基于匹配跟蹤與特征值分解的模糊漢字圖像復(fù)原
2017-06-10 03:15:26楊漢秀
電子技術(shù)與軟件工程 2017年11期
關(guān)鍵詞:圖像復(fù)原
楊漢秀

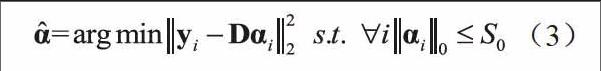
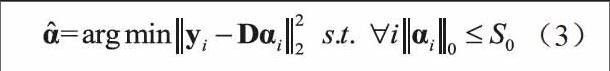
摘 要本文針對視覺不能辨識的模糊漢字圖像,提出了一種利用正交匹配跟蹤和特征值分解復(fù)原圖像的新方法。
【關(guān)鍵詞】匹配跟蹤 特征值分解 模糊漢字 圖像復(fù)原
我們在日常的圖像采集與傳輸過程中,因受各種干擾性因素的影響,常常會導(dǎo)致我們所采集或傳輸?shù)膱D像模糊,進而嚴(yán)重影響了對圖像的后續(xù)處理。對模糊漢字圖像進行復(fù)原具有重要的實用價值和社會意義。眾所周知,作為圖像中的特殊分類,模糊漢字圖像在具備圖像的一般特性外,還具有字符圖像的特有結(jié)構(gòu)特征。在針對模糊圖像尤其是字符類圖像的復(fù)原工作中,我們可以采取特征值分解K-SVD(K-Singular Value Decomposition)算法來對字符圖像加以復(fù)原與圖像改良。該算法能夠由圖像塊樣本準(zhǔn)確地表達(dá)出待處理字符圖像的結(jié)構(gòu)特征,有助于人眼正確辨識,具有更好的復(fù)原效果。
1 稀疏測量與匹配跟蹤重構(gòu)原理
在隨意建立的矩陣中,取線性空間Rm上的任意信號值x,以字典矩陣D中原子線性加以表述,得到
其中,ε為測量誤差。則在給定字典D下尋求最優(yōu)稀疏表出系數(shù)α的問題可表示為如下優(yōu)化方程:
2 特征值分解模糊漢字圖像復(fù)原
2.1 特征值分解原理
求解式(3)的另一個關(guān)鍵問題在于如何確定字典,Aharon和Elad等人提出了一種經(jīng)典的字典訓(xùn)練算法,即特征值分解算法K-SVD,以實現(xiàn)對式(3)中的字典D的求解。K-SVD通過對誤差項進行特征值分解,迭代更新字典D,最終找到能夠表示訓(xùn)練樣本信號的冗余字典。K-SVD算法的目標(biāo)函數(shù)可描述為:
求解式(4)是一個迭代過程,首先假設(shè)字典D是固定的,計算yi的表示系數(shù)αi:
求解此過程可由正交匹配跟蹤算法很好的解決。
2.2 漢字圖像復(fù)原模型
取尺寸為的漢字圖像X,此時若不做處理直接采用K-SVD算法,則存在字典尺寸過大、內(nèi)存溢出的問題。為了解決上述問題,同時考慮漢字圖像筆畫的局部連貫性,記Y為觀測到的模糊漢字圖像,則基于稀疏表示的模糊漢字圖像復(fù)原過程可由下式描述:
其中,λ表示懲罰系數(shù),用來約束模糊漢字圖像和復(fù)原漢字圖像的相似程度,式中后兩項是對圖像塊的稀疏約束。采用K-SVD方法訓(xùn)練得到冗余字典,并初始化X=Y,采用正交匹配追跟蹤OMP算法求解每個圖像塊的稀疏表示系數(shù):
求得每個圖像塊的稀疏表示系數(shù)后,即為復(fù)原的圖像塊,更新圖像X:
式(10)是一個二次項,相應(yīng)的解為:
3 實驗結(jié)果分析
選取20張不同程度模糊圖片進行分類復(fù)原實驗,通過不同程度高斯白噪聲條件下的復(fù)原實驗進行對比分析,復(fù)原PSNR指標(biāo)取均值后,實驗對比結(jié)果如表1所示。
此外,在同時給予不同噪聲方差的前提實驗條件下,通過10次重復(fù)性獨立實驗并取均值,得到不同復(fù)原方法的平均消耗時間Runtime數(shù)值,如表2所示。
綜上,由表1數(shù)值分析可以得到結(jié)論:在同等噪聲水平下,基于匹配跟蹤與特征值分解的模糊漢字圖像復(fù)原方法對模糊字符圖片的復(fù)原效果較為理想。此外有表2實驗分析結(jié)論可知:隨著噪聲方差的增大,該模糊漢字圖像復(fù)原方法所消耗時間呈下降趨勢,雖然時間消耗上并無明顯優(yōu)勢,但其對模糊字符圖片的復(fù)原效果大為提升,值得推廣。
4 結(jié)語
本文提出了一種基于匹配跟蹤和特征值分解的漢字圖像復(fù)原方法。該方法通過對漢字圖像塊進行多次迭代訓(xùn)練獲得具有更好結(jié)構(gòu)特征的冗余字典,結(jié)合稀疏測量對大尺度的模糊圖像分塊稀疏表示,并用匹配跟蹤重構(gòu)原理獲取去模糊的重構(gòu)圖像塊,最后對重構(gòu)圖像塊重疊區(qū)域加權(quán)平均以保持漢字圖像的細(xì)節(jié)特征并消除塊效應(yīng),實現(xiàn)對模糊文字圖像的復(fù)原。
參考文獻(xiàn)
[1]練秋生.基于圖像塊分類稀疏表示的超分辨率重構(gòu)算法[J].電子學(xué)報,2012(05).
[2]翟雪含.結(jié)合KSVD和分類稀疏表示的圖像壓縮感知[J].計算機工程與應(yīng)用,2015(06).
作者單位
四川外國語大學(xué)重慶南方翻譯學(xué)院 重慶市 401120
猜你喜歡
農(nóng)業(yè)工程學(xué)報(2022年14期)2022-10-19 02:34:26
石家莊鐵路職業(yè)技術(shù)學(xué)院學(xué)報(2019年3期)2019-10-30 03:26:32
大科技·C版(2019年1期)2019-09-10 14:45:17
數(shù)碼世界(2017年12期)2017-12-28 15:45:13
蘇州科技大學(xué)學(xué)報(自然科學(xué)版)(2017年1期)2017-03-20 15:25:20
科技資訊(2016年27期)2017-03-01 18:23:16
光學(xué)精密工程(2016年2期)2016-11-07 09:02:28
航天返回與遙感(2014年4期)2014-07-31 17:47:47
長江大學(xué)學(xué)報(自科版)(2014年7期)2014-03-20 13:21:02
電子設(shè)計工程(2014年18期)2014-02-27 12:00:32
