
基于共詞聚類分析的逆向物流熱點研究
2017-03-17 08:11:27畢小青羅燕兵
價值工程 2017年7期
畢小青+羅燕兵


摘要:逆向物流在節約資源、改善環境、降低成本等方面具有重要作用。因此,其廣受物流業界和學者們的關注。文章采用定量分析方法首先對我國近10年的文獻進行統計分析,然后構造共詞矩陣和相異矩陣,并運用相異矩陣進行因子分析和聚類分析。最后,歸納出我國逆向物流的研究熱點主要集中在3方面:網絡結構設計的研究、回收再利用的研究以及管理活動的研究。
Abstract: reverse logistics plays an important role in saving resources, improving environment and reducing cost. Therefore, it is widely concerned by the logistics industry and scholars. The quantitative analysis method is used to analyze the literature of the last 10 years in China, and then the co-word matrix and the dissimilarity matrix are constructed. Finally, the paper concludes that the research focus of reverse logistics in China mainly focuses on 3 aspects: the research of network structure design, the research of recycling and reuse, and the research of management activities.
關鍵詞:逆向物流;共詞分析;聚類分析;熱點
Key words: reverse logistics;Co-word analysis;cluster analysis;hot spot
中圖分類號:G353;F259.22 文獻標識碼:A 文章編號:1006-4311(2017)07-0222-03
0 引言
我國經濟實力不斷提高,人民消費水平得到改善,隨之而來的資源環境問題越來越嚴峻。受消費水平、國家政策和資源環保等的影響,我國對逆向物流的研究越來越重視。逆向物流是指為了獲取價值或者適當的處置而將與產品有關的材料進行再利用的過程。雖然如今對逆向物流研究的學者逐漸增多,但逆向物流在我國發展比較晚,還處于初級階段。眾多學者對逆向物流的研究比較局限而且相對分散孤立。因此,有必要對我國近些年學者們對逆向物流的研究熱點情況做一個整體的分析。本文運用共詞聚類分析方法對我國2005-2015年間國內發表的與逆向物流有關的期刊文獻進行研究。有依據的總結出了學者們的研究熱點并提出了目前研究的不足,為后期學者們的研究提供了思路和方向。
1 數據來源和研究方法
1.1 數據來源
本研究以CNKI為數據來源,選取來源類別為核心和CSSCI的以篇名為“逆向物流”的2005-2015年間的期刊文獻作為研究對象。共檢索出605篇,去重后剩余603篇。
1.2 研究方法
本文采用定量分析方法,即共詞聚類分析法。共詞聚類分析法是指采用聚類的計算方法對文獻中共現的關鍵詞的關聯性進行計算,將有關系的關鍵詞聚集歸類,從而總結出相關的信息[1]。
2 研究過程
2.1 關聯詞的整合
通過觀察可知,運用SATI3.2導出的關鍵詞存在大量的近義詞,部分詞匯還存在包含關系,分散的關鍵詞不利于后文的統計分析,需要對其進行規范化處理。
2.1.1 關鍵詞次數統計
將CNKI導出的txt格式文本文檔輸入到SATI3.2中統計得出1198個關鍵詞,總詞數為2607,平均頻次約為2.18。
2.1.2 關鍵詞的規范化
剔除導出的關鍵詞中不能用于分析逆向物流的關鍵詞,如“逆向物流”、“策略”等;合并意思相近或者具有包含關系的關鍵詞,將被包含的詞統一到一個類別中,如“循環經濟”與“循環型經濟”合并,將“退貨處理”、“退貨管理”等統一歸于關鍵詞“退貨”。
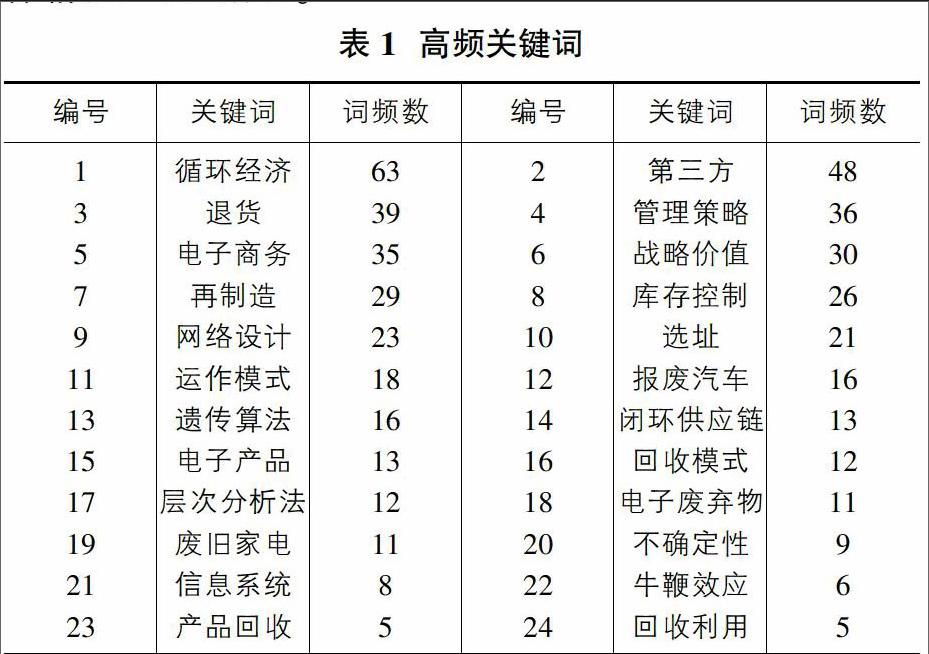
2.1.3 高頻關鍵詞的確定
將整合好的關鍵詞重新導入SATI3.2中進行統計,最終確定以閾值5為最低頻次,共獲得24個高頻關鍵詞,具體情況如表1所示。
2.2 共詞矩陣
共詞矩陣是指為了便于對共現頻率的計算,構造出體現該領域各個主體之間關系的N*N的矩陣(N為高頻關鍵詞個數)。對角線上的數是指該關鍵詞的總頻數。通過SATI3.2,選擇“Co-Occurrence Matrix (valued)”,得出的共詞矩陣如表2所示。
由于后文的因子分析、聚類分析需要用到相關矩陣,本文通過Ochiia系數將共詞矩陣轉換為相關矩陣,Ochiia系數=(A、B兩詞共現頻次)/((A詞出現的頻次)^0.5*(B詞出現的頻次)^0.5),在相關矩陣中,數值越接近于1,表明兩關鍵詞的關系越緊密。通過計算,得出的相關矩陣如表3所示。
2.3 因子分析
因子分析旨在用盡可能少的因子表示眾多的因素或指標,同組間因素的關系緊密,不同組中各因素之間的關系疏遠[2]。將上述得出的相關矩陣導入SPSS21.0軟件,選取主成分分析法和最大方差法,得到的因子碎石圖如圖1所示。圖中可以看出前3個因子比較明晰,從第4個因子開始曲線開始變得緩慢,所以將逆向物流24個關鍵詞的研究劃分為3大類比較合理。
2.4 聚類分析
聚類分析旨在將變量之間關系緊密的聚合到一個小的單元,關系疏遠的聚合到一個大的單元,形成一個由大到小,由關系疏遠到關系緊密的一個分類樹狀圖[3]。將相關矩陣導入SPSS21.0軟件,選取“組間聯接-平方Euclidean距離”,得出的聚類樹狀圖如圖2所示。從圖進一步驗證了將逆向物流的研究分為3大類是可行的,這3類主題可表示為:網絡結構設計的研究、回收再利用的研究以及管理活動的研究。
3 結果分析
結合前文對逆向物流關鍵詞的整合歸類,并結合對相關文獻的研究,近些年我國對逆向物流的研究熱點主要集中在3個方面。
3.1 網絡結構設計的研究(包含關鍵詞:10、13、9、23、18、7、20、14)
在資源利用方面,網絡構建是逆向物流的一個關鍵因素。對于網絡結構設計的研究,根據物品種類與處理方式的差異,大部分學者主要集中在產品回收、再制造以及電子廢棄物三個方向的分析。逆向物流網絡具有高不確定性的特點。在管理逆向物流中,其重要決策之一是選址。許多學者在不確定性的物流網絡環境下,也有學者在閉環供應鏈條件下建立模型分析這三方面逆向物流戰略層次的選址問題,而遺傳算法是解決這一模型的有效算法得到了廣大學者的證實。
3.2 回收再利用的研究(包含關鍵詞:12、24、16、19)
目前,我國回收利用研究的焦點主要集中在報廢汽車和廢舊家電方面,汽車和家電消費的數量不斷增長。報廢汽車和廢舊家電所導致的資源環境問題引起了許多學者的關注。報廢汽車的研究主要涉及供應商的選擇、評價指標、管理戰略、利潤分配、回收模式等。廢舊家電的研究主要涉及制度創新,制度創新涉及觀念、法律法規體系、回收模式、信息系統等多方面的內容。對于報廢汽車與廢舊家電的回收利用研究,回收模式涉及政府、消費者、企業等多方面的利益,眾多學者把回收模式的選擇作為分析的關注點。
3.3 管理活動的研究(包含關鍵詞:3、21、5、8、22、11、17、4、6、2、1、15)
3.3.1 庫存管理(包含關鍵詞:3、21、5、8、22)
庫存控制是逆向物流管理的主要內容之一,信息系統不完善是逆向物流管理健康發展的最大障礙之一。改善信息系統,減少牛鞭效應是未來逆向物流發展的趨勢。逆向物流系統需要對產品進行跟蹤,特別是針對退貨。在電子商務環境中,退貨是逆向物流中最常見的部分[4]。退貨常被作為庫存控制模型的一個參數,許多學者對退貨處理方式進行假設研究。
3.3.2 產品規劃管理(包含關鍵詞:1、2、4、6、11、15、17)
許多學者以循環經濟為導向,根據逆向物流的戰略價值,特別是其經濟價值和社會價值提出管理策略。產品管理特別是電子產品的管理策略問題已經成為我國緊迫性問題,眾多學者對電子產品的運作模式、第三方企業的選擇進行了分析,不同類型的企業其物流模式的選擇需要結合自身發展狀況不同而改變,這就需要針對不同企業對逆向物流運作模式進行專門的研究。許多學者分析的焦點在于將可實行的運作模式進行歸類,結合特定種類的企業運用層次分析法對不同的運作模式進行最優化選擇。
4 結束語
逆向物流的研究對于資源環境的改善具有積極的作用,是我國可持續發展的需要。本文整理出了我國逆向物流領域的24個高頻關鍵詞,運用相關軟件和方法可視化的展現了我國逆向物流領域的研究熱點。受工具和方法限制,本文僅是對逆向物流探索性的研究。在后續研究中,其結論尚需進一步證明。
參考文獻:
[1]鐘偉金,李佳,楊興菊.共詞分析法研究(三)——共詞聚類分析法的原理與特點[J].情報雜志,2008(07):118-120.
[2]白婷婷,鄭新奇,趙璐.基于共詞分析的復雜網絡研究現狀分析[J].資源開發與市場,2011(02):122-126.
[3]唐小華.混合原油中金屬鎳釩的特性研究[D].大連海事大學,2015.
[4]程艷霞,吳應良,劉勇.面向退貨管理的逆向物流信息系統建設的研究[J].科技進步與對策,2005(12):8-10.
