基于Hadoop的電信大數據采集方案研究與實現
2017-05-03 07:37:50汪保友錢晶袁時金
電信科學 2017年1期
關鍵詞:大數據
汪保友,錢晶,袁時金
(1.中國聯合網絡通信有限公司上海市分公司,上海 200050;2.同濟大學軟件學院,上海 201804)
基于Hadoop的電信大數據采集方案研究與實現
汪保友1,錢晶1,袁時金2
(1.中國聯合網絡通信有限公司上海市分公司,上海 200050;2.同濟大學軟件學院,上海 201804)
ETL是數據倉庫實施過程中一個非常重要的步驟,設計一個能夠對大數據進行有效處理的ETL流程以提高運營平臺的采集效率,具有重要的實際意義。首先簡單介紹某運營商大數據平臺采集的主要數據內容。隨后,為提升海量數據采集效率,提出了Hadoop與Oracle混搭架構解決方案。繼而,提出一種動態觸發式ETL調度流程與算法,與定時啟動的ETL流程調度方式相比,可有效縮短部分流程的超長等待時間;有效避免資源搶占擁堵現象。最后,根據Hadoop和Oracle的系統運行日志,比較分析了兩個平臺的采集效率與數據量之間的關系。實踐表明,混搭架構的大數據平臺優勢互補,可有效提升數據采集時效性,獲得比較好的應用效果。關鍵詞:大數據;ETL;Hadoop;調度流程;混搭架構
1 引言
移動互聯網時代,數據資源無疑是重要的戰略資源。電信運營商擁有龐大的活躍用戶群體,處在大數據產業鏈的傳輸與交換中心地位,具有豐富的高價值數據資源。除了用戶辦理業務時產生的用戶實名制基礎信息外,每天還會持續產生大量的用戶消費數據、用戶行為數據、用戶地理位置數據、用戶社交UGC數據等。智能終端的普遍使用,4G網絡的興起、網絡帶寬的大提速等業務和技術的發展,使得運營商的數據容量變得更大,數據增長速度變得更快,數據格式變得更復雜,大數據處理的及時性變得更為迫切。如何從海量低價值的數據庫中發現價值信息,如何在預期時間內實現價值發現過程,其基礎是要建立穩定可靠的企業級數據倉庫。眾所周知,ETL(extract-transform-load,抽取—轉換—加載)是數據倉庫實施過程中非常重要的一個步驟。國內外很多學者在研究中發現,ETL的實施時間通常要占到數據倉庫整個開發時間的60%~80%,是數據倉庫開發過程中最耗費時間的階段。ETL處理效率的高低、轉換質量的好壞,直接影響著數據倉庫的建設和數據挖掘結果的有效性。設計一個能夠對大數據進行有效處理的ETL流程,對提高運營平臺的采集效率具有重要的實際意義。
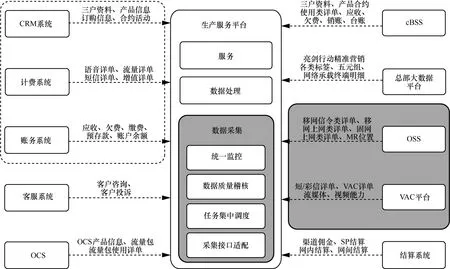
圖1 省分大數據平臺主要采集內容
2 主要采集內容
大數據產業的迅猛發展,給電信運營商開辟新的業務增長點,打開了機遇窗口。電信運營商在業務運營中產生大量用戶信息數據和行為數據,這些數據中包括 BSS(business support system,業務支持系統)域業務數據、OSS(operation support system,運營與支撐系統)域過程數據以及VAC平臺互聯網數據等,以700萬活躍用戶為例,每天產生大約16 TB的數據。BSS包括客戶關系管理(customer relationship management,CRM)、計費、賬務管理、在線計費系統 (online charging system,OCS)、客服、cBSS(central business support system,集中業務支撐系統)等系統,記錄用戶三戶資料、產品、訂購、合約活動等基礎信息,用戶流量、語音、短信等使用詳單信息,應收、預存款、繳費、欠費、賬戶余額等賬務數據;OSS包括基站、傳輸、固網和核心網等網絡單元,記錄大量信令類詳單、上網類詳單、MR測量報告位置數據等。
圖1列出了某省級運營商大數據平臺主要采集內容。
在圖1中,左邊和右上側代表來源于省分BSS、總部cBSS及總部大數據平臺,內容是賬單、詳單、用戶資料、產品服務訂購、業務受理記錄等結構化明細數據以及總部下發的各類明細及標簽數據等。這部分數據量相對占比較小(約占運營商數據總量的5%左右);右側陰影部分,來源于OSS和VAC平臺,主要是信令類數據、位置數據和互聯網內容數據,有半結構化、非結構化的數據,數據量特別龐大(約占運營商數據總量的95%)。
3 方案設計
3.1 問題提出
在長時間的系統運維實踐中,從“5M1E(人機料法環測)”6個方面,采用魚骨圖法對“采集響應耗時長”的原因進行歸納總結,列出了12個末端原因,如圖2所示。
其中,“海量數據采集耗時長”“流程等待時間長”兩個原因,是影響 “采集響應及時率”的關鍵因素。考慮到Hadoop計算架構具有的高性能集群計算和存儲能力,且易擴展,選擇采用Hadoop與傳統關系型數據庫混搭模式,優勢互補,既可提升數據采集時效性,又可確保核心數據服務能力的穩定。
Hadoop由Apache Lucene創始人Cutting D創建,其核心組件是HDFS和MapReduce。Hadoop通過HDFS為用戶提供高容錯性和高伸縮性的海量數據的分布式存儲,通過MapReduce為用戶提供邏輯簡單、底層透明的并行處理框架。Hadoop底層存儲和并行計算需要對用戶進行透明化處理,可以按照實際需要搭建平臺,易擴展,通過增加集群節點,可以線性地擴展計算能力。Hadoop2.0生態圈如圖3所示。
HDFS具有高容錯性,適合批處理、大數據處理,可構建在廉價機器上等優點,缺點是不適宜小文件存取、并發寫入、文件隨機修改。MapReduce是一種線性可伸展的編程模型,它建立了清晰的抽象層,采用“分而治之”思想,為用戶提供邏輯簡單、底層透明的并行處理框架。
Hive支持HQL語言 (一種類似傳統SQL的語言),允許用戶運行與SQL類似的操作,通過編譯器將SQL腳本轉換成對應的MapReduce程序運行,讓熟悉SQL編程的人員也能擁抱Hadoop。Hive是一種純邏輯意義上的表,Hive的表格邏輯上通過元數據進行組織和描述 (表名、表列、分區及屬性),通過HDFS進行數據的實際存儲。簡而言之,Hive是基于Hadoop體系結構進行大數據存儲及處理的數據倉庫工具,它使用HQL作為查詢接口,使用HDFS作為底層存儲,使用MapReduce作為執行層,通過把類 SQL腳本編譯解析成 MapReduce程序,簡化MapReduce編程的復雜度。
3.2 基于Hadoop的采集預處理架構
采用Hadoop、傳統關系型數據庫混搭架構,揚長避短,對大數據平臺數據進行分層管理。利用Hadoop分布式并行計算框架,對海量數據、非結構化數據進行采集預處理整合,存儲SRC層、ODS層數據以及DWD層加工過度數據。將傳統成熟關系型數據庫(Oracle、DB2等)作為主數據倉庫,對DWD層、DWA層、DM層數據進行存儲管理,存儲用戶標簽庫、客戶立體全息視圖、粗粒度匯總數據、報表數據、多維數據、指標庫等結果數據,確保核心數據服務能力的穩定。采用混搭架構的大數據支撐平臺,其邏輯架構如圖4所示。
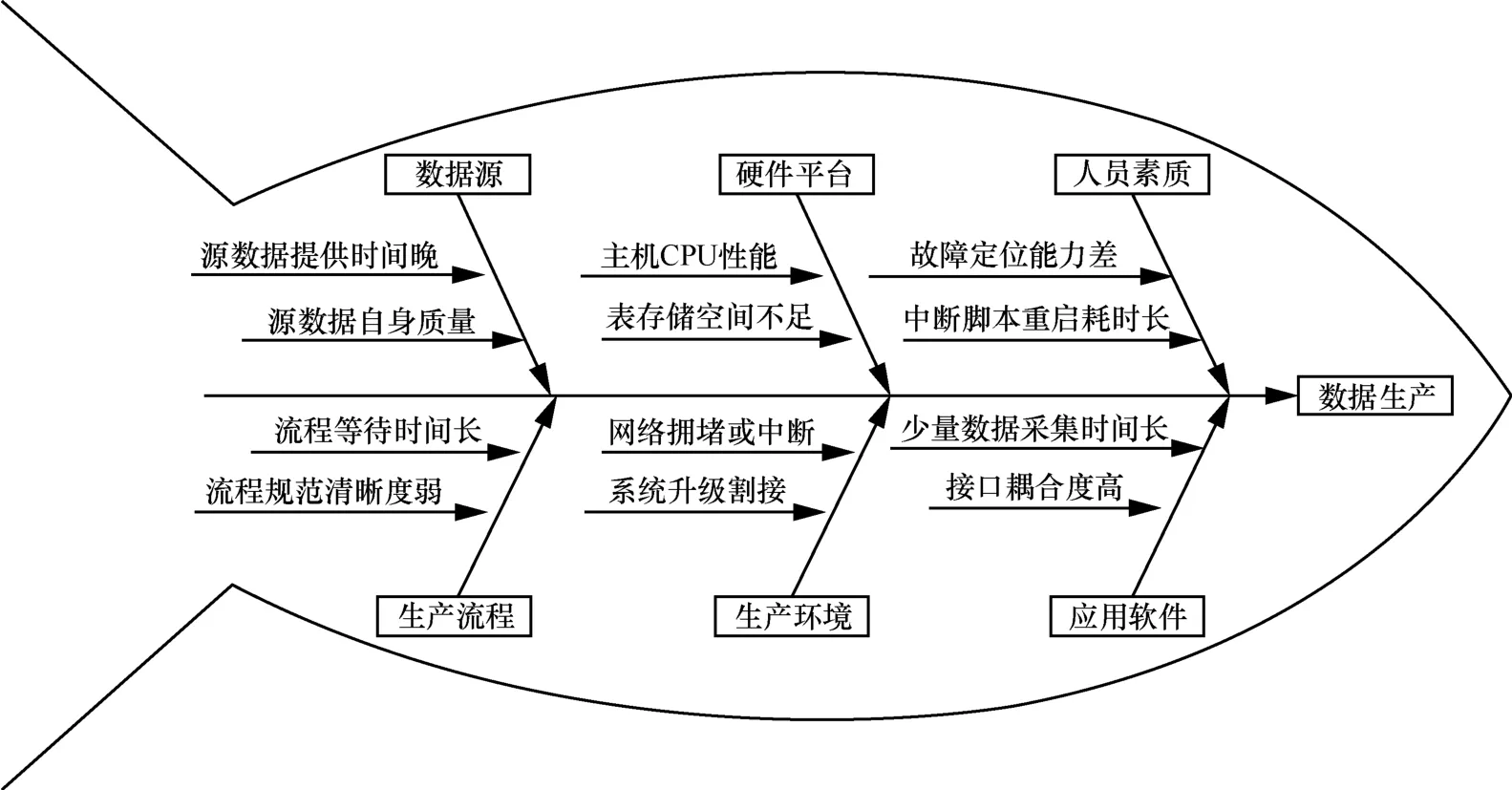
圖2 采集響應影響因素
圖4主要包括4層結構,即數據獲取層、數據存儲層、數據應用層和數據服務層。采集的數據源涵蓋了電信運營商擁有的過程數據和業務數據,數據資源的真實性、豐富性、完整性、連續性,集中體現運營商大數據優勢。數據獲取層通過基于Hadoop的ETL加工過程,包括數據校驗、數據清洗、數據關聯、數據匯總、數據聚合等系列加工流程,進行深度分析和信息挖掘,在數據存儲層形成企業數據倉庫和數據集市。數據存儲層包括Hadoop管理的SRC/ ODS粒度數據以及Oracle管理的DWD/DWA、DM粒度數據。數據應用層表現形式包括:智能網優、精準營銷、征信產品、智慧足跡、用戶標簽、用戶維系、OLAP分析、異動分析、運營監控、KPI、電子書、行業應用等生產服務支撐體系。在數據服務層,可通過個性化定制、信息推送、用戶搜素、能力開放等方式,實現對內對外服務。在整個數據加工處理、流轉服務過程中,數據質量、數據標準、元數據、生命周期等數據管理措施貫穿始終;通過安全制度、安全技術、
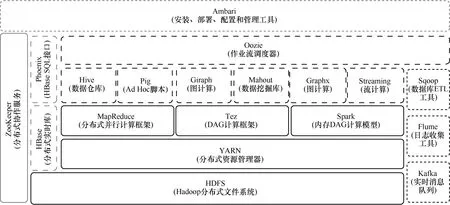
圖3 Hadoop2.0生態圈
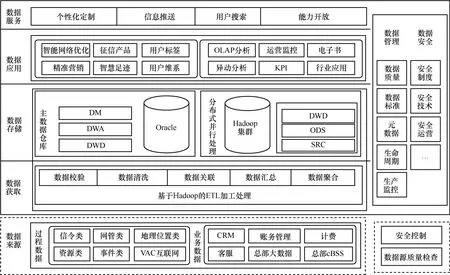
圖4 大數據平臺邏輯架構
安全運營、安全教育等運營機制確保數據安全。
采用混搭架構的大數據支撐平臺,其網絡架構拓撲如圖5所示。
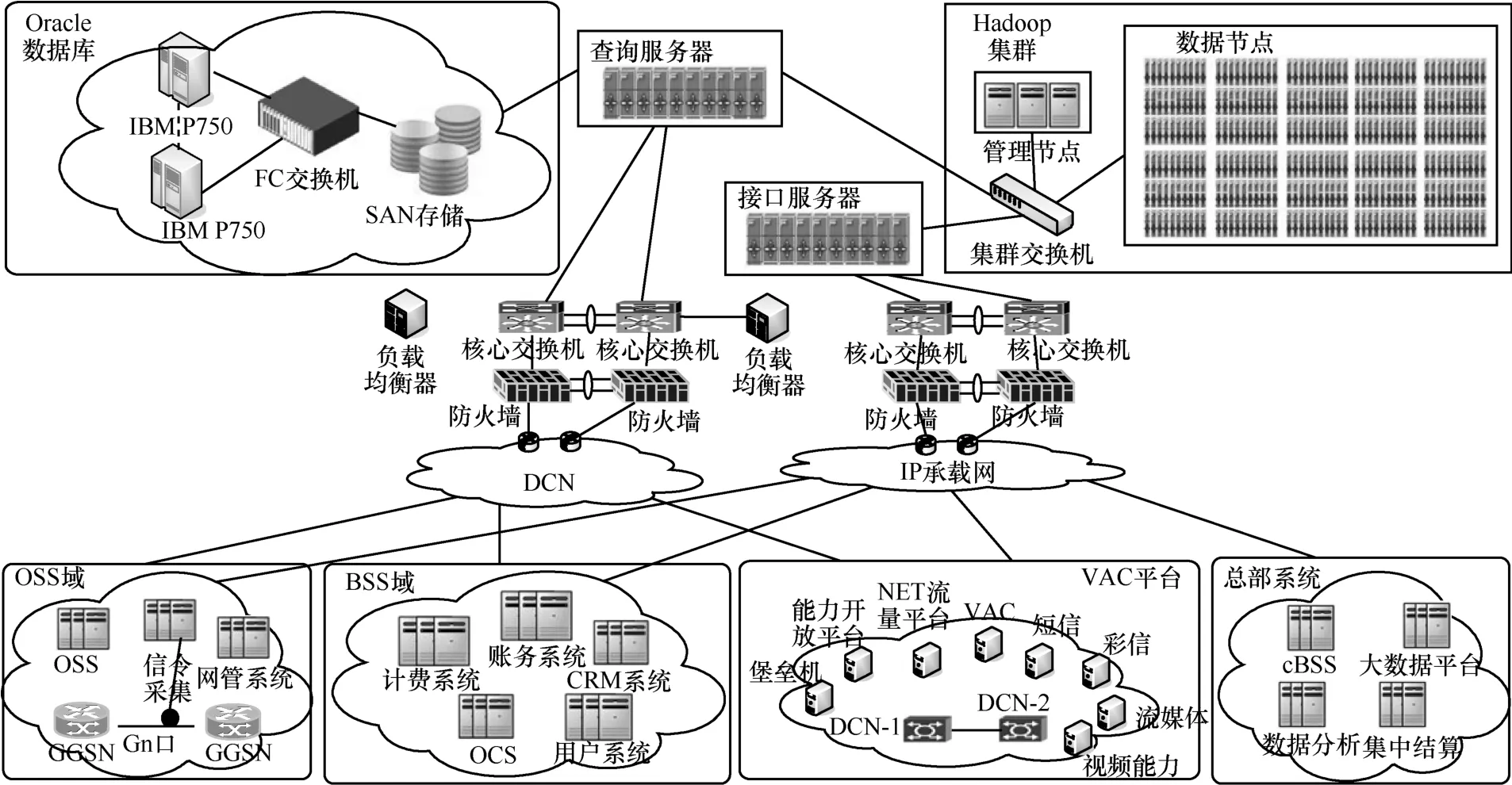
圖5 大數據平臺網絡架構拓撲
圖5的上半部分,是基于IOE的Oracle數據庫以及基于x86的Hadoop集群,組成了混搭架構的大數據平臺的硬件與系統軟件環境;圖5的下半部分,是采集數據源的拓撲,包括OSS域系統、BSS域系統、VAC平臺的各業務平臺和總部集中系統等。兩者之間通過查詢服務器、接口服務器、DCN、IP承載網等實現數據傳輸交互。
3.3 動態觸發式ETL調度流程
數據采集應用軟件部署在Hadoop集群接口機上,程序腳本規范為兩種類型,分別是:基礎邏輯腳本和業務邏輯腳本。其中,基礎邏輯腳本包含了日志記錄、注釋、配置文件讀取等工作,并調用業務邏輯腳本。業務邏輯腳本使用HQL語言編寫HQL語句,類同于SQL。
ETL流程調度方式一般有兩種方式:定時啟動式、事件觸發式。為方便采集流程調度與監控,在Oracle數據庫上部署了幾張實體表,包括:業務邏輯前置條件配置表、應采集接口配置表、FTP文件檢查日志、接口文件稽核日志、接口文件采集日志、SRC層已裝載觸發ODS流程日志表、ETL執行日志表等。提出一種動態觸發式ETL調度流程與算法,改變了以往定時啟動的ETL流程調度方式,可有效縮短部分流程的超長等待時間;同時通過并發量的監測和控制,可有效避免資源搶占擁堵現象,從而更有效地提升所有采集流程的整體完成時間。這種事件觸發式調度,每個ETL流程都預先配置了自動觸發的條件,可能包括n個接口文件、m個依賴流程;如果n個接口采集和m個依賴流程處理完成,則觸發該流程。所有流程通過任務集中調度,在適當的時間自動觸發運行,經過 ETL加工過程以及數據質量稽核,實現數據自動流動,直至完成全部流程。
動態觸發式ETL調度流程如圖6所示。
4 雙平臺效率比較
Hadoop與Oracle優勢有互補性,在工程實施過程中,把原先Oracle平臺的數據采集存儲過程腳本,平行遷移為Hadoop平臺的業務邏輯腳本,同時保持雙平臺并行運行一段時間,采集的數據源完全一樣,這為比較兩個平臺的優勢和效率提供了一樣的基準。通過對幾十萬條的運行日志圖形化分析,總的來說,Hadoop在大數據量時執行效率要好于Oracle。但在數據量小時,Oracle要好于Hadoop。為了避免超大數對微小數的淹沒,采用分段展現方式。
圖7是根據兩個平臺的實際運行日志結果,分段列出了Hadoop平臺與Oracle平臺的采集效率比較。
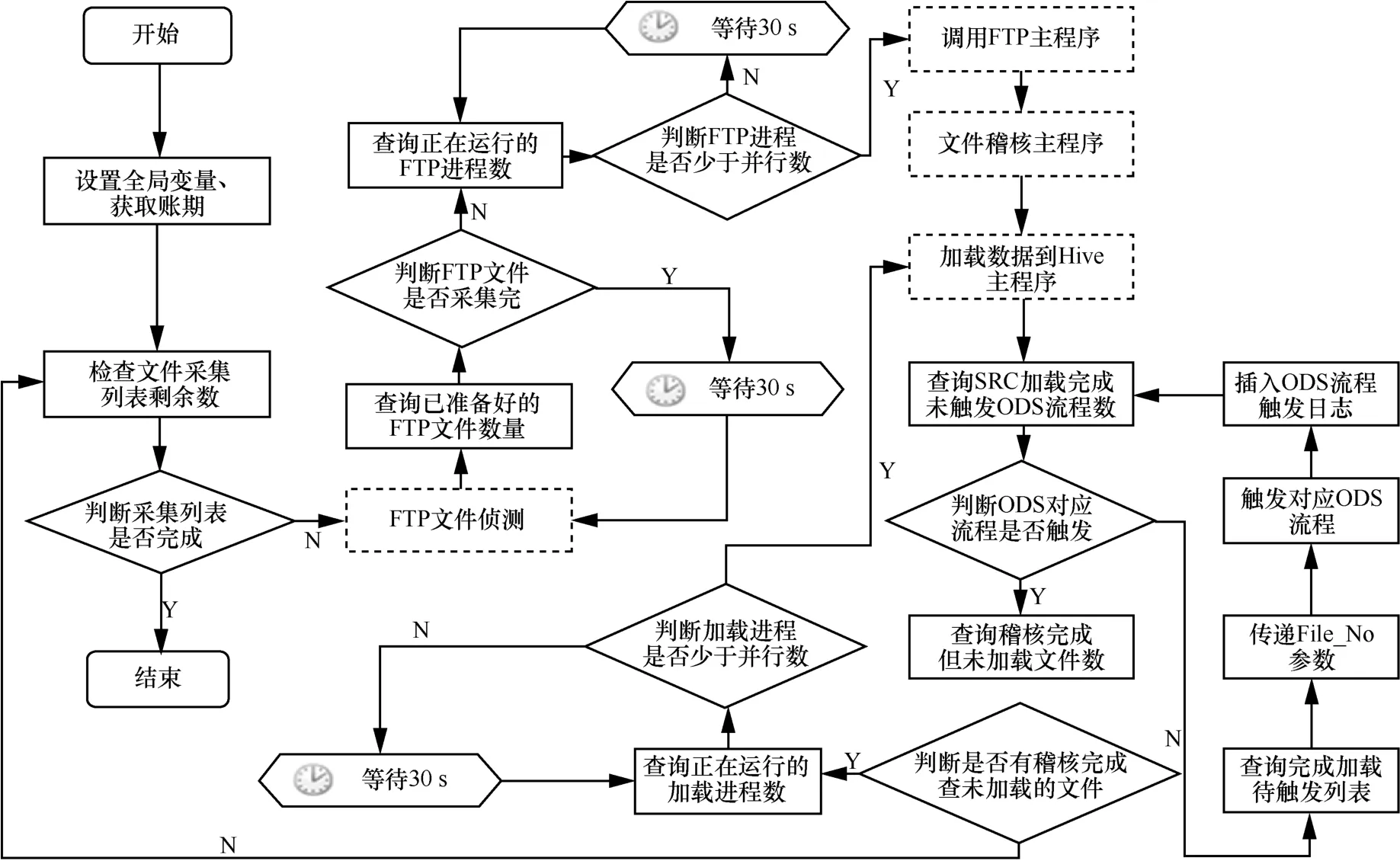
圖6 動態觸發式ETL調度流程
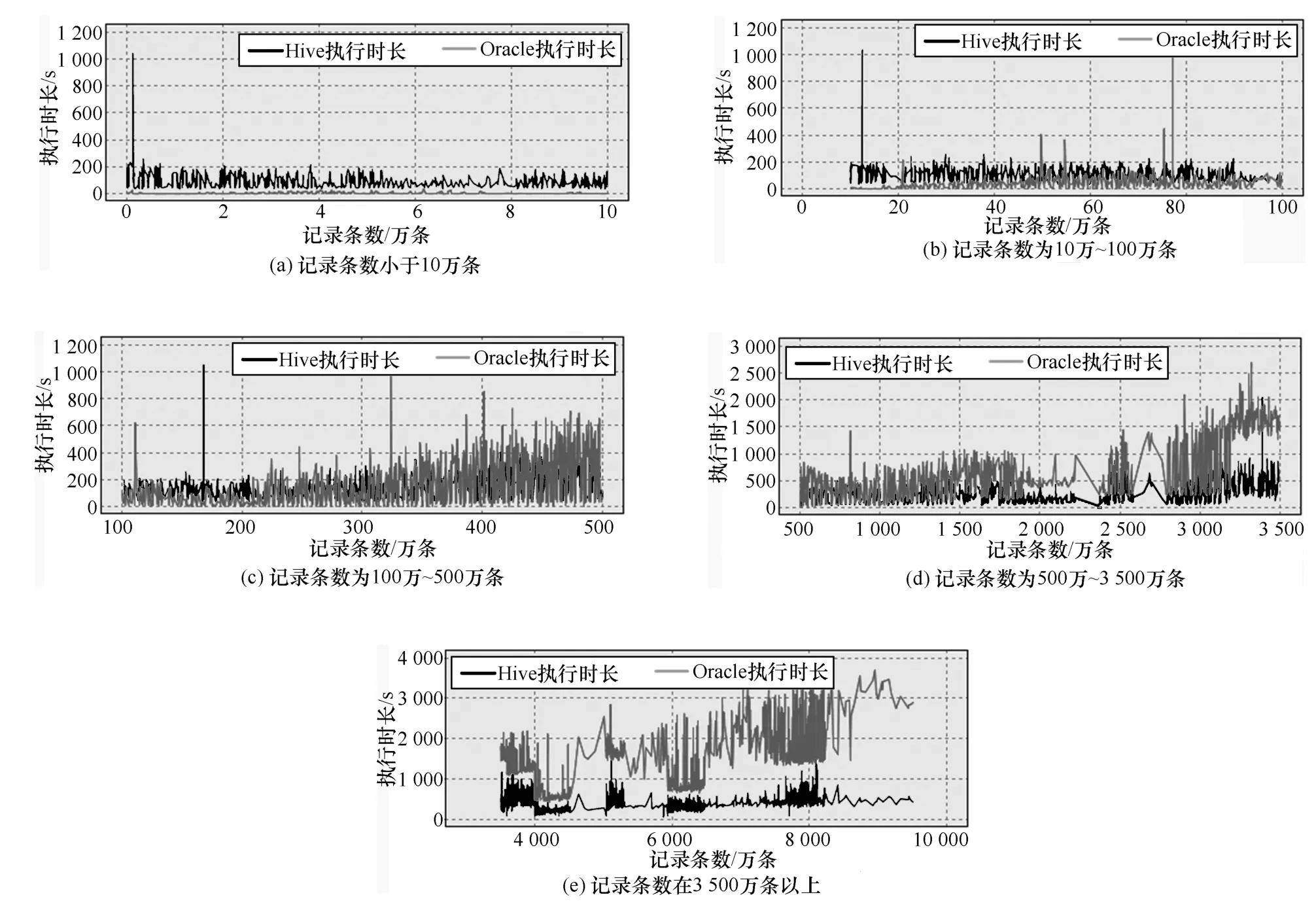
圖7 雙平臺日數據采集(時長)與記錄數量關系比較
記錄條數小于10萬條時,Oracle耗時很短,Oracle效率明顯好于Hive。記錄條數為10萬~100萬條時,Oracle效率好于Hive,隨記錄條數增大,耗時在增大,但Hive的耗時變化不明顯。在100萬條附近,Oracle與Hive的效率基本持平。記錄條數為100萬~500萬條時,Oracle耗時逐漸超過Hive;Hive的效率開始體現。記錄條數為500萬~3 500萬條時,Hive效率好于Oracle。隨記錄數增大,Oracle耗時增長快,與Hive效率差距增大。記錄條數在3 500萬條以上時,Oracle耗時長,Hive效率明顯好于Oracle。分析發現,Hadoop平臺對海量數據接口的采集效率優化效果明顯,對千萬條記錄以上的日接口大表,Hadoop平臺的采集時長相比Oracle平臺縮短50%~80%。圖8列出雙平臺對海量數據(千萬條以上)采集效率氣泡圖。

圖8 雙平臺對海量數據(千萬條以上)采集效率氣泡圖
其中“賬單流水表”接口(全量記錄條數平均72 000萬條),采集耗時最長;“流量詳單表”數據增幅很大(日增量記錄條數平均3 500萬條);是原先Oracle平臺采集效率的瓶頸。圖9是這兩個接口的雙平臺采集效率對比。
其中,賬單流水接口,Oracle采集時長平均在110 min,Hadoop采集時長為53 min,效率提升52%;流量詳單日采集接口,Oracle采集時長平均在26 min,Hadoop采集時長為9 min,效率提升67%。
但從圖9也可看出,對數據量較小的表(尤其是一些代碼表)、需要頻繁增刪改的表、需要多表復雜關聯分析等,這些場景不適宜于在Hadoop上管理;相反,這些場景,Oracle可以實現很好的管理。同樣Hadoop對海量數據、非結構化數據的處理效率,明顯好于Oracle等傳統關系型數據庫。從成本上考慮,Hadoop比Oracle的優勢明顯;從易于維護上考慮,Oracle反過來比Hadoop優勢明顯;同時Oracle的可靠性比Hadoop高。
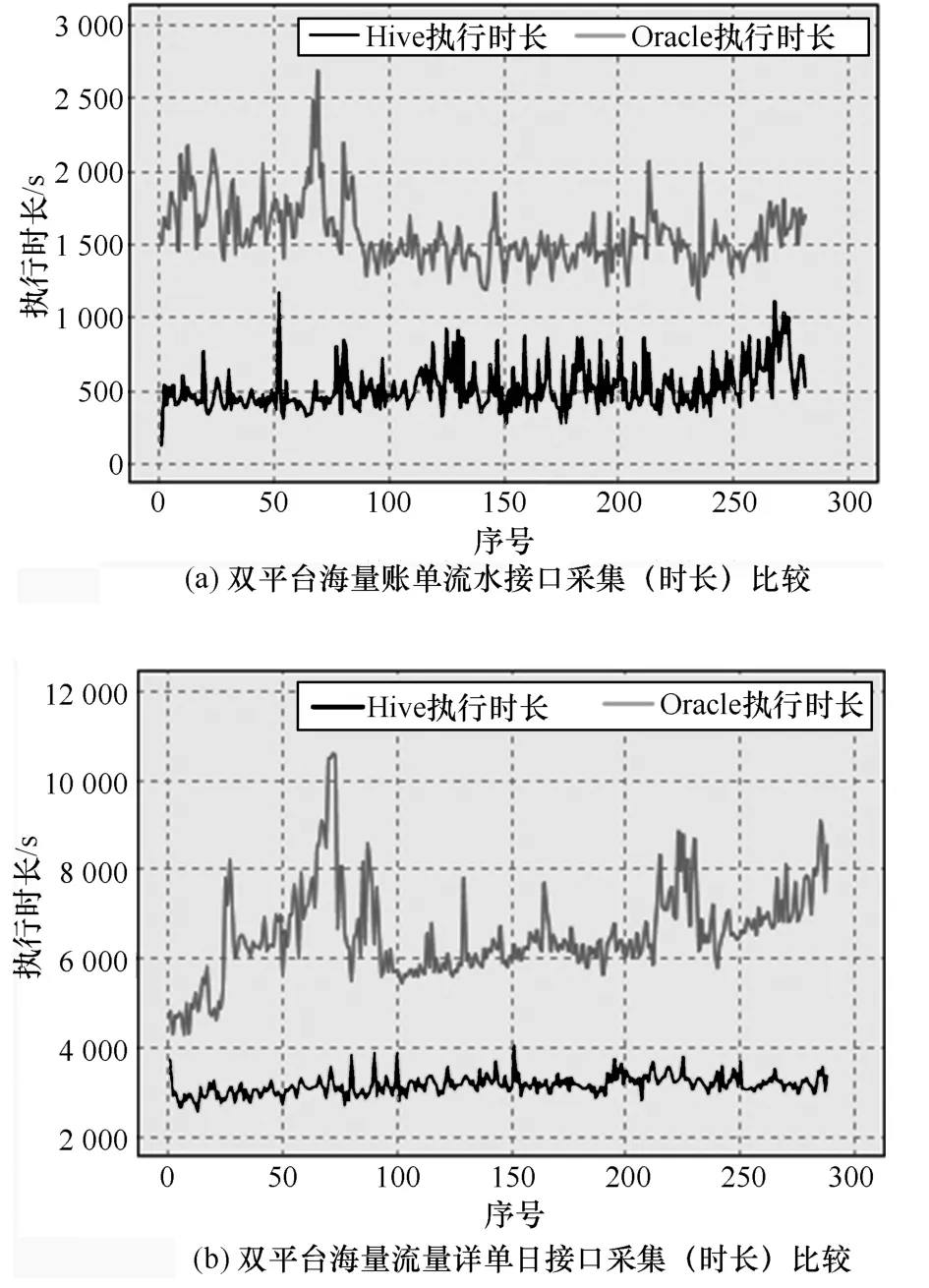
圖9 兩個接口的雙平臺采集效率對比
總的來說,通過Hadoop與Oracle混搭架構以及動態觸發式ETL調度流程兩大舉措,可有效提升數據采集時效性,在實踐中取得了比較好的應用效果。
5 結束語
ETL是數據倉庫建設中非常重要的環節,本文提出Hadoop與 Oracle混搭解決方案,對電信大數據分層管理,利用Hadoop的并行計算和存儲優勢,對海量數據、非結構化數據進行采集預處理整合,可有效提升海量數據采集效率。同時提出一種動態觸發式ETL調度流程與算法,與定時啟動的ETL流程調度方式相比,可有效縮短部分流程的超長等待時間,有效避免資源搶占擁堵現象。在某運營商大數據平臺建設的實踐過程中,取得了比較好的應用效果,有效確保了公司每天經營分析數據的及時展現,提升了數據服務支撐的時間窗口,提升了公司內外部客戶的滿意度,對業界也有一定借鑒作用。
[1]許佳捷,鄭凱,池明旻,等.軌跡大數據:數據、應用與技術現狀[J].通信學報,2015,36(12):97-105.XU J J,ZHENG K,CHI M M,et al.Trajectory big data:data, applications and techniques[J].Journal on Communications, 2015,36(12):97-105.
[2]劉南海,雷蕾,王睿.大數據時代運營商分析支撐域轉型的實踐與思考[J].電信科學,2016,32(8):146-158.LIU N H,LEI L,WANG R.Practice and thinking on the transition of telecom operator analysis support system in big data era [J].Telecommunications Science,2016,32(8): 146-158.
[3]金澈清,錢衛寧,周敏奇,等.數據管理系統評測基準:從傳統數據庫到新興大數據 [J].計算機學報,2015,38(1): 18-34. JIN C Q,QIAN W N,ZHOU M Q,et al.Benchmarking data management systems:from traditional database to emergent big data[J].Chinese Journal of Computers,2015,38(1):18-34.
[4]曾嘉,劉詩凱,袁明軒.電信大數據關鍵技術挑戰[J].大數據, 2016,2(3):96-105. ZENG J,LIU S K,YUAN M X.Key technical challenges in telecom big data[J].Big Data Research,2016,2(3):96-105.
[5]詹義,方媛.基于Spark技術的網絡大數據分析平臺搭建與應用[J].互聯網天地,2016(2):75-78. ZHAN Y,FANG Y.Building and application of network big data analysis platform based on Spark technology[J].China Internet,2016(2):75-78.
[6]劉珂.基于Hadoop平臺的大數據遷移與查詢方法研究及應用[D].武漢:武漢理工大學,2014. LIU K.Research and application of big data migration and query based on Hadoop platform[D].Wuhan:Wuhan University of Technology,2014.
Research and implementation on acquisition scheme of telecom big data based on Hadoop
WANG Baoyou1,QIAN Jing1,YUAN Shijin2
1.Shanghai Branch of China United Network Communication Co.,Ltd.,Shanghai 200050,China 2.School of Software Engineering,Tongji University,Shanghai 201804,China
ETL is a very important step in the implementation process of data warehouse.A good ETL flow is important,which can effectively process the telecom big data and improve the acquisition efficiency of the operation platform.Firstly,the main data content of the big data platform was expounded.Secondly,in order to improve the efficiency of massive data collection,Hadoop and Oracle mashup solution was suggested.Subsequently,a dynamic triggered ETL scheduling flow and algorithm was proposed.Compared with timer start ETL scheduling method,it could effectively shorten waiting time and avoid the phenomenon of resources to seize and congestion.Finally, according to the running log of Hadoop platform and Oracle database,the relationship between acquisition efficiency and data quantity was analyzed comparatively.Furthermore,practice result shows that the hybrid data structure of the big data platform complement each other and can effectively enhance the timeliness of data collection and access better application effect.
big data,ETL,Hadoop,scheduling process,mashup architecture
TP311
A
10.11959/j.issn.1000-0801.2017010

汪保友(1968-),男,博士,中國聯合網絡通信有限公司上海市分公司高級工程師,主要研究方向為數據科學、數據挖掘、數據簽名。

錢晶(1970-),女,中國聯合網絡通信有限公司上海市分公司工程師,主要研究方向為數據科學、移動互聯網、通信網絡規劃。

袁時金(1975-),女,博士,同濟大學軟件學院副教授,主要研究方向為大數據與高性能計算。
2016-12-11;
2017-01-03
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
