基于大數據技術的精準扶貧信息化平臺的研究與應用
2017-06-10 04:49:39章娟娟舒大鑫曹雅琴
赤峰學院學報·自然科學版 2017年9期
陳 琳,章娟娟,舒大鑫,曹雅琴,張 慶
(池州學院 數學與計算機學院,安徽 池州 247000)
基于大數據技術的精準扶貧信息化平臺的研究與應用
陳 琳,章娟娟,舒大鑫,曹雅琴,張 慶
(池州學院 數學與計算機學院,安徽 池州 247000)
基于大數據技術、預測建模分析技術搭建了精準扶貧信息化平臺,平臺通過建模工具,能夠對貧困戶進行行為預測,實現精準識別,防止脫貧戶返貧,同時為貧困戶和幫扶單位提供扶貧個性化推送和雙向選擇,實現與社會各種幫扶企業進行信息的共享,以及“脫貧攻堅”第三方檢測評估模塊,從而深入地推進大數據技術在精準扶貧過程中的應用.
精準識別;精準扶貧;大數據;扶貧信息化平臺;脫貧評估
1 大數據精準扶貧的研究動態
1.1 大數據精準扶貧的現實背景
貧困問題是我國“十三五”時期全面建成小康社會進程中需要解決的重大現實問題.習近平總書記在青海代表團表示“齊心協力打贏脫貧攻堅戰,確保到2020年現行標準下農村牧區貧困人口全部脫貧”.為了有效緩解并解決在扶貧工作中遇到的問題,以大數據為工具對貧困戶的信息、數據進行處理便顯得尤為重要.同時這也是推動扶貧工作治理規范化、科學化發展的重要方向.
1.2 大數據技術在精準扶貧中的使用概述
目前我國已經進入扶貧開發最關鍵的攻堅拔寨的沖刺期,大數據成為實施精準扶貧、精準脫貧的利器.根據安徽省政府的安排,本文研究團隊全程參與安徽省黃山市黟縣2016年年末脫貧攻堅第三方檢測評估,對貧困戶的相關信息、各級政府部門的扶貧政策有深刻的了解和認識,在此基礎上,研究基于大數據的精準扶貧信息化平臺,通過整合財政、教育、水利、就業、社保、林業、衛生、民政、殘聯、人行等相關數據,利用大數據技術提高數據處理能力和效率,深度挖掘數據的價值,為扶貧工作提供真實可靠、及時全面的決策數據,為最終實現精準扶貧和精準脫貧提供有力支撐.
2 精準扶貧信息化平臺的技術基礎
2.1 大數據技術
2.1.1 大數據技術優勢
大數據技術能夠快捷獲取數據隱藏信息,并進行分析處理,從而能夠有效節省成本.在精準扶貧工作中,通過大數據技術對龐大的貧困戶原始信息進行分析、可視化處理,挖掘出有價值信息為精準幫扶工作提供參考.
2.1.2 大數據技術簡介
大數據技術是針對數據采集,處理,可視化等方面的技術,在技術處理上主要采用Hadoop.Hadoop是使用海量數據存儲和計算的軟件框架,該框架采用分布式存儲和分布式計算技術,具有可靠、高效、可伸縮性特點.Hadoop框架包括數據存儲(HDFS)和數據計算(MapReduce).Hadoop表現在采用并行執行機制,具有高效性,并通過添加Zookeeper分布式鎖服務器,進行橫向的擴容,因此大大提高數據處理效率.
2.2 Hadoop框架的設計思想
Hadoop框架分為分布式文件系統HDFS、MapReduce處理過程[1].HDFS基于底層,上層為MapReduce引擎.HDFS對數據提供存儲,MapReduce對數據提供計算.框架最核心部分為HDFS和MapReduce的主從組件,其中名稱節點和數據節點來自HDFS,MapReduce引擎由JobTrackers和Task-Trackers組成.Hadoop包括數據倉庫工具和分布式數據庫Hbase,設計程序可訪問Hbase數據庫[2].
3 大數據精準扶貧信息化平臺的設計
本文將大數據技術應用于精準扶貧信息化平臺,該平臺采用MapReduce并行數據處理模型實現并行計算,同時利用建模工具對貧困戶相關數據進行可視化分析,預測其下一年度將會發生的行為,從而及時采取幫扶措施.平臺主要功能模塊為精準識別、精準幫扶、“脫貧攻堅”第三方檢測評估,平臺整體架構如圖1所示:

圖1 大數據精準扶貧信息化平臺
3.1 精準識別貧困戶
平臺將財政、教育、就業等方面的信息進行存儲,通過大數據技術并行計算,按照每戶年人均可支配年收入是否達到脫貧標準,家庭是否有因貧輟學學生,住房是否為危房等條件精準識別貧困戶.平臺識別的數據來源可以從兩個方面入手:一方面是由每個村對每個貧困戶的信息進行采集、甄別和錄入,最后進行層層核驗,同時要求各級對自己錄入核驗的數據負責.另一方面,則是要多維度對貧困戶信息進行準確跟蹤,綜合致貧原因、勞動力狀況、住房狀況、子女就學就業狀況、政府補貼狀況等指標,進一步做到大數據分析、精準識別.
3.2 精準幫扶
3.2.1 行為預測
將被動幫扶轉變為主動預測.為了提高幫扶效率,精準幫扶,將“處理問題”的思維方式轉向“預測問題”的前瞻性思維方式,利用大數據技術進行行為預測.
3.2.1.1 扶貧需求預測
通過大數據精準扶貧信息化平臺,著重理解貧困戶與幫扶人之間的交互行為[3],預測扶貧需求.以安徽省黃山市黟縣部分貧困戶為例,分析貧困戶脫貧的行為.
在扶貧的過程中,了解到貧困戶脫貧對于所需的資源都不盡相同.圖2反映的是貧苦戶的行為相關信息統計,針對行為特點可以進行行為的推測,其中工資收入(X1)、家庭經營收入(X2)、財產收入(X3)、轉移收入(X4)、生產經營支出(X5)、子女教育支出(X6)、醫療費用支出(X7).
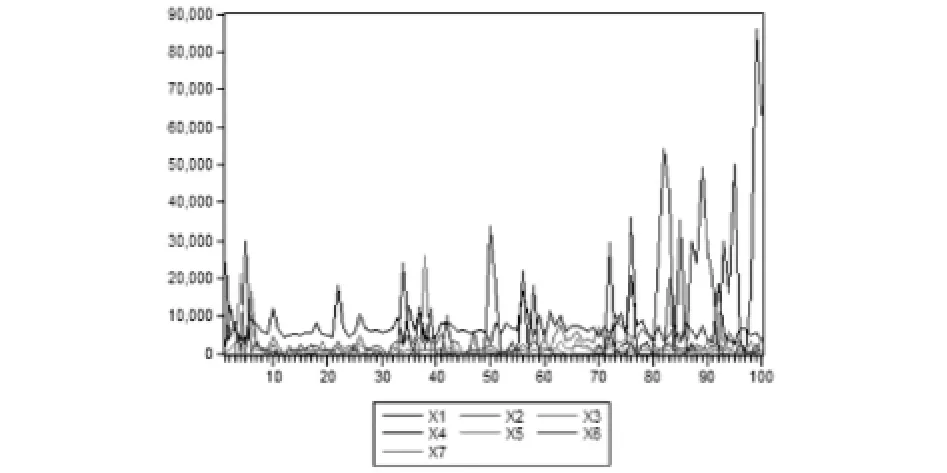
圖2 貧苦戶的行為相關信息統計圖
軟件分析的結果是,在這些貧困戶的行為中,以X4為經常性動作,X1為偶爾性動作,表明大多數的貧困戶最需要政府的社會補貼,部分貧困戶脫貧原因是由于自身勞動(導致行為的發生),根據預測,也可以得圖3,其為Y值與X1-X7回歸趨勢,表明X1集中趨勢最為明顯,故為了要達到脫貧的標準,需增加X1.平臺通過預測貧困戶的行為,關注其經常性動作,了解其扶貧需求.以此達到整體預測,精準扶貧的效果.
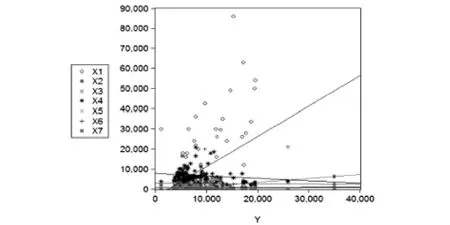
圖3 行為信息分析
3.2.1.2 脫貧返貧預測
平臺數據庫存儲海量的扶貧信息,通過關聯規律進行預測,防止脫貧戶再次返貧從而加重扶貧任務量.以安徽省為例,安徽省貧困戶人均純收入超過3100元的為脫貧戶.本文利用 Eviews7.0軟件對黟縣某一貧困戶脫貧期間(2013-2016年)的行為進行分析預測.輸出結果如圖4所示,R2統計量顯示值為0.975801,其擬合程度很高,且在顯著性水平0.5區間下,T統計量、F統計量的P值都極小,說明方程為顯著的,各項檢驗符合,可以進行預測,進而得出該戶2017年人均純收入5450元.同樣的對下一年2018年人均純收入進行推測為3950元,明顯在貧困戶標準線附近,此時平臺將處理此類信息,為幫扶人提供預先的幫扶措施,加大幫扶力度,針對拉低其Y值的方面進行有效的預防,防止該戶脫貧戶返貧.當預先采取精準幫扶措施時,能夠推測出2019年、2020年該戶人均純收入分別為5950元、6020元,已不再徘徊在貧困線附近,認為該脫貧戶已穩定脫貧.
據平臺行為預測,較好地解決了以往靜態、滯后的目標瞄準問題,同時對貧困戶的動態變化能夠準確掌握.
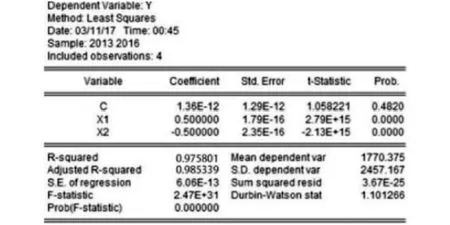
圖4 擬合值輸出
3.2.2 脫貧導向
在大數據精準扶貧信息化平臺中,系統分析模型板塊,利用預測處理,進行脫貧導向從而實現扶貧既“精”又“準”.根據扶貧需求搭建資源配置導向,讓每一份資源得到充分的利用,為貧困戶脫貧帶來指導.以黟縣某一貧困戶為例,根據其行為導向,在其醫療費用支出明顯又上升趨勢時,可以為其導向醫療資源,幫助其在費用上或報銷上的花費,保證其穩定的脫貧.又或是一貧困戶的工資性收入明顯有增高的趨勢,但金額漲幅不大,通過平臺,為其推送企業相關招工信息,達到貧困戶就業脫貧的目的.同樣的,根據返貧預測,平臺將及時采取處理方式,基于其已有的脫貧行為,對其進行個性化推薦幫扶措施,以此達到防止已經脫貧人員再次貧困、拉低脫貧效率、加重脫貧任務的目標.
大數據精準扶貧信息化平臺的搭建,通過對于貧困戶行為的動態分析[4],預測需求,精準定位資源配置方向,并有效的防止脫貧戶返貧,釋放大數據預測的真正潛能.
3.3“脫貧攻堅”第三方監測評估
為推進脫貧攻堅政策措施落實到位,確保脫貧成效真實可靠,以安徽省為例,根據《中共安徽省委安徽人民政府關于堅決打贏脫貧攻堅戰的決定》(皖發[2015]26號)精神,按照實現“四個全覆蓋”的要求,建立獨立、公正、規范的脫貧攻堅第三方監測評估機制,年中監測評估以脫貧攻堅政策措施落實情況為重點,年末監測評估以脫貧成效真實性為重點.
大數據精準扶貧信息化平臺對脫貧戶信息進行處理后,通過第三方監測評估模塊,由第三方監測評估人員將扶貧項目的流程完全透明于全體部門,對各地開展精準識別、精準施策、精準幫扶、精準脫貧情況進行調查核實、監測評估和分析研判.同時,也有利于查缺補漏、改進工作,便于客觀了解扶貧工作全局,更有助于總結經驗教訓.
4 大數據精準扶貧信息化平臺的創新應用策略
4.1 扶貧信息共享
國家層面也一直嘗試鼓勵民營企業和社會資本參與精準扶貧,通過大數據精準扶貧信息化平臺,不僅可以動態管理貧困戶的相關扶貧信息,而且與各民營企業進行數據實時共享.通過一定的分類,匹配出社會各組織幫扶有效資源,進行按近幫扶、按需幫扶.在緩解企業短時用工壓力的同時,還可以整合所在地區貧困戶的可利用勞動力.此外,電商企業可以上架并促銷貧困地區的農特產品,以達到消費扶貧的目的.同時通過大數據精準扶貧信息化平臺,可以將優秀的扶貧經驗分享至其他地區,促進精準扶貧工作的協同發展.
4.2 幫扶的雙向選擇
因病致貧,因病返貧是貧困群眾最主要的致貧原因之一,健康扶貧對于整個脫貧攻堅戰有著重要的作用.大數據精準扶貧信息化平臺能為貧困戶提供準確的醫療信息.將各類醫院分別錄入平臺,貧困戶可以根據自己的病情選擇合適的醫院,尋求幫助.醫院也可以通過平臺,根據自己的醫療優勢選擇貧困戶進行幫扶.
教育在促進扶貧、防止返貧方面的作用,可說是根本性的、可持續的[5].可將學校分為幼兒園、小學、中學、大學、特教學校等錄入大數據精準扶貧信息化平臺.貧困戶按照自己所需要的學校進行選擇,找到離家最近的學校.學校也可在平臺找到自己適合幫扶的貧困地區,進行對口教學.
中小型企業所需的勞動力按照年齡、性別、文化程度、健康狀況、所在地、專業等錄入大數據精準扶貧信息化平臺.貧困戶可以通過平臺篩選適合自己的工作,企業也可根據自己的需要選擇相應的勞動力,達到雙向選擇的目的.
4.3 幫扶信息個性化推送
4.3.1 個性化推送模塊的構建
大數據精準扶貧信息平臺將通過個性化推薦來實現精準化扶貧.對平臺上采集來的數據信息進行分析之后,基于對貧困戶行為的分析,再設計個性化的推送服務,向貧困戶推送所需的就業、醫療、教育等信息.個性化推薦模塊的總體目標,根據貧困戶最新的行為信息,提供對貧困戶信息的分析和處理服務,包括詞頻統計分析、信息調用、地域要求等,最后為貧困戶推薦他們極其需要的信息.
4.3.2 學習與跟蹤貧困戶各方面信息
個性化推送模塊中的功能,如果要達到個性化服務的要求,首要的問題就是對貧困戶信息的了解與獲取.一方面要加強與貧困戶的交互,另一方面是構造貧困戶興趣模型和個性化推薦算法.
大數據精準扶貧信息平臺個性化推送模塊主要包括以下三個層次:
4.3.2.1 數據層
通過平臺將貧困戶與數據相關聯,根據他們的致貧原因再將貧困戶之間相互區分開來.通過建立貧困戶的數據中心,將每個貧困戶的日常生活習慣,身體特征,性別年齡,知識能力,愛好性情等進行記錄.也就是將除了思維外的一切信息都儲存下來,并將這些數據帶入分析層進行分析處理. 4.3.2.2 分析層
通過平臺將貧困戶的特征匹配等相關的邏輯運算,將貧困戶和信息做關聯,篩選更適合的數據.將信息資源集中整合起來,把無序的數據變為有序的數據,即把離散的數據整理成可以為貧困戶服務的數據,使之方便貧困戶查找信息,同時提高所提供信息的準確性,節省時間,提高效率.
4.3.2.3 推送層
構建個性化推送與貧困戶交互的通道.將能夠幫助貧困戶的企業名稱、幫扶機構、等方面進行推送,該方面將直接影響到個性化推送的利用率,影響著推送的效果.本層是基于與用戶的優良互動性,通過主動分析貧困戶行為信息來推送信息.同時,也需要對社會各層構建個性化模塊,分析出企業、機構和個人所需的勞動力類型,需要的貧困戶年齡,幫扶條件是否滿足,進而為他們個性化推送滿足條件的貧困戶.
這樣的個性化推送模塊通常可以在比較恰當的時機捕獲到貧困戶最需要的信息,能夠讓貧困戶切身體會到個性化推送模塊的優點.同時也大力度的提高扶貧的精準度,真正的讓用戶集成的大數據知識為精準扶貧做出最大的貢獻.
5 結束語
精準扶貧的工作,關系到中國成千上萬貧困戶的生活和福利,影響著社會主義建設進程.正如習總書記強調的一樣:扶貧開發工作已進入“啃硬骨頭、攻堅拔寨”的沖刺時期.在這不到3年的時間,要確保所有貧困戶全部如期脫貧,可以在精準扶貧上進一步利用大數據技術,完善整個扶貧體系,促進精準扶貧工作的協同發展,實現偉大中國夢!
〔1〕廖峰.大數據環境下Hadoop分布式系統研究與設計.
〔2〕VigneshPrajapati著,李明等譯.R與Hadoop大數據分析實戰.
〔3〕蔣卓軒.基于MOOC數據的學習行為分析與預測.計算機研究與發展,2015(3).
〔4〕莫光輝.大數據在精準扶貧過程中的應用及實踐創新.求實,2016(10).
〔5〕劉傳鐵.教育是最根本的精準扶貧.人民日報,2016-01-27(05).
TP391
A
1673-260X(2017)05-0018-03
2017-01-04
猜你喜歡
中小學信息技術教育(2021年8期)2021-09-10 17:59:45
中小學信息技術教育(2021年4期)2021-06-06 04:36:26
甘肅教育(2020年18期)2020-10-28 09:06:02
活力(2019年21期)2019-04-01 12:16:40
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
中國衛生(2014年1期)2014-11-12 13:16:34
江蘇年鑒(2014年0期)2014-03-11 17:09:40
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
