視頻中旋轉與尺度不變的人體分割方法
2017-03-12 03:39:58薄一航HAOJiang
自動化學報 2017年10期
薄一航 HAO Jiang
視頻分割問題是當前計算機視覺領域一個比較熱門的話題.與靜態圖像分割方法不同的是視頻分割不僅要考慮到單視頻幀內各個像素點或超像素塊之間的關系,還要保證相鄰視頻幀之間對應像素點或超像素塊的連續性與光滑性.視頻分割的結果可以為更高一級的視頻及視頻中目標的分析工作提供較好的分析基礎.
起初,針對靜止攝像機拍攝的視頻,即視頻背景為靜止不變的情況,可以通過簡單的去背景的方法得到整個運動的前景區域[1?4].從目前的視頻分割方法來看,包括基于像素點的分割、基于超像素塊的分割和基于提議(Proposals)的分割等.但是,對于視頻分割而言,考慮到運算量和運算速度的問題,基于像素點的分割方法很不現實,也很少被采用.當前比較流行的視頻分割方法以基于超像素塊的分割和基于提議的分割為主.首先,對基于超像素塊的分割而言,研究者們試圖通過區域塊跟蹤的方法來處理[5?8]得到不同的分割區域.鑒于視頻數據本身的特殊性,還有一些視頻分割方法將視頻分割成底層特征隨時間變化連續的超像素塊[7?10].然而,超像素塊本身往往不具備完整的語義信息,每個超像素塊可能是一個完整的目標,也可能是構成某個目標的一部分,這樣的分割結果并不利于進一步的目標分析工作.并且,分割結果的優劣很大程度上還依賴于所選擇的分割閾值,我們通常很難選擇一個合適的閾值使得每一個分割區域都是一個完整且有意義的目標或目標的組成部分.另外,對于比較長的視頻而言,在整個視頻分割的過程中,會出現前后幀相對應的分割區域錯位的情況.近幾年,還有研究者提出針對視頻中運動目標的分割方法[11?12],比如文獻[13]中用一種全自動的方法,通過將Grab-Cut方法[14]擴展到時空領域來得到視頻中目標的閉合輪廓.為了得到更有意義的分割結果[15?16],基于提議(Proposals)的視頻分割方法越來越受到研究者們的青睞[9,17?20],每一個提議都極有可能是一個有意義的目標或目標的某個組成部分.其中,文獻[21]通過SVM(Support vector machine)分類器提取出每個視頻幀中較優的一些提議,再通過求解一個全連接的條件隨機場的最大后驗對前景和背景進行分類,得到的前景區域往往是一個完整的、有意義的目標所在的區域.文獻[22]利用特征空間優化的方法將視頻進行語義分割,得到視頻中各個語義目標所在的區域.文獻[23]借助目標檢測以及目標跟蹤的結果對視頻中的目標進行分割.
然而,這些視頻分割方法得到的是整個前景目標所在的區域[24?25],未能細化到構成目標的每一個組成部分.如果要進一步對運動目標的姿勢等進行識別與分析,僅僅得到整個目標所在的區域是遠遠不夠的,因此,與上述方法不同,本文所提出的視頻分割方法可以具體到構成運動目標的每個主要部位.
在各類運動目標中,人是最普遍,也是最復雜的一種.與其他剛性物體不同,由于人姿勢變化的不確定性和無規律性,其旋轉、尺度以及外貌的變化都會給分割過程帶來很大的困難.目前,已有不少關于人身體各部位的跟蹤與檢測方法,將人的身體分成若干個運動部位,如圖1(a)所示,不同的部位由不同灰度的矩形框來標定,而非具體的身體部位所在的區域.此類方法通常是基于模板的匹配,根據人姿勢、尺度的變化,分別與各個角度和尺度的模板進行匹配,從而得到與測試圖像最為接近的一個模板作為匹配結果,稱這種方法為“圖案結構(Pictorial structure)”[26?27].該方法的模型為樹形結構,只考慮到四肢與軀干之間的關系,而沒有對四肢之間的關系加以約束,往往會引起某一只胳膊或者某一只腿的漏檢或錯檢.另外,該方法雖然已被廣泛地應用到人的跟蹤與姿勢的估計中,但是,由于人運動姿勢變化的隨機性和不可預知性,無法事先知道目標尺度和旋轉角度的變化范圍,逐一模板匹配的過程會很大程度地影響運算速度.
針對以上問題,本文提出一種旋轉與尺度不變的運動視頻中人身體部位所在區域的分割方法,如圖1(b)所示為單幀的分割標注結果.該方法不僅考慮到軀干與四肢之間的關系,同時還考慮到四肢之間的相互關系.其最大的優勢就在于,它不需要考慮不同尺度與旋轉角度的模板匹配,而是利用人體各個部位的相對面積及比例關系,構建一個旋轉與尺度不變的視頻分割方法.實驗結果表明,該方法比“圖案結構”方法的魯棒性更強,尤其是對于目標旋轉和尺度變化較大的視頻,并與現有的“圖案結構”方法進行了定性和定量的比較.這樣的分割結果無論是在體育賽場、舞蹈演出,還是在視頻監控系統中都具有重要的應用潛質.

圖1 “圖案結構”檢測結果與本方法分割結果圖Fig.1 Detection result of“pictorial structure” method and the segmentation result of proposed method
本文最大的貢獻就是提出了一種新的旋轉與尺度不變的人身體各部位所在區域的視頻分割方法.如圖2所示為整個方法的鳥瞰圖,首先,找到每一幀(Frame 1,Frame 2,···,Framen)中可能的身體部位所在的區域塊;然后,根據每幀內各個身體部位間的相對位置、大小、對稱性等約束找到每一幀中可能的身體部位組合;最后,利用相鄰幀之間運動的連續性、光滑性等約束條件,采用動態規劃的方法找到每一幀中最優的人身體部位的組合.該方法不僅適用于行人視頻,同樣也適用于復雜的運動視頻.
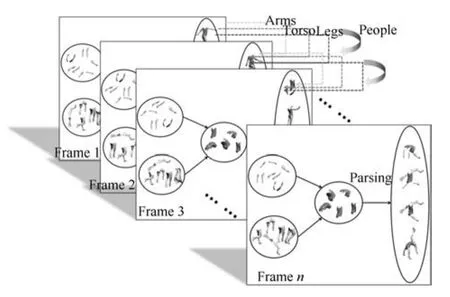
圖2 旋轉與尺度不變的視頻分割方法鳥瞰圖Fig.2 The bird-view of rotation and scale invariant video segmentation method
1 方法
本文提出的視頻分割方法旨在分割出視頻中人身體各部位所在的區域.該方法根據人體各部分組成結構之間空間與時間的連續性,對可能的人體部位組成結構進行優化選擇.為了使得分割結果不受目標運動過程中旋轉以及尺度變化的影響,人體部位組成結構的圖模型應為一個環狀結構,也就是說,不僅要考慮軀干與四肢之間的關系,還要考慮四肢之間的關系.如何有效地對該環狀結構進行優化具有一定的挑戰性.本文提出一種生成最優的N個人體部位組合的方法,每一幀中所有人體部位之間形成一個環狀的圖結構,分別找到每一幀中最佳的N個人體部位組合,根據幀與幀之間每個身體部位以及整個人運動的連續性和光滑性,采用動態規劃的優化方法找到每一幀中最優的一組人體部位組合,從而巧妙地解決了該非樹形結構的優化問題.
1.1 能量函數
本方法所采用的人體部位組成結構主要包括5個身體部位:軀干(Torso)、左右胳膊(Arm1,Arm2)和左右腿(Leg1,Leg2),由于頭的位置可以簡單地通過兩只胳膊和軀干的位置檢測到,考慮到模型的簡潔性,該方法沒有包括頭部.每幀內各個身體部位之間的結構關系以及相鄰幀間相應身體部位之間位移、形狀變化的關系,如圖3所示,圖中每個節點表示一個身體部位,每條邊表示它所連接的兩個身體部位之間的關系.其中,虛線邊代表單幀內身體各部位之間的關系,實線邊代表相鄰幀之間各部位之間的關系,每個點線方框代表一個視頻幀.這里,不僅考慮到軀干–胳膊、軀干–腿、胳膊–胳膊、腿–腿之間的關系,還考慮到胳膊–腿之間的關系.并且對于相鄰的前后幀之間,身體各個部位以及整個身體的連續性和一致性也是必須要考慮的.
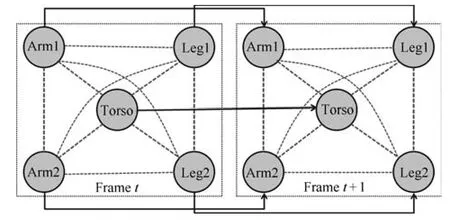
圖3 單幀內與相鄰幀之間身體部位關系圖Fig.3 Human body parts relationships in single frame and between adjacent frames
該方法把身體部位所在區域的視頻分割轉化成一個圖模型的優化問題,即把每一個身體部位分配給圖模型中的一個節點,通過優化過程使得分配的花費最小.這里,可能的身體部位所在的區域由文獻[28]所提出的方法得到.該方法可得到一系列與目標類無關的提議(Proposals).這些提議都具有較高的屬于某個目標類的分值,也就是說,這些通過合并超像素塊得到的提議很有可能是一個有意義的目標.這也是提議比普通超像素塊的優勢所在.另外,通過分割算法得到的超像素塊很容易將具有相同表觀特征的不同目標劃分為同一個區域,而提議則可以在很大程度上避免這種錯誤的產生.本方法將最有可能屬于身體部位的提議集合起來構成可能的身體部位的組合.
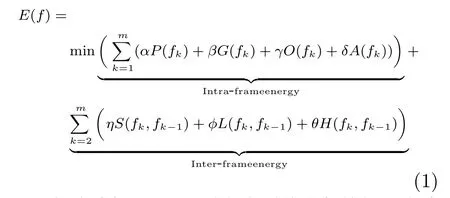
如式(1)所示,同時考慮到幀內與幀間的連續性與一致性,能量函數E(f)包括幀內能量(Intraframe energy)和幀間能量(Inter-frame energy)兩大部分,其中幀內能量主要包括身體部位的形狀匹配花費P(fk)、身體部位之間的距離G(fk)、身體部位之間的重疊O(fk)、身體部位之間的面積比例A(fk)等,身體部位的形狀越接近真實形狀,P(fk)就越小;身體部位之間的距離和重疊區域越小,G(fk)和O(fk)就越小;身體部位之間的面積比越接近真實比例,A(fk)就會越小.而幀間能量主要包括身體部位以及整個目標形狀的連續性S(fk,fk?1)、位置的連續性L(fk,fk?1)以及顏色的連續性H(fk,fk?1),幀與幀之間身體各部位以及整個目標的形狀變化越小、位移越小以及顏色的改變越小,S(fk,fk?1)、L(fk,fk?1) 和H(fk,fk?1) 就會越小.系數α、β、γ、δ、η、φ和θ為控制各分項比重的常量系數.
1.1.1 身體部位形狀匹配花費( P)
首先通過文獻[28]中所提出的方法得到各個候選區域塊.每一個候選區域塊為一個可能的身體部位,即一個提議.每一個身體部位,比如軀干、胳膊等,均具有一組模板.通過度量候選區域與模板之間所對應形狀描述子[29]的歐氏距離來衡量候選區域的形狀與真實身體部位形狀的相似性.區域的形狀描述子定義為區域內部任意點對之間的距離直方圖.當計算這個直方圖時,用區域內所有點對距離的最大值對其進行歸一化處理.該形狀描述子是旋轉與尺度不變的,即不隨區域旋轉和尺度的變化而變化的.具體的身體部位形狀匹配花費P定義為
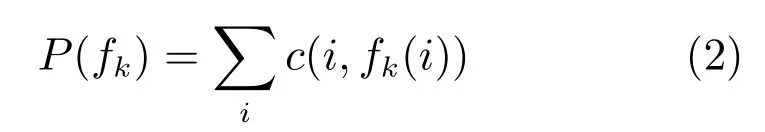
其中,i表示各個身體部位的索引值,fk(i)為身體部位i的候選區域,c(i,fk(i))為分配候選區域fk(i)給身體部位i的花費.c為區域fk(i)的形狀描述子與身體部位i的模板之間的最短距離.為了減少候選區域的個數,提高運算速度,實驗過程中用RANSAC(Random sample consensus)方法去掉背景部分.即取先前若干幀和未來若干幀,比較它們的SIFT(Scale-invariant feature transform)特征,由于前景目標往往只占每一幀的一小部分區域,因此,前景目標上的SIFT特征點在RANSAC特征匹配中成為野點.匹配過程中,只匹配背景點,將當前幀與其前后幀相減并求均值,得到一個估計的背景,從而可得到大致的前景區域.當然,由于受到光照變化、攝像機抖動等外界條件的影響,視頻的背景并非完全靜止,也就是說,這種去背景的方法并不能保證去掉所有的背景部分.需要說明的是去背景的過程是可選的,并不會影響最終的分割結果.
1.1.2 身體部位間的距離(G)
除了保證每一個身體部位所在的區域有正確的形狀之外,還要確保軀干與四肢之間的距離足夠小,也就是說,所有的軀干和四肢之間是連接的,而不是離散的.設t為軀干的索引值,j為四肢的索引值.計算四肢j與軀干之間的最小邊界距離d(fk(j),fk(t)),那么身體部位之間的距離則表示為
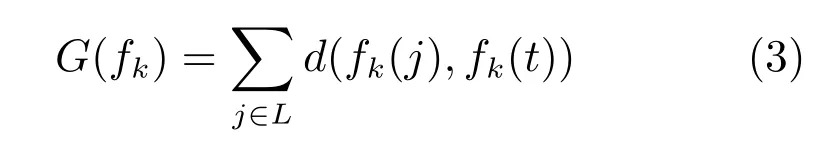
其中,L為四肢的集合.
1.1.3 身體部位間的重疊(O)
將身體部位之間的重疊O作為懲罰項,使得各個身體部位之間盡量的展開,又不會排斥部位之間的重疊,比如,我們允許胳膊和軀干之間的重疊,而當有展開的胳膊和軀干存在時,會優先選擇身體部位展開的情況:
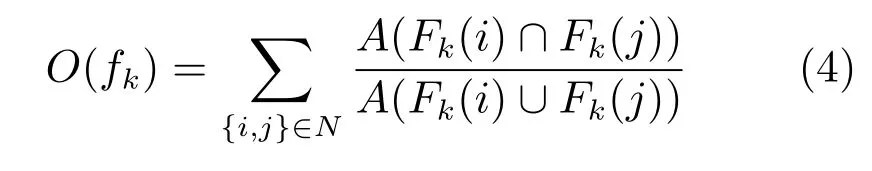
其中,Fk(i)為第k幀內部位i的估計區域,N為身體部位對的集合,包括胳膊–胳膊,腿–腿,胳膊–軀干,腿–軀干,胳膊–腿等部位對,函數A給出了區域的面積.
1.1.4 身體部位間的面積比( AAA)
不同的身體部位,比如胳膊和腿,可能會具有相似的形狀描述子.因此,僅通過形狀描述子進行約束是不夠的,模型需要更有力的條件來對其進行約束.進一步講,盡管不同的部位可能具有相似的形狀,但不同部位的面積比例往往不同且有一定的規律,是服從高斯分布的,高斯分布的參數可由訓練樣本得到:
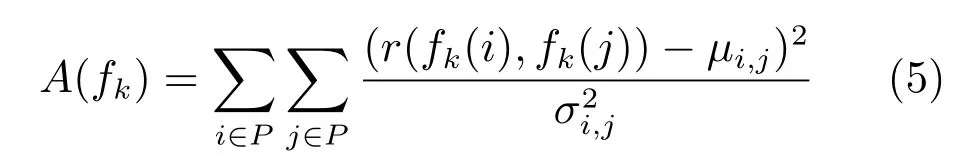
其中,r(fk(i),fk(j))為部位i的候選區域fk(i)與部位j的候選區域fk(j)的面積比,μi,j和分別為高斯分布的均值與方差.P為身體部位的集合.
除了幀內身體部位的位置比例關系之外,為了進一步保證運動的光滑性,還需要進一步考慮相鄰幀之間目標的連續性.這里由以下特征來衡量目標在時間上的連續性.
1.1.5 相鄰幀間形狀連續性(S)
通常情況下,相鄰幀之間目標的形狀變化往往不大,而且不會發生快速的變化.這樣一來,目標所在區域輪廓的變化也是光滑的.模型通過衡量身體部位所在區域輪廓變化的光滑性來判斷目標形狀的連續性S.這里,區域的形狀用其邊界的朝向直方圖[30]來表示.需要說明的是,這里用朝向直方圖而沒有用內部距離的原因是不需要保證幀與幀之間目標形狀的旋轉和尺度不變性,朝向直方圖更適合此種類型的形狀匹配.
設sfk(i)為第k幀內第i個身體部位候選區域fk(i)的形狀描述子,sfk表示第k幀內整個前景目標區域的形狀描述子,即其包括了所有的身體部位.形狀的連續性特征表示為
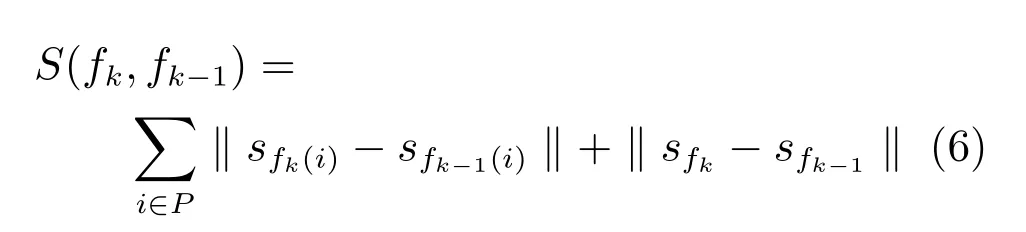
注意,邊界朝向直方圖沒有進行歸一化處理,而且它還包含有區域的大小信息.通過最小化S,可以保證多個視頻幀之間所估計目標的形狀和大小的連續性.
1.1.6 相鄰幀間位置連續性( LLL)
與形狀的連續性類似,同樣要求幀與幀之間身體部位的位置不會發生突然的變化.相鄰幀之間每個身體部位的位置變化用該部位所在區域中心點的位移來表示.設lfk(i)為第k幀內第i個身體部位的候選區域fk(i)的中心位置,那么該部位位置變化則定義為
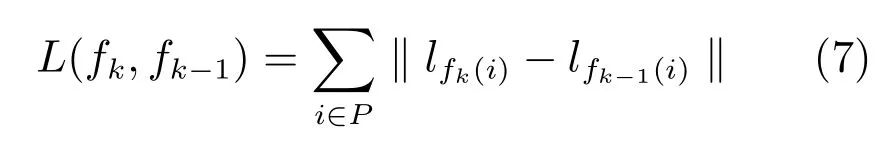
1.1.7 相鄰幀間顏色連續性(HHH)
假設目標的外貌在連續的相鄰幀中不會發生突然的變化.顏色的連續性可以保證身體部位的顏色在連續幀中的穩定性.這里,我們用RGB直方圖來量化人身體部位的顏色.顏色選項定義為
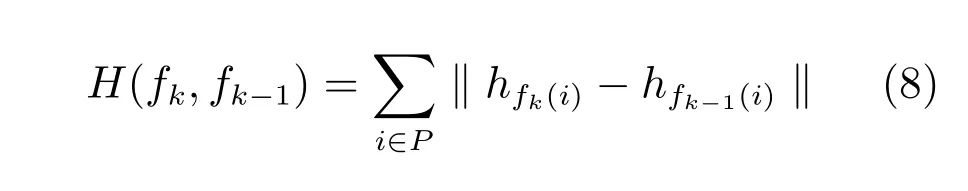
其中,hfk(i)為第k幀中第i個身體部位候選區域的顏色直方圖.
通過整合這些特征選項,可以得到一個完整的能量函數.能量函數的最小化可以保證在每一幀內得到一組最優的身體部位組合.這里所提出的模型是非樹形的,因此,我們沒辦法用動態規劃直接對能量函數進行優化.另外,由于無法估算候選區域的個數,因此無法直接使用貪婪的搜索算法.下一節將提出一種巧妙地將非樹形結構轉化為樹形結構的方法,從而能夠直接用動態規劃的方法進行能量函數的優化.
1.2 優化過程
1.2.1 單幀內最優N個身體部位組合優化過程
對于視頻中的每一幀,都會產生若干個可能的身體部位組合,組合的數量是整個優化過程中必須要考慮的問題,而且每幀中可能組合的數目也是無法事先預知和估算的.如果不對可能的組合進行篩選,優化運算的時間復雜度會成倍增加.因此,我們需要一種有效地提取每一幀中最優的N個身體部位組合的方法,其中N是動態規劃算法中所能駕馭的相對最小值.
本方法最大的創新之處就在于,在處理人體各個部位的關系時,不僅同文獻[31]一樣要考慮軀干與四肢之間的關系,還要考慮到四肢之間的關系,這就使原本的線性結構變成了非線性結構,從而也增加了選取最優身體部位組合優化過程的難度.下面來分析一下身體各個部位之間的關系.如果我們把兩個胳膊看作同一個節點,兩條腿看作同一個節點,那么軀干、胳膊和腿之間的關系就如圖4(a)所示,為一個環狀結構.對軀干進行復制并將其分開,即有兩個相同但不相連的軀干,那么圖4(a)中的圖模型就轉變為圖4(b)中所示的鏈狀結構,如此一來,便可以直接用動態規劃來對其進行優化,即如圖4(c)所示,左右兩個軀干為同一個軀干,每次固定一個候選軀干,然后用標準的動態規劃優化算法選出對于每一個候選軀干最優的胳膊和腿的組合.而對于所有可能的軀干,把每個軀干得到的身體部位組合進行優劣排序,最終保留最優的N個組合.此時,對于視頻中的每一幀,可以分別得到N個最優的身體部位組合.
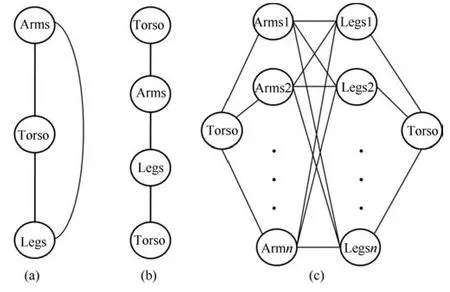
圖4 身體部位關系解析圖Fig.4 The relationship of human body parts
1.2.2 相鄰幀間最優身體部位組合優化過程
根據式(1)中的能量函數以及圖3中所示的圖模型可以看出,除了要考慮單幀內每一對身體部位之間的相關性及位置關系,還要考慮相鄰幀之間對應身體部位之間的連續性與光滑性.圖3給出了該方法的圖模型,為一個非樹形結構,我們無法直接用線性的優化方法對其進行優化.而在第1.2.1節中,每一幀已經產生出了最優的N個身體部位組合,這里,把每幀中的每一個身體部位組合作為圖中的一個節點,即把圖3中的每一個子圖作為一個節點,把相鄰幀中的各個節點用邊連接起來,這些邊和節點就會構成一個網格狀的圖結構,每個節點的花費由幀內能量函數(如式(1)中的Intra-frame energy)決定,每條邊上的花費由幀間的能量函數(如式(1)中的Inter-frame energy)決定.找到一條使得節點花費(幀內能量)和邊緣花費(幀間能量)均最小的路徑,路徑上所有的節點即為我們想要找的每一幀中最優的身體部位組合.這條最優路徑通過動態規劃的優化方法得到.假設每一幀中有N個可能的身體部位組合,視頻共有M幀,那么該優化過程的時間復雜度為O(M×N).
2 實驗
實驗中,我們把該方法應用到頗具挑戰性的各種運動視頻序列中,其中包括復雜的人體姿勢和各種翻轉動作.前四個視頻(Video 1,Video 2,···,Video 4)取自Youtube視頻,最后一個視頻(Video 5)取自HumanEVA數據庫[32].下面,分別給出定性的和定量的實驗結果與分析,以及該模型應用在行人姿勢估計上的結果.實驗中,能量函數里控制各分項比重的系數根據不同視頻的具體情況分別設定.下面,對能量函數中各個參數的設置做出具體解釋和分析.由于人各種姿勢的不同特征,在考慮各個身體部位之間的關系時應根據不同動作和姿勢下各個部位之間的不同關系和規律,具體問題具體分析.式(1)所示的能量函數中,Intra-frame energy的各項在整個能量函數中所起的作用大小各不相同,比如,在Video 1~Video 4中,運動目標均完成了翻轉或者平轉等動作,此時胳膊和腿的形狀會發生較大的變化,因此,這種情況下形狀匹配花費P就會被設置較小的比重.而在Video 5中,包含了行人行走的各個朝向,此時胳膊與軀干之間總會處于相互重疊的狀態,那么在這種情況下,身體部位間的重疊項O就會被設置較小的比重.而對于Inter-frame energy中的各項,幀與幀之間目標形狀、位置以及顏色的連續性均不會受到運動目標姿勢的影響,因此,對于所有的測試視頻,這其中各項都會設置為相同的比重系數.對于N的選擇,無論是在選取單幀中最優的N個身體部位組合時,還是在選擇每一幀中最優的那一組身體部位組合,都使用的是動態規劃的優化方法.能量分值最小的未必是最優的那一個組合,因此實驗中會選擇多個可能的身體部位及其組合參與優化過程.然而每個階段的節點數目過大會影響到優化速度,但如果N值選的太小(小于10)運算結果的準確性又會受到一定程度的影響.經過反復實驗,我們選擇了一個既不會對運算速度有太大影響,又不會降低運算結果準確度的N值,這里設置N為100.
2.1 定性實驗結果
我們用文獻[28]提出的區域提取方法得到各個可能的候選身體部位所在的區域.用第1.1.1節中提到的RANSAC方法進行去背景處理,由于受到光照、攝像機抖動等因素的影響,視頻的背景并非完全靜止不動,因此,這個方法不能去掉所有的背景區域,而且,目標的影子會隨目標的運動而運動(本方法中,前景目標的影子也被視為背景)也不能被去除,換句話說,RANSAC方法只能去掉完全靜止不動的背景區域.舉兩個比較典型的去背景后的例子,如圖5所示,第一個例子中(圖5中第一行),由于攝像機的抖動,發生抖動的背景區域并不能被去掉,而第二個例子中(圖5中第二行),人的影子隨人的運動而運動,也被誤認為是前景部分.需要說明的是,去背景與否并不會影響到我們最終的實驗結果.部分去背景雖然減少了大部分的背景噪音,但是我們仍可以得到一個相對比較干凈的前景區域,這對于提高檢測各個身體部位的運算速度有很大的幫助,但是諸如影子等無法被去掉的背景噪音對我們的檢測也是一個非常大的挑戰.圖6給出了分別在5段視頻上的分割結果,包括了不同的運動姿勢,比如,跳、翻轉、倒立、平轉以及正常行走等.所給出的幀均等間距的采樣于整個視頻.從分割結果中可以看出,即使是在比較有挑戰性的、姿勢變化較大的運動視頻上,該模型也可以得到不錯的分割結果.

圖5 去背景后效果圖Fig.5 Results after background removed
當然,從實驗結果中我們也可以看出,最終視頻分割結果的好壞很大程度上還依賴于提議(Proposals)檢測的準確與否.比如,圖6中第6行第3列Video 3中的分割結果,胳膊與軀干被同時檢測為軀干,此時頭部則被誤認為是胳膊,同樣,圖6中第8行第3列Video 4中的分割結果也是如此.這也是接下來的工作中需要改進和增強之處.
我們也與目前較新的類似的視頻分割方法做了定性的對比與分析.大部分的視頻分割方法[33]基于視頻幀圖像的底層特征將視頻分割成時間上連續的立體超像素塊(Supervoxel),沒有考慮視頻中前景目標的語義信息以及上下文關系,并且,其分割結果在很大程度上依賴于分割閾值的大小,閾值選的越大,分割結果越細;相反,分割結果會越粗.文獻[34]所提出的基于時空特性的前景目標提議的檢測方法把2D的目標提議檢測方法擴展到具有時間連續性的視頻數據中,從而得到立體的超像素塊,可以正確地檢測出視頻中的前景目標.該方法利用顏色[35]、光流[36]等特征,以及時間的連續性,光流梯度和邊緣在相鄰幀間的位移等信息對視頻進行分層分割,如圖7中第2行至第6行所示,為不同分割閾值下的分割結果,從上到下分割閾值依次增大.對這些在不同閾值下得到的分割結果進行合并聚類,進而得到較為理想的目標所在的區域,如圖7中第7行所示(圖7中所示為去背景后的結果).由于測試視頻背景為靜止狀態,因此,分割和檢測結果不受是否進行去背景操作的影響.然而,該方法并未考慮前景目標本身各個組成部分的結構和比例關系,如圖7中第7行的結果所示,無法解決影子對前景目標檢測分割結果的影響,圖7第8行為本文的分割結果.另外,該方法并沒有對目標的各個組成部分所在的區域進行語義標注,因此,實驗中并未與本文的方法進行定量的比較.

圖6 本方法在5段測試視頻上的部分分割結果Fig.6 Sample results of proposed methods on fi ve test videos
2.2 定量實驗結果
該實驗把本文所提出的方法與文獻[31]中提出的nbest的方法進行定量的比較分析,即分別把該方法得到的分割結果和nbest方法得到的結果與Ground truth(GT),也就是手工標注的真實的身體部位所在的區域相比較.
nbest[31]方法利用構成人體各個部位之間的“圖案結構”對于人體的各個組成部分進行檢測,該結構最大的問題就是只考慮到了軀干與四肢之間的位置關系,而忽略了四肢之間的關系,因此,對于直立狀態的人體而言,該方法可以得到較好的檢測結果,而對于發生旋轉的、非直立狀態的人體而言,該方法很難奏效.如圖8所示,為nbest方法對非直立姿勢的人體的檢測結果,圖中第1列為原始視頻幀,第2列為nbest方法的檢測結果,不同顏色的矩形框表示不同的身體部位,第3列為本文所提出的方法的檢測結果.
為了公平起見,實驗中同樣對nbest方法的輸入數據也進行去背景操作.另外,我們的方法得到的是分割的區域,而nbest方法得到的是每個身體部位區域所在的矩形綁定框,因此,我們按照一定的合適的比例擴張nbest方法得到的矩形區域的中軸線,使矩形區域腐蝕為一定比例的圓柱形區域,讓這個圓柱形區域無限地接近身體部位所在的分割區域.由于nbest方法[31]不是尺度和旋轉不變的,它對于翻轉幅度比較大的情況得到的實驗結果會很差.而本文提出的方法恰恰克服了這一點,不論目標發生如何旋轉和尺度的變化,均可以得到可靠的分割結果.

圖7 文獻[31]的方法與本方法測試結果對比示例Fig.7 Example results of the method in[31]and proposed method

圖8 nbest方法檢測結果與本方法結果示例Fig.8 Example results of nbest method and proposed method
對于每一個身體部位所在的區域,這里定義了一個匹配分值,A(P∩G)A(P∪G),其中,P是分割得到的身體部位所在的區域,G為對應的真實身體部位所在的區域,A為區域的面積函數.表1中給出了本方法與文獻[31]所提出的nbest方法對相同視頻檢測結果的比較分值.無論哪種運動情況,該方法的結果均比nbest方法要改進和提升很多.對于整體的平均檢測和分割結果,我們的方法依舊要優于所比較的方法.
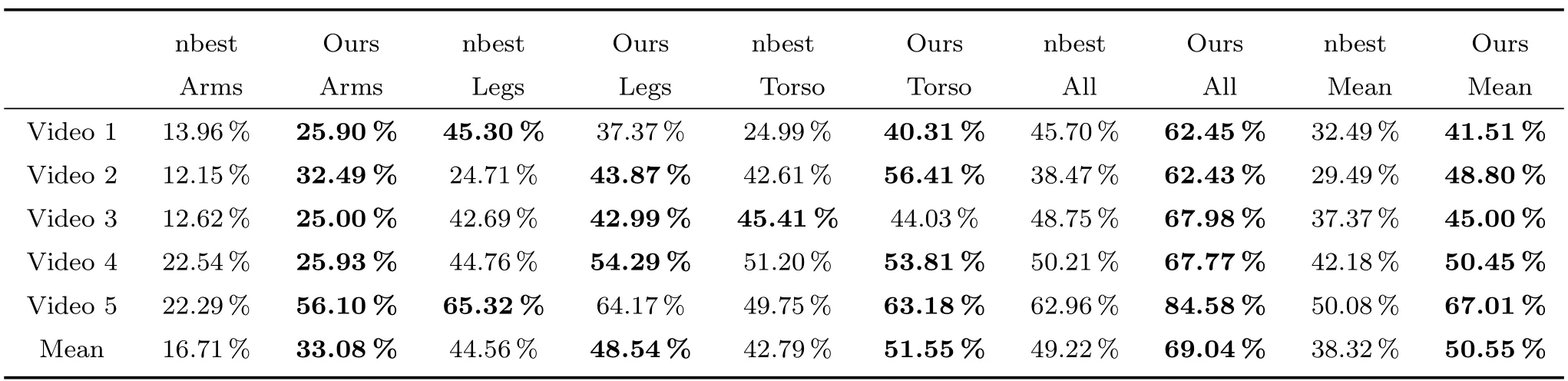
表1 該方法和nbest方法分別與GT的比較結果Table 1 Comparison of proposed method and GT,nbest method and GT
圖9給出了本文提出的方法與nbest方法實驗結果的正確率曲線,其中包括單個身體部位以及整個人體的正確率.每條檢測曲線都給出了所檢測到的高于某一閾值的正確的身體部位占整個檢測結果的比例.比該閾值高的均認為是正確的檢測結果.并且,當閾值為1時,檢測結果的正確率為0,而閾值為0時,檢測結果正確率為1.從圖9的正確率曲線不難看出,該方法得到結果的正確率明顯高于nbest方法.
2.3 行人姿勢估計的應用
由于該方法分割結果的特殊性,以及行人正常行走姿勢的規律性,可將其應用到行人的姿勢估計上.分割結果可分為上身和下身兩部分,軀干與胳膊屬于上身,腿屬于下身.根據直立行走的行人身體各個部位的比例位置關系,可以找到行人身體上可能的各個關節點,比如,肩膀、肘部、手腕、臀部、膝蓋和腳踝等.然后,用擴展動態規劃(Extended dynamic programming)的方法求得各個最優的關節點,從而得到行人的姿勢.
這里,每一對相鄰的關節點被看作是動態規劃中的一個狀態.所用到的各種約束條件包括兩相鄰關節點之間距離與行人高度比、兩相鄰狀態之間的內夾角,以及兩相鄰狀態連線與對應身體部位所在區域輪廓之間的平行性.另外,還需要考慮當前狀態與先前狀態的連續性和上身關節點與下身關節點的對齊,進而估計出不同朝向行人的關節點,用大小不同的原點表示關節點,關節點越大表示其離攝像頭距離越近;反之越遠.圖10給出了在本方法分割結果的基礎上,4個不同朝向的行人姿勢估計結果,圖中第1行到第4行分別為正面、背面、左面和右面4個朝向.
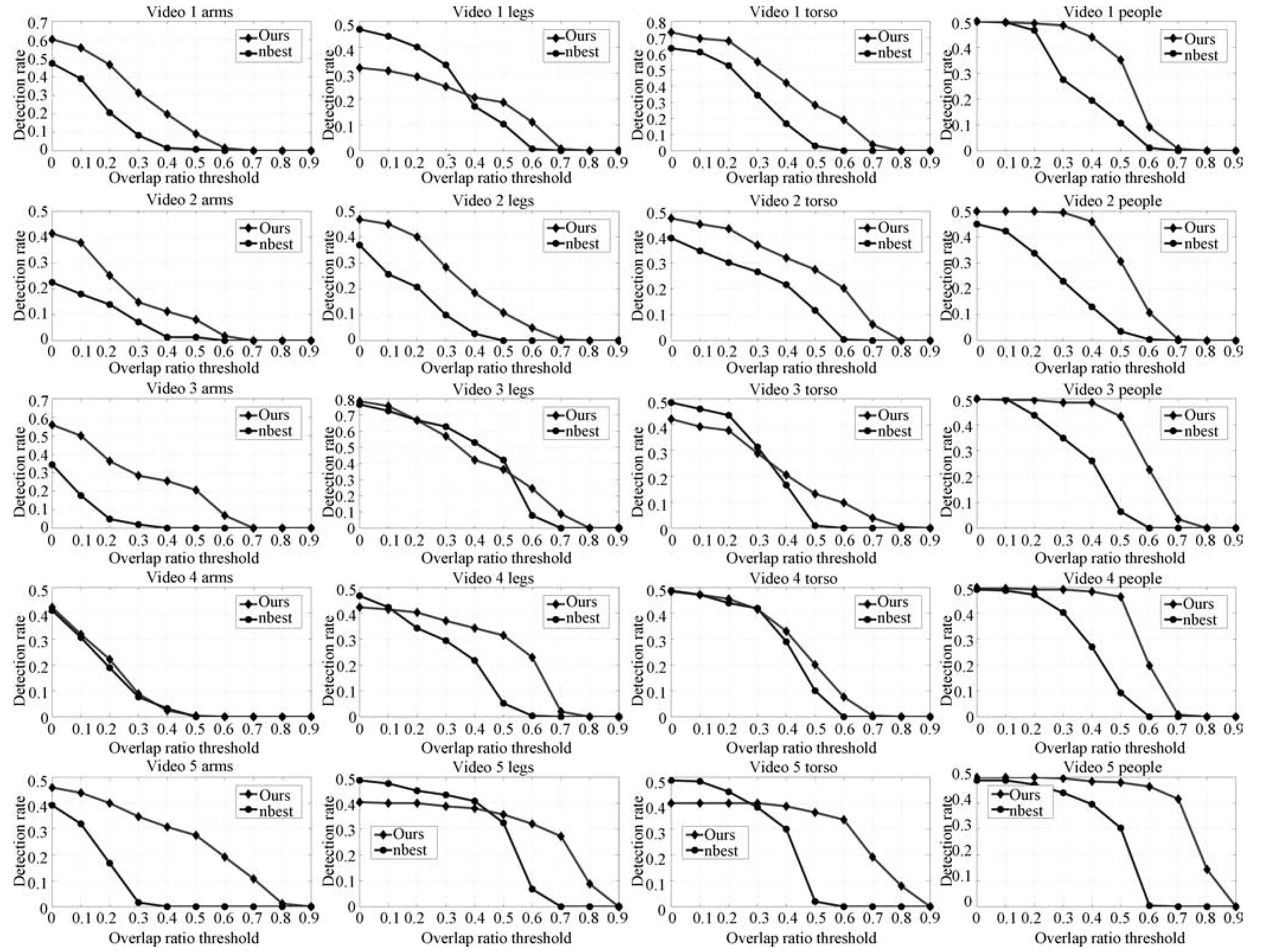
圖9 該方法與nbest方法實驗結果的正確率曲線圖Fig.9 Detection rate comparisons of nbest and proposed method

圖10 行人姿勢估計結果Fig.10 Pedestrian pose estimation results
3 總結與展望
本文提出了一種新的人身體部位所在區域的視頻分割方法.該方法不需要任何初始化,對于各種旋轉與尺度的變化都具有較好的魯棒性.實驗中分別對該方法進行了定性和定量的分析比較,實驗結果表明,與類似的方法相比,該方法不僅適用于直立行走的行人,對各種姿勢的人也可以得到較好的實驗結果.另外,還試將行人視頻的分割結果應用到行人行走姿勢的估計中,為進一步行人異常行為的分析奠定了良好的基礎.當然,針對實驗中出現的不足,比如如何提高提議(Proposals)的準確率等問題,也是接下來的工作中需要解決的.另外,在接下來的工作中,會在該工作的基礎上繼續進行體育、舞蹈等運動視頻中目標姿勢的估計與分析,以及其在智能視頻監控與人機交互領域的應用.
1 Criminisi A,Cross G,Blake A,Kolmogorov V.Bilayer segmentation of live video.In:Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition.New York,USA:IEEE,2006.53?60
2 Cheung S C S,Kamath C.Robust techniques for background subtraction in urban traffic video.In:Proceedings of SPIE 5308,Visual Communications and Image Processing.San Jose,USA:SPIE,2004,5308:881?892
3 Hayman E,Eklundh J.Statistical background subtraction for a mobile observer.In:Proceedings of the 9th IEEE International Conference on Computer Vision.Nice,France:IEEE,2003.67?74
4 Ren Y,Chua C S,Ho Y K.Statistical background modeling for non-stationary camera.Pattern Recognition Letters,2003,24(1?3):183?196
5 GiordanoD,MurabitoF,PalazzoS,SpampinatoC.Superpixel-based video object segmentation using perceptual organization and location prior.In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition.Boston,MA,USA:IEEE,2015.4814?4822
6 Brendel W,Todorovic S.Video object segmentation by tracking regions.In:Proceedings of the 12th IEEE International Conference on Computer Vision.Kyoto,Japan:IEEE,2009.833?840
7 Li F X,Kim T,Humayun A,Tsai D,Rehg J M.Video segmentation by tracking many fi gure-ground segments.In:Proceedings of the 2013 IEEE International Conference on Computer Vision.Sydney,Australia:IEEE,2013.2192?2199
8 Varas D,Marques F.Region-based particle fi lter for video object segmentation.In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus,OH,USA:IEEE,2014.3470?3477
9 Arbel′aez P A,Pont-Tuset J,Barron J T,Marques F,Malik J.Multiscale combinatorial grouping.In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus,OH,USA:IEEE,2014.328?335
10 Tsai Y H,Yang M H,Black M J.Video segmentation via object fl ow.In:Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas,USA:IEEE,2016.
11 Ramakanth S A,Babu R V.Seamseg:video object segmentation using patch seams.In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus,OH,USA:IEEE,2014.376?383
12 Faktor A,Irani M.Video segmentation by non-local consensus voting.In:Proceedings British Machine Vision Conference 2014.Nottingham:BMVA Press,2014.
13 Papazoglou A,Ferrari V.Fast object segmentation in unconstrained video.In:Proceedings of the 2013 IEEE International Conference on Computer Vision.Sydney,Australia:IEEE,2013.1777?1784
14 Rother C,Kolmogorov V,Blake A. “Grabcut”:interactive foreground extraction using iterated graph cuts.Acm Transactions on Graphics,2004,23(3):309?314
15 Girshick R,Donahue J,Darrell T,Malik J.Rich feature hierarchies for accurate object detection and semantic segmentation.In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus,OH,USA:IEEE,2014.580?587
16 Lin T Y,Maire M,Belongie S,Hays J,Perona P,Ramanan D,Doll′ar P,Zitnick C L.Microsoft COCO:common objects in context.In:Proceedings of the 13th European Conference.Zurich,Switzerland:Springer International Publishing,2014.740?755
17 Endres I,Hoiem D.Category-independent object proposals with diverse ranking.IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(2):222?234
18 Kr¨ahenb¨uhl P,Koltun V.Geodesic object proposals.In:Proceedings of the 13th European Conference on Computer Vision.Zurich,Switzerland:Springer International Publishing,2014.725?739
19 Zhang D,Javed O,Shah M.Video object segmentation through spatially accurate and temporally dense extraction of primary object regions.In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition.Portland,Oregon,USA:IEEE,2013.628?635
20 Fragkiadaki K,Arbelaez P,Felsen P,Malik J.Learning to segment moving objects in videos.In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition.Boston,USA:IEEE,2015.4083?4090
21 Perazzi F,Wang O,Gross M,Sorkine-Hornung A.Fully connected object proposals for video segmentation.In:Proceedings of the 2015 IEEE International Conference on Computer Vision.Santiago,Chile:IEEE,2015.3227?3234
22 Kundu A,Vineet V,Koltun V.Feature space optimization for semantic video segmentation.In:Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas,Nevada,USA:IEEE,2016.
23 Seguin G,Bojanowski P,Lajugie R,Laptev I.Instance-level video segmentation from object tracks.In:Proceeding of the 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas,Nevada,USA:IEEE,2016.
24 Lee Y J,Kim J,Grauman J.Key-Segments for video object segmentation.In:Proceedings of the 2011 IEEE International Conference on Computer Vision.Barcelona,Spanish:IEEE,2011.1995?2002
25 Tsai D,Flagg M,Rehg J.Motion coherent tracking with multi-label MRF optimization.In: Proceedings of the British Machine Vision Conference 2010.Aberystwyth:BMVA Press,2010.190?202
26 Ramanan D,Forsyth D A,Zisserman A.Tracking people by learning their appearance.IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(1):65?81
27 Yang Y,Ramanan D.Articulated pose estimation with fl exible mixtures-of-parts.In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition.Colorado Springs,USA:IEEE,2011.1385?1392
28 Endres I,Hoiem D.Category independent object proposals.In:Proceedings of the 11th European Conference on Computer Vision.Heraklion,Crete,Greece:Springer,2010.575?588
29 Ling H B,Jacobs D W.Shape classi fi cation using the innerdistance.IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(2):286?299
30 Dalal N,Triggs B.Histograms of oriented gradients for human detection.In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition.San Diego,CA,USA:IEEE,2005.886?893
31 Park D,Ramanan D.N-best maximal decoders for part models.In:Proceedings of the 2011 IEEE International Conference on Computer Vision.Barcelona,Spain:IEEE,2011.2627?2634
32 Sigal L,Black M J.HumanEva:Synchronized Video and Motion Capture Dataset for Evaluation of Articulated Human Motion.Techniacl Report CS-06-08.Brown University,USA,2006
33 Grundmann M,Kwatra V,Han M,Essa I.Efficient hierarchical graph based video segmentation.In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition.San Francisco,USA:IEEE,2010.2141?2148
34 Oneata D,Revaud J,Verbeek J,Schmid C.Spatio-temporal object detection proposals.In:Proceedings of the 13th European Conference on Computer Vision.Zurich,Switzerland:Springer International Publishing,2014.737?752
35 Pele O,Werman M.Fast and robust earth mover's distance.In:Proceedings of the 12th IEEE International Conference on Computer Vision.Kyoto,Japan:IEEE,2009.460?467
36 Brox T,Malik J.Large displacement optical fl ow:descriptor matching in variational motion estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(3):500?513
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52

- 自動化學報的其它文章
- 面向新穎成像模式敏捷衛星的聯合執行機構控制方法
- Robust H∞Consensus Control for High-order Discrete-time Multi-agent Systems With Parameter Uncertainties and External Disturbances
- Convolutional Sparse Coding in Gradient Domain for MRI Reconstruction
- Interactive Multi-label Image Segmentation With Multi-layer Tumors Automata
- Bayesian Saliency Detection for RGB-D Images
- 雙時間尺度下的設備隨機退化建模與剩余壽命預測方法