基于稀疏正則化的高維數據可視化分析技術
2017-07-10 10:27:26陳海輝周向東施伯樂
計算機應用與軟件 2017年6期
陳海輝 周向東 施伯樂
(復旦大學計算機科學技術學院 上海 200433)
基于稀疏正則化的高維數據可視化分析技術
陳海輝 周向東 施伯樂
(復旦大學計算機科學技術學院 上海 200433)
高維數據可視化分析是數據分析與可視化領域的研究熱點,傳統的降維方法得到的低維空間往往難以解釋,不利于人們對高維數據的可視化分析與探索。提出一種新的可視化解釋器(Explainer)方法,將L1稀疏正則化特征選取引入到高維數據的可視化處理過程中,建立起高層語義標簽與少量的關鍵特征之間的聯系。通過可視化設計與實驗驗證了該方法可以有效改善高維數據的可視化分析性能。
高維數據 特征選取 稀疏學習 可視化分析 降維 投影
0 引 言
高維數據可視化分析將高維數據處理與可視化呈現結合,如運用數據降維技術,結合視覺編碼手段進行數據分析與探索。近年來高維數據可視化分析技術在實際應用中顯示出越來越重要的價值。
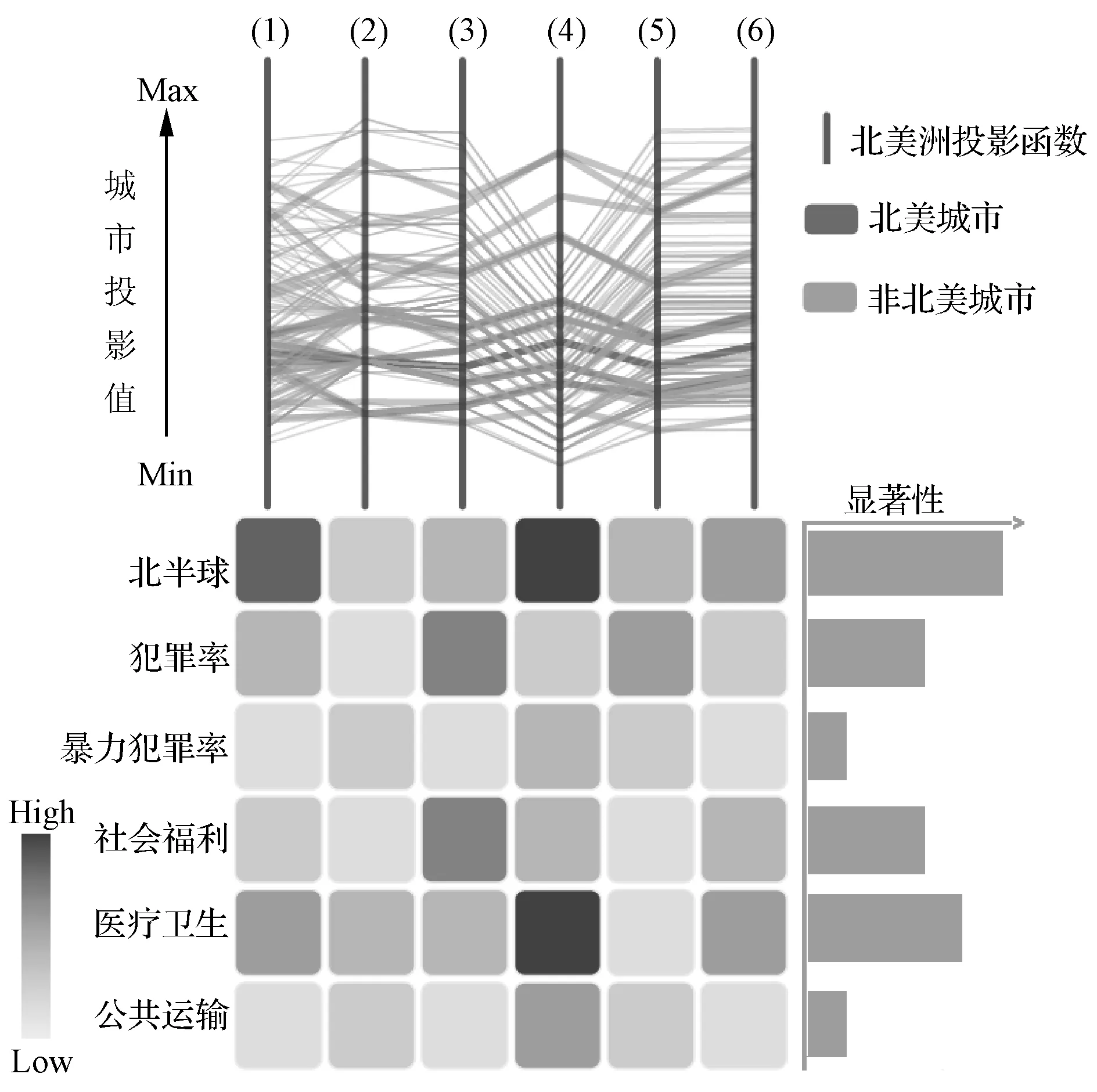
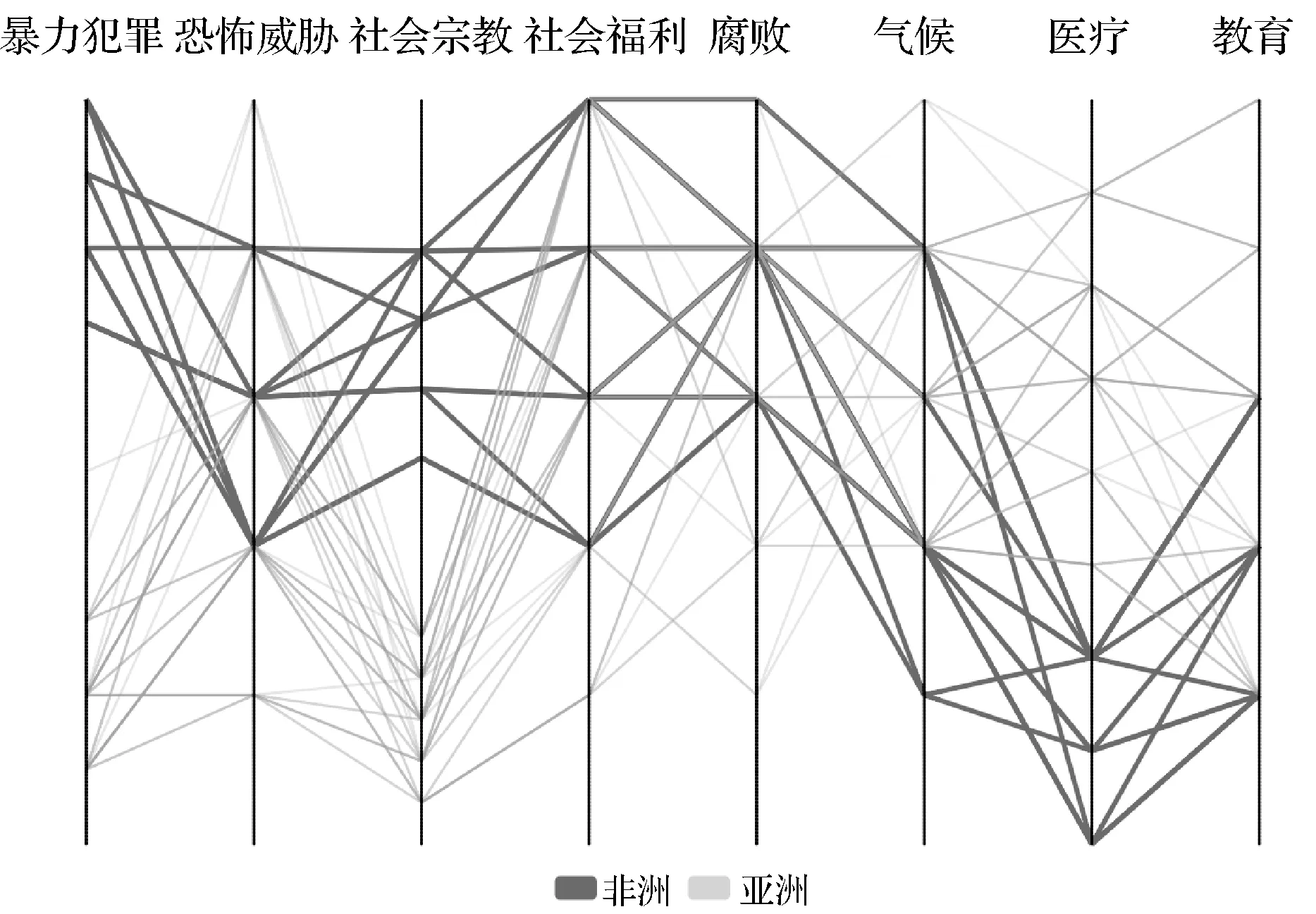
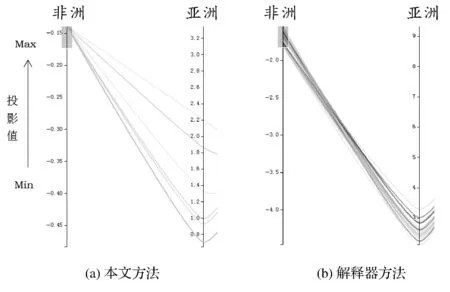
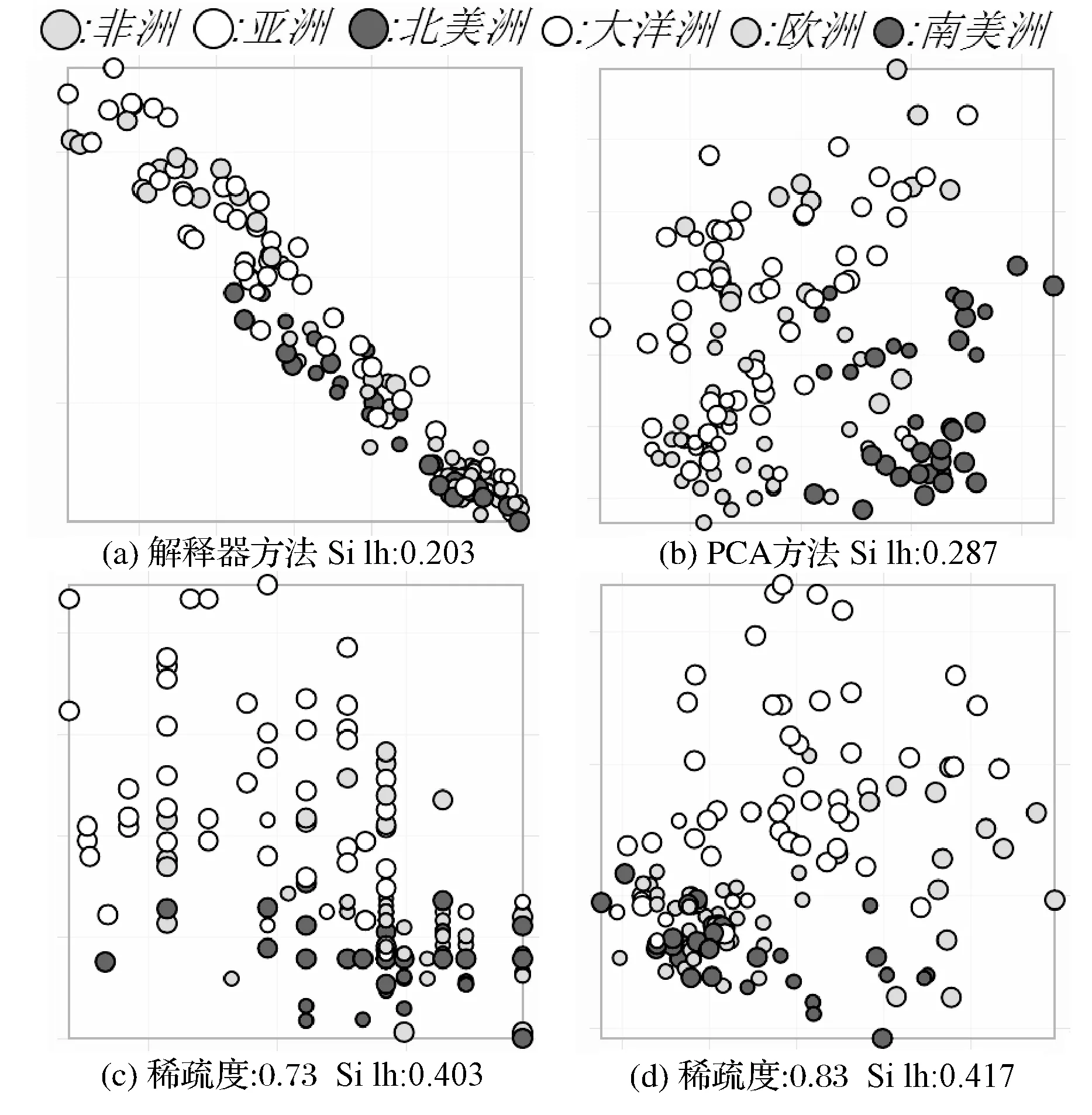
高維數據可視化分析中常用的數據降維方法,如主成分分析法[1]等將N維高維數據點投射到新生成的K維空間中(K< 本文在解釋器技術的基礎上,提出一種新的針對層次化高維數據可視化分析的方法。我們使用基于L1稀疏正則化的層次分類器進行模型訓練,實現數據特征的自動選取(即降維處理)。通過參數調節模型的稀疏性,可以得到不同的特征組合,以及相應的解釋器(投影函數),從而建立起多方位的從高維特征到低維特征、低維特征到高層語義之間的聯系,克服了直接從高維特征到語義空間映射的可視化困難。在兩個通用的可視化數據集上進行了可視化設計與實驗,驗證了本文提出的方法可以有效改進傳統解釋器投影技術的可視化分析性能。特別是在平行坐標圖和散點圖等常用的高維數據可視化技術中,本文提出的方法表現出更好的數據分離能力,改進了高維數據可視化分析的效果 高維數據可視化分析通常由數據降維算法和可視化編碼方法組合而成。投影追蹤算法[2]將高維數據投影到低維子空間上,并通過極小化投影指標函數,尋找出反映原高維數據的結構特征的投影,提高低維空間上數據可視化分析的性能。文獻[3-4]對投影追蹤算法進行改進,將投影指標函數應用到特征變量上,并運用交互式可視化方法從不同視角進行數據分析與探索。文獻[5]將投影追蹤技術應用到散點圖矩陣可視化上,使得在單一空間內可以展示更多的散點圖。上述工作將高維數據變換投影到低維空間的過程中,往往缺乏與用戶知識的結合,基本上可以視為非監督學習類型的高維數據可視化技術。 近年來,將用戶知識融入高維數據的可視化分析的研究越來越多,文獻[6-7]中用戶驅動式的降維算法如PPCA(Probabilistic PCA)、 GTM(Generative Topographic Mapping)根據用戶定義的視角和條件,調節參數產生各種投影函數,方便用戶進行問題驅動的數據探索與分析。文獻[8]提出LAMP算法,通過引入正交投影理論,將用戶知識引入到投影函數學習的過程中。LAMP算法有效地將兩個不相關的高維數據集在同一可視化平面展示,用以探索不同來源數據之間的潛在聯系。這些投影函數往往都是用來組織數據的分布,并不能解釋特征與變量之間的聯系。 文獻[9]中通過為高維數據打上標簽,并學習得到相應的投影函數,用以解釋特征與變量之間的聯系。文獻[10]在高維數據處理過程中使用sugiyama算法減少折線稠密交叉情況,用以解決高維數據平行坐標圖可視化時常見折線聚集的問題。文獻[11]中提出的解釋器技術采用監督學習方法對有關分類器進行學習,把獲得的線性分類函數作為從特征空間到語義空間的投影工具(也稱為解釋器)。通過對待分析數據進行投影(或解釋),實現數據的分析與理解。但是對高維數據的分析,仍然是從高維特征空間到語義空間的映射,無法克服高維數據本身引起的“維災問題”。 2.1 解釋器技術 解釋器技術[11]利用用戶知識來提高數據可視化分析的性能。即根據用戶對數據進行語義標注,采用有監督學習技術,對線性分類器進行訓練: f(x)=w·x+b (1) 式(1)中線性分類器f(x)被看作連接高層語義與底層特征之間的投影函數,稱為解釋器。 根據用戶知識得到的解釋器可以用來重新組織數據,并與可視化編碼相結合實現數據的可視化分析和探索。在文獻[11]的基礎上,文獻[12]引入解釋器技術學習包含用戶知識的投影函數,應用到氣候模型的可視化分析領域。文獻[13]把解釋器作為交互式投影方法,隨著用戶視角改變,交互式探索高維數據在用戶語義空間的分布特性。 但是,利用傳統的解釋器技術對高維數據的分析,仍然面臨高維數引起的“維災問題”,應用到平行坐標圖,散點圖等常見可視化方法中,不同類別數據之間遮擋情況嚴重,耦合與分離效果較差,影響可視化效果。因此,本文基于L1稀疏正則化分類技術,提出一種對高維層次數據可視化分析的新方法,即通過數據特征自動選取建立起低維特征空間與語義空間的聯系,使高維數據可視化分析獲得更好的效果。 2.2 基于L1正則化的層次分類器模型 圖1 城市的層次類標簽結構 層次化數據集是一種常見的數據分析對象,圖1是關于世界各國城市數據集的語義標簽層次結構[11,16]。層次數據集一般使用樹結構進行描述:令A(i)和S(i)分別代表標簽結構樹上節點i的祖先節點和兄弟節點集合,并且令A+(i)=A(i)∪i。令X∈Rd為輸入數據集的特征空間,維數是d。Y={1,2,…,m}為層次樹上除了根節點0以的其他節點對應的標簽編號。每一個層次標簽對應唯一的編號。 本文采取的對高維層次數據可視化分析方法主要包括:基于L1正則化的層次分類器模型的訓練;可視化分析設計兩個部分。本節主要介紹層次分類技術;可視化設計在實驗部分詳細介紹。 (2) 式(2)中R(w)是正則化項,用以防止訓練得到的模型過擬合。{ξk},?k∈{1,2,…,N}是損失因子中的松弛變量。參數C1用以控制正則化項和損失項的平衡。 (3) 式(3)中R(w)采用混合的正則化方法[15],第一項使用L1稀疏化方法對模型的參數進行約束,這樣既能增加層次分類的判別區分能力,又能夠同時學習出一組稀疏的真正有貢獻的特征組合。在后續的層次數據可視化分析和探索中,幫助學習語義標簽與對應特征組合之間的關聯。C2可以用來控制稀疏化的程度。第二項和第三項是層次分類的正交正則化約束,使得不同層次和兄弟節點分類器使用各自特有的特征組合,提高分類性能。關于模型的參數估計,本文采用文獻[14-15]給出的正則對偶式平均RDA(Regularized Dual Averaging)方法。 3.1 可視化分析案例 本文以城市數據集[16]和UCI汽車數據集[17]為案例進行可視化探索的實驗與對比分析。城市數據集包含4層數據:城市、國家、地區和大洲,數據維度45維。汽車數據集包含2層數據:汽車類型和汽車品牌,數據維度26維。 可視化實驗分為兩部分: 1) 本文設計的解釋器-特征選擇圖幫助可視化探索數據語義標簽與顯著特征的關系。 2) 常見高維數據分析的可視化效果對比:在平行坐標圖和散點圖對比使用本文方法和解釋器方法的可視化效果。 3.2 解釋器-特征選擇圖 本文設計了如圖2所示的解釋器-特征選擇圖。該圖形展示了不同的北美洲投影函數與相應的特征組合之間的關系。通過調節L1懲罰項參數,可以得到6組北美洲投影函數和與之對應的特征組合。用平行坐標圖中的不同垂直軸線,代表了不同的北美洲投影函數。北美洲的城市(圖中深色折線)與非北美洲城市(圖中淺色折線)分別用6個投影函數在平行坐標圖上作投影映射。 圖2 解釋器-特征選擇圖 圖2以熱力圖的形式展示投影函數與其對應的顯著特征。每一列方格代表不同的特征組合,與上方的軸線(即投影函數)對應。每一行代表一種特征。熱力圖中方格顏色深淺代表該特征的顯著性。熱力圖右邊用直方圖統計每一種特征的平均顯著性。 圖2中每條軸線上深色折線基本都在淺色折線的上方。在北美洲投影函數下,北美洲的城市對比于非北美軸的城市,往往具有更高的投影值,證明了本文將L1稀疏化方法引入分類器學習的有效性。 通過解釋器-特征選擇圖,發現北美洲城市中最顯著的特征,主要是醫療衛生水平、犯罪率等。這樣就可以發現高層語義標簽與特征之間的潛在關系,用戶可以重點觀察這些特征進一步分析數據。 表1為將本文方法應到城市數據集,根據解釋器-特征選擇圖分析得出的各個大洲的最具有顯著性的特征組合。根據表1中得到的所有8個特征,繪制出圖3所示城市數據集的平行坐標圖。可以發現,非洲城市(深線)和亞洲城市(淺色)在各個特征上的表現的模式具有顯著的區分度和離散度,可以非常方便地對不同城市(折線)進行觀測與分析。原始45維的數據集在這8個維度就可以得到很顯著的區分性,證明了解釋器-特征選擇圖可以方便高維數據的可視化分析。 表1 大洲的特征組合 表2為將本文方法應到汽車數據集,根據解釋器-特征選擇圖分析得出的各個汽車類型的最具有顯著性的特征組合。 圖3 城市數據集的平行坐標圖 表2 汽車類型的特征組合 3.3 改進的解釋器投影效果 本節對比本文方法與解釋器方法投影效果,分別應用L1稀疏正則化方法和解釋器方法得到“非洲”語義標簽對應的投影函數。經過投影變換,將城市數據投影到非洲軸上。 圖4 本文方法與解釋器方法投影效果對比 如圖4所示,在非洲解釋器上投影值排名前10%的城市的分布,可以發現本文方法中非洲城市主要分布在非洲軸的上部分,不是非洲的城市主要分布在軸下方,而解釋器方法中非洲城市分布在非洲軸的中上部分,明顯本文方法投影效果比解釋器方法更好,對于提高投影的準確性具有顯著作用。 3.4 改進的平行坐標圖效果 如圖5所示,同樣以非洲與亞洲兩個軸線為例,分別應用本文方法和解釋器方法作平行坐標圖。通過對數據作篩選,取在非洲軸投影值最高的10%的數據。可以發現右圖中,數據折線很明顯聚集在一起(b),并不利于發現這一系列數據在其他軸線上的分布特性。而我們使用稀疏化方法(a)中,數據折線相對離散,分離效果明顯,便于對數據單獨分析和可視化展示。引入L1稀疏化特征選擇方法,表現出了更好的數據分離能力,對于平行坐標圖的數據線條聚集問題有明顯改進。 圖5 平行坐標圖折線分散效果對比 3.5 改進的散點圖效果 由于散點圖平面較小,當數據數量很高時,數據點聚集現象就會變得很嚴重,極大影響可視化圖形的閱讀性。因此,可視化數據點之間的聚集與離散性指標Silhouette (Silh)系數[18]通常用來評價散點圖可視化效果。式(4)中,ax代表點x與同類別的其它點之間距離的平均值,bx代表點x與所有其它類別的點的距離的最小值。Silh的值的范圍在-1到 1之間,Silh值越大代表更好的內聚性和分離性。 (4) 圖6展示的是學習得到的關于非洲城市和亞洲城市投影函數后得到散點圖。圖6(a)是解釋器方法得到的散點圖, Silh值為0.203。圖6(b)是應用本文方法后得到低維空間的數據后,再使用PCA方法得到的散點圖,Silh值為0.287。 圖6(c)和圖6(d)所示為本文方法在稀疏度為0.73、0.83時,Silh值分別為0.403和0.417均高于傳統方法和PCA方法。說明本文方法在數據的散點圖可視化時,耦合性和分離性效果表現更好。圖7展示中將本文方法應用到汽車數據集合中,對比傳統的解釋器方法以及PCA方法,本文方法圖7(c),圖7(d)的Silh分別為0.485和0.513,獲得了更好的結果。 圖8為本文方法和傳統的PCA方法應用到城市數據集和汽車數據集上的稀疏度-silh值圖。可以發現隨著稀疏度的提高,散點圖的Silh值明顯提高。但特征過于稀疏后,Silh也會明顯下降。對比這兩個數據集上的結果,發現本文方法相比于PCA方法,獲得的Silh值都更大,可視化效果更好。 因此,本文方法相比解釋器方法和PCA方法,對于多類別的數據在二維散點圖展示時,明顯提升數據的內聚性和分離性,不同類別數據點聚集情況明顯減輕,方便了分析人員可視化探索數據。 通過可視化實驗中對比效果,可以發現本文提出的基于高維層次數據可視化分析的方法,通過引入L1稀疏化學習的過程,不僅便于分析人員可視化探索高維數據語義標簽與特征之間的潛在關系。通過可視化實驗,本文方法對比于解釋器方法和傳統的PCA方法,在平行坐標圖和散點圖上的可視化效果更好,明顯改進了圖形中數據的聚集現象,提高數據分離效果,方便分析人員對高維數據的可視化探索。 圖6 城市數據集-散點圖效果對比 圖7 汽車數據集-散點圖效果對比 圖8 稀疏度-silh值圖 本文提出一種針對層次化高維數據進行可視化分析和探索的新方法。對層次結構數據集采用L1稀疏化分類器進行模型訓練,實現語義標簽與之緊密相關的數據特征的自動選取。通過參數調節模型的稀疏性,可以得到不同的特征組合,以及相應的高維數據解釋器(投影函數),從而建立起了從高維到低維特征與高層語義之間的聯系。通過可視化實驗,證明了本文提出的方法可以改進解釋器投影技術的可視化分析效果,特別是在平行坐標和散點圖等常用的高維數據可視化技術中,本文提出的方法表現出更好的數據分離能力,可以有效改進高維數據的可視化分析效果。 [1] Jolliffe I T.Principal Component Analysis[J].Springer Berlin, 2010,87(100):41-64. [2] Friedman J H, Tukey J W. A Projection Pursuit Algorithm for Exploratory Data Analysis[J].Computers IEEE Transactions on, 1974, C-23(9):881-890. [3] Faith J. Targeted Projection Pursuit for Interactive Exploration of High-Dimensional Data Sets[C]//Information Visualization, 2007. IV’07. 11th International Conference. IEEE, 2007:286-292. [4] Seo J, Shneiderman B. A Rank-by-Feature Framework for Interactive Exploration of Multidimensional Data[J].Information Visualization, 2005, 4(2):96-113. [5] Wilkinson L, Anand A, Grossman R. Graph-theoretic scagnostics[C]//Information Visualization, 2005. INFOVIS 2005. IEEE Symposium on,2005:157-164. [6] Wang S P, Cao H F, Wei Ping W U. Observation-level interaction with statistical models for visual analytics[C]//Visual Analytics Science and Technology. IEEE, 2011:121-130. [7] Tejada E, Minghim R, Nonato L G. On improved projection techniques to support visual exploration of multidimensional data sets[J].Information Visualization,2003,2(4):218-231. [8] Paulo J, Paulovich F V, Danilo C, et al. Local Affine Multidimensional Projection[J].IEEE Transactions on Visualization & Computer Graphics,2011,17(12):2563-2571. [9] Kandogan E. Just-in-time annotation of clusters, outliers, and trends in point-based data visualizations[C]//Visual Analytics Science and Technology,2012:73-82. [10] Lu L F, Huang M L, Chen Y W, et al.Clutter Reduction in Multi-dimensional Visualization of Incomplete Data Using Sugiyama Algorithm[C]//International Conference on Information Visualization. IEEE Computer Society, 2012:93-99. [11] Michael G.Explainers: expert explorations with crafted projections[J].IEEE Transactions on Visualization & Computer Graphics, 2013,19(12):2042-2051. [12] Jorge P, Aritra D, Yaxing W, et al. Visual Reconciliation of Alternative Similarity Spaces in Climate Modeling[J].IEEE Transactions on Visualization & Computer Graphics, 2014,20(12):1923-1932. [13] Sedlmair M, Heinzl C, Bruckner S, et al. Visual Parameter Space Analysis: A Conceptual Framework[J].IEEE Transactions on Visualization & Computer Graphics, 2014,20(12):2161-2170. [14] Zhou D, Xiao L, Wu M.Hierarchical Classification via Orthogonal Transfer[C]//International Conference on Machine Learning,2011:801-808. [15] 產文. Web社區問答檢索的關鍵技術研究[D].復旦大學,2014. [16] Buzzdata. Best City Contest[Z]. 2012. [17] Bache K, Lichman M. UCI Machine Learning Repository[Z/OL]. Irvine, CA: University of California, School of Information and Computer Science.2013. http://archive.ics.uci.edu/ml. [18] Tan P N, Steinbach M, Kumar V. Introduction to Data Mining, (First Edition)[M].Addison-Wesley Longman Publishing Co. Inc,2005. HIGH-DIMENSIONAL DATA VISUALIZATION ANALYSIS TECHNOLOGY BASED ON SPARSE REGULARIZATION Chen Haihui Zhou Xiangdong Shi Bole (SchoolofComputerScienceandTechnology,FudanUniversity,Shanghai200433,China) High-dimensional data visualization analysis is the research hotspot in the field of data analysis and visualization, the traditional low-dimensional dimension reduction method is often difficult to explain, and is not conducive to the visualization of high-dimensional data analysis and exploration. In this paper, a new visual explorer (Explainer) method is proposed to introduce the L1 sparse regularization feature selection into the high-dimensional data visualization process, and establish the relationship between high-level semantic tags and a few key features.The feasibility of the method is verified by visual design and experiment. It can improve the visualization performance of high dimensional data effectively. high-dimension data Feature selection Sparse learning Visualization analysis Dimension reduction Projection 2016-05-03。國家自然科學基金項目(61370157);上海市科技項目(14511107403);國網科技項目(5209401600 0A)。陳海輝,碩士生,主研領域:數據可視化。周向東,教授。施伯樂,教授。 TP3 A 10.3969/j.issn.1000-386x.2017.06.0051 相關工作
2 模 型


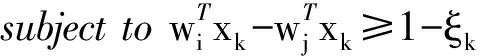
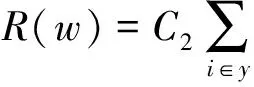
3 可視化實驗





4 結 語
猜你喜歡
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
傳媒評論(2019年4期)2019-07-13 05:49:14
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
