CPU計算和GPU計算
2017-06-27 08:07:07李旻昊
中國科技縱橫 2017年9期
關鍵詞:大數據
李旻昊
摘 要:本文先介紹了CPU和GPU的相關知識,包括他們的歷史、架構、以及目前發展的現狀。然后來闡述兩者在使用上的區別以及使用場景的不同。最后也是本文的重點,講述如何使用GPU來加快程序的運算速度,尤其是在大數據的處理這一方面,并且介紹NVIDIA公司所推出的CUDA運算平臺。
關鍵詞:CPU;GPU;大數據
中圖分類號:TP338 文獻標識碼:A 文章編號:1671-2064(2017)09-0029-02
CPU與GPU是每一臺電腦中都必不可少的部件。簡單來說,CPU就是一臺電腦中的“大腦”,能夠協調電腦中各個部件的運作。相比之下,GPU就顯得低調了很多。它處于顯卡之中,是顯卡的“心臟”,并且在以往的概念中,GPU并沒有CPU那般地位重要。
CPU和GPU都遵循著摩爾定律,即當價格不變時,集成電路上可以容納的元器件的數目,約每隔18-24個月便會增加一倍,性能也將會增加一遍。我們不可否認的是,即使科技不斷的進步,可以容納的元器件的數目也會有一個上限。這時,我們會用何種方式來提高性能呢?科學家們不停的探索這一方面的內容,給出的答案的其中之一就是使用GPU編程。如何利用GPU來編程?它和CPU的區別在哪里?它適用于怎么樣的程序?能提高的性能有多少?這四個問題就是本文想要闡述的。下面就讓我們一起進入電子元器件的世界。
1 CPU(中央處理器)
下面先介紹一下CPU(中央處理器)相關的知識。包括指令集,物理結構,流水線架構,以及目前CPU發展的六個階段。
1.1 指令集
我們日常使用電腦的過程中可能會思考下面的一個問題:為什么我雙擊了桌面上的一個圖標,程序就開始運行了?你也可能已經猜到了答案:我們向電腦發出了一條命令。這條命令是什么,誰處理這條命令,這個問題就是我們這一節要弄明白的問題。
當我們雙擊了圖標之后,就向計算機發出了一條命令。這條命令被CPU所接受,然后CPU開始解析這條命令并且向計算機其他部件發出信號,包括從硬盤取出相應的程序,放到內存中運行。這就是一條指令帶給計算機的工作。如果還不能夠理解,也沒有關系,只需要知道我們給計算機發出的命令都可以轉換成指令的形式就足夠了。
當然,計算機能夠接受的指令有很多很多,總體來說分成兩大類:復雜指令集和精簡指令集。
復雜指令集也稱CISC。在CISC微處理器中,指令是按照順序來執行的,其優點就是控制簡單,但是因為只能夠順序執行,因此它的運行速度不盡如人意。我們現在使用的所有的Intel處理器都是CISC,也就是x86和x86-64架構的。
精簡指令集稱作RISC。John Cocke對CISC機進行研究之后發現,程序中出現頻率達到80%的指令只占指令集中所有指令的20%(這也是著名的28定律)。復雜的指令系統會增加微處理器的復雜頂,導致計算機運行的速度降低。因此RISC誕生了,它的指令格式統一,種類比較少,尋址方式也簡單了很多,自然處理速度也有了提高。目前在高檔的服務器中都采用了RISC指令集。
1.2 物理結構
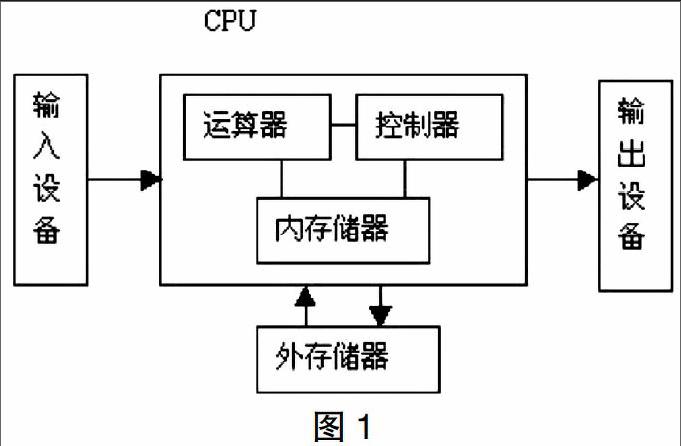
計算機之父馮·諾依曼曾經提出過存儲程序原理,把程序本身當作數據來對待,程序和該程序處理的數據用同樣的方式存儲。大致的思想如圖1所示。
可以看到,運算器、控制器和內存儲器是被放在CPU之中的,這也是目前CPU的物理結構。運算器也稱做運算邏輯部件,可以執行各種算術運算操作和邏輯操作。內存儲器包括寄存器和CPU緩存,用來保存指令執行過程中臨時存放的寄存器操作數和中間操作結果。控制部件主要是對指令進行翻譯,并且發出為完成每條指令所要執行的各個操作的控制信號。
在CPU中,上述三個部件是必不可少的。當然隨著技術的發展,目前CPU還有很多其他的部件,感興趣的讀者可以自行搜索相關資料。
1.3 流水線架構
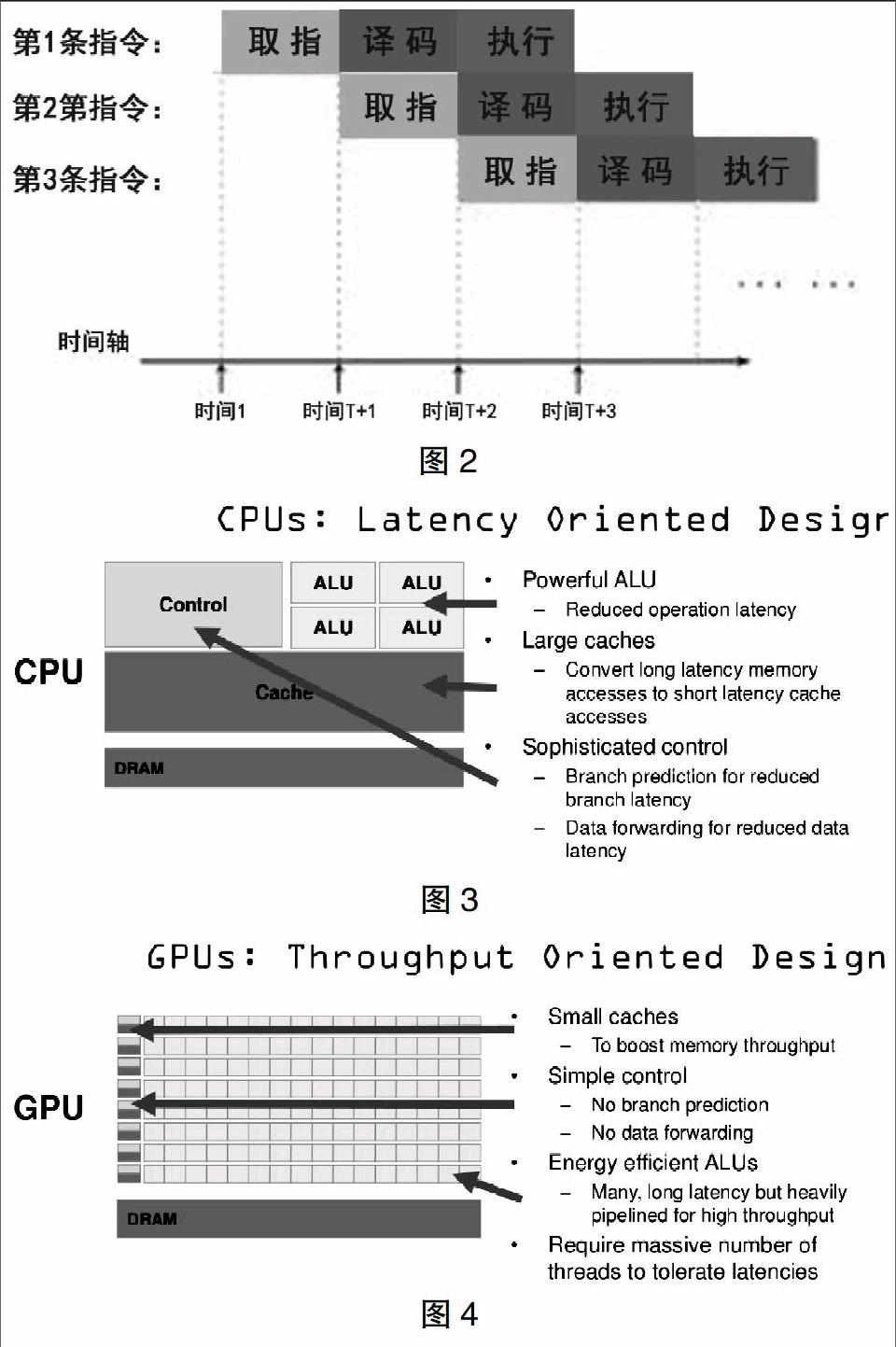
在說流水線架構之前,我們需要先弄清楚CPU的工作流程。CPU從存儲器中取出指令,放入指令寄存器,并且進行譯碼。然后發出各種控制命令,執行微操作,從而完成一條指令的執行。詳細來說,主要分成下述四個步驟:
(1)提取。用程序計數器來指定存儲器的位置,然后從存儲器中檢索指令。
(2)解碼。根據我們提取到的指令來決定其執行行為。根據CPU的指令集,指令會被拆解成有意義的片段。
(3)執行。我們根據相應的指令片段,來鏈接到各種CPU運算部件,進行相應的操作。
(4)寫回。最終,我們將在執行階段得到的結果簡單的寫回。通常他會被寫進CPU內部的寄存器中,也有可能會被寫進速度較慢但是容量較大的內存中。這時,一條指令已經完成,程序計數器值會遞增,來提取下一條指令并且重復上述的過程。
這就是CPU的工作流程。在流水線架構誕生之前,我們的指令都是一條完成后再接著另一條的,這樣做效率就會很低,因為并不是所有部件都無時無刻的在工作。比如,在執行階段,指令存儲器就沒有辦法很好的利用起來。為了解決這樣的問題,流水線架構誕生了。簡單來說,就是能夠充分利用每一個部件。在第n條指令解碼的時候,我們可以提前提取第n+1條指令。然后在第n條指令執行之時,CPU會去對第n+1條指令進行解碼。詳細的流程如圖2所示。
有了流水線架構,CPU的工作效率大大提高。
1.4 發展的六個階段
CPU發展已經有40多年的歷史了。我們通常將其分成六個階段。
(1)第一階段(1971年-1973年)。這是4位和8位低檔微處理器時代,代表產品是Intel4004處理器。
(2)第二階段(1974年-1977年)。這是8位中高檔微處理器時代,代表產品是Intel8080。此時指令系統已經比較完善了。
(3)第三階段(1978年-1984年)。這是16位微處理器的時代,代表產品是Intel8086。相對而言已經比較成熟了。
(4)第四階段(1985年-1992年)。這是32位微處理器時代,代表產品是Intel80386。已經可以勝任多任務、多用戶的作業。
(5)第五階段(1993年-2005年)。這是奔騰系列微處理器的時代。
(6)第六階段(2005年至今)。是酷睿系列微處理器的時代,這是一款領先節能的新型微架構,設計的出發點是提供卓然出眾的性能和能效。
2 GPU(圖像處理器)
讀完了CPU的介紹,現在我們來簡單介紹一下GPU。因為CPU和GPU的工作流程和物理結構大致是類似的,因此這里不再重復了。我們僅僅介紹一下GPU的功能和目前主流的供應商。
相比于CPU而言,GPU的工作更為單一。在大多數的個人計算機中,GPU僅僅是用來繪制圖像的。如果CPU想畫一個二維圖形,只需要發個指令給GPU,GPU就可以迅速計算出該圖形的所有像素,并且在顯示器上指定位置畫出相應的圖形。
由于GPU會產生大量的熱量,所以通常顯卡上都會有獨立的散熱裝置。
除此之外,GPU的供應商比CPU供應商更多一些。主流的供應商有:
(1)Intel,基本都為集成顯卡。
(2)Nvidia,也就是我們常說的N卡,在運算速度上有較大的優勢。
(3)AMD(ATI),我們常說的A卡,通常在圖形渲染上做的比N卡好。
(4)其他廠商,包括3dfx,Matrox,SiS和VIA。這些都是相對比較小眾的公司。
3 CPU和GPU的比較
現在,我們來比較一下CPU和GPU。看看他們各自在哪些領域能夠發揮出自己的作用。我們從兩個角度入手:設計結構和使用場景。
3.1 設計結構
我們先從CPU開始說起。CPU有強大的算術運算單元,可以在很少的時鐘周期內完成算術計算。同時,有很大的緩存可以保存很多數據在里面。此外,還有復雜的邏輯控制單元,當程序有多個分支的時候,通過提供分支預測的能力來降低延時。具體的結構如圖3所示。
下面我們來討論GPU的設計結構。GPU是基于大的吞吐量設計,有很多的算術運算單元和很少的緩存。同時GPU支持大量的線程同時運行,如果他們需要訪問同一個數據,緩存會合并這些訪問,自然會帶來延時的問題。盡管有延時,但是因為其算術運算單元的數量龐大,因此能夠達到一個非常大的吞吐量的效果。如圖4所示。
3.2 使用場景
顯然,因為CPU有大量的緩存和復雜的邏輯控制單元,因此它非常擅長邏輯控制、串行的運算。相比較而言,GPU因為有大量的算術運算單元,因此可以同時執行大量的計算工作,它所擅長的是大規模的并發計算,計算量大但是沒有什么技術含量,而且要重復很多次。
這樣一說,我們利用GPU來提高程序運算速度的方法就顯而易見了。我們使用CPU來做復雜的邏輯控制,用GPU來做簡單但是量大的算術運算,就能夠大大地提高程序的運行速度。下面我們來介紹一下Nvidia所推出的CUDA運算平臺。
4 CUDA
CPU程序員的挑戰不只是在GPU上獲得出色的性能,還要協調系統處理器與GPU上的計算調度、系統存儲器和GPU存儲器之間的數據傳輸。為了解決這樣的問題,Nvidia決定開發一種與C類似的語言和編程環境,通過克服多種并行帶來的挑戰來提高GPU程序員的生產效率。這個系統的名稱為CUDA,表示“計算統一設備體系結構”。
在CUDA中,這些并行形式的統一主題就是CUDA線程。CUDA線程是最低級別的并行,可以執行一次操作。例如,如果我們有200個CUDA線程,那我們就可以同時進行200個算術運算,這樣一來程序的吞吐率就有了提高。
就目前來看,CUDA的應用場景是非常廣泛的。在消費級市場上,幾乎每一款重要的視頻程序都已經使用CUDA加速。除此之外,在科研界和金融市場,CUDA都有相應的使用場景。不可否認的是,在未來,GPU計算必將成為主流。
參考文獻
[1]John L. Hennessy, David A. Patterson. Computer Architecture: A Quantitative Approach[M].人民郵電出版社,2013.
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
