結構體數據對齊方法的研究
2017-05-19 12:34:31王若
未來英才 2017年7期
王若
摘要:內存地址對齊,是一種在計算機內存中排列數據、訪問數據的一種方式。當今的計算機在計算機內存中讀寫數據時都是按字(word)大小塊來進行操作的。基本類型數據對齊就是數據在內存中的偏移地址必須等于一個字(word)的倍數,按這種存儲數據的方式,可以提升系統在讀取數據時的性能。有時候為了對齊數據,可能必須在上一個數據結束和下一個數據開始的地方插入一些沒有用處字節,這就是結構體數據對齊。
關鍵詞:結構;數據
一、假設計算機的字大小為4個字節,因此變量在內存中的首地址都是滿足4地址對齊,CPU只能對4的倍數的地址進行讀取,而每次能讀取4個字節大小的數據
假設有一個整型的數據a的首地址不是4的倍數,因此想讀取a的數據,CPU要進行兩次內存讀取,而且還要對兩次讀取的數據進行處理才能得到a的數據,而一個程序的瓶頸往往不是CPU的速度,而是取決于內存的帶寬,因為CPU得處理速度要遠大于從內存中讀取數據的速度,因此減少對內存空間的訪問是提高程序性能的關鍵[1]。從上例可以看出,采取內存地址對齊策略是提高程序性能的關鍵。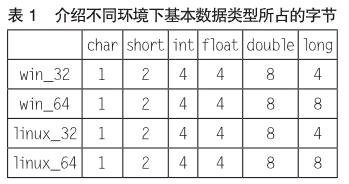
二、結構體默認的規則
本文所述的環境均是在32位編譯器的編譯環境中,一般編譯器默認對齊方式是4字節。
總結結構體的數據對齊方式滿足條件:
1、結構體變量的首地址能夠被其最寬基本類型成員的大小所整除。2、結構體每個成員相對于結構體首地址的偏移量(offset)都是成員自身大小的整數倍,如有需要編譯器會在成員之間加上填充字節。3、結構體的總大小為結構體最寬基本類型成員大小的整數倍,如有需要編譯器會在最末一個成員之后加上填充字節。
三、手動對齊方式
如果編譯器自動實現結構體對齊,我們就稱為自動對齊,與之相反,使用#pragma進行對齊的就是手動對齊。
#pragma備用告訴編譯器,程序員自己希望的對齊方式。比如,雖然編譯器的默認對齊方式是4,但是如果我們不希望按照4對齊,而是希望是8,這個時候就必須使用#pragma進行手動對齊了。
常用的設置手動對齊的命令有兩種:第一種是#pragmapack(),這種就是設置編譯器1字節對齊,不過也可以認為是設置為不對齊或者取消對齊;第二種是
#pragmapack(4),這個括號中的數字表示希望以多少字節進行對齊。
我們需要#prgamapack(n)開頭,以#pragmapack()結尾,定義一個區間,這個區間內的對齊參數就是n。
舉例說明
(一)自動對齊方式或者是默認4字節對齊
分析代碼:根據基本數據類型對齊規則可知,c(字節),i(4字節),d(8字節),b(2字節)。是不是結果就是1+4+8+2呢?很明顯不是,c是首元素,不需要對齊,但是后面的就需要對齊了,i是4字節,但是它的起始偏移量只有1字節,不能整除4,因此就在c后面再加3個字節,當遇到d時,由于之前的偏移量就是8,所以不需要偏移,在b之前有16字節,這時也不需要偏移就是直接加上2。所以最后結果就是1+3+4+8+2=20,對不對呢?其實是不對的,因為18不是默認對齊4的整數倍,還需要在后面補充2字節。一共就是20字節。
分析:該結果就是24字節,分析同上,但是在最后一步不一樣,對齊是8字節,所以在b后面還需要添加6字節。最終結果就是24.
四、結語
需要字節對齊的根本原因在于CPU訪問數據的效率問題。因為計算機可以處理數據位數都是確定的,這時候就說明它一次性只能處理確定位數的數據,但是當認為造成該數據不在計算機一次性可訪問的范圍內的時候,計算機就會按照一定的優化方法來處理,這樣是更加方便和快捷的處理數據。也就是強制的要求一來簡化了處理器與內存之間傳輸系統的設計,二來可以提升讀取數據的速度。
參考文獻
[1] 陳榮,蔡志勇,胡保安. 基于嵌入式操作系統VxWorks數據采集系統軟件設計[J]. 科技廣場,2005,(06):82-84.
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
小學科學(學生版)(2021年7期)2021-07-28 06:44:42
趣味(數學)(2020年9期)2020-06-09 05:35:08
科技傳播(2019年22期)2020-01-14 03:06:34
科技傳播(2019年22期)2020-01-14 03:06:30
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
消費導刊(2017年20期)2018-01-03 06:26:40
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現代企業(2015年9期)2015-02-28 18:56:50
