基于Hadoop的大數據解決方案的設計及應用
2017-06-22 14:41:54蘇樹鵬
河池學院學報 2017年2期
蘇樹鵬
(廣西機電職業技術學院,廣西 南寧 530007)
基于Hadoop的大數據解決方案的設計及應用
蘇樹鵬
(廣西機電職業技術學院,廣西 南寧 530007)
隨著信息化技術和終端智能的迅猛發展,系統需要處理的數據呈現海量化,使得海量數據的存儲、挖掘成為當前亟待解決的問題。使用云計算技術構建集群系統,可有效地解決海量數據的存儲、共享和深度挖掘問題。首先,采用平臺Hadoop構建主框架,并采用異構存儲的方式將各部門的業務數據轉儲到集群系統各節點上存儲,有效地解決了大數據的存儲和備份問題。最后借鑒Hive和Hbase優點設計數據挖掘子系統,提高了集群系統對海量數據的分析能力。實時性分析實驗結果表明此次采用的方法較之以往的方法再獲得了30%的提升。
Hadoop;Hbase;Hive
0 引言
隨著物聯網和智能終端技術的廣泛應用,數字世界產生了6ZB的數據,其中95%屬于非結構化數據,且總量飛速增長。系統在處理大數據過程中面臨真正的難題是大數據的存儲、高速處理和系統及時響應。為了解決大數據帶來的難題,柏林工業大學博士后Mikio L.Braun[1]提出了大數據解決方案:通過可動態伸縮并無限擴展對大數據進行可靠存儲管理,運用知識計算等大數據分析技術挖掘大數據潛在價值的信息,但該方案還未解決實時大數據遷移等問題。本文在推進信息化智能化數字校園建設背景下,針對存在校園網平臺中的各系統處理和存儲的數據類型呈現多樣化、異構性等問題,而導致無法實時存儲和高效處理的大數據,利用大數據思想和云計算技術構建智能化數字校園平臺。先對校園各個系統平臺處理的信息生命周期分析,構建云計算架構的大數據解決方案,通過設計數據遷移子系統,解決實時將各個服務器中的數據遷移到集群系統中進行統一存儲管理問題,實現校園海量數據共享。通過設計數據分析挖掘系統,解決數據深度挖掘、智能數據分析等問題,為處理大數據提供新的解決方案。
1 系統平臺架構技術介紹
目前進行云計算研究與大數據處理的較為主流的平臺有由Apache公司研發的Hadoop[2-3]系統,其把復雜的作業經過算法優化進行合理切分成若干子作業,然后將子作業分配到具有所需數據的若干節點進行并行MapReduce計算,節點間沒有依賴性且可以根據運行狀況進行調度,提高處理速度和效率。平臺進行并行處理時,需要位于平臺底層分布式存儲系統中眾多節點存儲的數據和節點具體操作,眾多節點中有唯一的主節點控制其他節點的協同操作和存儲信息。HBase[4-6]是利用Hadoop系統另一核心HDFS作為存儲基礎,具備存儲海量非關系數據庫,作為眾多節點進行并行計算任務的輸入和輸出。Hive[7]是采用類似SQL語言對數據進行管理的數據倉庫工具,把經過解析和編譯的HiveQL命令交給Hadoop平臺中各個子節點的MapReduce并行執行。利用Hbase與Hive兩者的API接口進行通信建立關聯,對Hbase提供的用鍵值存儲數據進行快速的索引查找。
2 基于Hadoop的大數據解決方案
2.1 方案系統需求分析
大數據解決方案系統主要分為兩個子系統:數據遷移子系統和數據分析挖掘子系統。數據遷移子系統把各個在線業務平臺服務器的數據實時遷移到海量數據庫中,解決大數據的存儲、備份和共享問題;數據分析挖掘子系統利用系統集群并行對大數據進行快速分析處理,生成有價值的報告。
2.2 系統架構設計
系統架構圖如下圖1所示。
本文設計的大數據解決方案系統基于Hadoop平臺的集群,以面向列存儲的HBase作為海量數據存儲數據庫。數據遷移子系統通過基于網絡的存儲虛擬化整合網絡異構,規避和減少宕機,保證在線數據遷移時不需間斷業務,遷移后由HBase對大數據進行高效管理。數據分析挖掘子系統則基于密集型離線數據分析,通過建立Hive和HBase無縫連接,Hive提供類似SQL查詢,經過系統平臺編譯HQL,生成執行計劃,交由MapReduce對HBase管理的數據進行高效地并行計算,把深度挖掘到有價值的結果反饋給用戶。
(1)數據遷移子系統拓撲圖如圖2所示。
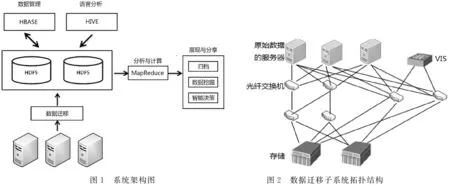
該拓撲圖采用臨時存儲網絡,解決在遷移過程中不需要中斷業務,且可以控制業務的遷移速度問題,同時可以降低因網絡環境問題對其他業務系統的影響。
(2)數據遷移子系統架構圖圖3所示

圖3 數據遷移系統架構圖
遷移功能的主要流程:
①各服務器原始數據:基于校園平臺中的各系統在應用過程中產生種類繁多且海量化數據,如何將各個服務器上的海量數據安全、快速地遷移入分布式HDFS,集群系統中的IO性能起著決定性作用,通過實時分析IO讀寫速度和網絡資源狀況,把任務分配給IO負載較輕的節點,實現高效的從客戶端將數據導入服務器的HDFS系統。
②系統Job:根據系統集群并行處理的需求,編寫代碼生產并行操作的Map/Reduce架包,當在運行Map和Reduce時生成一個作業Job實例,設計好Map方法讀取數據的路徑和格式。
③數據解析轉換:運行在MapReduce架構中的Job,讀取指定路徑中的HDFS中的文件,并在Map方法中將數據生成指定的格式。
④通過ZooKeeper在META.表查找存儲大數據的RegionServer,通過運行系統jar生成Put對象,使用該對象的add()方法將客戶端的數據映射到數據庫中對應的列,最后將數據通過Write方法遷移入指定的HBase數據表。
(3)數據分析挖掘子系統架構如圖4所示。

圖4 挖掘子系統架構圖
數據分析模塊的主要流程:
①Hive與HBase集成:Hive和Hbase兩個框架通過HBaseStorageHandler架包實現無縫接口整合,在Hive建立的表自動獲取與其建立通信的Hbase中的對應的表名、列簇和輸入輸出格式等信息。
②數據表映射:運行HQL命令創建Hive的外表,該外表和Hbase的表映射,通過配置信息映射由HBase到Hive,確保HBase和Hive兩者之間列和數據類型的一致性。
③HBase表切分:根據數據表對應的HRegion,將Region作為InputSplit單位,根據拆分數量交給等量的Map操作。
④查詢分析統計:用戶在系統平臺中使用Hive提供的組件,根據業務需求進行編譯、提交HQL命令,然后編譯器對HiveQL命令進行解析,優化,最后系統生成Hadoop的MapReduce任務,通過構建Scanner對HBase表數據進行掃描,對條件進行過濾、排序、去重,最后通過next()獲取數據,并且把數據生產表格、圖表等形式交付給用戶。
3 系統負載均衡
集群系統吞吐量和數據處理能力需要負載均衡,在集群各設備中合理分配業務量,確保集群中設備協同完成作業,步驟如下圖5:

圖5 負載均衡步驟
①集群系統狀態初始化:存儲系統中的各個Region服務器在規定的時間間隔內把自身的負載狀況向master匯報,并通過master獲取集群的分配情況且存入數據表Map中,存儲方式采用鍵值對,設置好Region服務器的負載度以及Memstore內存大小等等。
②計算系統是否平衡:先計算系統集群中負載平均值:float average=region數/server數;再求集群負載最小值floor和最大值ceil,通過遍歷Map中的Value,如果Value的最小值大于floor,并且最大值小于ceil,則不需要進行負載均衡,反之則需要。
③計算開銷:當需要平衡時,首先根據集群分配表生成一個虛擬的集群clusterP,其中clusterState是表的狀態,loads是整個集群的狀態:Cluster clusterP=new Cluster(clusterState,loads,regionFinder);通過對集群中各服務器計算cost的加權平均和計算實現開銷重心,然后循環MaxSteps次,用選號器從集群當中隨機選出
④數據移動:根據平衡方案List
4 系統運行效果分析
為了測試大數據解決方案的數據分析挖掘子系統性能,實驗中采用了5組不同的數據進行測試。本次實驗的重點在于負載均衡方案下評估系統集群協同處理作業的耗時測試,集群的每個節點的配置一樣且沒有失效問題。實驗環境:系統集群由1臺做NameNode,JobTracker,另外5臺做DataNode,Task-Tracker。服務器運行用centos操作系統,并安裝hadoop-1.0.3,hive-0.9.0,hbase-0.94.2,zookeeper-3.3.5。
實驗內容:在實驗中的數據都來自存儲在具有唯一主鍵的HBase數據庫中,集群通過系統負載均衡方案優化,再根據優化結果向各節點發送數據,然后在各節點中并發處理數據,最后統計發送和處理數據總耗時,為了表明本文所提系統集成之后經過系統均衡方案算法的有效性,如表1所示。

表1 數據耗時對比
通過表1的實驗數據可以看出,本文所提出在Hadoop平臺上集成Hive和HBase,通過本文設計的系統均衡方案,處理相同容量的數據性能平均提高了30%,表明本文算法的可行性,所以在以Hadoop為平臺的集群中,Hive+Hbase數據處理時,通過優化Hbase能發揮其海量處理的優勢,且隨著處理數據量的增大優勢更明顯。本方案與Hadoop+Hive架構方案最大的不同包含以下兩方面:
一是數據存儲方式不同。兩種方案都是采用Master/slaves架構,Hadoop+Hive架構方案中的HDFS會把大文件分割成很多小文件來存儲,保證大數據存儲完整性和安全性,并且Hadoop記錄每一個數據塊在存儲架構中的位置,在Map/Reduce處理作業時,通過就近原則進行任務分配,從執行任務的Task機器上讀取最近的數據塊,減少了數據傳輸和讀取的時間開銷。本方案的數據由HBase管理,為了解決HBase會隨機分配數據無法存儲在本地機器的難題,在少重啟系統的條件下,每臺機器都裝Hadoop和HBase,確保每個RegionServer都有DataNode,這樣RegionServer具備了從本地機器讀取數據的條件,且在測試系統過程中發現數據的存儲地點更穩定。
二是讀取數據效率不同。Hadoop+Hive架構方案讀取數據提交給HiveQL,并通過編譯交給Map/Reduce同時對HDFS存儲的數據進行處理。本方案設計系統負載均衡算法,使MasterServer分配Region更合理,確保每個Region被分配給擁有最多RegionBlock的RegionServer。HBase是低延遲,所以通過Hive集成HBase,使MapReduce執行效率得到最優化。
5 總結
基于Hadoop平臺系統集群通過協同作業是解決大數據方案之一,系統集群中存在備份數據困難、負載不均衡導致JobTracker的負載過大,系統集群性能遇到瓶頸。本文提出了基于Hadoop大數據解決方案,通過設計數據遷子系統,實現了實時數據遷移功能,解決了海量數據備份問題;利用Hadoop平臺構建系統集群,使用HBase實現實時存儲數據和高效檢索,通過負載均衡方案,使得系統集群中的每個JobTracker實現高效處理海量數據,大大提高了處理海量數據速度和挖掘效率。
[1]朱珠.基于Hadoop的海量數據處理模型研究和應用[J].北京郵電大學學報,2008,11(2):100-102.
[2]周霞.基于云計算的太陽風大數據挖掘分類算法的研究[J].成都理工大學學報,2014,10(5):50-52.
[3]劉士佳.基于MapReduce框架的頻繁項集挖掘算法研究[J].哈爾濱理工大學學報,2015,12(2):70-73.
[4]曾大耽,周傲英.Hadoop權威指南[M].北京:清華大學出版社,2010:12-15.
[5]范建華.TCP/IP協議詳解[M].北京:機械工業出版社,2012.
[6]劉鵬.實戰Hadoop開啟通向云計算的捷徑[M].北京:電子工業出版社,2011.
[7]易見.Hadoop開發者[M].北京:清華大學出版社,2010.
[責任編輯 韋志巧]
The Design and Application of Big Data Solution Based on Hadoop
SU Shupeng
(Guangxi Technologial College of Machinery and Electricity,Nanning, Guangxi 530007, China)
With the rapid development of information and intelligent terminal technology, the data needed to be processed has grown enormously.How to store and mine the massive data become more essential at present.This article solves the problem of massive data storing,sharing and mining by building cluster system on thebasis of cloud computing technology.First of all,this paper construct a framework with Hadoop platform.then transfer business data to nodes of cluster system in heterogeneous storage mode,finally,with reference to the advantage of Hive and Hbase. a data mining subsystem is designed,that enhance the massive data analytical ability of cluster system.The result of real-time analysis shows that the solution of this article raise 30% in efficiency,which has high practical and reference value
Hadoop; Hbase; Hive
TP31
A
1672-9021(2017)02-0089-05
蘇樹鵬(1980-),男,廣西南寧人,廣西機電職業技術學院講師,碩士,主要研究方向:云計算和軟件設計。
2016年度廣西高校中青年教師基礎能力提升項目“基于云計算和物聯網的智能校園的研究與設計”(KY2016YB650)。
2016-12-25
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
儀器儀表用戶(2022年4期)2022-04-01 03:17:14
閱讀與作文(英語初中版)(2021年8期)2021-09-13 02:16:29
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
數字通信世界(2015年10期)2015-12-21 12:22:54
母子健康(2015年1期)2015-02-28 11:21:44
