸特征消除算法; Boruta方法
特征選擇對基于機器學習的模型構(gòu)建和優(yōu)化有著重要意義.優(yōu)質(zhì)特征的選擇和構(gòu)建可以選擇有限合理的特征,剔除不相關(guān)的特征,讓模型得到數(shù)據(jù)集中良好的結(jié)構(gòu),使模型運算速度更快,模型結(jié)果更易理解,模型更易維護.因此,使模型發(fā)揮優(yōu)良效果,需要通過特征選擇的方法對模型進行優(yōu)化.然而,基于機器學習的聚類模型進行特征選擇存在以下2個問題.1) 特征選擇方法通常是針對機器學習中的監(jiān)督學習模型,需要具備目標特征變量,而聚類模型屬于無監(jiān)督學習[1-2],沒有目標特征變量.2) R語言作為機器學習比較好的實踐環(huán)境,提供了相應(yīng)的特征選擇包,但需要做比較分析.本文對特征選擇在聚類模型中的適用性進行分析,應(yīng)用R語言進行特征選擇算法設(shè)計.
1 理論基礎(chǔ)
1.1 特征選擇適用性分析
特征選擇要考慮聚類模型的適用性問題.聚類屬于無監(jiān)督學習[3],只有聚類特征變量,沒有目標特征變量.因此,從在線消費數(shù)據(jù)集[4]中,以各品牌作為目標特征變量,研究聚類特征變量集對目標特征變量的影響,并根據(jù)影響程度的大小,決定選擇哪些特征作為衡量品牌忠誠度的聚類特征.
1.2 R語言特征選擇方法分析
以R語言作為機器學習特征選擇和模型優(yōu)化的實踐環(huán)境.該環(huán)境中遞歸特征消除(RFE)特征選擇方法[5]和Boruta特征選擇方法具備特征選擇基本方法的功能.再結(jié)合啟發(fā)式搜索中的序列后向選擇對特征進行選擇,即從特征全集開始,每次減少一個特征用于模型構(gòu)建,從而選擇最優(yōu).
2 R語言特征選擇算法設(shè)計
2.1 基于 RFE特征選擇方法的算法設(shè)計
算法以聚類特征變量集和目標特征變量作為算法輸入?yún)?shù),具體實現(xiàn)的功能是評價變量的重要性和模型的精確性.算法核心程序如下所示.
f_select_feature_accuracy<-function(x_set,y_set)
{x_scale_filter <<- sbf(x_set,y_set,sbfControl=sbfControl(functions=rfSBF,verbose=F,method=‘cv’))
x_set<-x_set[x_scale_filter$optVariables]
x_scale_profile <<-rfe(x_set,y_set,sizes =c(1,2,3,4,5,6,7,8,9,10,11,12),rfeControl=rfeControl(functions=rfFuncs,method=‘cv’))
plot(x_scale_profile,type=c(‘o’,‘g’))}
由算法程序可知:算法核心是針對聚類特征變量集x和目標特征變量y實施過濾方法,并在此基礎(chǔ)上確定變量對模型精確性的影響程度.其中,RFE方法應(yīng)用rfe( )函數(shù)執(zhí)行特征選擇,其程序要點如下:rfe(x,y,sizes=1:MAX,rfeControl=control).
特征選擇就是根據(jù)聚類特征變量集x對目標特征y的影響程度進行評價,從而對x中的特征重要性進行排序.其中,Size是特征個數(shù);rfeControl用來指定特征選擇算法的細節(jié).
2.2 基于Boruta特征選擇方法的算法設(shè)計
根據(jù)特征選擇原理和思路,算法包括兩個子算法,具體實現(xiàn)的功能主要是:對于子算法f_select_feature_Boruta,基于隨機森林方法思想,通過循環(huán)迭代的方式對各特征的重要性進行評價,并對結(jié)果進行可視化呈現(xiàn).對于子算法f_select_feature_Boruta_final,將特征重要性未被確定的暫定項進行最終判別.算法核心程序如下所示.
f_select_feature_Boruta<-function(x_set,y_set,mr,pv=0.01,mc=TRUE,do=2,hh=TRUE,gi=getImpRfZ)
{…boruta_total_scale<<-Boruta(x_set,y_set,maxRuns=mr,pValue=pv,mcAdj=mc,doTrace=do,holdHistory=hh,getImp=gi)…
plot(boruta_total_scale,xlab = “ ”,xaxt = “n”,main=“Boruta算法特征重要性”)…}
f_select_feature_Boruta_final<-function(boruat_result)
{…final_boruta_total_scale<-TentativeRoughFix(boruat_result) …
plot(final_boruta_total_scale,xlab = “ ”,xaxt = “n”,main=“Boruta算法特征重要性確認”)…
getSelectedAttributes(final_boruta_total_scale,withTentative = F)
result_df_boruta_total_scale <-attStats(final_boruta_total_scale) …}
由算法程序可知:算法核心是對于子算法f_select_feature_Boruta來說,主要通過Boruta()對各特征的重要性進行評價;對于子算法f_select_feature_Boruta_final來說,主要通過TentativeRoughFix( )方法對特征重要性進行最終判別.其中,Boruta方法應(yīng)用Boruta( )函數(shù)執(zhí)行特征選擇,即Boruta(x,y,pValue=0.01,mcAdj=TRUE,maxRuns=100,doTrace=0,holdHistory=TRUE,getImp=getImpRfZ,…).特征選擇就是根據(jù)評價特征集合x對目標特征y的影響程度進行評價,x中的特征對y的影響越顯著,則x中的這個特征越重要.
3 實驗及結(jié)果分析
3.1 實驗數(shù)據(jù)
以在線消費者特征集作為聚類特征變量集x,通過特征選擇方法選擇出有效特征,實現(xiàn)在線品牌忠誠度的度量.其中,聚類特征變量集包含x_sum_count,sum_count,c_rate,x_sum_price,sum_price,p_rate,x_avg_score,x_sum_score,max_commentdate,max_buydate,max_usrtypenum,max_usrlocnum.目標特征變量y為L4(各品牌名稱).
用以上數(shù)據(jù)進行特征選擇和模型優(yōu)化后,應(yīng)用內(nèi)部有效性指標針對模型優(yōu)化結(jié)果對特征選擇效果進行檢驗和分析.內(nèi)部有效性指標包括SSE,SSB,IntraDPS和InterDPS[6-7].衡量的含義是SSE越小,SSB越大,IntraDPS越小和InterDPS越大,模型有效性越好,特征選擇的效果也越好[8-10].未進行特征選擇的初始模型內(nèi)部有效性指標SSE,SSB,IntraDPS,InterDPS分別為225 429.700 0,101 762.300 0,0.689 0,0.311 0.
3.2 應(yīng)用RFE特征選擇算法的實驗分析
應(yīng)用RFE特征選擇算法之前,將聚類特征變量集x和目標特征變量y作為參數(shù),執(zhí)行函數(shù)sbf,實施過濾方法.其結(jié)果作為rfe函數(shù)的參數(shù),實施封裝方法,實現(xiàn)變量重要性的評價及對模型精確性的判斷,其結(jié)果如圖1所示.由圖1可知:通過遞歸特征消除算法,在數(shù)據(jù)集的9個特征中選取4個特征作為重要特征,分別是x_sum_price,sum_price,max_buydate,x_sum_count.當重要特征數(shù)量達到4個時,模型的精確性最高,如圖2所示.
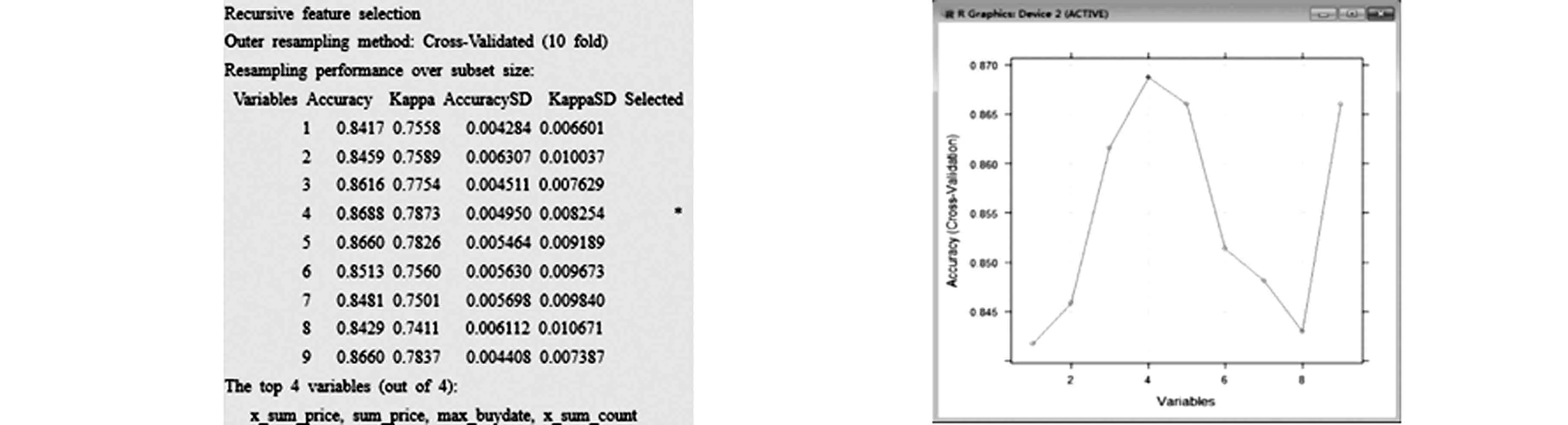
圖1 模型精確性結(jié)果 圖2 模型精確性可視化結(jié)果 Fig.1 Model accuracy result Fig.2 Model accuracy visualized result
基于4個重要特征的模型優(yōu)化的結(jié)果,需要結(jié)合初始模型和RFE特征選擇優(yōu)化模型內(nèi)部有效性檢驗的結(jié)果,進行比較分析,如表1所示.由表1可知:在4個指標中,RFE特征選擇優(yōu)化模型在SSE,InterDPS,InterDPS這3個指標上優(yōu)于初始模型,表明經(jīng)過RFE特征選擇的模型,其有效性得到提升.

表1 初始模型和RFE特征選擇優(yōu)化模型內(nèi)部有效性指標Tab.1 Internal validity index of initial model and RFE feature selection optimization model
3.3 應(yīng)用Boruta特征選擇算法的實驗分析
將聚類特征變量集x、目標特征變量y和Boruta方法參數(shù)要素作為參數(shù),執(zhí)行函數(shù)f_select_feature_Boruta,沒有特征被確定為重要特征和非重要特征,12個特征均被確定為暫定項.
由于存在暫定項,需要以f_select_feature_Boruta算法的執(zhí)行結(jié)果集作為參數(shù),執(zhí)行f_select_feature_Boruta_final算法中的TentativeRoughFix函數(shù)以判別暫定項的重要性.經(jīng)過進一步的判定,12個暫定項最終被歸為重要特征.對于特征重要性確認結(jié)果,還可以通過getSelectedAttributes和attStats函數(shù)確認特征列表和創(chuàng)建一個數(shù)據(jù)框架進行描述.
對數(shù)據(jù)框架信息中的各項重要性指標進行分析.按照medianImp指標,可得指標結(jié)果及特征重要性的排序:38.404 31(x_sum_count)>26.929 42(sum_count)>26.783 07(x_avg_score)>25.623 44(c_rate)>25.094 46(x_sum_price)>24.051 46(x_sum_score)>23.583 09(p_rate)>19.840 42(sum_price)>15.650 59(max_buydate)>14.739 77(max_commentdate)>12.200 94(max_usrlocnum)>11.395 70(max_usrtypenum).
根據(jù)Boruta特征選擇算法的特征重要性排序結(jié)果,結(jié)合序列后向選擇,從聚類特征變量集的全集開始,每次減少一個進行模型構(gòu)建.針對這些聚類特征變量集依次進行模型構(gòu)建,分別命名為Boruta優(yōu)化模型1~10,并從這些模型中選取最優(yōu).應(yīng)用內(nèi)部有效性檢驗指標分別對Boruta優(yōu)化模型1~10進行檢驗.由檢驗結(jié)果可知:Boruta優(yōu)化模型10各項指標明顯優(yōu)于初始模型及Boruta優(yōu)化模型1~9.
3.4 RFE和Boruta特征選擇方法的比較
RFE方法屬于最小優(yōu)化方法,依賴于特征的子集,其優(yōu)勢是最大限度地減少了隨機森林模型的誤差,而劣勢是會丟失一些相關(guān)的特征.Boruta方法依賴全體特征,其特點是找到所有的特征,無論其與決策變量的相關(guān)性強弱與否.與傳統(tǒng)的RFE特征選擇算法相比,Boruta方法的優(yōu)勢是能夠返回變量重要性的更好結(jié)果,解釋性更強.因此,從方法上看,Boruta方法的特征選擇更加有效.應(yīng)用RFE和Boruta特征選擇方法進行模型優(yōu)化的內(nèi)部有效性評價指標,如表2所示.由表2可知:采用Boruta方法選擇的特征用于模型優(yōu)化時,模型的聚類效果和有效性最好.

表2 RFE和Boruta特征選擇方法進行模型優(yōu)化的內(nèi)部有效性評價指標Tab.2 Internal validity index of RFE and Boruta feature selection optimization model
4 結(jié)束語
解決了聚類模型特征選擇存在的問題,設(shè)計了基于R語言中的RFE特征選擇方法和Boruta特征選擇方法實現(xiàn)特征選擇的算法.在此基礎(chǔ)上,應(yīng)用聚類內(nèi)部有效性指標,對在線品牌忠誠度聚類模型優(yōu)化結(jié)果進行分析,并對RFE特征選擇方法和Boruta特征選擇方法進行比較.由此可知:Boruta特征選擇方法對在線品牌忠誠度聚類模型優(yōu)化更加適用和有效.
[1] 錢彥江.大規(guī)模數(shù)據(jù)聚類技術(shù)研究與實現(xiàn)[D].成都:電子科技大學,2009:4-5.
[2] 汪永旗,王惠嬌.旅游大數(shù)據(jù)的MapReduce客戶細分應(yīng)用[J].華僑大學學報(自然科學版),2015,36(3):292-296.
[3] 方匡南.基于數(shù)據(jù)挖掘的分類和聚類算法研究及R語言實現(xiàn)[D].廣州:暨南大學,2007:78-84.
[4] 劉蓉,陳曉紅.基于數(shù)據(jù)挖掘的移動通信客戶消費行為分析[J].計算機應(yīng)用與軟件,2006,23(2):60-62.
[5] 盧運梅.SVM-RFE算法在數(shù)據(jù)分析中的應(yīng)用[D].長春:吉林大學,2009:16-28.
[6] 王曰芬,章成志,張蓓蓓,等.數(shù)據(jù)清洗研究綜述[J].情報分析與研究,2007(12):50-56.
[7] 周開樂,楊善林,丁帥,等.聚類有效性研究綜述[J].系統(tǒng)工程理論與實踐,2014,34(9):2417-2431.
[8] 胡勇.聚類分析結(jié)果評價方法研究[D].包頭:內(nèi)蒙古科技大學,2014:62-63.
[9] KANUNGO T,MOUNT D M.A local search approximation algorithm fork-means clustering[J].Computational Geometry,2004,28(2/3):89-112.
[10] ELKAN C.Using the triangle inequality to acceleratek-means[C]∥Proceedings of the Twentieth International Conference on Machine Learning.Menlo Park:AAAI Press,2003:147-153.
(責任編輯: 錢筠 英文審校: 吳逢鐵)
Comparison of Feature Selection Method of Clustering Model Using Machine Learning
ZHAO Wei
(College of Applied Science and Technology, Beijing Union University, Beijing 100101, China)
Targeting at problems during the feature selection process of machine learning clustering model, at first, it makes analysis on the applicability of the feature selection for clustering model and makes adjustment and improvement. Then makes feature selection algorithm design based on R language recursive feature elimination (RFE) feature selection method and Boruta feature selection method. At last, applying cluster interior validity indexes to analyze the optimization result of online brand loyalty clustering model, a further comparative study is made on the feature selection method. The results show that the Boruta feature selection method has more advantages. Keywords: feature selection; clustering model; machine learning; recursive feature elimination algorithm; Boruta method
10.11830/ISSN.1000-5013.201701020
2016-11-25
趙瑋(1981-),女,講師,博士,主要從事數(shù)據(jù)挖掘與數(shù)據(jù)分析、電子商務(wù)的研究.E-mail:yykjtzhaowei@buu.edu.cn.
北京市教委科研計劃項目(KM201511417010)
TP 181
A
1000-5013(2017)01-0105-04
猜你喜歡
電子技術(shù)與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(shù)(2016年20期)2016-08-19 18:49:49
電腦知識與技術(shù)(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(shù)(2016年3期)2016-04-07 16:12:55
