基于深度學(xué)習(xí)的醫(yī)療命名實(shí)體識(shí)別
2017-05-08 21:07張帆王敏??
計(jì)算技術(shù)與自動(dòng)化 2017年1期
關(guān)鍵詞:數(shù)據(jù)挖掘深度學(xué)習(xí)
張帆+王敏??
摘要:在較為深入地研究醫(yī)療文本實(shí)體識(shí)別的現(xiàn)有方法的基礎(chǔ)上,設(shè)計(jì)一種基于深度學(xué)習(xí)的醫(yī)療文本實(shí)體識(shí)別方法。本文在醫(yī)療文本數(shù)據(jù)集上進(jìn)行實(shí)體識(shí)別對(duì)比實(shí)驗(yàn),所識(shí)別目標(biāo)實(shí)體包含疾病,癥狀,藥品,治療方法和檢查五大類(lèi)。實(shí)驗(yàn)結(jié)果表明,設(shè)計(jì)的深度神經(jīng)網(wǎng)絡(luò)模型能夠很好的應(yīng)用到醫(yī)療文本實(shí)體識(shí)別,本文所設(shè)計(jì)的方法比傳統(tǒng)算法(如CRF)具有較少人工特征干預(yù)及更高的準(zhǔn)確率和召回率等優(yōu)點(diǎn)。
關(guān)鍵詞:實(shí)體識(shí)別; 數(shù)據(jù)挖掘; 深度學(xué)習(xí); 醫(yī)療信息
中圖分類(lèi)號(hào):U491.14文獻(xiàn)標(biāo)識(shí)碼:ADOI:10.3969/j.issn.10036199.2017.01.025
1引言
醫(yī)療文本實(shí)體識(shí)別是醫(yī)療知識(shí)挖掘,醫(yī)療智能機(jī)器人,醫(yī)療臨床決策支持系統(tǒng)等應(yīng)用領(lǐng)域的重要基礎(chǔ)工作。最近一大批在線醫(yī)療信息,社區(qū)及遠(yuǎn)程問(wèn)診網(wǎng)站及其應(yīng)用迅猛發(fā)展。這些網(wǎng)站為病患者提供多元化的醫(yī)療信息獲取渠道。同時(shí)產(chǎn)生大量疾病問(wèn)答信息與醫(yī)療文本。這些信息將匯成一股非常可觀的大數(shù)據(jù)。并且這些醫(yī)療文本中有大量真實(shí)的個(gè)人案例,潛藏著豐富的醫(yī)療價(jià)值。但是這些醫(yī)療文本大多處于一種非結(jié)構(gòu)化的狀態(tài)。為充分挖掘其中的價(jià)值,并為接下來(lái)醫(yī)療問(wèn)答等應(yīng)用打好基礎(chǔ)工作,醫(yī)療文本實(shí)體識(shí)別是必不可少的步驟。
2相關(guān)工作
命名實(shí)體識(shí)別這個(gè)概念是在MUC6(Message Understanding Conference)會(huì)議被提出。命名實(shí)體識(shí)別主要任務(wù)是識(shí)別出文本中出現(xiàn)專(zhuān)有名稱(chēng)和有意義的數(shù)量短語(yǔ)并加以歸類(lèi)。通用的命名識(shí)別主要包含實(shí)體(組織名、人名、地名),時(shí)間表達(dá)式(日期、時(shí)間),數(shù)字表達(dá)式(貨幣值、百分?jǐn)?shù))等。在生物醫(yī)學(xué)領(lǐng)域,目前比較集中的研究是針對(duì)醫(yī)學(xué)文獻(xiàn)中的基因、蛋白質(zhì)、藥物名、組織名等相關(guān)生物命名實(shí)體識(shí)別工作[1]。隨著醫(yī)療系統(tǒng)的信息化, 也出現(xiàn)大量針對(duì)電子病歷進(jìn)行的識(shí)別工作。
目前常用的命名實(shí)體識(shí)別方法分為兩大類(lèi):基于規(guī)則和知識(shí)的方法與基于統(tǒng)計(jì)的方法。基于規(guī)則和知識(shí)的方法是一種最早使用的方法,這種方法簡(jiǎn)單,便利[2]。基于規(guī)則和知識(shí)方法缺點(diǎn)是需要大量的人工觀察,可移植性較差。基于統(tǒng)計(jì)的方法將命名實(shí)體識(shí)別看作一個(gè)分類(lèi)問(wèn)題,采用類(lèi)似支持向量機(jī),貝葉斯模型等分類(lèi)方法;同時(shí)也可以將命名實(shí)體識(shí)別看作一個(gè)序列標(biāo)注問(wèn)題,采用隱馬爾可夫鏈、最大熵馬爾可夫鏈、條件隨機(jī)場(chǎng)等機(jī)器學(xué)習(xí)序列標(biāo)注模型[3-6]。這些方法都需要人依靠邏輯直覺(jué)和訓(xùn)練語(yǔ)料中的統(tǒng)計(jì)信息手工設(shè)計(jì)出大量特征。這些統(tǒng)計(jì)學(xué)習(xí)方法識(shí)別性能很大程度上依賴(lài)于特征的準(zhǔn)確度,所以要求團(tuán)隊(duì)中要有語(yǔ)言學(xué)專(zhuān)家。
加拿大多倫多大學(xué)的Hinton教授[7]提出深度學(xué)習(xí)的概念,在全球掀起一次熱潮。深度學(xué)習(xí)通過(guò)模仿人腦多層抽象機(jī)制來(lái)實(shí)現(xiàn)對(duì)數(shù)據(jù)(圖像、語(yǔ)音和文本等)的抽象表達(dá),將特征學(xué)習(xí)和分類(lèi)整合到一個(gè)統(tǒng)一的學(xué)習(xí)框架中,從而減少手工特征制定的工作量。最近幾年來(lái),深度學(xué)習(xí)在圖像識(shí)別和語(yǔ)音識(shí)別等領(lǐng)域已經(jīng)取得巨大成功。深度學(xué)習(xí)技術(shù)在原始字符集上提取同樣也受到很多關(guān)注。因?yàn)樯疃葘W(xué)習(xí)技術(shù)可以在原始字符集上提取高級(jí)特征,所以本文利用深度學(xué)習(xí)技術(shù)在大量未標(biāo)記醫(yī)療語(yǔ)料上無(wú)監(jiān)督地學(xué)習(xí)到詞特征、不用依賴(lài)人工設(shè)計(jì)特征,從而達(dá)到實(shí)體識(shí)別的目的。
針對(duì)實(shí)體識(shí)別這一任務(wù),本文用到神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型對(duì)詞進(jìn)行分布式表達(dá)。神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型利用神經(jīng)網(wǎng)絡(luò)對(duì)詞的概率分布進(jìn)行估計(jì)、生成模型,從而得到詞與詞之間的關(guān)系;同時(shí)該模型是一種無(wú)監(jiān)督訓(xùn)練模型,可以從大量未標(biāo)記的非結(jié)構(gòu)化文本中學(xué)習(xí)出詞語(yǔ)的分布式表示,并且可以對(duì)詞語(yǔ)之間的關(guān)系以及相似度進(jìn)行建模。
神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型(NNLM)[8]是2003年由Bengio提出,直至近年來(lái)由于硬件成本降低、文本數(shù)量急劇增加,神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型開(kāi)始逐漸被應(yīng)用到多種自然語(yǔ)言處理任務(wù)中,并取得了不錯(cuò)的效果。縱觀神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型的演變過(guò)程,同樣也說(shuō)一個(gè)逐步完善和逐步應(yīng)用的過(guò)程。2011年Mikolov等[9]使用循環(huán)神經(jīng)網(wǎng)絡(luò)改進(jìn)了Bengio的神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型,該模型在語(yǔ)音識(shí)別上的應(yīng)用性能要優(yōu)于傳統(tǒng)的n-gram語(yǔ)言模型。2011年Collobert等[10]提出了一個(gè)統(tǒng)一的神經(jīng)網(wǎng)絡(luò)架構(gòu)及其學(xué)習(xí)算法,并設(shè)計(jì)了SENNA系統(tǒng)可用于解決語(yǔ)言建模、詞性標(biāo)記、組塊分析、命名實(shí)體識(shí)別、語(yǔ)義角色標(biāo)記和句法分析等問(wèn)題。2013年Zheng等[11]在大規(guī)模未標(biāo)記數(shù)據(jù)集上改進(jìn)了中文詞語(yǔ)的內(nèi)在表示形式,并使用深度學(xué)習(xí)模型發(fā)現(xiàn)詞語(yǔ)的深層特征以解決中文分詞和詞性標(biāo)記問(wèn)題。2016年Z Jiang等[12] 提出一種基于圖的詞向量表達(dá),并將其應(yīng)用到醫(yī)療文本挖掘中。2016年SR Gangireddy等[13]提出一種自適應(yīng)的RNN神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型,并將其用到自然語(yǔ)音識(shí)別上。本文在前人研究基礎(chǔ)上,利用神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型構(gòu)建了詞的分布式特征,從而使醫(yī)療詞匯的命名實(shí)體識(shí)別更加具有可應(yīng)用價(jià)值。
3算法模型設(shè)計(jì)
本文設(shè)計(jì)一種可以用于命名實(shí)體識(shí)別的深層神經(jīng)網(wǎng)絡(luò)架構(gòu),該架構(gòu)的本質(zhì)是構(gòu)建具有多層的神經(jīng)網(wǎng)絡(luò),學(xué)習(xí)出更有用的特征,從而提升識(shí)別的性能。比自然語(yǔ)言處理任務(wù)中常用模型如:條件隨機(jī)場(chǎng)模型,SVM,貝葉斯模型,該架構(gòu)具有兩大優(yōu)勢(shì):1. 傳統(tǒng)的稀疏特征被稠密的分布式特征取代;2. 利用深度學(xué)習(xí)結(jié)構(gòu)以發(fā)現(xiàn)更高級(jí)的特征。
3.1命名實(shí)體識(shí)別的深層架構(gòu)
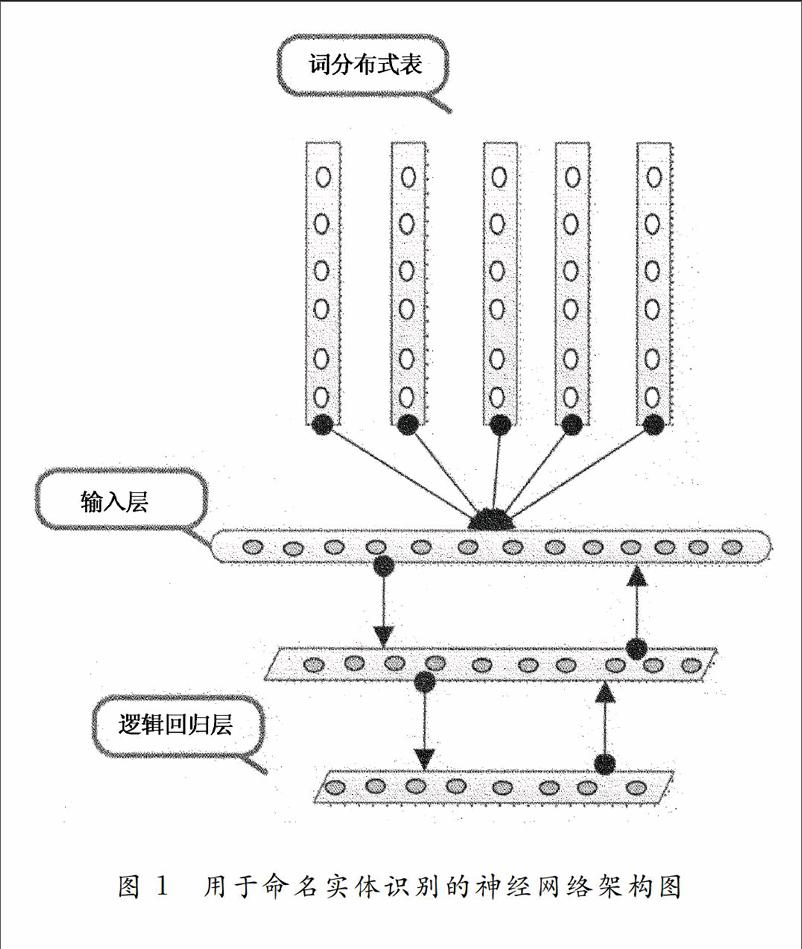
本文的神經(jīng)網(wǎng)絡(luò)至少包含三層,第一層是輸入層,第二層是隱含層,第三層是輸出層。
該深層網(wǎng)絡(luò)的輸入是詞分布式表達(dá),輸入的詞向量也需要訓(xùn)練和優(yōu)化模型參數(shù);隱含層可以有多層,本文為提高訓(xùn)練速度,使用單層作為隱含層;輸出層采用損失函數(shù)為二元交叉熵的邏輯分類(lèi)器構(gòu)成。
該架構(gòu)主要思路是將實(shí)體識(shí)別看作一個(gè)分類(lèi)問(wèn)題。其輸入是詞向量表達(dá)與上下文詞匯的詞向量。這些詞向量替代了傳統(tǒng)機(jī)器學(xué)習(xí)方法人工定義的特征,將這些詞向量輸入到神經(jīng)網(wǎng)絡(luò),然后通過(guò)隱含層將這些詞向量轉(zhuǎn)換為另外向量,再通過(guò)邏輯回歸層進(jìn)行分類(lèi),得到每個(gè)詞的實(shí)體名概率,從而完成此實(shí)體識(shí)別工作(如圖1所示)。3.2分布式表示
上文提到神經(jīng)網(wǎng)絡(luò)的輸入是詞向量。
對(duì)詞特征和詞性特征進(jìn)行傳統(tǒng)的特征表示,那么任意兩個(gè)詞語(yǔ)之間或者任意兩個(gè)詞性標(biāo)記之間都是孤立的、沒(méi)有聯(lián)系的。對(duì)詞特征和詞性特征進(jìn)行分布式表示,即把每個(gè)詞語(yǔ)或者每個(gè)詞性標(biāo)記都表示為一個(gè)低維實(shí)數(shù)向量,那么任意兩個(gè)詞語(yǔ)之間或者任意兩個(gè)詞性標(biāo)記之間的歐氏距離將更近。
詞語(yǔ)特征的分布式表示可解決機(jī)器學(xué)習(xí)中的維數(shù)災(zāi)難和局部泛化限制等問(wèn)題,相比于傳統(tǒng)的特征表示方式可以更深入地探索輸入數(shù)據(jù)之間的固有聯(lián)系,捕獲其內(nèi)部的語(yǔ)法、語(yǔ)義相似性。當(dāng)遇到訓(xùn)練語(yǔ)料中未出現(xiàn)的詞語(yǔ)或詞性標(biāo)記時(shí),采用詞語(yǔ)特征的分布式表達(dá)訓(xùn)練出的模型仍然能夠有較好的表現(xiàn)。
3.3前饋神經(jīng)網(wǎng)絡(luò)函數(shù)
一個(gè)詞的實(shí)體識(shí)別需要考慮該詞的上下文環(huán)境,這樣識(shí)別準(zhǔn)確度才能更高。本文神經(jīng)網(wǎng)絡(luò)輸入層是窗口詞向量,而不只是單個(gè)詞的詞向量。定義窗口大小為C,當(dāng)C=1時(shí)則表示輸入是一個(gè)詞向量。隱含層的輸入是窗口詞向量,是一個(gè)C*M的矩陣。C為窗口大小,M為詞向量的維度。隱含層的輸出作為邏輯回歸層的特征。邏輯回歸層將計(jì)算窗口的中心詞為各個(gè)類(lèi)別的概率。故本文網(wǎng)絡(luò)架構(gòu)的前饋神經(jīng)網(wǎng)絡(luò)函數(shù)如下:
3.6參數(shù)訓(xùn)練
對(duì)該深層架構(gòu)的訓(xùn)練本質(zhì)是在訓(xùn)練語(yǔ)料上計(jì)算模型中的未知參數(shù),未知參數(shù)主要包括隱含層的若干參數(shù),還包含邏輯回歸層中的變換矩陣W∈Ry×n和偏置矩陣b∈Ry×n。訓(xùn)練神經(jīng)網(wǎng)絡(luò)需要用到反向傳播算法和SGD(隨機(jī)梯度下降)算法。具體參數(shù)訓(xùn)練流程為:
第一步:隨機(jī)初始化網(wǎng)絡(luò)全部參數(shù),包含隱含層、邏輯回歸層參數(shù)。
第二步:隨機(jī)挑選一個(gè)訓(xùn)練樣本(xi,yi),首先進(jìn)行前向傳播,將隱含層的輸出信息傳遞到邏輯回歸層,將所提取的最高級(jí)特征映射到相應(yīng)的標(biāo)記信息上,利用數(shù)據(jù)的標(biāo)記值對(duì)模型進(jìn)行有監(jiān)督訓(xùn)練,并不斷調(diào)整連接權(quán)值,減小模型的目標(biāo)預(yù)測(cè)標(biāo)記與實(shí)際標(biāo)記之間的概率誤差。
第三步:反向傳播,計(jì)算前向傳播過(guò)程中目標(biāo)預(yù)測(cè)標(biāo)記與實(shí)際標(biāo)記之間的概念誤差,并將該誤差從邏輯回歸層向隱含層傳播,并不斷調(diào)整隱含層參數(shù)θ=(W,b(i))。
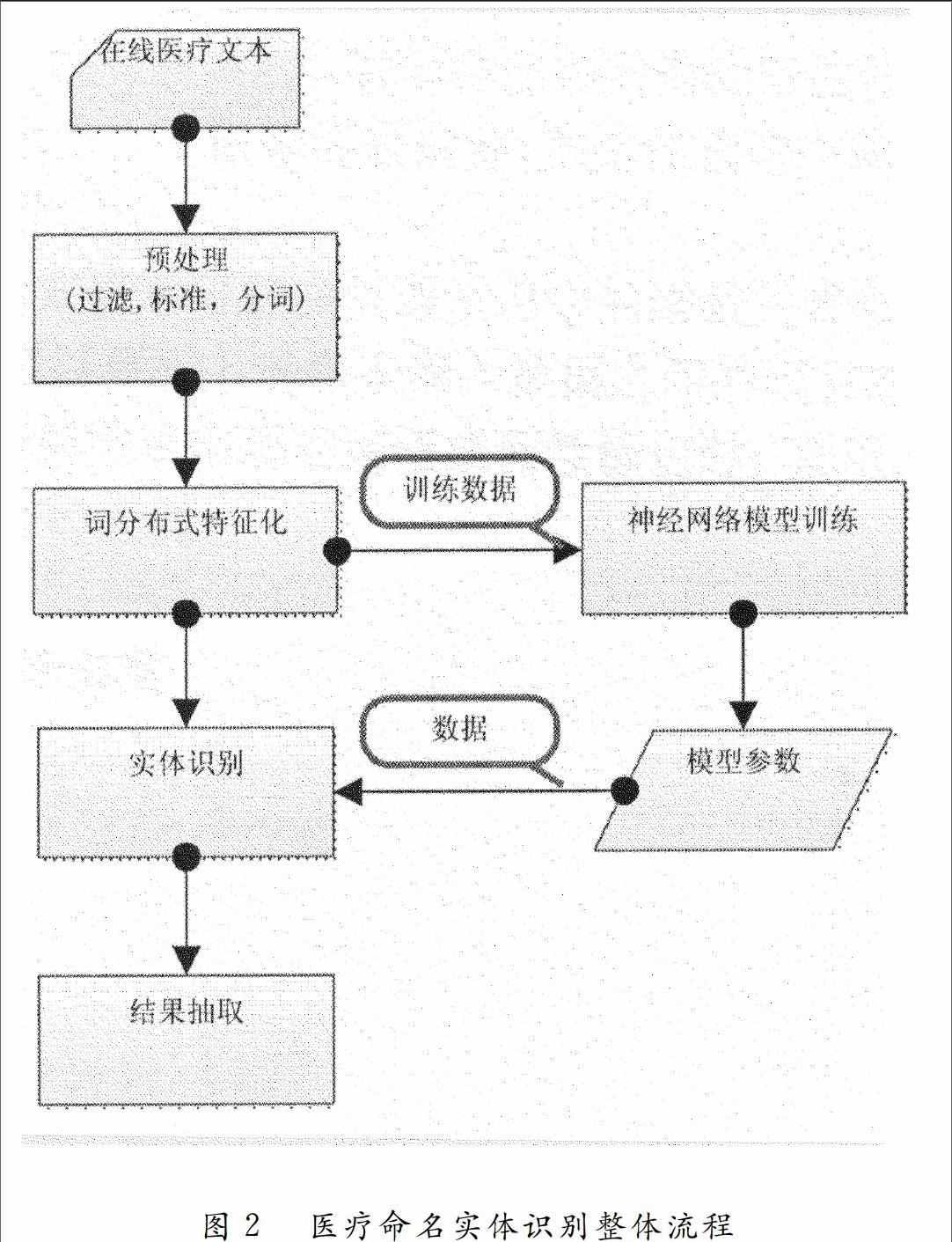
4醫(yī)療文本實(shí)體識(shí)別流程
針對(duì)在線醫(yī)療文本信息, 本文主要考慮了5 類(lèi)命名實(shí)體:疾病、癥狀、藥品、治療方法和檢查。具體實(shí)體識(shí)別流程如圖2 所示, 主要包括數(shù)據(jù)爬取、數(shù)據(jù)處理、數(shù)據(jù)處理、詞匯分布式特征訓(xùn)練、神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練、實(shí)體識(shí)別和識(shí)別結(jié)果抽取。首先爬取胃癌、糖尿病、哮喘、高血壓四種病相關(guān)醫(yī)療文本,對(duì)獲取的醫(yī)療文本進(jìn)行預(yù)處理, 包括特殊符號(hào)的過(guò)濾、人工標(biāo)注、分詞、大小寫(xiě)轉(zhuǎn)化等操作, 然后, 利用程序?qū)⑺袛?shù)據(jù)劃分為訓(xùn)練集和測(cè)試集兩部分。將訓(xùn)練集放到模型中進(jìn)行訓(xùn)練, 隨后再利用訓(xùn)練得到的參數(shù)測(cè)試模型識(shí)別效果。
5實(shí)驗(yàn)結(jié)果及分析
5.1實(shí)驗(yàn)條件
本文在Centos系統(tǒng)環(huán)境下用Java實(shí)現(xiàn)相關(guān)代碼,完成整個(gè)模型的構(gòu)建與訓(xùn)練。其中使用一款開(kāi)源工具包word2vec構(gòu)建神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型,word2vec是Tomas Mikolov在2013年開(kāi)開(kāi)發(fā)出來(lái)的工具包。word2vec使用CBOW模型(連續(xù)詞袋模型)[14-16]。CBOW模型是一種簡(jiǎn)化的NNLM模型,CBOW去掉了最耗時(shí)的非線性隱層、且所有詞共享隱層,可無(wú)監(jiān)督地訓(xùn)練出詞特征的分布式表示和詞性特征的分布式表示。為驗(yàn)證本文算法效果,本文通過(guò)設(shè)置2組對(duì)比實(shí)驗(yàn)進(jìn)行驗(yàn)證,兩組對(duì)比實(shí)驗(yàn)如下:
實(shí)驗(yàn)1通過(guò)觀察分析訓(xùn)練語(yǔ)料,手工構(gòu)建特征集。這些特征集有符號(hào)特征,詞性特征,形態(tài)特征,后綴特征,身體部位指示詞特征與上下文特征等。在訓(xùn)練語(yǔ)料上使用這些特征集訓(xùn)練條件隨機(jī)場(chǎng)模型,并利用得到的條件隨機(jī)場(chǎng)模型在測(cè)試語(yǔ)料上進(jìn)行命名實(shí)體識(shí)別,然后對(duì)識(shí)別結(jié)果進(jìn)行評(píng)估,將實(shí)驗(yàn)標(biāo)記為CRF。
實(shí)驗(yàn)2在訓(xùn)練語(yǔ)料上無(wú)監(jiān)督地學(xué)習(xí)出詞的分布式表達(dá)和詞性的分布式特征表達(dá),并利用詞的分布式表達(dá)和詞性的分布式表達(dá)構(gòu)建并訓(xùn)練3層網(wǎng)絡(luò)架構(gòu)。然后利用訓(xùn)練出來(lái)的深度神經(jīng)網(wǎng)絡(luò)在測(cè)試語(yǔ)料上進(jìn)行命名實(shí)體識(shí)別,且對(duì)識(shí)別結(jié)果進(jìn)行評(píng)估,將實(shí)驗(yàn)標(biāo)記為DBN。
5.2實(shí)驗(yàn)結(jié)果
本實(shí)驗(yàn)使用3個(gè)指標(biāo)來(lái)衡量命名實(shí)體識(shí)別的性能:正確率、召回率和F值。其計(jì)算公式如下:
正確率(P)=系統(tǒng)正確識(shí)別的實(shí)體個(gè)數(shù)系統(tǒng)識(shí)別的實(shí)體個(gè)數(shù)×100%(10)
召回率(P)=系統(tǒng)正確識(shí)別的實(shí)體個(gè)數(shù)文檔中實(shí)體個(gè)數(shù)×100%(11)
F-值=2×P×RP+R×100%(12)
6結(jié)論
本文通過(guò)神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型學(xué)習(xí)得到詞特征的分布式表達(dá)和詞性特征的分布式表達(dá)。并在詞分布式表達(dá)基礎(chǔ)上構(gòu)建出一種深層架構(gòu),將該深層架構(gòu)應(yīng)用于醫(yī)療命名實(shí)體識(shí)別任務(wù)。實(shí)驗(yàn)表明該方法可以自動(dòng)抽象出更高級(jí)特征,最大程度減少手工特征設(shè)計(jì)工作量。在醫(yī)療語(yǔ)料庫(kù)上進(jìn)行2組對(duì)比實(shí)驗(yàn),取得總體上88.03%的準(zhǔn)確率和82.34%的召回率,該實(shí)驗(yàn)結(jié)果表明該方法在命名實(shí)體識(shí)別任務(wù)中比條件隨機(jī)場(chǎng)模型效果更好。
參考文獻(xiàn)
[1]胡雙,陸濤,胡建華.文本挖掘技術(shù)在藥物研究中的應(yīng)用[J]. 醫(yī)學(xué)信息學(xué)雜志, 2013,(8):49-53.
[2]周昆. 基于規(guī)則的命名實(shí)體識(shí)別研究[D]. 合肥:合肥工業(yè)大學(xué), 2010
[3]闞琪. 基于條件隨機(jī)場(chǎng)的命名實(shí)體識(shí)別及實(shí)體關(guān)系識(shí)別的研究與應(yīng)用[D]. 北京:北京交通大學(xué), 2015.
[4]馮元勇,孫樂(lè),張大鯤,等. 基于小規(guī)模尾字特征的中文命名實(shí)體識(shí)別研究[J]. 電子學(xué)報(bào),2008,36(9): 1883-1838.
[5]鐘志農(nóng),劉方馳,吳燁,等. 主動(dòng)學(xué)習(xí)與自學(xué)習(xí)的中文命名實(shí)體識(shí)別[J]. 國(guó)防科技大學(xué)學(xué)報(bào),2014,4:82-88.
[6]懷寶興,寶騰飛,祝恒書(shū),等. 一種基于概率主題模型的命名實(shí)體鏈接方法[J]. 軟件學(xué)報(bào),2014,9: 2076-2087.
[7]HINTON G E,SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks [J].Science, 2006, 313(5786): 504-507.
[8]BENGIO Y, DUNCHARME R, VINCENT P,et al.A neural probabilistic language model [J]. The Journal of Machine Learning Research, 2003,3:1137-1155.
[9]MIKKOLOV T, KOMBRINK S, BURGET L,et al.Extensions of recurrent neural network language model[C] // 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) IEEE,2011: 5528-5331.
[10]COLLOBERT R, WESTON J, BOTTOU L,et al.Natural language processing (almost) from scratch[J]. The Journal of machine Learning Research, 2011, 12: 2493-2537.
[11]ZHENG Xiaoqing, CHEN Hanyang, XU Tiayu. Deep Learning for chinese Word segmentation and POS Tagging[C] //EMNLP. 2013: 647-657.
[12]JIANG Zhenchao,LI Lishuang,HUANG Degen.An Unsupervised Graph Based Continuous Word Representation Method for Biomedical Text Mining// IEEE/ACM Transactions on Computational Biology and Bioinformatics,2016, 13 :634-642.
[13]GANGIREDDY S R,SWIETOJANSKI P,BELL P,et al.Unsupervised Adaptation of Recurrent Neural Network Language Models// Interspeech, 2016, 9: 2016-1342
[14]MIKOLOV T,CHEN K, CORRADO G,et al.Efficient estimation of word representations in vector space [J]. Neural Computation,2014, 14: 1771-1800.
[15]MIKOLOV T, SUTSKKEVER I, CHEN K,et al.Distributed representations of words and phrases and their compositionality[C] // Advances in Neural information Processing Systems. 2013: 3111-3119.
[16]ALEXEYBORISOV T K,MAARTEN DE R S CBOW: Optimizing Word Embeddings for Sentence Representations[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. 2016: 10.18653/v1/P16-1089.
第36卷第1期2017年3月計(jì)算技術(shù)與自動(dòng)化Computing Technology and AutomationVol36,No1Mar. 2 0 1 7第36卷第1期2017年3月計(jì)算技術(shù)與自動(dòng)化Computing Technology and AutomationVol36,No1Mar. 2 0 1 7
猜你喜歡
西部交通科技(2021年9期)2021-01-11
速讀·下旬(2016年8期)2017-05-09
電子技術(shù)與軟件工程(2016年24期)2017-02-23
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21
現(xiàn)代情報(bào)(2016年10期)2016-12-15
新教育時(shí)代·教師版(2016年23期)2016-12-06
法制與社會(huì)(2016年32期)2016-12-01
軟件導(dǎo)刊(2016年9期)2016-11-07
軟件工程(2016年8期)2016-10-25
哈爾濱理工大學(xué)學(xué)報(bào)(2016年2期)2016-09-12
