多倫縣降雨量時間序列的隨機模擬
2017-01-18 07:27:49李睿芳
綠色科技 2016年18期
李睿芳
(天津師范大學,天津 300380)
?
多倫縣降雨量時間序列的隨機模擬
李睿芳
(天津師范大學,天津 300380)
以1971~2002年的降雨量資料為依據(jù),利用相關(guān)知識和時間序列分析方法,對多倫縣降雨量時間序列進行了模擬。利用年資料建立隨機模型,根據(jù)時間序列的自相關(guān)系數(shù)和偏相關(guān)系數(shù)的比較建立了一階平穩(wěn)的AR(1)模型。 通過模型模擬出了服從偏態(tài)分布的降雨量序列,并通過誤差分析得出了由AR(1)模型模擬的大量序列都較符合預報要求,故此模型在實際中可以對水文時間序列進行偏態(tài)模擬。
AR(1)模型; 水文時間序列; 自相關(guān)系數(shù); 偏相關(guān)系數(shù)
1 引言
依據(jù)觀測到的多倫縣降雨量樣本序列建立隨機水文模型,由模型模擬出大量降雨量序列。雖然在水文隨機模擬中還存在一些問題有待解決,如模型與參數(shù)的不確定性的影響,但水文隨機模擬技術(shù)的正確使用,將有助于在水資源工程的規(guī)劃設計和管理運用中得到比應用傳統(tǒng)方法更為可靠的結(jié)果,從而可以提高規(guī)劃設計或管理運用的科學水平。
2 時間序列模型建立
2.1 建模目的
出自模型模擬序列的應用十分廣泛,在水文水利計算、水文測驗、水文站網(wǎng)規(guī)劃以及水文預報中均有應用,不同的目的要求有不同的模擬序列即不同的模型,設計建立模型的目的是根據(jù)降雨量資料的分析情況,建立隨機模型,以便模擬出大量序列。
2.2 模型類型的選擇
由自相關(guān)圖可以看出該序列存在著相依性,為一組相依序列,考慮以下幾點初步選用AR(p)模型: ① AR(p)模型表征降雨量序列的統(tǒng)計特性有一定的物理基礎; ② AR(p)模型參數(shù)的估計可以用簡單的距法,而且精度較高; ③ AR(p)模型形式簡單,數(shù)字處理方法簡單,為大家所熟悉。
2.3 模型形式的識別
選定AR(p)模型后,主要問題是如何確定階數(shù)p,對模型識別階數(shù)p的主要方法是對偏相關(guān)系數(shù)的統(tǒng)計分析。當k≥1時,數(shù)據(jù)落入容許限內(nèi),即可推斷出p=1,換言之,據(jù)偏相關(guān)系數(shù)的統(tǒng)計分析,AR(1)模型可以用來描述該降雨量系列的統(tǒng)計變化。
2.4 參數(shù)估計
因此對降雨量序列建立AR(1)模型為:
(1)
2.5 利用AIC準則對模型進一步識別
由準則計算的情況如下:
AIC(0)=29Ln(5120.872)+2×0=247.6913
AIC(1)=29Ln(4757.441)+2×1=247.5565
AIC(2)=29Ln(4648.0775)+2×2=248.876
AIC(1,1)=29Ln(4673.811)+2×2=249.04
根據(jù)計算結(jié)果,設計中采用AR(1)模型。
2.6 模型的檢驗
利用建立的AR(1)模型和實測的1999年降雨量對2000~2002降雨量進行模擬,AR(1)模型遞推公式為:
(2)
利用(2)式遞推出2000~2002年降雨量的隨機項,加上確定性成分就得到了 2000~2002年降雨量的模擬值。
計算的實測值與模擬值的絕對誤差如表1,因絕對誤差沒有超過2倍標準差,所以模型檢驗符合要求,即AR(1)模型可用來模擬降雨量序列。
3 模擬降雨量序列
確定出AR(1)模型后,還要判斷隨機項是屬于正態(tài)分布還是偏態(tài)分布的, 經(jīng)計算隨機項的偏態(tài)系數(shù)Cs=0.119,因此可以判斷該序列屬于偏態(tài)分布。
AR(1)偏態(tài)模型如下。
(3)
筆者選用的是長序列法模擬序列計算統(tǒng)計參數(shù),即由模型模擬出一個很長的模擬序列,然后進根據(jù)這個長序列來估計參數(shù)。序列的主要數(shù)字特征為數(shù)學期望函數(shù),方差函數(shù),偏態(tài)系數(shù)等。
利用計算機電子表格中的數(shù)據(jù)分析隨機數(shù)發(fā)生器公式,在計算機上直接生成10組長度為1000的(0,1)上均勻分布的隨機數(shù),并從中選取1組長度為1000的隨機數(shù)序列用來進行模擬。
對服從偏態(tài)分布的純隨機項的模擬,將均勻隨機數(shù)作下列變換:
則ζ1,ζ2為相互獨立的標準正態(tài)分布[N(0,1)]變量。因為該序列屬于偏態(tài)分布,偏態(tài)系數(shù)Cs=0.119<0.5,所以采用近似法又稱W—H變換法來進行偏態(tài)序列模擬,這一方法的實質(zhì)在于標準正態(tài)分布和標準化的皮爾遜Ⅲ型分布之間存在著近似關(guān)系
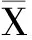

(4)
模擬的步驟如下所示。
(2)由服從標準正態(tài)分布的的隨機變量的模擬方法模擬出ζ1,算出φ1;
(3)以x0和值φ1代入式(4)又計算出x1;
(4)回到步驟二模擬出ζ2,算出φ2;
(5)以x1,φ2又代入是(4)計算出x2;
(6)重復以上步驟,可得到一個很長的序列,設計中模擬生成長度為1000的序列。在模擬過程中隨著模擬長度的增加,模擬序列的統(tǒng)計特性逐漸接近實測序列的統(tǒng)計特性。故模型具有實用性。
(7)考慮到序列的前100項受初值的影響,各將其舍去,最后從剩余序列中選取長度為n的序列。
對于以上步驟可在計算機上算出,用選取的這段模擬序列加上前面分析求得的確定性成分,就得到了降雨量模擬序列。并將實測序列和模擬序列的參數(shù)作對比(表2)。
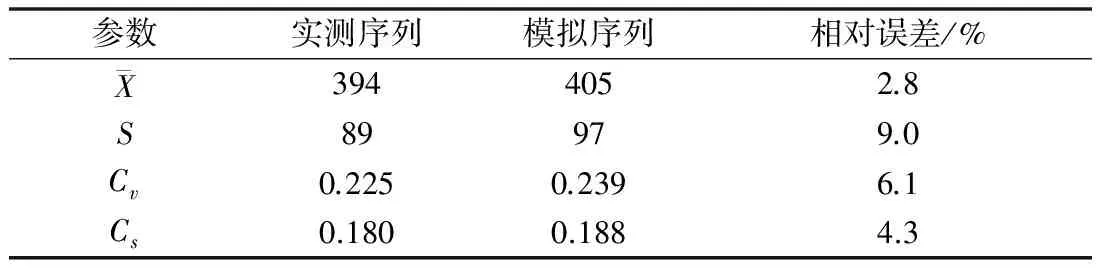
表2 多倫縣降雨量實測與模擬序列參數(shù)對照
經(jīng)比較相對誤差在允許范圍之內(nèi)(相對誤差取10%),所以選取這段模擬序列符合要求。
4 小結(jié)
筆者用隨機水文學中的時間序列分析方法和技術(shù),對多倫縣1971~1999年降雨量資料進行時間序列分析,建立了一階平穩(wěn)的AR(1)模型,通過誤差分析,模型模擬的序列較符合要求。
在上述過程中,雖然資料較全面,可靠,但由于隨機發(fā)生器上產(chǎn)生的隨機數(shù)隨機性較大,因此存在一些不足之處,需要改進,主要表現(xiàn)在以下幾個方面。
(1)設計中用隨機水文學中的時間序列分析方法和技術(shù)對多倫縣1971~2002年的降雨量資料進行時間序列分析,建立AR(1)模型,來進行模型模擬。
(2)在進行周期分析時,由于所選取的樣本序列較短,有可能存在偽周期成分,與降雨量總體序列的周期可能會存在一定的偏差造成周期成分計算結(jié)果存在一定的誤差。
(3)對降雨量時間序列選取模型進行建模,可以看出建立符合要求的模型涉及到基本資料分析、隨機理論和方法運用等。實際問題錯綜復雜,需要對具體情況具體分析,以便達到期望的建模目的。
[1]王立坤,付強,楊廣林,等. 季節(jié)性周期預測法在建立降雨預報模型中的應用[J].東北農(nóng)業(yè)大學學報 ,2002(1).
[2]陳元芳. 隨機模擬中模型與參數(shù)不確定性影響的分析[J].河海大學學報(自然科學版) ,2000(1).
[3]陳元芳. 非負自回歸模型的提出及估計回歸系數(shù)的新方法[J].水利水運科學研究 , 1994(Z1).
2016-09-06
李睿芳(1990—),女,天津師范大學碩士研究生。
P426.61
A
1674-9944(2016)18-0023-02
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業(yè)技術(shù)(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國中醫(yī)藥現(xiàn)代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
